アップデート情報
- GH200の結果を追加
1. 背景・目的
NVIDIAのGPUは毎年新しいモデルがリリースされ、機械学習や推論の性能向上が謳われています。
それらを眺めながら「実際はどのくらいの性能向上なんだろうか?」と興味を持つ人は多いのではないでしょうか。
またコンシューマー系のRTXも性能が良くなってきており、データセンター系との性能差はどのくらいなのだろう、というのも気になります。
タイトルにある通り、RTXから最新のB200までのGPUについて性能の感覚値を持っておきたいと思い、この性能比較を実施しました。
2. 比較対象GPUのスペック一覧
今回対象としたGPUは以下です。
お仕事的に身近なデータセンターで学習向けや推論向け、またワークステーションで利用されるプロフェッショナル向け、コンシューマーでゲーム向けなどから気になるGPUをピックアップしてみました。
| カテゴリ | GPU |
|---|---|
| コンシューマー向け | RTX 4090 |
| RTX 5090 | |
| プロ向け | RTX 6000 Ada |
| RTX PRO 6000 | |
| データセンター向け | L4 |
| L40S | |
| A100 (SXM 80GB) | |
| H100 (SXM) | |
| H200 (SXM) | |
| B200 |
3. ベンチマーク環境の準備
これだけのGPUを現物で準備することはできないのでクラウドを利用します。
今回利用したのはRunpodで、上記に挙げたさまざまなクラスのGPUを1つからDockerイメージと組み合わせて利用できます。
今回の用途を考えると、ラインナップ、コスト、利用しやすさから選定しました。
特に最新のB200を1GPUから気軽に使えるのは私が調べた限りではRunpodだけでこれが決定的でした。
RunpodにはSecure CloudとComunity CloudのどちらかからGPUを選択できます。
■ Secure Cloud
- Runpod が厳選したパートナー企業の Tier-3/Tier-4 データセンター上で稼働
- 電源・ネットワークともに冗長化されており、高い可用性・安定性を担保
- エンタープライズや機密性の高いワークロードに最適と推奨
■ Community Cloud
- グローバルの個人や小規模事業者が提供するピアツーピア型インフラ
- ホストは招待制で厳選(vetted)され、Runpod の品質基準をクリアしているが、電源・ネットワークの冗長性は Secure Cloud より抑えめ
- “分散型” の特性を活かしてコストを抑えたい場合に向いている
今回の検証では性能の安定性という観点でSecure Cloudを利用しています。ただSecure Cloudには存在しないコンシューマー向けGPUについてはCommunity Cloudを利用しました。
4. ベンチマーク方法
■ ハードウェア関連
- GPU Type: 上記
2. 比較対象GPUのスペック一覧の通り - GPU数:
1
GPU数の1については、GPU単体の性能をなるべく確認したいのと、自腹なのでコスト的なのもあります😅
■ ソフトウェア関連
Runpodオフィシャルのコンテナイメージを提供しておりますので、それを利用します。
具体的にはRunpod Pytorch 2.4.0というもので各verは以下のようになっています。
- OS:
Ubuntu 22.04 - CUDA:
12.4.1 - Python:
3.11 - Pytorch:
2.4.0
■ 学習関連
学習コード: Llama-cookbook
LLM: TinyLlama-1.1B-Chat-v1.0 / Llama-3.1-8B-Instruct
データセット: Alpaca
■ 計測方法
これで1エポックだけ学習し、その所要時間を計測します。
またGPUによってはFP8やFP4なども最新のGPUではサポートしていてそれにより性能向上が謳われていますが、それらへの個別の対応は実施せず、デフォルト(BF16)での計測となります。
5. 結果
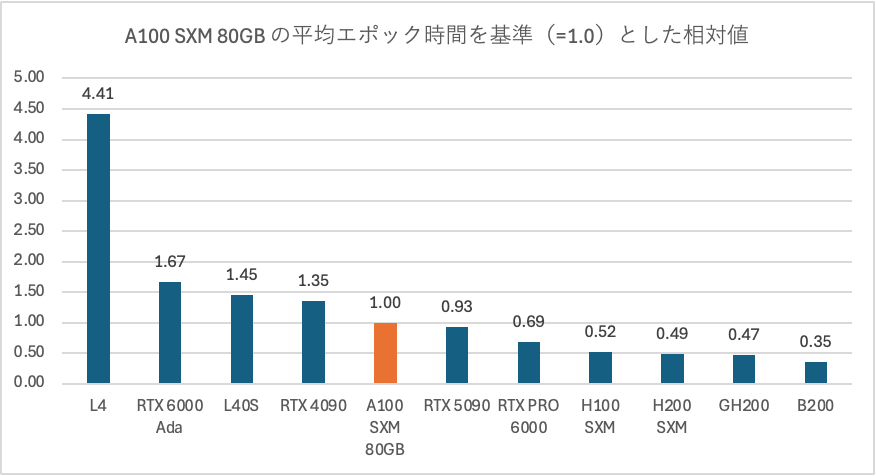
複数のGPUで試しましたが、A100 SXM(80GB)を基準(1.0)としての相対値でまとめてみました。
■ TinyLlama-1.1B-Chat-v1.0
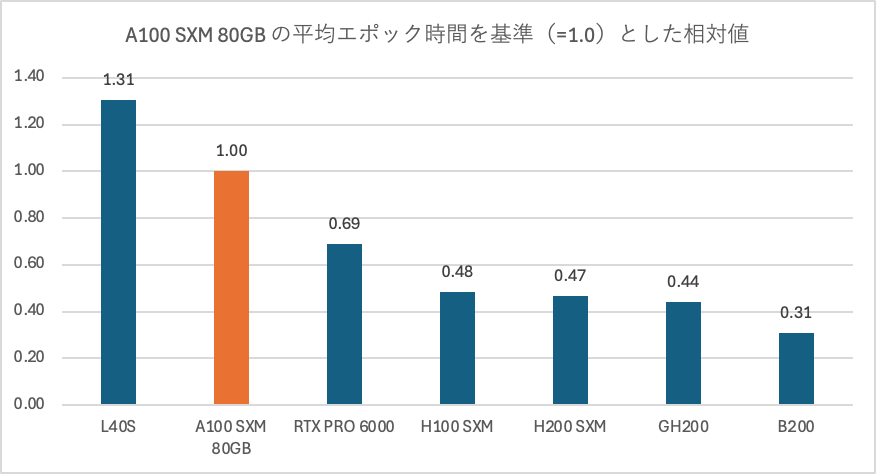
■ Llama-3.1-8B-Instruct
※8Bモデルを動かすにおいて48GB以上搭載のGPUを対象としました
また、以下は各GPUのBF値とメモリ帯域を調べたものです。
| GPUモデル | アーキテクチャ | BF16 TFLOPS | メモリ帯域 GB/s |
|---|---|---|---|
| L4 | Ada | 121 | 300 |
| RTX 6000 Ada | Ada | 364 | 960 |
| L40S | Ada | 362 | 864 |
| RTX 4090 | Ada | 165 | 1,008 |
| A100 SXM 80 GB | Ampere | 312 | 1,555 |
| RTX 5090 | Blackwell | 419 | 1,792 |
| RTX PRO 6000 | Blackwell | 503 | 1,792 |
| H100 SXM | Hopper | 989 | 3,400 |
| GH200(H100) | Hopper | 989 | 4,220 |
| H200 SXM | Hopper | 989 | 4,800 |
| B200 SXM | Blackwell | 2,250 | 8,000 |
6. 考察
■ LLMによる違い
今回、サイズの違うTinyLlama-1.1B-Chat-v1.0とLlama-3.1-8B-Instructで取得をしましたが、概ね同じ傾向であった。
■ 計測値とスペックの乖離について
● TinyLlama-1.1B-Chat-v1.0においてのL4 vs RTX4090
- BF16 TFLOPS値は約1.3倍だが、計測値は3.2倍と乖離がある
- メモリ帯域は約3.3倍違い計測値との差と近いことから、メモリ帯域が影響している可能性がある
- LLMが小さいことから演算性能よりメモリ転送がボトルネックになっていたと考えるのが自然
● スペックがそのまま計測値に反映されるわけではない
例として、B200のBF16 TFLOPSはA100の約7.2倍だが、計測値は2.8倍にどどまる。
今回の計測では判断ができませんが、
- Llama-cookbookのコードがB200において最適化されていない
- メモリボトルネックの可能性
- プロファイラなどによる詳細な分析
- より大きなLLMでの挙動の比較
などなど要因や追加の検証を行う必要がありますね。
■ コンシューマー向けGPUの健闘
- RTX 4090とA100の差は約1.3倍
- RTX 5090はA100を超えた
コストパフォーマンスの観点で良い結果が得られたと思います。
ただ、以下の観点については注意が必要になります。
- 今回は1GPUでの計測であり、複数GPUを利用する場合、PCIe接続となるので違う結果になる可能性が高いです
- コンシューマー向けGPUなのでECCメモリには対応していないことから長時間の学習には不安がある
- NVIDIA Driver License Agreementにてデータセンターでの展開はできない
7. 計測において工夫した点
■ データダウンロード時間の削減
Runpodではリージョンの指定ができず、どこのリージョンが割り当てられるか起動するまでわかりませんでした。
Llama-3.1-8B-Instructの容量は30GBほどになるため、このダウンロードに時間がかかると無駄にコストを消費してしまう可能性がありました。
今回、対処方法として、手持ちのクラウドでアメリカ、ヨーロッパ、アジアのObject Storageにデータを置いておき、podが起動したところの一番近いところから取得することでダウンロード時間を短縮しました。
ちなみに、計測後半にはRunpod側のリージョンを選べるようになりました。
■ Blackwell系でErrorが発生し実行できない
実行時に以下のメッセージが出力され、
NVIDIA B200 with CUDA capability sm_100 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_50 sm_60 sm_70 sm_75 sm_80 sm_86 sm_90.
If you want to use the NVIDIA B200 GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
以下のエラーで停止しました。
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
今回のイメージに入っていたpytorchがBlackwell(RTX 5060, RTX RPO 6000, B200)のCUDA capabilitiesに対応していないのが原因でした。
これらのGPUで実行するためにnightlyを別途再インストールすることで実行することができました。
pip uninstall -y torchaudio
pip install --upgrade --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cu128
8. 最後に
NVIDIA GPUの単体性能についてLLMの学習コードを用いて比較を行いました。
対象のLLMやGPU種類、GPU数など限られた範囲での計測でしたが、「GPUモデルによる性能値の感覚を持つ」っというゴールはの最初の一歩は踏めたかなと思います。
また、今回の結果から以下のようなことが気になってきましたので引き続きチャレンジかなと思います。
- マルチGPUでの性能
- Blackwellでの最適化
- FP8やFP4などでどうなるか
- AMD GPUでの実行
7. Appendix
今回のベンチマークで利用したものです。
利用したクラウドサービス
利用した学習コード
torchrun \
--nnodes 1 \
--nproc-per-node 1 \
--rdzv_id 12345 \
--rdzv_backend c10d \
--rdzv_endpoint ${MASTER_ADDR}:${MASTER_PORT} \
./llama-cookbook/getting-started/finetuning/finetuning.py \
--enable_fsdp \
--low_cpu_fsdp \
--use_peft \
--use_wandb True \
--peft_method lora \
--mixed_precision False \
--dataset alpaca_dataset \
--model_name ./models/<MODEL> \
--output_dir ./output/alpaca/model \
--num_epochs 1
利用したLLM
利用したデータセット
NVIDIA GPUの性能値
こちらに値がまとまっていたので参照させていただきました。