やりたいこと
JSONL(※)ファイルをGlue Crawlerで認識しAthenaで読む際、nullなデータがあった場合どうなるかを知りたい。
※JSON Lines。改行コードをデリミタとして1行1レコードに分割したJSONのこと。AthenaはJSONLしか扱えないので注意。
データを作る
nameをstring、ageをintと想定してサンプルデータを作る。
json-test.json
{ "id": 001, "name": "Kamado", "age": 16 }
{ "id": 002, "name": "Kibutsuji", "age": null }
{ "id": 003, "name": null, "age": 19 }
{ "id": 004, "name": "Gyutaro", "age": 0 }
{ "id": 005, "name": "", "age": null }
{ "id": 006, "name": "Uzui" }
{ "id": 007, "age": 32 }
% aws s3 cp ./json-test.json s3://<バケット名>/jsontest/
スキーマを読み取る
jsondbというデータベースを作り、上記S3パスを走査対象としたGlue Crawlerを作成し、実行する。
(※詳細は省略)
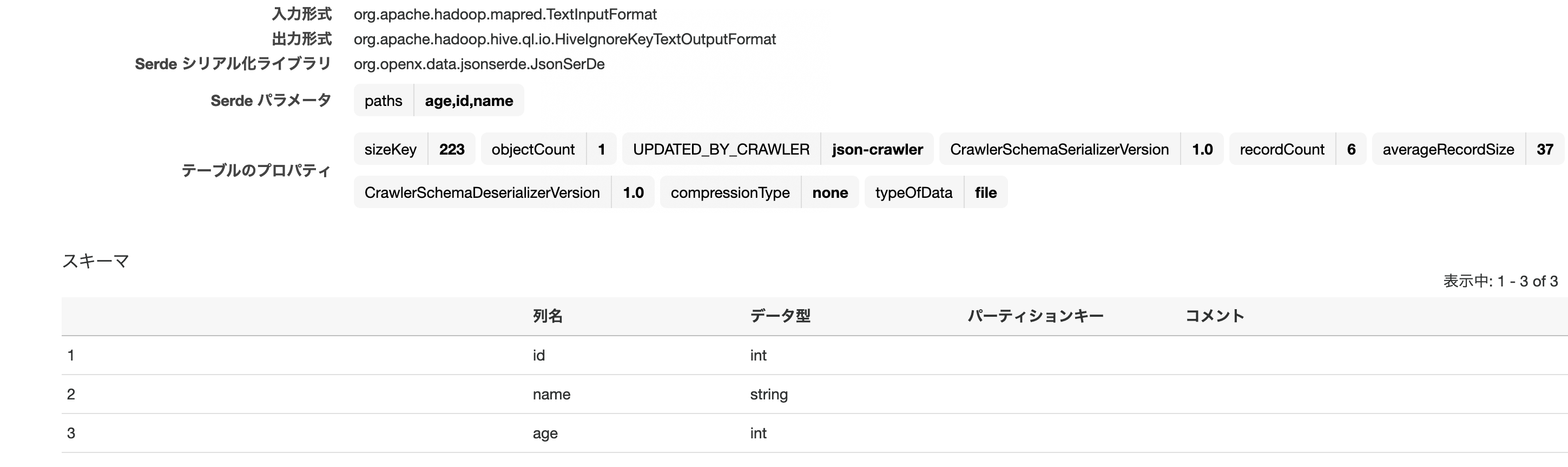
読み取られたスキーマはこちら。
int、stringとintとして読み取られていることが分かる。テーブルはS3パス名を反映してjsontestとなっている。
Athenaで検索
まずは全件。
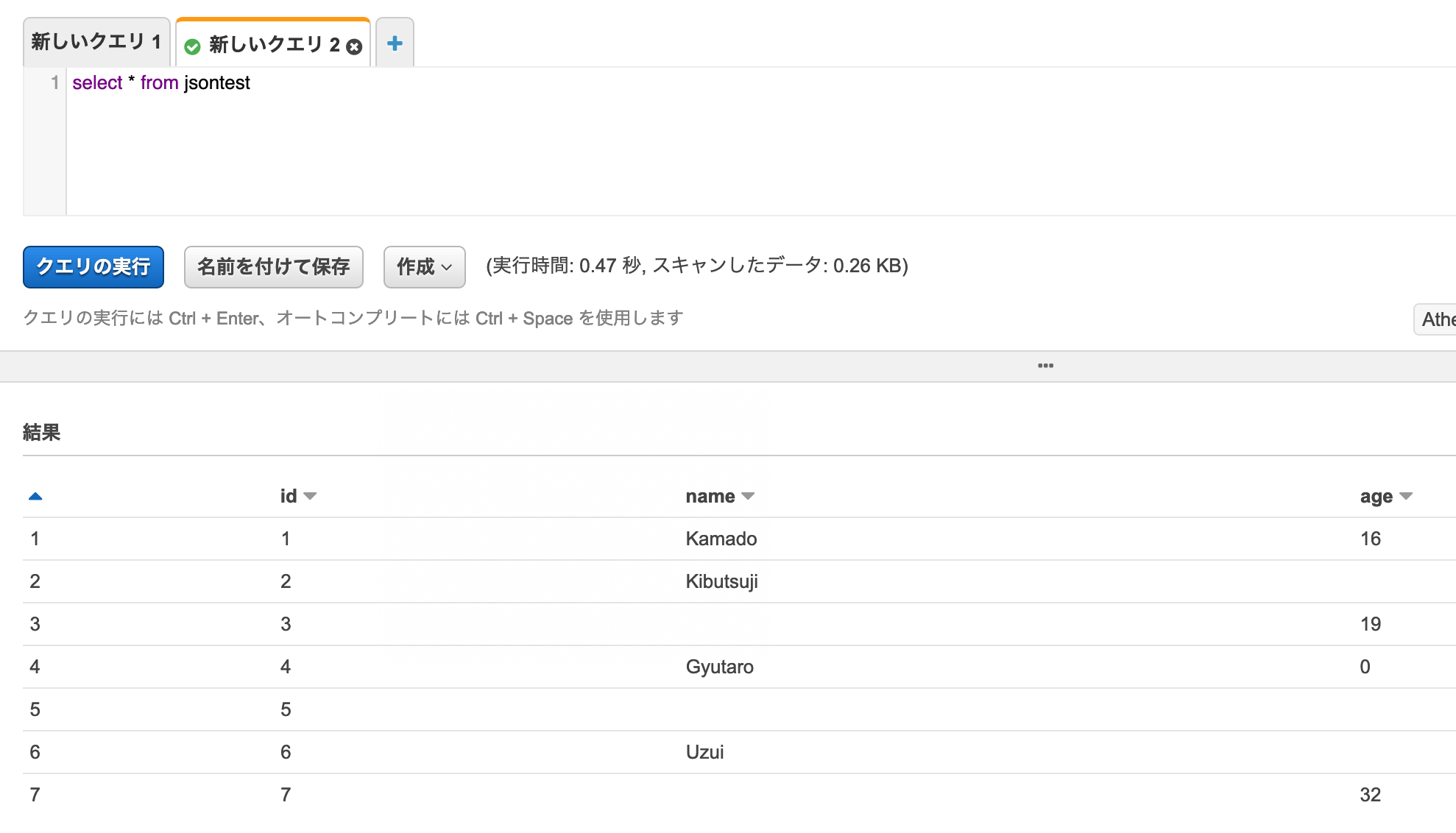
null、空文字("")、項目なしは、ぱっと見いずれも同じ扱いに見える。
name(string)がnullのものをクエリーしてみる。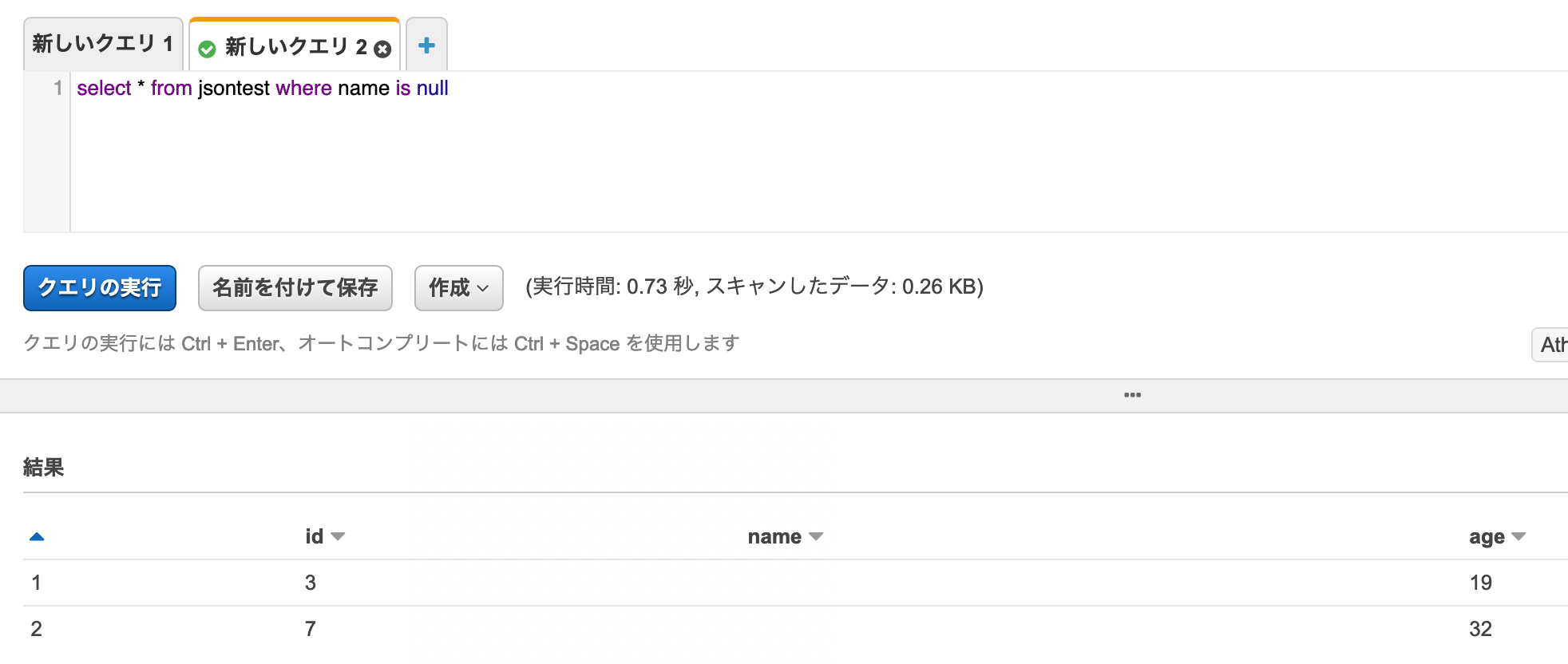
id=3(null)とid=7(値なし)が検索され、id=4(空文字)は除外された。
両者は同じ扱いな一方で、空文字は別扱いされていることが分かる。
intについても確認。
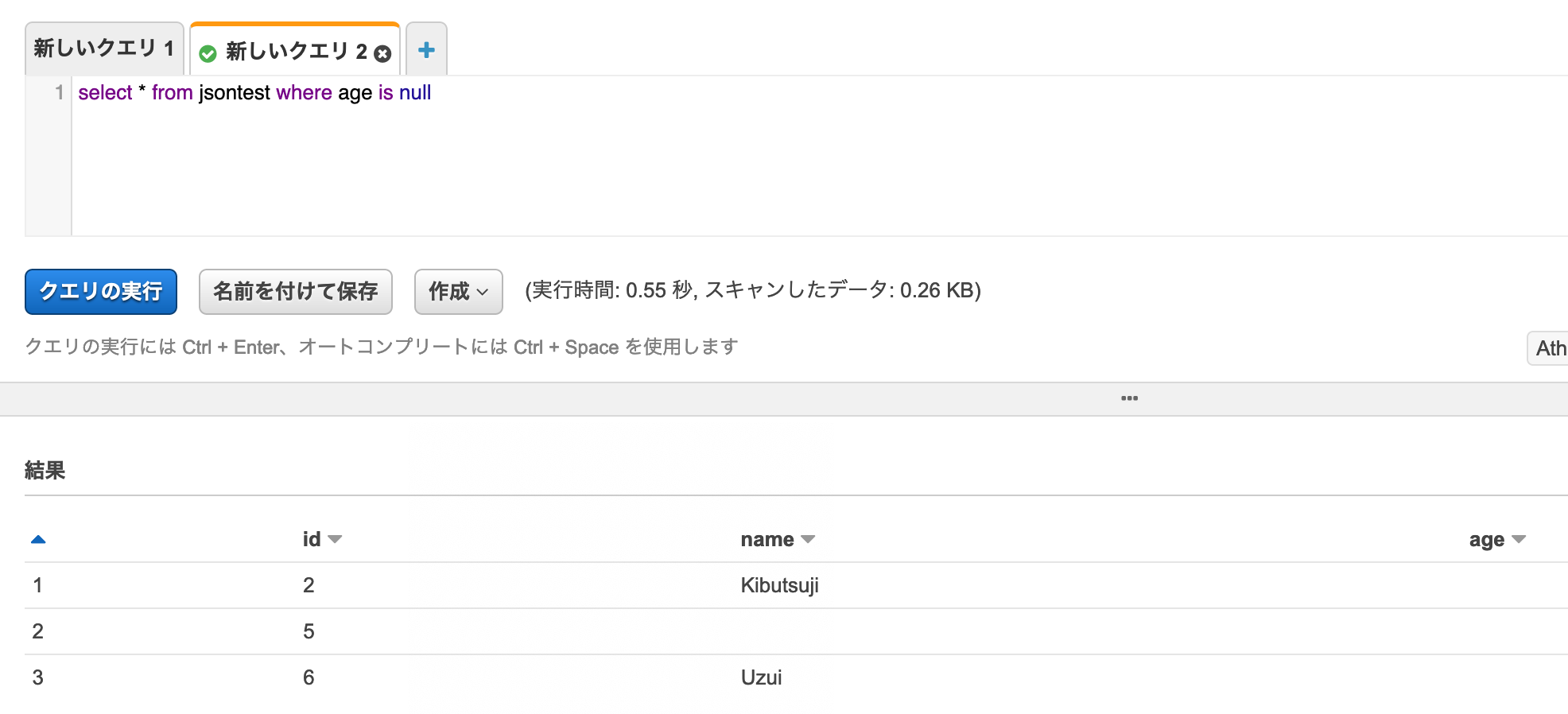
id=2(null)、id=5(null)、id=6(値なし)が検索された。id=4(0)が除外されるのはまあ当たり前。
ここでも、nullと値なしが同じ扱いなのが確認できた。
結論
- GlueでもAthenaでも、JSONLに含まれたnullを扱える。
- nullと値なしは同等の扱いのため、出力元コードやAthenaの処理量を少しでも減らしたい場合は、nullで埋めずに値なしでJSONL出力するのもあり。