Intro
![]()
elasticsearchへのデータ収集あれこれを調べていてelasticのサイトみていたら
http://streamsets.com/
https://www.elastic.co/blog/elasticsearch-plus-streamsets-reliable-data-ingestion
素晴らしそうなプロダクトがありましたので備忘と紹介のためメモしたものです。
何となく概要
多分大きな間違いがあるかとは思いますが何となくまとめてみました。
GUIでデータの入力/変換/出力をつなげていってデータモデリング/収集ができるツールです。
動画みたほうがわかりやすいです。
これだけあれば収集、何でもできるぜ。って感じがします。
| 主な登場人物 | 説明 |
|:-----------|:------------|:------------|
| origins | データ入力元 |
| destination | データ出力先 |
| processor | 変換処理を行うもの |
| pipeline | これらをつなげたもの |
詳細はhttp://streamsets.com/documentation/datacollector/1.1.3/help/に記載されてます。
これらをつなぎ合わせてデータ変換を行い最終的にdestinationへデータを出力していきます。
この画像わかりやすかったのでネットから拝借。
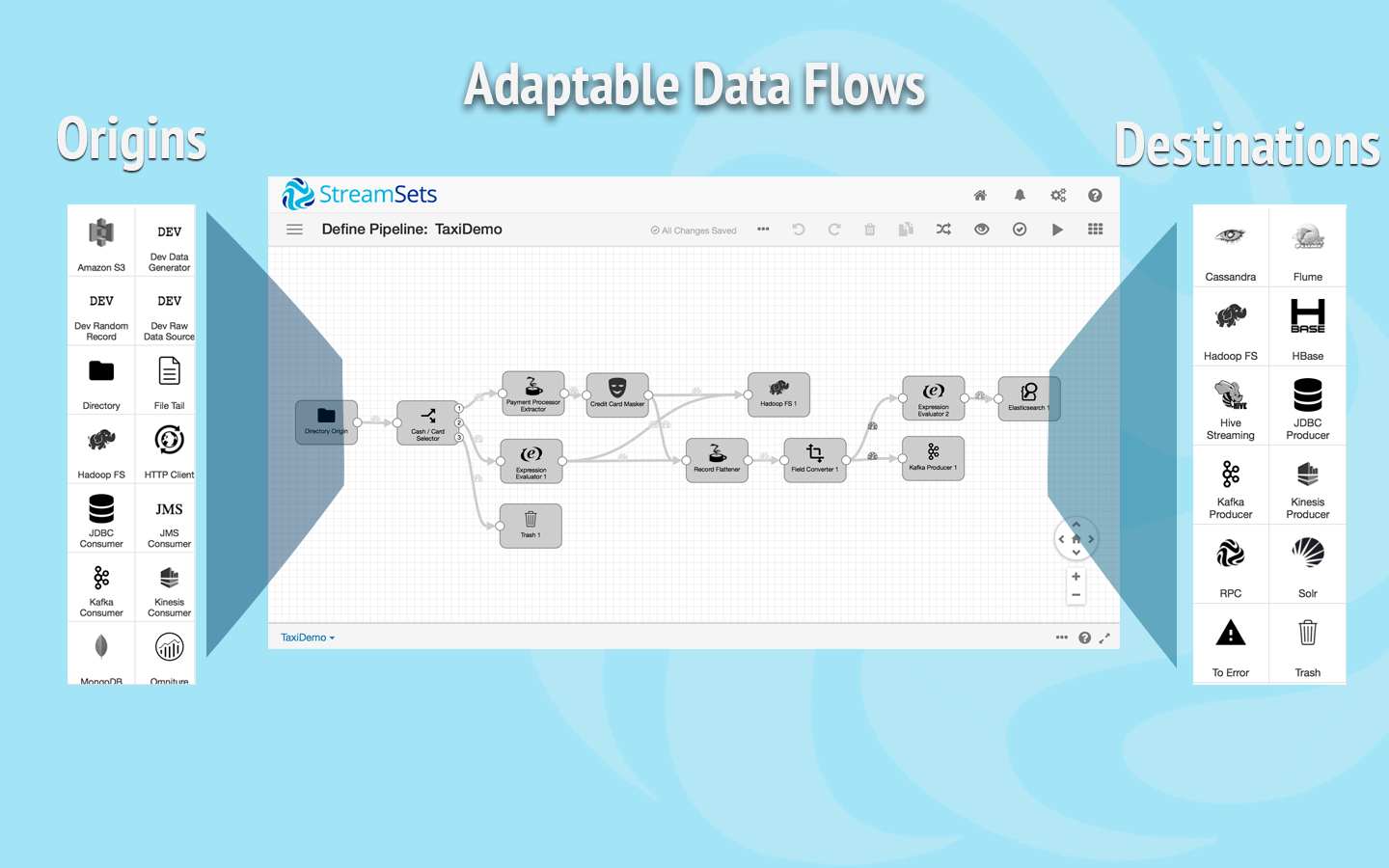
originsが現時点では下記のものがあります。すごい。
- Amazon S3 - Reads files from Amazon S3.
- Directory - Reads fully-written files from a directory.
- File Tail - Reads lines of data from an active file after reading related archived files in the directory.
- HTTP Client - Reads data from a streaming HTTP resource URL.
- JDBC Consumer - Reads database data through a JDBC connection.
- JMS Consumer - Reads messages from JMS.
- Kafka Consumer - Reads messages from Kafka.
- Kinesis Consumer - Reads data from Kinesis.
- MongoDB - Reads documents from MongoDB.
- Omniture - Reads web usage reports from the Omniture reporting API.
- RPC - Reads data from an RPC destination in an RPC pipeline.
- UDP Source - Reads messages from one or more UDP ports.
- In cluster pipelines, you can use the following origins:
- Hadoop FS - Reads data from the Hadoop Distributed File System (HDFS).
- Kafka Consumer - Reads messages from Kafka. Use the cluster version of the origin.
destinationも。ぐへへ
- Cassandra - Writes data to a Cassandra cluster.
- Elasticsearch - Writes data to an Elasticsearch cluster.
- Flume - Writes data to a Flume source.
- Hadoop FS - Writes data to the Hadoop Distributed File System (HDFS).
- HBase - Writes data to an HBase cluster.
- Hive Streaming - Writes data to Hive.
- JDBC Producer - Writes data to JDBC.
- Kafka Producer - Writes data to a Kafka cluster.
- Kinesis Producer - Writes data to a Kinesis cluster.
- RPC - Passes data to an RPC origin in an RPC pipeline.
- Solr - Writes data to a Solr node or cluster.
- To Error - Passes records to the pipeline for error handling.
- Trash - Removes records from the pipeline.
processorも。うほほ。
- Expression Evaluator - Performs calculations and appends the results to the record.
- Field Converter - Converts the data type of a field.
- Field Hasher - Uses an algorithm to encode sensitive string data.
- Field Masker - Masks sensitive string data.
- Field Merger - Merges fields in complex lists or maps.
- Field Remover - Removes fields from a record.
- Field Renamer - Renames fields in a record.
- Field Splitter - Splits the string values in a field into different fields.
- Geo IP- Provides geographic location information based on an IP address.
- JavaScript Evaluator - Processes records based on custom JavaScript code.
- JSON Parser - Parses a JSON object embedded in a string field.
- Jython Evaluator - Processes records based on custom Jython code.
- Log Parser - Parses log data in a field based on the specified log format.
- Record Deduplicator - Removes duplicate records.
- Stream Selector - Routes data to different streams based on conditions.
- Value Replacer - Replaces null values or replaces values with nulls
環境
centos6.5
Installと起動
公式のインストール手順を参考にtarballから入れてみました。展開して起動するだけ。
curl -O https://archives.streamsets.com/datacollector/1.1.4/tarball/streamsets-datacollector-1.1.4.tgz
tar -xvzf streamsets-datacollector-1.1.4.tgz
cd streamsets-datacollector-1.1.4
./bin/streamsets dc #これで起動
起動後
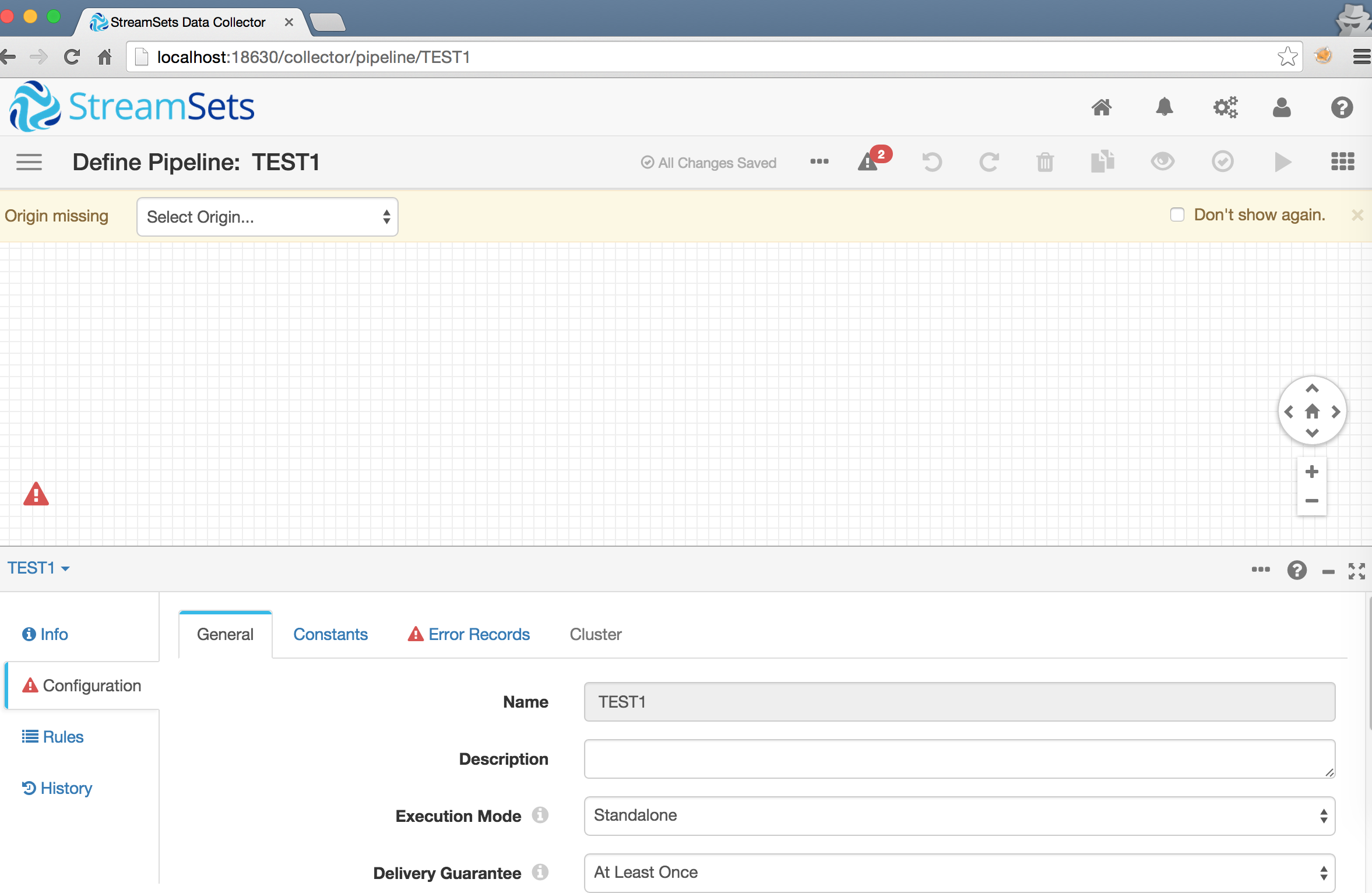
ログイン後、新規パイプラインをつくるとこんな画面がでるはず。あとは直感でいじれます(はず)。
感想
アプリログの収集とかRDBMSのパフォーマンスデータ毎時収集とか
fluentdとかでがんばって設定書いて集めてましたがそれが悲しくなるくらい簡単でした。
- MongoDB -> ElasticSearch
- JDBC(MySQL/Postgres/SQLServer) -> ElascicSearch
- ElasticSearch -> ElasticSearch
など試しましたがあっさり動いてくれました。
(SQLServerやOracleなどベンダーもの別途JDBCdriverの配置、設定が必要です)
origin側はPKやIDをOffset設定すれば差分(Appendのみ)更新が可能なのでそれも素晴らしいです。
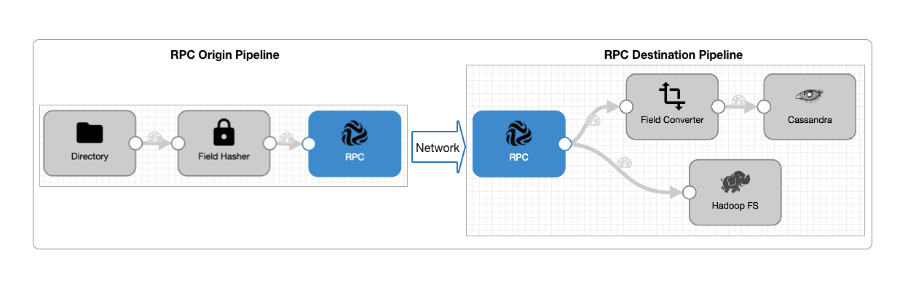
面白いのはRPC PipeLineと言うもので別インスタンスのstreamsetsへデータがながせたりするのも
アグレッシブだなーとおもいました。
http://streamsets.com/documentation/datacollector/1.1.3/help/#RPC_Pipelines/RPCpipeline.html#concept_lnh_z3z_bt
今後いろんな機能が拡張されていくと思うのでかなり期待しています。
データ分析などで一時データを集めたりする用途にはばっちりだなと感じました。
補足
今後つかっていって随時更新していきます。