はじめに
2023年5月18日 に CyberAgent がリリースした日本語 LLM であるの Open-CALM が Twitter や AI 系ニュースで大変話題になっています。
Twitter 上でも試してみたというツイートが多く見られます。
構築
OpenCALM を Oracle Cloud 上で動かすに当たり、以下の2つがありますが、今回は IaaS 上に NVIDIA A10 インスタンスを作成しそこで環境を構築したいと思います。
- Data Sience (Jupyter Notebook 環境)
- IaaS 上の GPU インスタンス
インスタンス作成
インスタンスの作成手順は省きますが、Shape として VM.GPU.A10.1 という NVIDIA A10 を1枚搭載したインスタンスを選択しました。また OS は Ubuntu 22.04 とします。
注意点としてはこの Ubuntu 22.04 には NVIDIA Driver が含まれておりません。インスタンス起動後に別途インストールする必要があります。
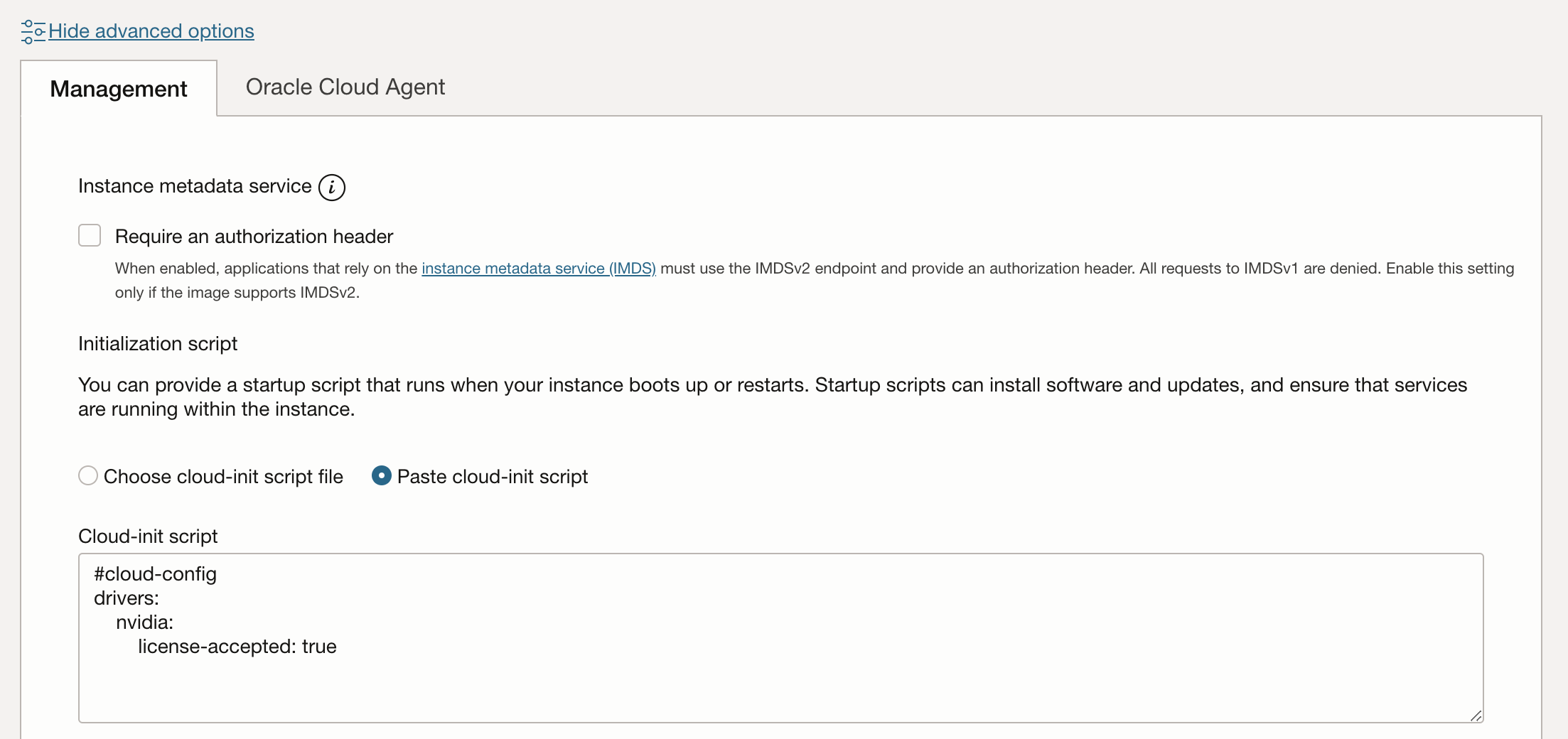
インスタンス作成時に advanced options の Cloud-init script に以下を追加します。
#cloud-config
drivers:
nvidia:
license-accepted: true
ドライバインストール
インスタンスが作成できたら ubuntu ユーザで SSH でログインし、 NVIDIA Driver をインストールしていきます。
cloud-init のステータス が status: done になっていることを以下コマンドで確認します。
cloud-init status
以下コマンドで NVIDIA Driver をインストールします。
sudo apt install nvidia-utils-525-server
reboot をする。
sudo reboot
再度、SSH でログインし直してドライバがインストールされたことを確認します。
$ nvidia-smi
Wed May 17 15:01:13 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10 Off | 00000000:00:04.0 Off | 0 |
| 0% 33C P0 50W / 150W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
事前インストール
OpenCALM を動かすために必要なものをインストールしていきます。
pip をインストールします。
sudo apt install -y python3-pip
pip で以下のインストールをします。
pip install -U transformers torch
pip install accelerate
以上で準備は完了です。
実行
それでは https://huggingface.co/cyberagent/open-calm-7b に書かれている通りに進めていきます。
ここでは以下のようにファイルを作成し、
vi OpenCALM-7B.py
以下のようにします。入力に世界で一番高い山はエベレスト。日本で一番高い山は、として続きの文章を生成させます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-7b", device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-7b")
inputs = tokenizer("世界で一番高い山はエベレスト。日本で一番高い山は、", return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
以下のように実行します
python3 OpenCALM-7B.py
出力結果。初回実行はモデルのダウンロードが行われるため時間が掛かりますが、こはクラウドなので1分30秒前後で完了です。
ubuntu@instance-20230518-0045:~$ time python3 test.py
Downloading (…)lve/main/config.json: 100%|███████████████████████████████████████████| 611/611 [00:00<00:00, 4.94MB/s]
Downloading (…)model.bin.index.json: 100%|████████████████████████████████████████| 42.0k/42.0k [00:00<00:00, 291kB/s]
Downloading (…)l-00001-of-00002.bin: 100%|████████████████████████████████████████| 9.93G/9.93G [00:39<00:00, 249MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|████████████████████████████████████████| 3.95G/3.95G [00:15<00:00, 261MB/s]
Downloading shards: 100%|███████████████████████████████████████████████████████████████| 2/2 [00:55<00:00, 27.82s/it]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████| 2/2 [00:07<00:00, 3.70s/it]
Downloading (…)neration_config.json: 100%|███████████████████████████████████████████| 116/116 [00:00<00:00, 1.17MB/s]
Downloading (…)okenizer_config.json: 100%|███████████████████████████████████████████| 323/323 [00:00<00:00, 4.43MB/s]
Downloading (…)/main/tokenizer.json: 100%|███████████████████████████████████████| 3.23M/3.23M [00:00<00:00, 3.67MB/s]
Downloading (…)cial_tokens_map.json: 100%|███████████████████████████████████████████| 129/129 [00:00<00:00, 1.36MB/s]
世界で一番高い山はエベレスト。日本で一番高い山は、富士山になるはずです。ところが、世界には富士山よりもはるかに高い山があります。それが、カンチェンジュンガです。カンチェンジュンガはヒマラヤ山脈の中央部にあった山ですが、近年、標高8,586.05mという、富士山よりも高い山であることが分かりました。カンチェンジュンガは、ヒマラヤ山脈の最高
2回目以降は20秒前後で出力されます。
$ time python3 OpenCALM-Large.py
世界で一番高い山はエベレスト。日本で一番高い山は、標高3,856メートルの富士山です。
富士山は、標高3,776メートルで日本の最高点であり、標高3,776メートルの日本最高峰です。
1,820メートルから、富士山を見上げると、山頂の断崖絶壁がはっきり見え、富士山が2つの山
real 0m18.142s
user 0m9.532s
sys 0m4.400s
GPU 使用率について
A10 は 24GB のメモリを搭載しています。
open-calm-7b で今回のケースでは GPU メモリを約2.8GB ほど消費していました。
GPU 利用率はピークで約30%でした。
$ nvidia-smi -l 1 --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv
utilization.gpu [%], utilization.memory [%], memory.total [MiB], memory.free [MiB], memory.used [MiB]
0 %, 0 %, 23028 MiB, 22547 MiB, 0 MiB
0 %, 0 %, 23028 MiB, 22547 MiB, 0 MiB
0 %, 0 %, 23028 MiB, 22535 MiB, 12 MiB
3 %, 0 %, 23028 MiB, 21923 MiB, 624 MiB
29 %, 2 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
0 %, 0 %, 23028 MiB, 20169 MiB, 2378 MiB
4 %, 0 %, 23028 MiB, 19777 MiB, 2770 MiB
28 %, 14 %, 23028 MiB, 19761 MiB, 2786 MiB
13 %, 6 %, 23028 MiB, 19749 MiB, 2798 MiB
0 %, 0 %, 23028 MiB, 22547 MiB, 0 MiB
他の GPU との比較
V100 でも同じ内容を実行してみました。
処理時間としては約40秒で A10 の約20秒の倍ほど掛かっていました。
$ time python3 OpenCALM-Large.py
世界で一番高い山はエベレスト。日本で一番高い山は、岐阜県の白山である。日本一高い山は、標高5,982mの日本アルプスである。
ちなみに世界で一番高い山は、エベレストである。
日本で一番高い山は、岐阜県の白山である。
日本で一番高い山は、岐阜県の白山である。日本の最も高い山は、標高5,967m
real 0m40.322s
user 0m10.706s
sys 0m4.869s
最後に
こういったモデルを動かすに当たりシンプルかつ迅速にとなると Jupyter Notebook 環境になると思いますが、今回のような クラウド IaaS 上での構築と動作でも30分前後で行うことができました。
クラウドならインターネット上の帯域も十分なので、比較的大きなファイルのダウンロードも苦にはならないのも良いですね。また大量のデータを扱う上でもファイルシステムを簡単に拡張できたり、Object Storage を利用したりとメリットがあると考えています。
今回はまず動かしてみるというところでしたが、今後はファインチューニングについてもチャレンジしたいと思います。