長きにわたって OpenCV の Stitch モジュールについてコードリーディングを進めてまいります。こちらは最初の記事です。
全体の概要はこちらです。
https://qiita.com/itoshogo3/items/7a3279668b24008a3761
概要
入力となる画像達は配列として渡ってきますが、画像の順番はバラバラで完全にランダムなため、どれとどれが重なった領域を持つのか全くわかっていません。というわけで、まずはつながっている画像のペアを探るところからはじまります。

特徴点抽出
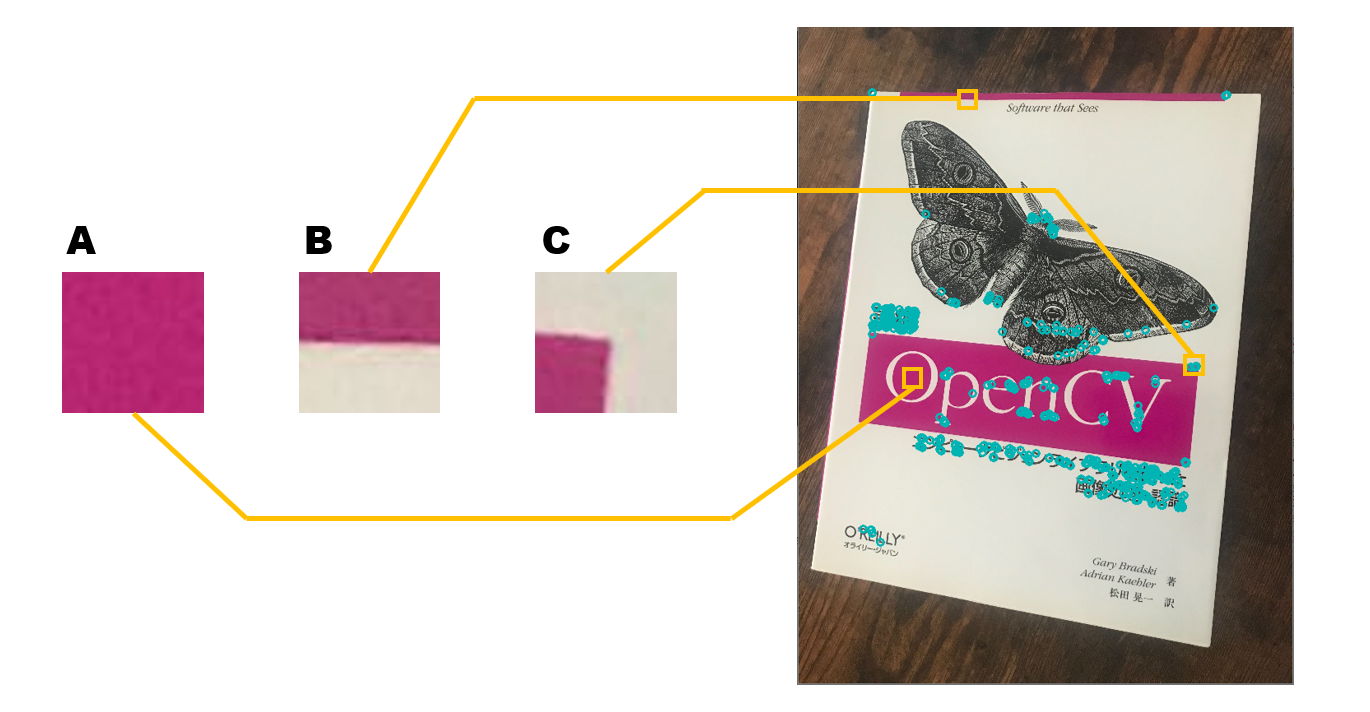
最初に画像の中から特徴点を抽出していきます。「特徴点」とは読んで字のごとく特徴を持った点で、他の点と区別できそうな点(ピクセル)のことを指します。そこでまずは「他の点と区別できそうな点」とはどんな点なのかを考えていきたいと思います。とりあえず下図をご覧ください。画像 A ~ C は右の画像から一部分を切り出したものとなっています。では、それぞれの画像がどの部分を切り出したものかを探してみて下さい。

A は全体的に均一すぎて何も取っ掛かりがありません。ピンク色の場所から切り出したということだけは分かりますが、それだけでは候補となる場所が多すぎます。B は被写体の端(エッジ)の部分が含まれているためなんとなく場所は分かりそうですが、やはり特定するのは難しそうです。C は被写体の角(コーナー)がわかりやすく写っているため切り出した場所をガッツリ特定できます。
以上のようなことから、特徴点としては画像のうちの角(コーナー)となっている部分が適していると言えます。もっと具体的に言うと、全方向に対して色の変化が大きい点、つまり周辺のピクセルとの値の差が大きい点が他の点と区別しやすく、「特徴点」にふさわしい点となるのです。OpenCV で検出した特徴点は下図のようになりました。

局所特徴量
続いては各画像で検出された特徴点を見比べていきますが、そのために「特徴量」なるものを計算します。「特徴量」とは特徴点の周辺のピクセルの情報も含んだ値で、計算方法はめちゃめちゃややこしいのですが、なんだかんだ多次元のベクトルの形で表されます。各画像から検出された特徴点は、その特徴量ベクトルの距離を比較することによって、実際に同じ場所かどうかあたりをつけることができます。
このような特徴点検出からの特徴量計算の流れには、これまでにいくつも手法が提案されており、コンピュータビジョンの分野でひとつの大きなトピックとなっていました。OpenCV でも feature2d module として様々な手法が実装されています。ちなみに stitch モジュールはデフォルトでは ORB という方法が使われています。特徴点の話というのはかなり奥が深く、細かく説明していると全然先に進めないので、ここで深く解説することはしませんが、興味を持った人のためにとりあえず良さげなリンクを貼っておきます。
-
OpenCV feature2d module
https://docs.opencv.org/4.3.0/d9/d97/tutorial_table_of_content_features2d.html
算出した特徴量同士を比較することによって、異なる画像に同じ点が写っているかどうかを判定することが出来るのです。

コードリーディング
ここまでで今回の前提知識がそろったので、コードリーディングを進めたいと思います。基本的には解説する部分のコードを張り付けていきますが、見やすさのためにログ出力のコードやあまり重要でないと思われる部分はザクっと削除したりしてます。逆にわかりにくいと思った場所や変数の説明等のために適当に日本語でコメントを追加したり、スペースや改行を加えたりしています。ですので、ここに貼るコードはオリジナルとはちょっと違うものになっているのであらかじめご承知おきください。詳細を知りたい方は本家の方を参照してください。
まずは全ての始まりである stitch() の中身がこちらです。
Stitcher::Status Stitcher::stitch(
InputArrayOfArrays images, /* 入力画像の配列 */
OutputArray pano /* 出力の合成画像 */ )
{
return stitch(images, noArray(), pano);
}
Stitcher::Status Stitcher::stitch(
InputArrayOfArrays images, /* 入力画像の配列 */
InputArrayOfArrays masks, /* マスク画像 */
OutputArray pano /* 出力の合成画像 */ )
{
Status status = estimateTransform(images, masks);
if (status != OK)
return status;
return composePanorama(pano);
}
第3引数のマスクあり版となし版の二つが用意されています。マスクの説明はもうちょっと後でやるので今は気にしないでください。マスクなし版で実行しても結局は下側の関数が呼び出されます。この時点ではすごくシンプルです。大きく二つのパートに分かれており、前半は estimateTransform() を実行して、オッケイだったら後半に composePanaoram() を実行しています。estimateTransform() は下記のようにさらに Stitcher::matchImages() と estimateCameraParams() という処理に分割されます。
Stitcher::Status Stitcher::estimateTransform(
InputArrayOfArrays images, /* 入力画像の配列 */
InputArrayOfArrays masks /* マスク画像 */ )
{
images.getUMatVector(imgs_);
masks.getUMatVector(masks_);
Status status;
if ((status = matchImages()) != OK)
return status;
if ((status = estimateCameraParams()) != OK)
return status;
return OK;
}
入力された画像とマスクを imgs_ と masks_ に UMat に変換してコピーしています。ちなみに語尾に "_" アンダースコアがつく変数は全てメンバ変数です。今回解説した場所はソースコードでいうと Stitcher::matchImages() の前半部分になります。
画像のリサイズ
入力する画像のサイズに制限はないので大きいのが入ってくる可能性があって、そのまま扱ってしまうと処理の負荷が重くなってしまいます。というわけで、まずは良い感じにリサイズします。下記がリサイズしている部分です。
// 各画像の特徴点
features_.resize(imgs_.size());
// 縫い目を探すために利用する画像
seam_est_imgs_.resize(imgs_.size());
// 入力画像のサイズ
full_img_sizes_.resize(imgs_.size());
// 特徴点を探すために利用する画像
std::vector<UMat> feature_find_imgs(imgs_.size());
// 特徴点を探すために利用するマスク
std::vector<UMat> feature_find_masks(masks_.size());
for (size_t i = 0; i < imgs_.size(); ++i)
{
full_img_sizes_[i] = imgs_[i].size();
// 特徴点探す用の画像のリサイズ
if (registr_resol_ < 0)
{
// リサイズしない
feature_find_imgs[i] = imgs_[i];
work_scale_ = 1;
is_work_scale_set = true;
}
else
{
// リサイズする
if (!is_work_scale_set)
{
work_scale_ = std::min(1.0, std::sqrt(registr_resol_ * 1e6 / full_img_sizes_[i].area()));
is_work_scale_set = true;
}
resize(imgs_[i], feature_find_imgs[i], Size(), work_scale_, work_scale_, INTER_LINEAR_EXACT);
}
// 縫い目探す用の画像のリサイズスケールを決める
if (!is_seam_scale_set)
{
seam_scale_ = std::min(1.0, std::sqrt(seam_est_resol_ * 1e6 / full_img_sizes_[i].area()));
seam_work_aspect_ = seam_scale_ / work_scale_;
is_seam_scale_set = true;
}
// マスクのリサイズ
if (!masks_.empty())
{
resize(masks_[i], feature_find_masks[i], Size(), work_scale_, work_scale_, INTER_NEAREST);
}
features_[i].img_idx = (int)i;
// 縫い目探す用の画像のリサイズ
resize(imgs_[i], seam_est_imgs_[i], Size(), seam_scale_, seam_scale_, INTER_LINEAR_EXACT);
}
for 文をまわして全画像に対して resize() を実行しています。ちょっとややこしくなっていますが、リサイズは画像一枚につき2回行っていて、ひとつは特徴点を探す用で feature_find_imgs に、もうひとつは縫い目探す用で seam_est_imgs_ にそれぞれ結果が格納されています。
registr_resol_ と seam_est_resol_ はリサイズ時に解像度をどれくらいまで落とすかという指標になっていて、これらの値をもとにリサイズスケールである work_scale_ と seam_scale_ の値が決定されます。resol は resolution の略で解像度のことですね。このあたりの変数はアンダースコアがついてるのでメンバ変数となりますが、ユーザーが自由に設定できるようにインターフェイスが提供されています。
CV_WRAP double registrationResol() const { return registr_resol_; }
CV_WRAP void setRegistrationResol(double resol_mpx) { registr_resol_ = resol_mpx; }
CV_WRAP double seamEstimationResol() const { return seam_est_resol_; }
CV_WRAP void setSeamEstimationResol(double resol_mpx) { seam_est_resol_ = resol_mpx; }
CV_WRAP double compositingResol() const { return compose_resol_; }
CV_WRAP void setCompositingResol(double resol_mpx) { compose_resol_ = resol_mpx; }
特徴点抽出&特徴量計算
続いて、次の一文で特徴点の抽出と特徴量の計算を一気に行います。
detail::computeImageFeatures(
features_finder_, /* 特徴点の検出器 */
feature_find_imgs, /* 入力画像の配列 */
features_, /* 特徴点の検出結果がここに出力される */
feature_find_masks /* マスク画像の配列 */ );
computeImageFeatures() の中身はこんなかんじです。
void computeImageFeatures(
const Ptr<Feature2D> &featuresFinder, /* 特徴点の検出器 */
InputArrayOfArrays images, /* 入力画像の配列 */
std::vector<ImageFeatures> &features, /* 特徴点の検出結果 */
InputArrayOfArrays masks /* マスク画像の配列 */ )
{
std::vector<std::vector<KeyPoint>> keypoints;
std::vector<UMat> descriptors;
featuresFinder->detect(images, keypoints, masks);
featuresFinder->compute(images, keypoints, descriptors);
size_t count = images.total();
features.resize(count);
for (size_t i = 0; i < count; ++i)
{
features[i].img_size = images.size(int(i));
features[i].keypoints = std::move(keypoints[i]);
features[i].descriptors = std::move(descriptors[i]);
}
}
detect() で特徴点の検出を行い結果を keypoints に格納します。続いてすぐさま compute() を実行して特徴量の計算行い、結果を descriptors に格納します。2行で書かれたこの処理の中身はかなり複雑なことをやっているのですが、こちらは別モジュールの機能なので今回はそこまで追っかけません。とりあえず OpenCV の機能を使えば簡単に特徴点が扱えるのでした。