データ列のソートアルゴリズムの中で、速いとされているクイックソートとマージソートをC言語で実装してみます。クイックソートはC言語のライブラリにあるqsort()で使用されているということですが、条件によって計算量が増加してしまいます。それに対する対策もさまざまな実装があるようです。マージソートは計算量は一定であり、安定して速いと言われていますが、処理過程においてワークメモリを使用する必要があります。
クイックソートの実装
クイックソートは、Charles Antony Richard Hoareが考案したアルゴリズムである。
クイックソートの動作は、データ列をある値(ピボット)より小さい値のデータ列と大きい値のデータ列に分離し、分離したデータ列に対してまた、ある値(ピボット)より小さい値のデータ列と大きい値のデータ列に分離するという操作を、データ列の要素が1つになるまで繰り返す。
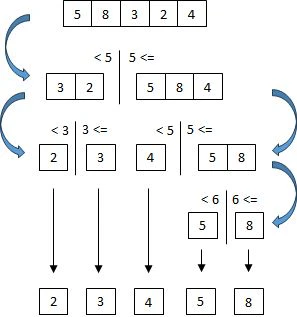
アルゴリズムがhttps://dl.acm.org/doi/pdf/10.1145/366622.366644に記載されているので、ほぼその通りに(C言語で)実装する。引数は、データ列 array[]、ソート範囲の左端 m、ソート範囲の右端 nである(arra[m] ~ array[n] をソートする)。
void quick_sort(int array[], int m, int n) {
if (m >= n) {
return;
}
/***データ列の分割(partition)***/
quick_sort(array, m, j);
quick_sort(array, j + 1, n);
}
データ列の分割は、データ列(array[m] ~ array[n])をピボットより小さい値のデータ列(array[m] ~ array[j])とピボットより大きい値のデータ列(array[j+1] ~ array[n])に分割する。アルゴリズムの説明がHoare's partition algorithmにあるので、これもその通りに実装する。
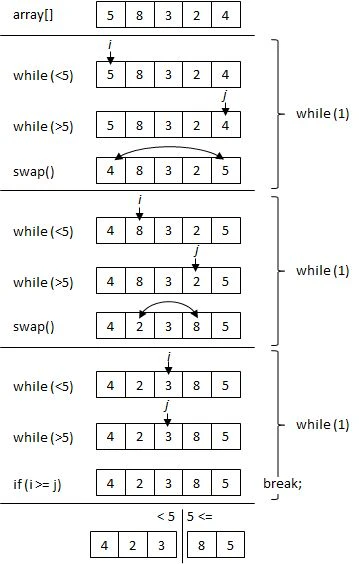
/* partition */
int p = array[m]; // consider the first element as pivot
int i = m, j = n; // i = left most, j = right most
while (1) {
while (array[i] < p) i++; // until greater than or equal to pivot
while (array[j] > p) j--; // until less than or equal to pivot
if (i >= j) { // pointers cross -> partitioning complete
break;
}
int tmp = array[i]; // swap left element and right element
array[i] = array[j];
array[j] = tmp;
i++; j--;
} // partition m to j and j+1 to n
ただし、iとjについては、i + 1 = j の関係でなければならないので、j のみを使って実装した。また、
上記実装例では、
int i = -1;
while () {
do {
i++;
} while ();
swap();
}
のようにしているが、ここでは、
int i = 0;
while () {
while () i++;
swap();
i++;
}
のように実装した。このアルゴリズムの説明では、ピボットをデータ列の先頭の値にしているので、これもそのまま実装した。このアルゴリズムの動作は、
のようになる。
- iを左端からピボット以上の値がデータ列に現れるまでインクリメントし、jを右端からピボット以下の値がデータ列に現れるまでデクリメントする。
- iとjが一致または交差していなければ、iの位置のデータはpivot以上の値なので右側のデータ列に、jの位置のデータはpivot以下の値なので左側のデータ列に移動するために、swapする。
- i と j が一致または交差するまで、1. 2.を繰り返す。
要素数N個のデータ列をソートする場合、データ列を2つに分割するのを繰り返すのにlogN回、分割する操作(partition)にN回(左からの検索と右からの検索が同じ位置に達するまで)であるから、計算量は N×logN 回となる。ただし、2つに分解する操作で、1個とN-1個のような分割になってしまうと、N個のデータを分割する操作にN-1回かかることになり、最悪条件ではN2回の計算量になってしまう。
マージソートの実装
マージソートは、データ列を分割し、分割したデータ列をソートした後で、データをマージする際に小さい値から順番にマージしていくことで、データ列をソートする。
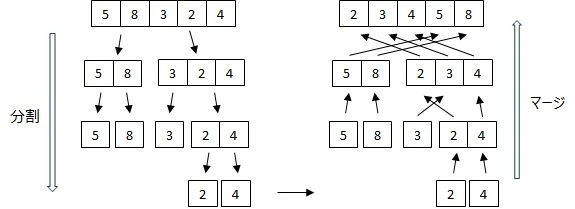
データ列の分割は、分割した要素が1個になるまで、左半分と右半分に2分割することを繰り返す。データの分割ができたら、データ列のマージを繰り返していく。マージする際には次の手順で行う。
- 2つのデータ列の先頭のデータを比較して、小さい方の値をマージする。
- マージした値は元のデータ列から取り除く。
- 1.と2.を繰り返して、2つのデータ列の値すべてを1つのデータ列にマージする。
この手順では、マージする前の2つのデータ列がソートされている必要があるが、データ列の分割で要素数が1個になるまで分割している(要素数が1個のデータ列はソート済みである)ので、上記の手順でマージを繰り返していくことで、常にソート済みのデータ列をマージしていくことができる。
この手順を実装してみる。merge_sort() 関数は、データ列 array[] とデータ列の要素の個数 n を引数にとる。関数の中で、データ列を2分割したデータ列を引数として、merge_sort() を再帰的に呼び出し、関数から戻ってきた(2分割したデータ列がソートされてきた)後で、1つのデータ列にマージする。
void merge_sort(int array[], int n) {
if (n == 1) { // no need to sort
return;
}
int mid = n / 2;
merge_sort(array, mid); // sort left half
merge_sort(array + mid, n - mid); // sort right half
/*** データ列をマージ(merge) ***/
}
マージの実装は以下の通り。
/* merge */
int sorted[n]; // merge into here
int li = 0, ri = mid;
for (int i = 0; i < n; i++) { // merge sorted arrays
if (li == mid) { // left half end
sorted[i] = array[ri++]; // merge right half
} else if (ri == n) { // right half end
sorted[i] = array[li++]; // merge left half
} else {
if (array[li] < array[ri]) { // merge smaller of left or right
sorted[i] = array[li++];
} else {
sorted[i] = array[ri++];
}
}
}
for (int i = 0; i < n; i++) { // revise array with merged
array[i] = sorted[i];
}
データ列は、array[0] ~ array[mid-1] と arra[mid] ~ array[n-1] の2つのソート済みデータ列が与えらえてている。したがって、一方のデータ列の先頭の位置は li = 0、もう一方のデータ列の先頭の位置は ri = mid である。要素の合計数nに対して、i = 0~ n-1 について、array[li]とarray[ri]の小さい方を sorted[i] に入れて、入れた方のインデックス(li または ri )を 1 増やす。どちらかのデータ列の要素をすべてマージしてしまったら、残っているデータ列の値をマージしていく。
速度比較
データ個数20000のデータ列(乱数で発生させたものと降順に並べたもの)に対して、quick_sort()、merge_sort() それぞれ3回ずつ
$ time ./a.exe < in.dat > out.dat
のコマンドで時間を計測した。実行プログラムは、
int main() {
int n;
scanf("%d", &n);
int array[n];
for (int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
array[i] = x;
}
quick_sort(array, 0, n - 1);
/* merge_sort(array, n); */
for (int i = 0; i < n; i++) {
printf("%d ", array[i]);
}
printf("\n");
return 0;
}
である。では、結果。
- 乱数20000個のデータ列の場合
| quick_sort | merges_sort | ||||
|---|---|---|---|---|---|
| 1回目 | 2回目 | 3回目 | 1回目 | 2回目 | 3回目 |
| ---- | ---- | ---- | ---- | ---- | ---- |
| real 0m0.116s | real 0m0.115s | real 0m0.115s | real 0m0.114s | real 0m0.102s | real 0m0.115s |
| user 0m0.031s | user 0m0.031s | user 0m0.015s | user 0m0.000s | user 0m0.015s | user 0m0.015s |
| sys 0m0.000s | sys 0m0.000s | sys 0m0.015s | sys 0m0.062s | sys 0m0.015s | sys 0m0.031s |
- 降順の20000個のデータ列の場合
| quick_sort | merges_sort | ||||
|---|---|---|---|---|---|
| 1回目 | 2回目 | 3回目 | 1回目 | 2回目 | 3回目 |
| ---- | ---- | ---- | ---- | ---- | ---- |
| real 0m0.498s | real 0m0.482s | real 0m0.482s | real 0m0.115s | real 0m0.101s | real 0m0.102s |
| user 0m0.031s | user 0m0.000s | user 0m0.000s | user 0m0.015s | user 0m0.015s | user 0m0.015s |
| sys 0m0.031s | sys 0m0.015s | sys 0m0.015s | sys 0m0.032s | sys 0m0.015s | sys 0m0.000s |
今回実装した quick_sort() では、ピボットをデータ列の最初の値にしているため、降順(あるいは昇順)のデータ列だと、1個 vs 残り個数、で分割されてしまうので、quick_sort() は遅くなっている。
バブルソートで同じデータをソートしてみた。その結果はこちら。
| 乱数データ | 降順データ | ||||
|---|---|---|---|---|---|
| 1回目 | 2回目 | 3回目 | 1回目 | 2回目 | 3回目 |
| ---- | ---- | ---- | ---- | ---- | ---- |
| real 0m1.232s | real 0m1.195s | real 0m1.213s | real 0m0.896s | real 0m0.894s | real 0m0.874s |
| user 0m0.015s | user 0m0.015s | user 0m0.015s | user 0m0.031s | user 0m0.031s | user 0m0.031s |
| sys 0m0.000s | sys 0m0.046s | sys 0m0.015s | sys 0m0.015s | sys 0m0.015s | sys 0m0.031s |
バブルソートのコードはこちら。
void bubble_sort(int array[], int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < (n-1) - i; j++) {
if (array[j] > array[j+1]) {
int tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
}
}
}
}