やりたいこと
現在year,month,dayまでのパーティション粒度で作成しているテーブルを、year,month,day,hourのパーティション粒度に変換する。
しばらく前にAthenaがGlueパーティションインデックスに対応したので、より細かいパーティションを作ってもGetPartitionで遅くなる問題は回避できそう、じゃあ細かいパーティションを切って取得データ量を減らせるのでは、という発想による。
やること
CTASを使って別テーブルを作る。
ステップバイステップ
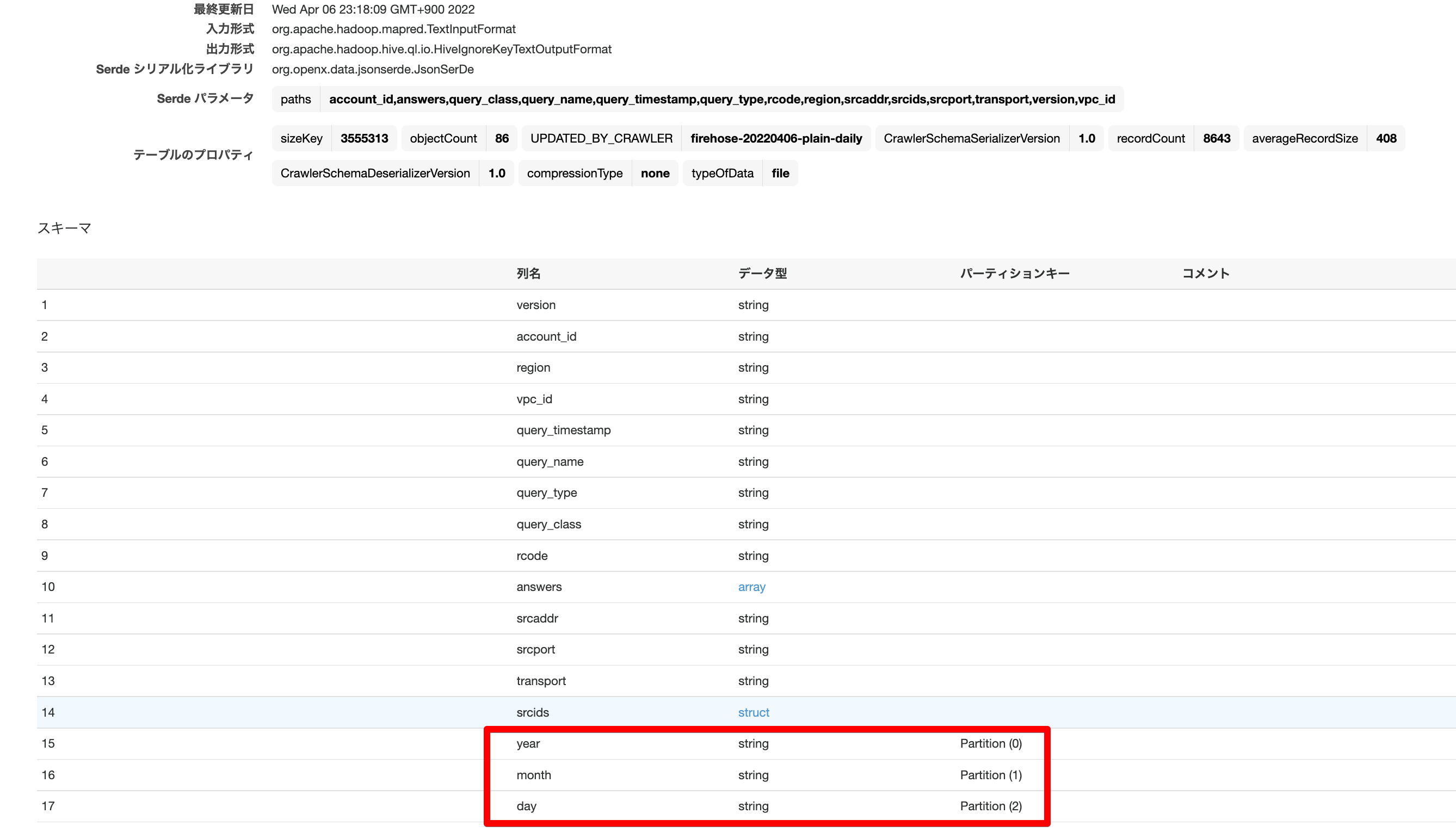
1. 現行テーブルの定義を確認
サンプルのソーステーブルは、動的パーティショニング検証で作ったDNS Resolverクエリーのものを、dayまでのパーティション粒度に変更して作成。
Glueでテーブル定義を確認してみる。PARTITIONED BYセクションがyear,month,dayまでになっていることがわかる。
2. CTASの実行
以下を実行する。
なおここでは、全件ではなく試しに4月6日分だけを対象としている。また、本筋に関係ないので、列も絞っている。
CREATE TABLE plain_daily_migrated
WITH (
format = 'JSON',
external_location = 's3://kfh-dynamic-test/plain_migrated/',
partitioned_by = ARRAY['year','month','day','hour']
) AS
SELECT version, region, query_timestamp, query_type, year, month, day, substr(query_timestamp,12,2) as hour
FROM plain_daily
where year = '2022'
and month = '04' and day='06';
ポイントは、timestamp相当列(このテーブルの場合はquery_timestamp)の、時間(HH)に相当する文字をsubstrで取り出し、hourパーティション列として定義していること。これがないと、partitioned_byで指定したパーティション列が存在しないと怒られることになる(Partition columns [hour] not present in schema.)。
3. 確認
S3を確認すると、ちゃんとdayの下にhourパーティションが作られていることがわかる(hour=00〜05がないのは、hour=05以前のデータがないため。plain_dailyテーブルは日本時間の15時頃、UTCの06時頃に作成している)。
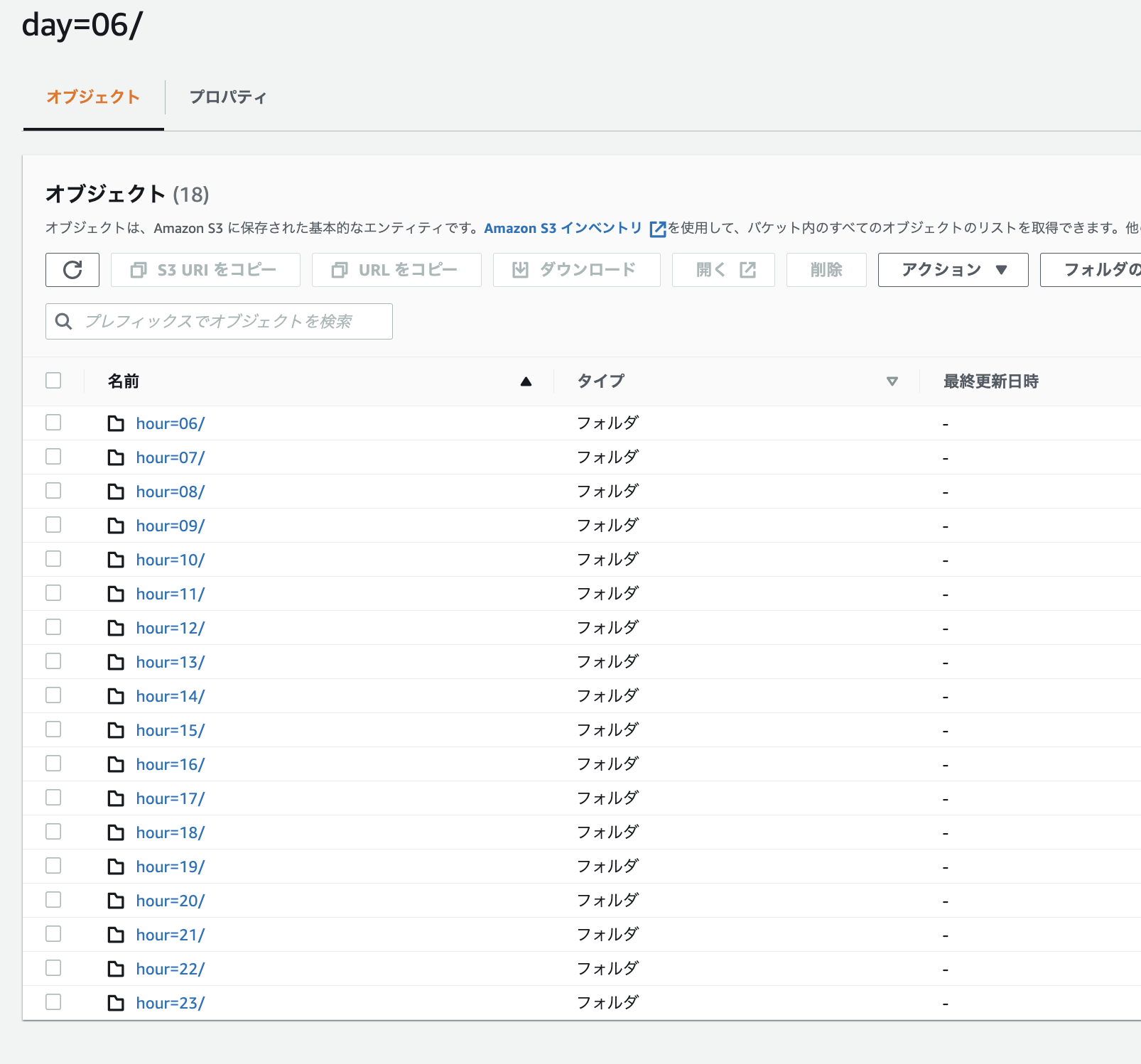
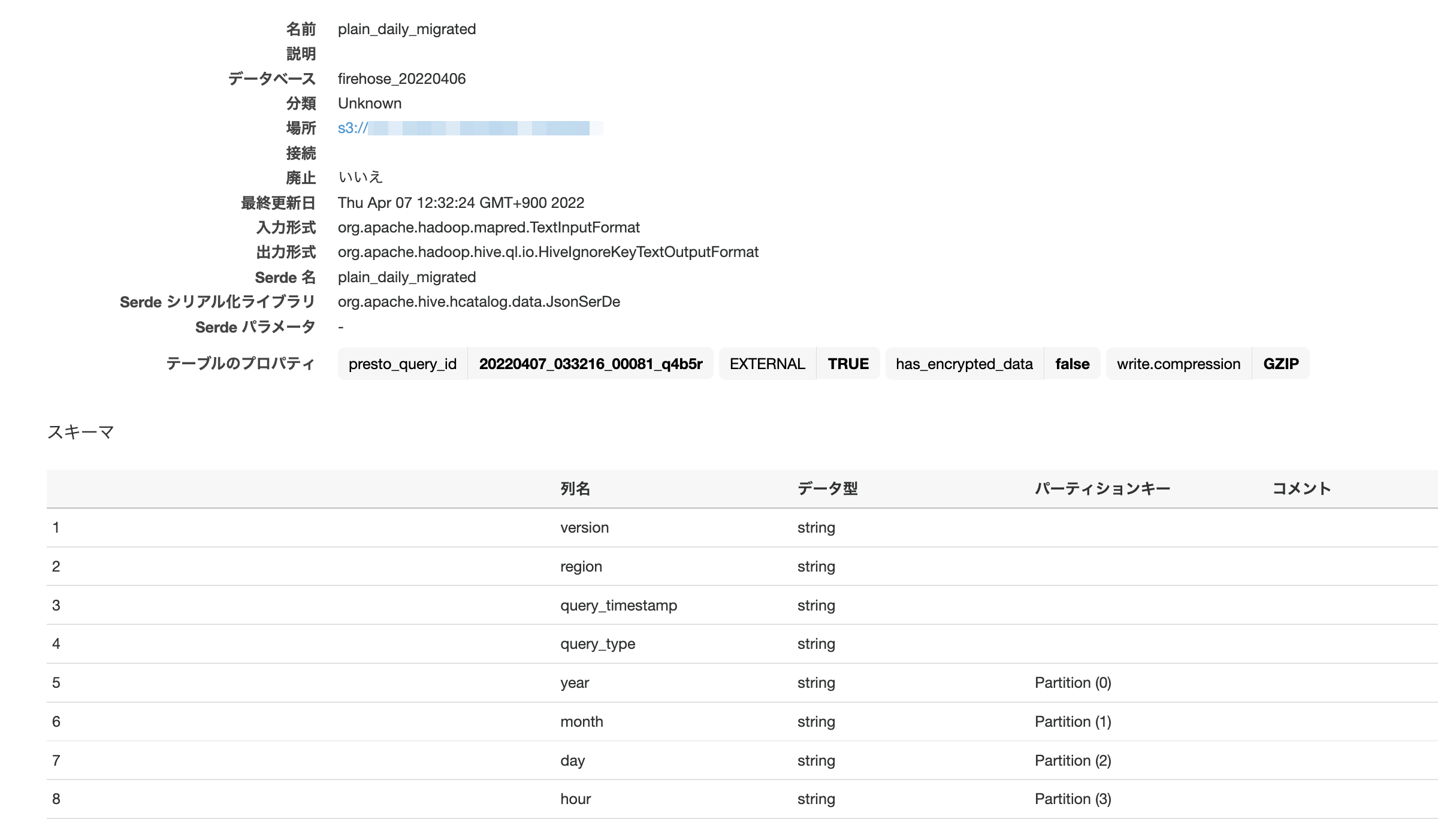
Glueテーブル定義(抜粋)。
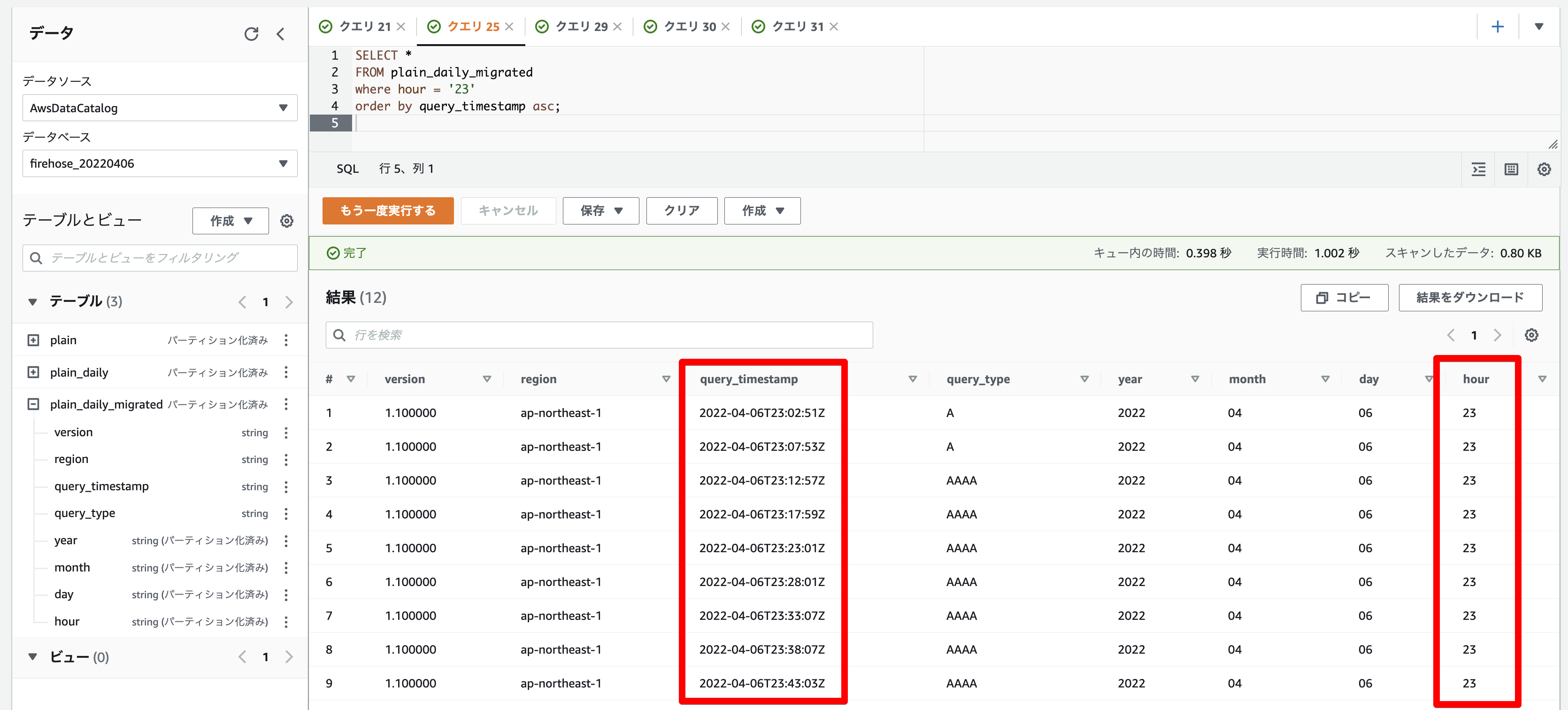
最後にAthenaで実データを確認する。
SELECT *
FROM plain_daily_migrated
where hour = '23'
order by query_timestamp asc;
23時のデータを検索してみると、timestamp列の時刻と、新たにパーティションとして追加されたhour列が一致していることが確認できる。
まとめ
少なくともtimestampの場合、CTASで簡単にパーティション列を追加できることが分かった。
なお今回はたまたまtimestamp相当の列があったために細かい設定をせずに済んだが(マニュアル上はsubstrやcastを駆使する必要がありそうな記載だが今回は要らなかった※)、テーブル定義や追加したいパーティション列の内容によっては、あれこれと工夫しなければならないかも知れない。
また、AthenaのCTASには一度に100パーティションしか追加できない制約があること(対処するには100件未満のIASを繰り返す必要がある)や、Firehose等でリアルタイム/準リアルタイムに生成している場合の新旧データ統合、CTASに伴うクエリーコストなど、実際にこの方法を採る上での課題は多いように感じた。
また、ここでhourの元となっているtimestampは、あくまでデータ発生時刻である点にも注意する必要がある。
元テーブルのパーティションが処理時刻ベースな場合(例えばFirehoseは、動的パーティショニングを使わない限りそうなる)に整合性が取れなくなるし、timestampはUTCだがパーティションはJSTベースとしたいといったケースもあり得る。
...と、要件やデータ量に左右される要素はまあ大きいものの、CTAS一発で簡単にパーティション列を追加できる点は、素直に便利だなと思った次第。
※2022年4月7日追記:
ソーステーブルを、間違えてhourパーティションが既にあるもの(plain)を選んでいたためにその列が使われただけでした。dayパーティションのみのソーステーブル(plain_daily)に指定し直したところ、やはりsubstrは必要でしたので、お詫びして訂正します。