はじめに
「ScratchでAIを学ぼう」の筆者です。この本では、初めての方でもきちんと分かることを目指し、ゲームを題材にしてQ学習を3段階で説明しました。
ここでは、その続編として、pythonで基本のQ学習、ニューラルネットの応用、また、多少実験的な試みになりますが、短期記憶ユニットであるLSTM/GRUの応用を紹介したいと思います。
使用するプログラムmemoryRLは、GitHubからダウンロードできます。GPUのない普通のPCでも短時間(長くても数分)で学習できることを想定しています。
まず、2つの例を見てください。
1つ目の例はmany_swamp と呼んでいるタスクです。ロボットを操作して、4つのゴール(青)を全て巡回できるとクリアとなり、エピソードが終わります。エピソード毎に壁とゴールの配置がランダムに変わります。アニメーションは、ニューラルネットを使ったQ学習(qnet)で学習させた結果です。

アニメーションの左側が環境全体を表しています。白黒の中央と右側の図は、実際に強化学習アルゴリズムが受け取る観測情報に対応します。観測情報は、2マス以内の周囲のゴール(中央)と壁(左)のパターンになります。
ロボットは2マスまでの周囲しか見えない設定なのですが、「壁はよける」、「ゴールに近づいたらそちらに曲がる」、「何もなければまっすぐ進む」、のようなアルゴリズムで動いているように見えます。このアルゴリズム自体を強化学習が作ったということです。マップはランダムに変わりますが、追加学習をすることなく対応しています。
ちなみに、この学習には、筆者の古いノートPCでも4分弱で終わりました (qnet, many_swamp, 33000 qstep, 3分40秒)。
※筆者のノートPCのCPUは、Intel Core i7-6600UでGPUなし。i7でも第6世代なので結構遅く、i5-7500Uの方が上のようです。 参考:CPU性能比較表 | 最新から定番のCPUまで簡単に比較
2つめの例は、Tmaze_either と呼んでいるタスクです。青のゴールにたどり着けばクリアなのですが、ゴールが観測情報から消えてしまいます。観測から消えてもゴールはあるので、ゴールの位置を覚えておいて正しい方向にT字路を曲がる必要があります。つまり短期記憶が必要なタスクです。

このような問題は通常のQ学習ではできませんが、短期記憶ユニットであるLSTMを組み入れたQ学習で解くことが可能となりました。
以上が2つの例の紹介になりますが、このmemoryRLプロジェクトでは、このタスクを含む7つのバリエーションのタスクを、4種類の強化学習エージェントで試すことができます。
この記事ではmemryRLの使い方をメインに紹介しますが、学習の原理、実装方法など、更に詳しい解説は、以下にまとめていますので参考にしてください。
http://itoshi.main.jp/tech/0100-rl/rl_introduction/
環境構築
ここでは、windows 10 を想定し、pythonでmemoryRLを動かすための環境構築を説明します。
Anaconda インストール
まず、pythonをするための基本環境として、anaconda をインストールします。
以下の記事が参考になります。
Windows版Anacondaのインストール
仮想環境作成
次に、特定のpythonのバージョンやモジュールのバージョンの環境を設定するために、conda で仮想環境を作成します。
仮想環境について詳しく知るためには以下が参考になります。
【初心者向け】Anacondaで仮想環境を作ってみる
python japan, Conda コマンド
スタートメニューからAnaconda Powershell Prompt を立ち上げます。
以下のコマンドで、mRLという名前の仮想環境をpython3.6 で作成します(mRLでなくてもよいですが、ここではmRLとして進めていきます)。
(base)> conda create -n mRL python=3.6
以下で、mRLをアクティベートします(仮想環境に入る)。
(base)> conda activate mRL
tensorflow, numpy, h5py をバージョン指定でインストールします。
(mRL)> pip install tensorflow==1.12.0 numpy==1.16.1 h5py==2.10.0
opencv-pythonとmatplotlib は、最新のバージョンでインストールします。
(mRL)> pip install opencv-python matplotlib
今後、この仮想環境 mRL に入ることで(> conda activate mRL)、今インストールしたモジュール(ライブラリ)の環境で、プログラムを動かすことができます。
memoryRLのダウンロードと展開
gitが使える方は、以下のコマンドでクローンすれば完了です。
(mRL)> git clone https://github.com/itoshin-tech/memoryRL.git
以下、git を使っていない人用の説明です。
ブラウザで、次ののURLに行きます。
https://github.com/itoshin-tech/memoryRL
Code から、Download zip を選び、PCの適当な場所に保存して解凍すると、memoryRL-master というフォルダが作られます
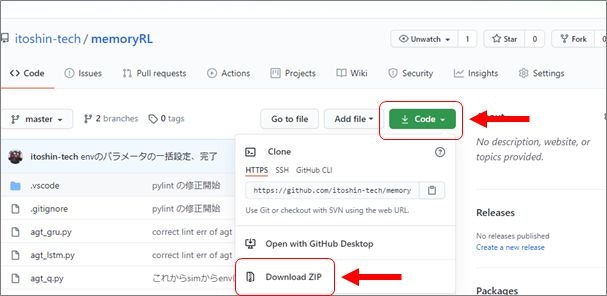
これで準備OKです。
memoryRLの実行
memoryRLを解凍して作成されたフォルダーに入ります。
(mRL)> cd C:\解凍した位置のパス\memoryRL-master\
sim_swanptour.py を以下のコマンドで実行します。
(mRL)> python sim_swanptour.py
すると以下のように使い方が表示されます。
---- 使い方 ---------------------------------------
3つのパラメータを指定して実行します
> python sim_swanptour.py [agt_type] [task_type] [process_type]
[agt_type] : q, qnet, lstm, gru
[task_type] :silent_ruin, open_field, many_swamp,
Tmaze_both, Tmaze_either, ruin_1swamp, ruin_2swamp,
[process_type] :learn/L, more/M, graph/G, anime/A
例 > python sim_swanptour.py q open_field L
---------------------------------------------------
説明にあるように、python sim_swanptour.py の後に3つのパラメータをセットして使います。
agt_type とtask_type については後ほど図解しますが、パラメータの説明は以下のようになります。
| [agt_type] | 強化学習のアルゴリズム |
|---|---|
| q | Q学習 |
| qnet | ニューラルネットを使ったQ学習 |
| lstm | LSTMを使った短期記憶付きQ学習 |
| gru | GRUを使った短期記憶付きQ学習 |
| [task_type] | タスクのタイプ。 全てのタスクにおいて全ての青いゴールに辿り着けばクリア |
|---|---|
| silent_ruin | マップ固定、ゴール数2。 |
| open_field | 壁なし、ゴール数1。ゴールの位置はランダムに変わる。 |
| many_swamp | 壁あり、ゴール数4。配置がランダムに変わる。 |
| Tmaze_both | T迷路。短期記憶が必要。 |
| Tmaze_either | T迷路。短期記憶が必要。 |
| ruin_1swamp | 壁あり、ゴール数1。 |
| ruin_2swamp | 壁あり、ゴール数2。高難易度。 |
| [process type] | プロセスの種類 |
|---|---|
| learn/L | 初めから学習する |
| more/M | 追加学習をする |
| graph/G | 学習曲線を表示する |
| anime/A | タスクを解いている様子をアニメーションで表示 |
では、具体的に、qnet (ニューラルネットを使ったQ学習) に many_swamp のタスクを学習させる場合を説明します。
学習を開始するので、最後のパラメータは、more か Lにします。
(mRL)> python sim_swanptour.py qnet many_swamp L
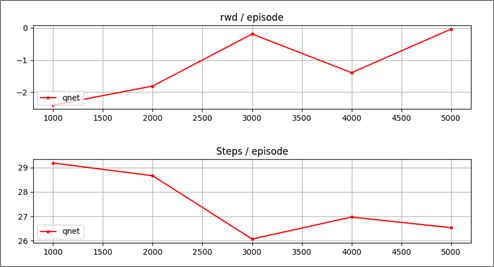
すると、以下のようにコンソールに学習過程の評価が表示され、全5000 stepの学習が行われます。
qnet many_swamp 1000 --- 5 sec, eval_rwd -3.19, eval_steps 30.00
qnet many_swamp 2000 --- 9 sec, eval_rwd -0.67, eval_steps 28.17
qnet many_swamp 3000 --- 14 sec, eval_rwd -0.21, eval_steps 26.59
qnet many_swamp 4000 --- 18 sec, eval_rwd -1.27, eval_steps 28.72
qnet many_swamp 5000 --- 23 sec, eval_rwd -1.29, eval_steps 28.90
1000回に1回、評価のプロセスがあり、そこで、eval_rwdとeval_stepが計算されます。eval_rwd は、その時の1エピソード中の平均報酬、eval_steps は平均step数です。評価プロセスでは、学習を停止し、行動選択のノイズも0にした状態で、100回のエピソードを行って平均を出しています。
eval_rwdやeval_step を指標として学習が目標値に進んだときにも学習は終了するようになっています(EARY_STOP)。目標値はタスク毎に設定されています。
最後に以下のような学習過程のグラフ(eval_rwd, eval_steps)が表示されます。
[q]を押すとグラフが消え終了します。
学習の結果後の動作アニメーションを見るには、最後のパラメータをanime か Aにします。
(mRL)> python sim_swanptour.py qnet many_swamp A
すると、以下のようなアニメーションが表示されます。

100エピソードが終わると終了します。[q]を押すと途中終了します。
アニメーションを見ると、適切に動けていなことが分かります。まだ学習が足りないのです(アニメーションの中央から右側の白黒の図はエージェントへの入力を表しています)。
そこで、追加学習します。最後のパラメータをmore か Mにして実行します(初めから学習する場合は L を使います)。
(mRL)> python sim_swanptour.py qnet many_swamp M
このコマンドを数回繰り返します。EARY_STOPが表示されて途中終了すると、学習が良いところまで進んだといえます。many_swampは、eval_rwd が1.4以上または、eval_steps が22以下になるとEARY_STOPとなります。
qnet many_swamp 1000 --- 5 sec, eval_rwd 0.55, eval_steps 24.25
qnet many_swamp 2000 --- 9 sec, eval_rwd 0.92, eval_steps 23.52
qnet many_swamp 3000 --- 14 sec, eval_rwd 1.76, eval_steps 21.69
EARY_STOP_STEP 22 >= 21
グラフが最後に表示されます。エピソード当たりの報酬(rwd)が増加し、ステップ数(Steps)が減少していることから、学習が進んでいたことが分かります。
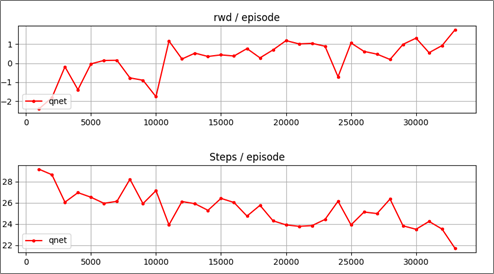
アニメーションを見てみましょう。
(mRL)> python sim_swanptour.py qnet many_swamp A
たまに失敗しますが、だいたいうまくいっているようです。

今までに学習させたグラフを表示するには、最後のパラメータをgraph か Gにします。
(mRL)> python sim_swanptour.py qnet many_swamp G
以上がsim_swamptour.py(池巡り)の使い方の説明です。
強化学習アルゴリズムの種類
[agt_type] で指定できる強化学習アルゴリズム(エージェント)は、 q, qnet, lstm, gru の4種類です。ここではその特徴を簡単に説明します。
q:通常のQ学習
基本のQ学習アルゴリズムです。各観察に対して各行動のQ値を変数(Qテーブル)に保存し、更新していきます。観測値は500個まで登録できる設定にしています。それ以上のパターンが観測されたらメモリーオーバーで強制終了となります。

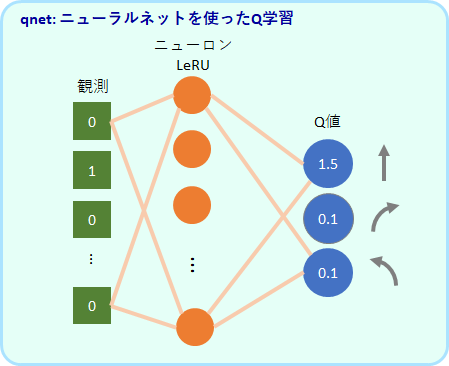
qnet:ニューラルネットを使ったQ学習アルゴリズム
ニューラルネットワークでQ値を出力するよう学習します。入力は観測値で、出力は3つ値です。この3つの値が各行動のQ値に対応します。中間層は64個のReLUユニットです。
未知の観測値に対してもQ値を出力することができます。
lstm/gru: 記憶ユニットを使ったQ学習アルゴリズム
過去の入力にも依存した反応が可能な記憶ユニット(LSTM または GRU)を加えたモデルです。LSTMを使ったアルゴリズムをlstm、GRUを使ったアルゴリズムをgruとしています。
qやqnetは、観測値が同じであれば同じ行動しか出力することしかできませんが、lstmやgruはモデルは、過去の入力が異なれば今の観測値が同じでも異なる行動を出力することが原理的に可能です。
LSTMは自然言語処理のモデルでもよく使用されている記憶ユニットです。GRUはLSTMをシンプルにしたモデルです。
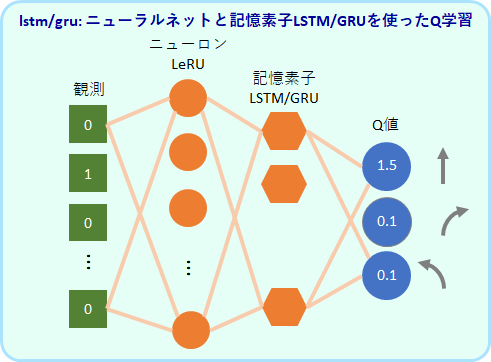
LeRU を64個、LSTMまたはGRU を32個を使用しています。
タスクの種類
[task_type] で指定できるタスクは、silent_ruin, open_field, many_swamp, Tmaze_both, Tmaze_either, ruin_1swamp, ruin2swamp の7種類です。ここではその特徴を簡単に説明します。
全タスクで共通のルール
全てのタスクで共通しているのは、ロボットが全てのゴール(青のマス)に訪れたらクリア、というルールです。
アルゴリズムが受け取る情報は、ロボットを中心とした、限られた視野におけるゴールと壁の情報です。各タスクの図の、右側の白黒の図がその情報に対応します。
報酬は、初めてのゴールにたどり着くと+1.0、壁に当たると-0.2、それ以外のステップで-0.1となります。
silent_ruin
ゴールは2か所ありますが、マップは常に同じです。そのために、観測のバリエーションは限られており、q でも学習が可能です。

open_field
壁はありませんが、ゴールの場所はエピソード毎にランダムに変わります。しかし、壁がないので観測のバリエーションは限られており、qでも学習が可能です。

many_swamp
ゴールと壁の位置がエピソード毎にランダムに決まるために、観測のバリエーションが多く、qではメモリーオーバーとなってしまい学習ができません。qnet での学習が可能です。

Tmaze_both
普通の強化学習ではできない問題です。
マップは固定ですが、片方のゴールにたどり着くと、スタート地点に戻されます。そして、訪れたゴールも見えたままです。この状態で、次は別な方のゴールに進まなければなりません。
スタート地点にロボットがいるとき、スタート直後でも、片方のゴールに訪れた後でも同じ観測となります。そのために、同じ観測に対して同じ行動しか選べないqやqnet は、適切な行動を学習種ることができません。過去の履歴で行動を変えることができる gru と lstm のみが学習可能です。

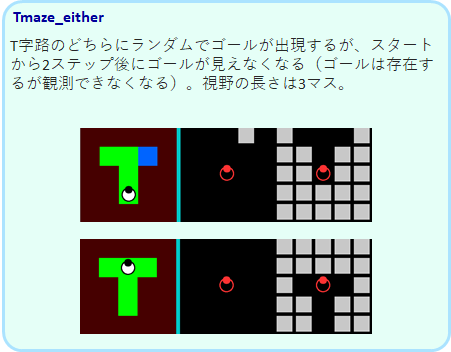
Tmaze_either
このTmazeは、左右のどちらかでゴールが出現しますが、2ステップ後にゴールが見えなくなります。
ロボットは2ステップでT迷路の分岐路に来ることになりますが、ゴールが見えていた方を覚えておき、そちらに向かうことが必要です。このタスクも、qやqnet ではできません。gruとlstmのみが学習可能です。
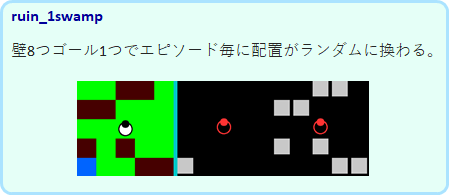
ruin_1swamp
壁が8個、ゴールは1つで、配置がランダムに変わります。回り込んでゴールにたどり着かなければならない場合もあり難易度は高めです。
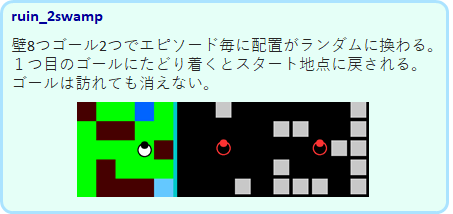
ruin_2swamp
最高難易度のタスクです。ゴールは2つで、片方にたどり着くとスタート地点に戻されます。ゴールは訪れても消えません。Tmaze_both のランダムバージョンのようなタスクです。gruやlstmでも満足にはできませんでした。
ゴールを更に増やしたりフィールドを大きくすることで、更に難易度を上げることができます。将来このようなタスクでもしっかり解けるような強化学習アルゴリズムを開発したいものです。
参考
この記事ではmemryRLの使い方をメインに紹介しましたが、学習の原理、実装方法など、更に詳しい解説は、以下にまとめていますので参考にしてください。
http://itoshi.main.jp/tech/0100-rl/rl_introduction/