GOとはgene ontologyの略で、遺伝子につけられるアノテーション。生物学的プロセス、細胞内の構成要素、分子機能とGOにはいくつか種類があり、一つの遺伝子は複数のGOを持つ。
PANTHERでGO解析
とある解析をして得られた酵母の遺伝子名のリスト sample_geneid.txt がある。
このリストに列挙された遺伝子名の機能には、酵母の全体と比較して偏りがあるのか調べる。
yal025c
yal038w
yal044c
yal061w
yar009c
・
・
・
PANTHER | http://www.pantherdb.org/
! 注意: ブラウザバックすると挙動が狂う
トップページでの操作 | サンプルのアップロードと解析方法
1.遺伝子名が列挙されたファイルをアップロードする。フォームに直接貼り付けても良い。
2.種名を選ぶ
3.解析方法を選ぶ。機能の偏りを見るときは statistical overrepresentation test
4.submit
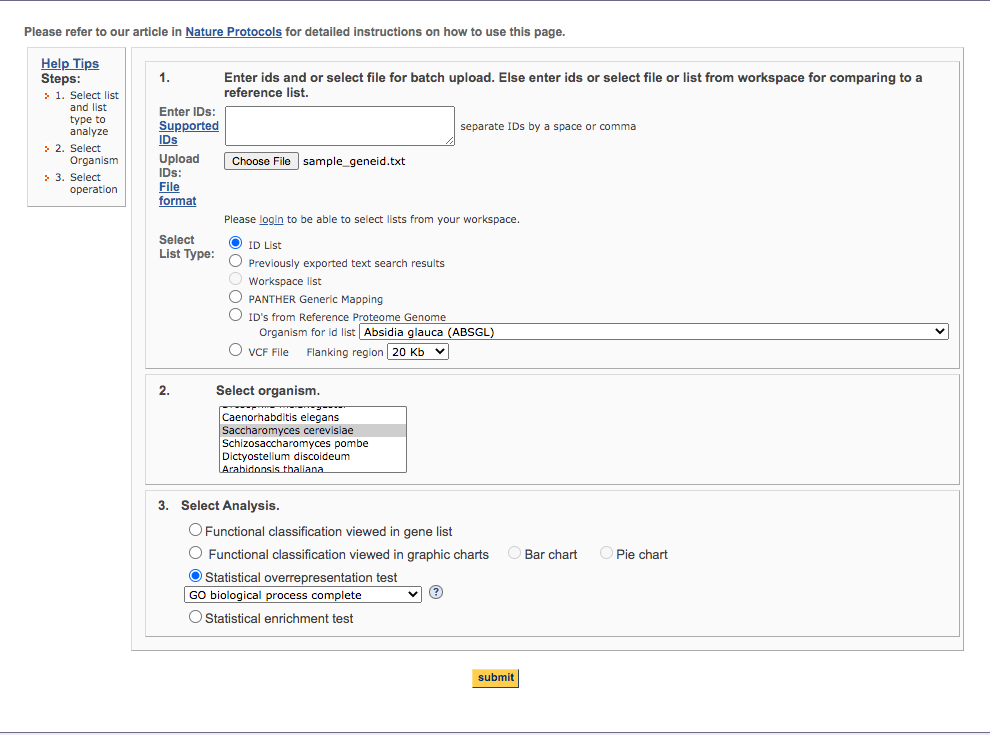
2ページ目 | reference list の選択

左側はデフォルトで良い。下か右上の方にreference list のアップロード欄がある。
reference list のGOとサンプルのリストのGOを比較してサンプルのGOの偏りを調べるので、基本はサンプルのリストと同じ種を選択する。
3ページ目 | テストのパラメータの設定
3ページ目ではデフォルトでLaunch analysisをする。

Test typeで検定の種類を選べる。Correctionはおそらく多重検定の方法で、FDRを用いるかボンフェローニ法で多重補正するかを選べる。
Launch analysis をした後に下のtableから結果をダウンロードできる。GOを記した長い文字列と数字のtsvになっててそのままだとわかりづらいが、だいたいこんな構造になってる。
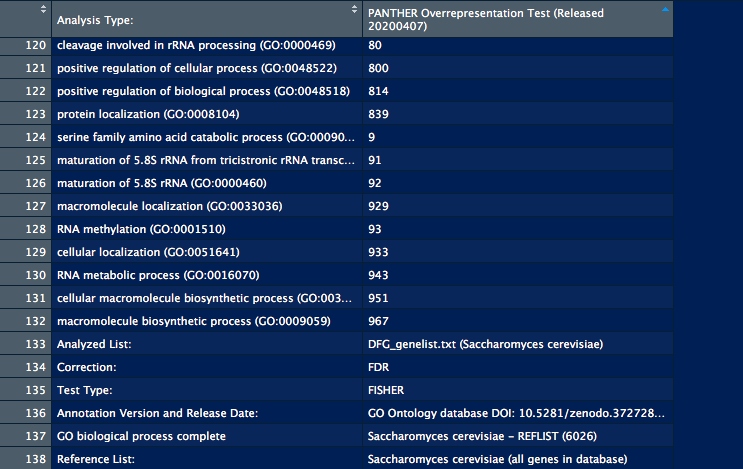
同ページでブラウザで結果を見れる。(ボンフェローニ法で多重補正した結果なのでFDR列はない )
1列目: Gene Ontology
2列目: そのGOに属するリファレンスリストの遺伝子数
3列目: そのGOに属するサンプルリストの遺伝子数
4列目: リファレンスリストから推定される、そのGOに属するサンプルリストの遺伝子数(期待値)
5列目: 観察値/期待値の値
6列目: 観察値が期待値より大きければ + 少なければ -

GO は完璧なアノテーションではないけど一つの理解として便利ですね。