1. はじめに
Cohere社が最近リリースしたLLMのCommand R+がGPT4に迫る性能を発揮していたり、RAG利用での性能で話題となっています。
そのCommand R+でRAGを体験できるチャットアプリの実装がLightningAIにてチュートリアルが公開されています。
これを身近な環境で動かしてみたいと思います。
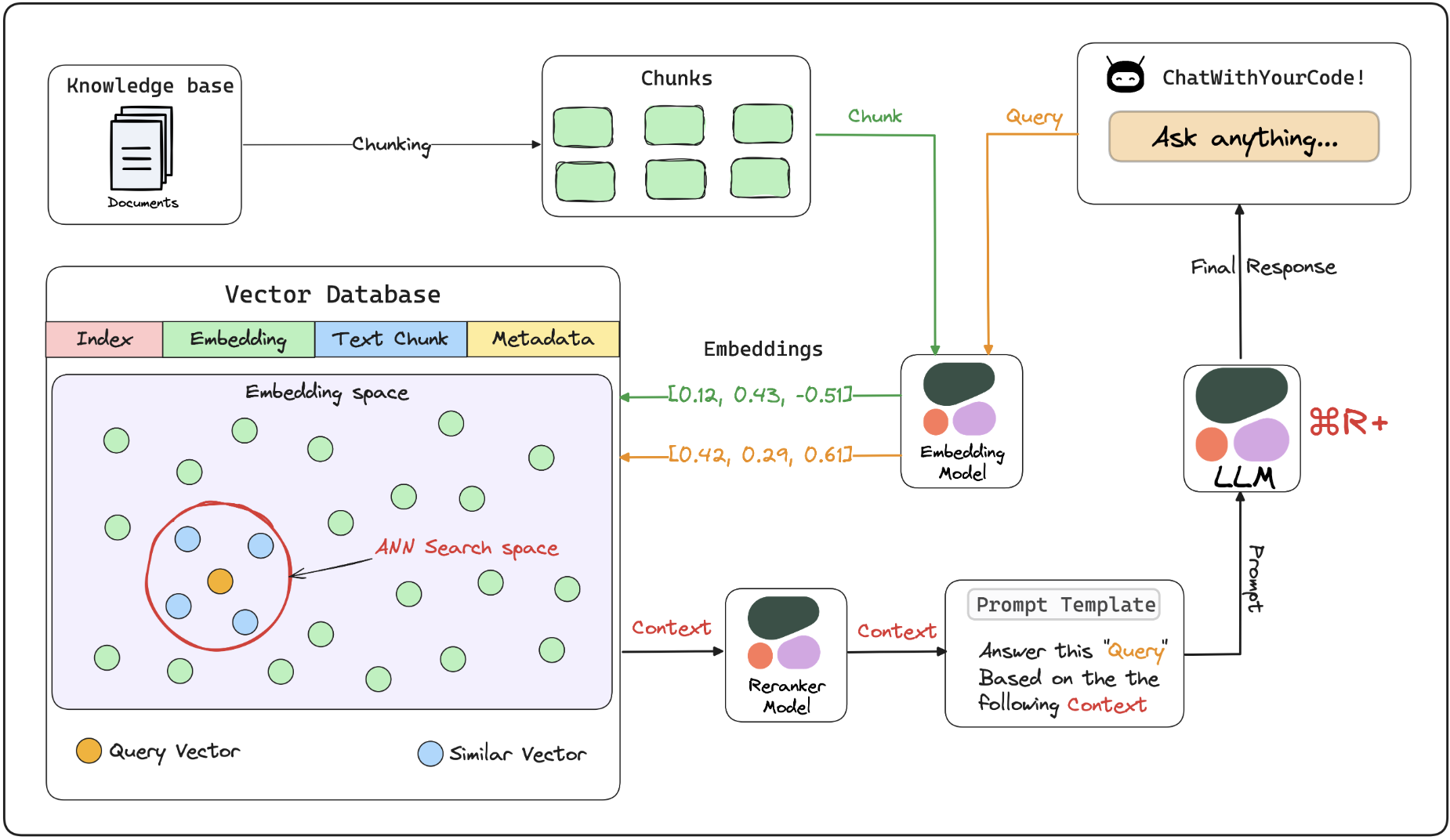
このチャットボットでCohere社の以下のモデルが使われています
- LLM: Command R+
- Embed: embed-english-v3.0 / embed-multilingual-v3.0
- Reranker: rerank-english-v3.0 / rerank-multilingual-v3.0
以下の動画のようにブラウザでPDFファイルをアップロードしてチャットで問い合わせができます。
2. 必要なもの
以下の2つを準備しましょう。
- Cohere社のAPIキー(無料でトライアルキーが取得可能)
- https://dashboard.cohere.com/welcome/login からGoogleアカウントまたは、Githubアカウントで連携してログイン可能
- ノートブック環境または、インターネットに接続できるLinux環境
3. 構築
lightning.aiのサービスを使って試すのが一番簡単と思われますが、登録して有効になるのは2、3営業日後のようなので、ここではNotebook環境やLinux環境で試したいと思います。
3-1. CohereのAPIキーをコピーする
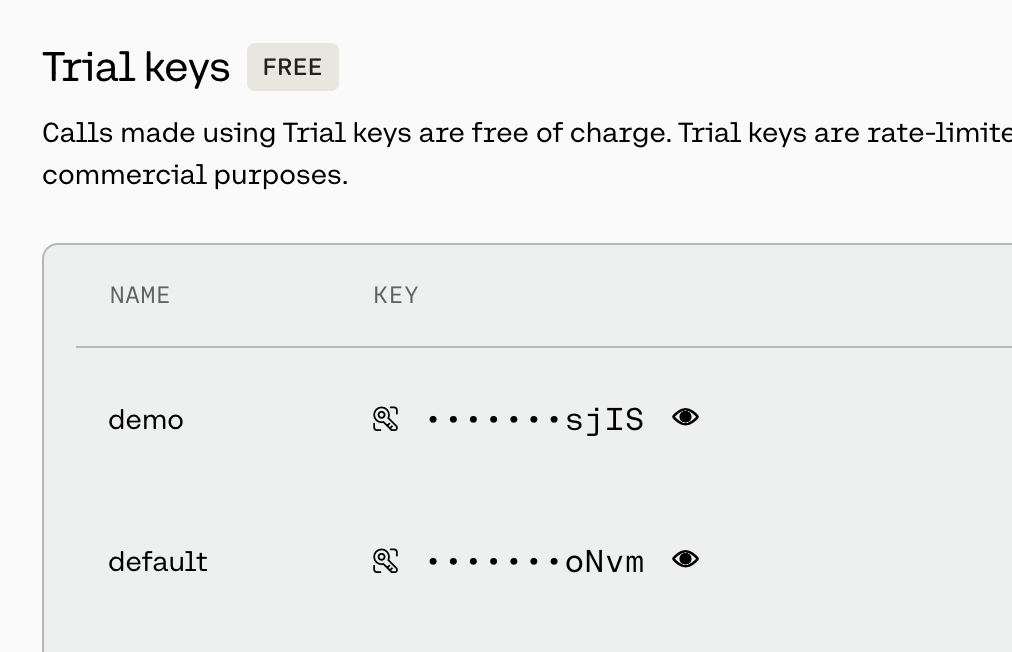
以下のURLにアクセスして、以下のTrial keysでKEYの内容をコピーしてメモ帳などに控えておきます。
https://dashboard.cohere.com/api-keys
👁️のアイコンをクリックすると全てのキーが表示されます。
3-2. コードをコピーする
https://lightning.ai/lightning-ai/studios/rag-using-cohere-command-r?section=featured にアクセスして、Filesタブをクリックします。
ファイル一覧が表示されるので、左側のapp.pyをクリックし、コードが表示されたら1行目から177行目まで選択してコピーしてメモ帳などに控えておきます。
または以下を展開してコピーでも大丈夫です。
2024年4月14日時点のapp.py
# Adapted from https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps#build-a-simple-chatbot-gui-with-streaming
import os
import base64
import gc
import random
import tempfile
import time
import uuid
from llama_index.core import Settings
from llama_index.core import VectorStoreIndex, ServiceContext, SimpleDirectoryReader
from llama_index.core import PromptTemplate
from llama_index.llms.cohere import Cohere
from llama_index.embeddings.cohere import CohereEmbedding
from llama_index.postprocessor.cohere_rerank import CohereRerank
import streamlit as st
if "id" not in st.session_state:
st.session_state.id = uuid.uuid4()
st.session_state.file_cache = {}
session_id = st.session_state.id
client = None
def reset_chat():
st.session_state.messages = []
st.session_state.context = None
gc.collect()
def display_pdf(file):
# Opening file from file path
st.markdown("### PDF Preview")
base64_pdf = base64.b64encode(file.read()).decode("utf-8")
# Embedding PDF in HTML
pdf_display = f"""<iframe src="data:application/pdf;base64,{base64_pdf}" width="400" height="100%" type="application/pdf"
style="height:100vh; width:100%"
>
</iframe>"""
# Displaying File
st.markdown(pdf_display, unsafe_allow_html=True)
with st.sidebar:
st.header(f"Set your Cohere API Key")
st.link_button("get one @ Cohere 🔗", "https://dashboard.cohere.com/api-keys")
API_KEY = st.text_input("password", type="password", label_visibility="collapsed")
uploaded_file = st.file_uploader("Choose your `.pdf` file", type="pdf")
if uploaded_file and API_KEY:
try:
with tempfile.TemporaryDirectory() as temp_dir:
file_path = os.path.join(temp_dir, uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getvalue())
file_key = f"{session_id}-{uploaded_file.name}"
st.write("Indexing your document...")
if file_key not in st.session_state.get('file_cache', {}):
if os.path.exists(temp_dir):
loader = SimpleDirectoryReader(
input_dir = temp_dir,
required_exts=[".pdf"],
recursive=True
)
else:
st.error('Could not find the file you uploaded, please check again...')
st.stop()
docs = loader.load_data()
# setup llm & embedding model
llm = Cohere(api_key=API_KEY, model="command-r-plus")
embed_model = CohereEmbedding(
cohere_api_key=API_KEY,
model_name="embed-english-v3.0",
input_type="search_query",
)
cohere_rerank = CohereRerank(
model='rerank-english-v3.0',
api_key=API_KEY,
)
# Creating an index over loaded data
Settings.embed_model = embed_model
index = VectorStoreIndex.from_documents(docs, show_progress=True)
# Create the query engine
Settings.llm = llm
query_engine = index.as_query_engine(streaming=True, node_postprocessors=[cohere_rerank])
# ====== Customise prompt template ======
qa_prompt_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information above I want you to think step by step to answer the query in a crisp manner, incase case you don't know the answer say 'I don't know!'.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
query_engine.update_prompts(
{"response_synthesizer:text_qa_template": qa_prompt_tmpl}
)
st.session_state.file_cache[file_key] = query_engine
else:
query_engine = st.session_state.file_cache[file_key]
# Inform the user that the file is processed and Display the PDF uploaded
st.success("Ready to Chat!")
display_pdf(uploaded_file)
except Exception as e:
st.error(f"An error occurred: {e}")
st.stop()
col1, col2 = st.columns([6, 1])
with col1:
st.header(f"Chat with Docs using ⌘ R+")
with col2:
st.button("Clear ↺", on_click=reset_chat)
# Initialize chat history
if "messages" not in st.session_state:
reset_chat()
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if prompt := st.chat_input("What's up?"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(prompt)
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
# Simulate stream of response with milliseconds delay
streaming_response = query_engine.query(prompt)
for chunk in streaming_response.response_gen:
full_response += chunk
message_placeholder.markdown(full_response + "▌")
# full_response = query_engine.query(prompt)
message_placeholder.markdown(full_response)
# st.session_state.context = ctx
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": full_response})
3-3. ノートブック環境で試す
3-3-1. Google Colab 編
ノートブック環境においてGoogle Colabが有名で使いやすいところですが、PDFファイルのアップロード後にファイルが認識できないという問題に遭遇しました。
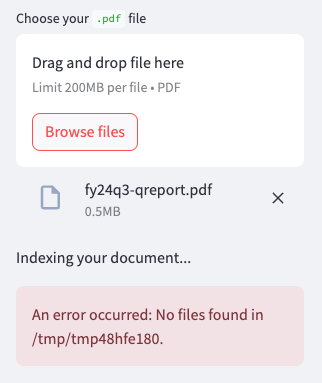
保存先を/content配下にしてみたのですが、挙動は変わらず。原因がわからなかったので、他のノートブックを試してみます。
もし原因や修正方法がわかった方はコメントをいただけると助かります。
3-3-2. Data Science Service 編
Google Colabがそのような状況だったので、代わりの環境としてOracle CloudのData Science Serviceで試してみます。
まずはコードを格納するディレクトリを作成します。名前は任意ですが、RAGとします。
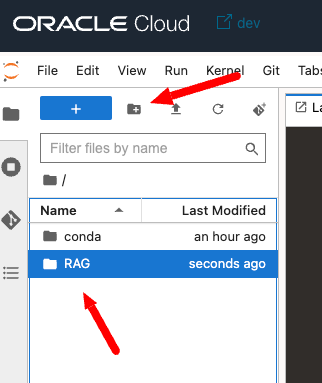
RAGディレクトリに移動して、右クリックでNew Fileを選択します。

pythonコードとしてapp.pyを作成してコピーしたコードを貼り付けます。
続いて、再度右クリックでNew Notebookを作成します。
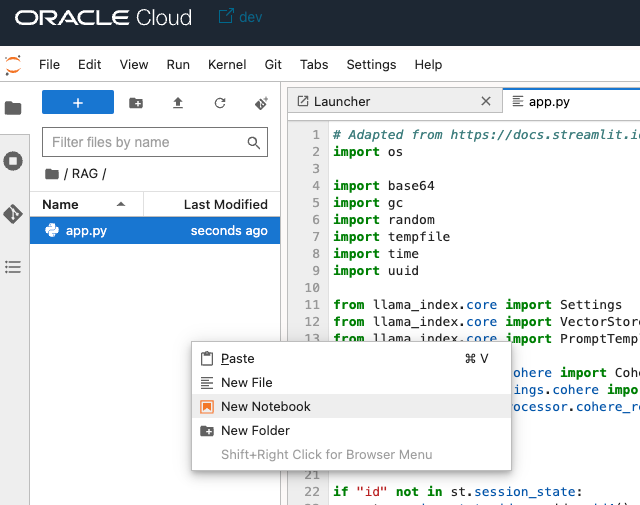
以下の2行を、
!pip install llama_index.core llama_index.llms.cohere llama_index.embeddings.cohere llama_index.postprocessor.cohere_rerank streamlit llama-index-readers-file
!streamlit run ./app.py & sleep 3 && npx -y localtunnel --port 8501
それぞれのセルとして以下のようにします。

RunタブのRun All Cellsを実行します。
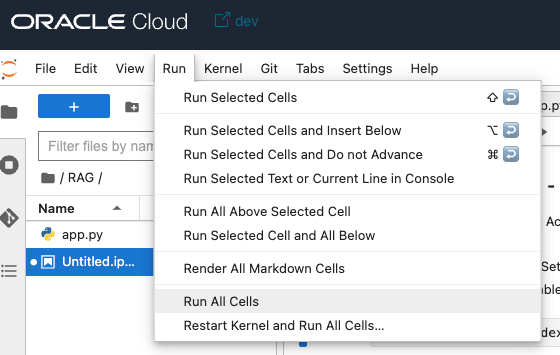
先ほどの2行の内容が実行され、2行目の結果が表示されます。
External URLのIPアドレス部分(赤マーキングの部分)をコピーし、your url is:のリンクをクリックします。
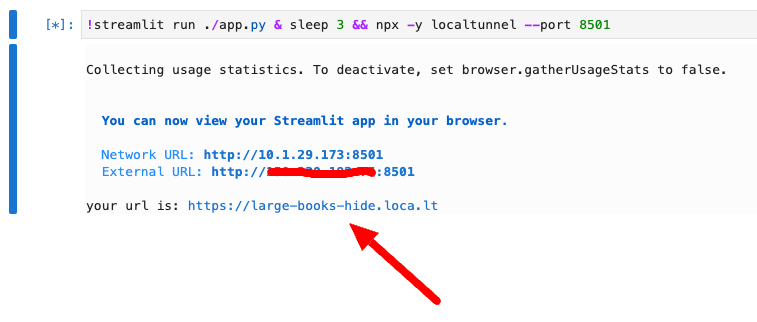
localtunnelのWebページが開くので、コピーしたIPアドレスをTunnel Passwordに貼り付けて、Click to Submitをクリックします。
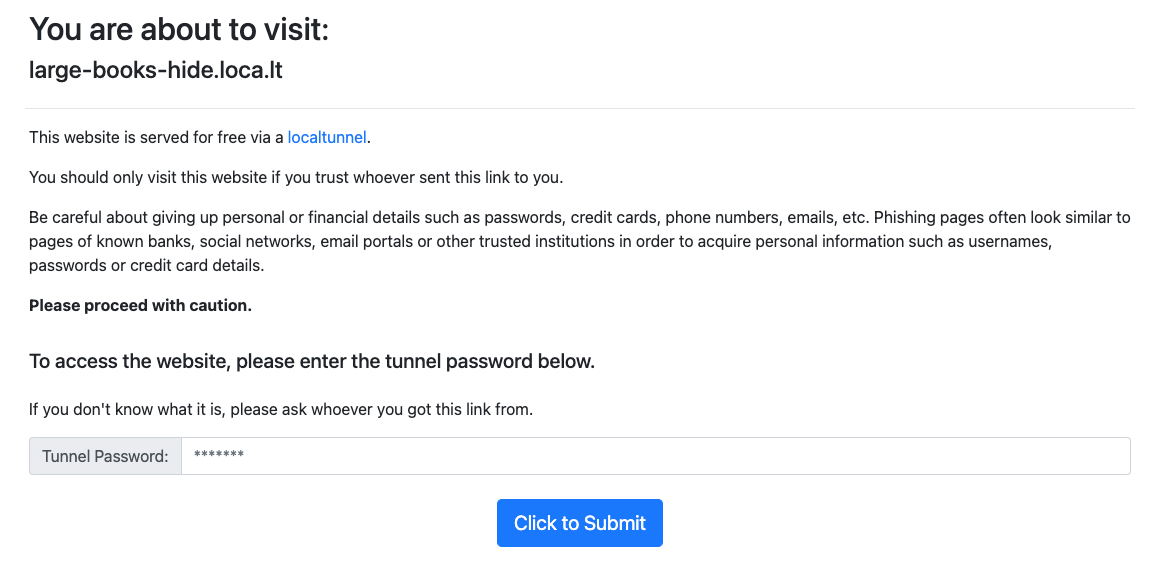
これでStreamlitの画面が表示されます。
3-4. Linux上で実行する
Notebook以外にもインターネットに接続可能なLinux環境でも準備可能です。
ここではUbuntu 22.04環境で構築していきます。
pipをインストールします。
sudo apt install -y python3-pip
コードを置くディレクトリを作成して、移動します。
mkdir RAG
cd RAG
viなどお好みのエディタでapp.pyを作成し、冒頭にコピーしておいた内容をペーストします。
vi app.py
app.pyを動かすのに必要なパッケージをpipでインストールします。
pip install llama_index.core llama_index.llms.cohere llama_index.embeddings.cohere llama_index.postprocessor.cohere_rerank streamlit llama-index-readers-file
streamlitでapp.pyを実行します。
streamlit run ./app.py
表示されるExternal URL:に対してブラウザでアクセスします。
その他注意点
- Firewall(ufwやiptables)で8501ポートを解放してください
- pipでパッケージをインストールしたにも関わらずstreamlitが実行できない場合は一度ログアウトして再度ログインしてみてください
4. 使ってみる
-
Set your Cohere API Keyのテキストボックスに取得したCohereのAPIキーを入力します。 -
Choose your .pdf fileにチャットでやり取りしたい内容のPDFファイルをアップロードします。ここでは日本オラクルの2024年5月期の第3四半期報告書を使いたいと思います。 - ファイルのアップロードが完了すると、Index(Embedding)が行われ、
Ready to Chat!と表示され、アップロードしたPDFファイルのプレビューが表示されます。
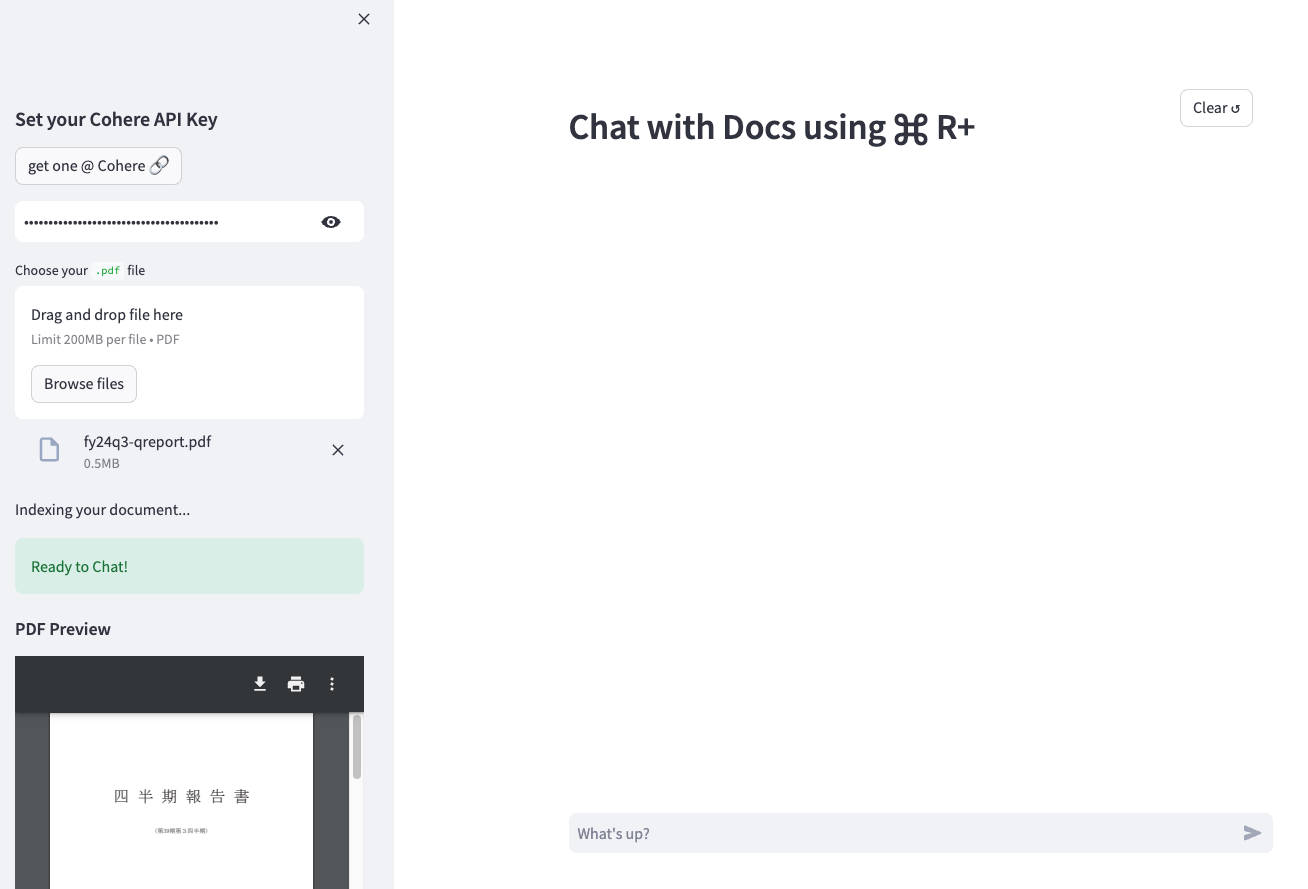
では、早速問い合わせてみましょう!
まず、「このドキュメントの概要について説明してください。」と聞いてみます。
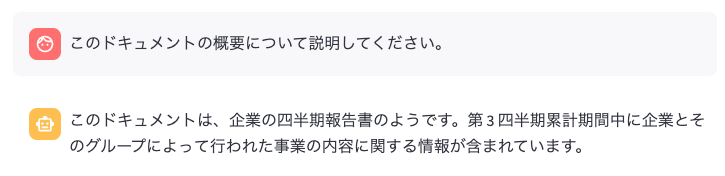
四半期報告書であるという回答は得られましたが、具体的な企業名はなく単に企業という回答が気になります。
では続けて、「どこの企業の四半期報告書ですか?」かと聞いてみます。
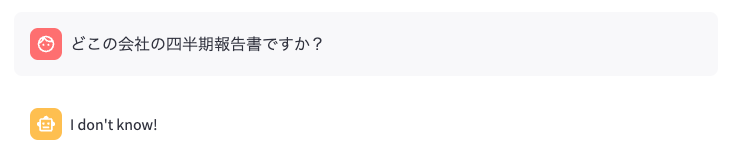
I don't know!という回答になってしまいました。
これはプロンプトに万が一、答えがわからない場合は、『わからない!』と言ってください。と書かれているためです。
incase case you don't know the answer say 'I don't know!'
なぜ分からなかったのだろうとコードを眺めていると、Embeddモデルが英語のみに対応しているembed-english-v3.0です。ついでにRerankモデルも英語でした。
embed_model = CohereEmbedding(
cohere_api_key=API_KEY,
model_name="embed-english-v3.0",
input_type="search_query",
)
cohere_rerank = CohereRerank(
model='rerank-english-v3.0',
api_key=API_KEY,
)
これを日本語に対応しているマルチリンガル版に書き換えます。

streamlit(notebookであれば!streamlit run ./app.py & sleep 3 && npx -y localtunnel --port 8501のセルを停止、Linux環境であれば$ streamlit run ./app.pyをctrl+cで止めて)を一度停止して、再度実行します。
もう一度、同じ質問をして確認してみましょう。
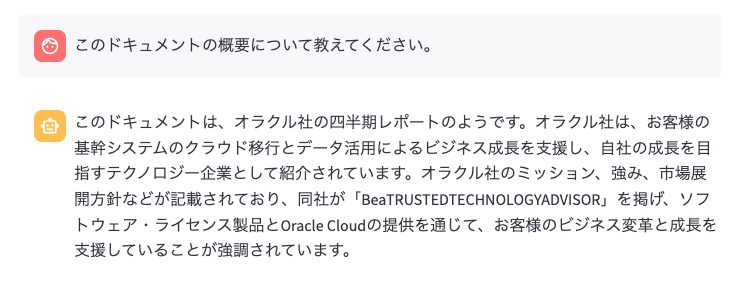
今度はオラクル社という内容が含まれており、明らかに良い回答です。できれば日本オラクルと回答して欲しかったのですが、とりあえず良いでしょう。
ドキュメントは四半期報告書なので、報告内容である売上高について問い合わせてみます。
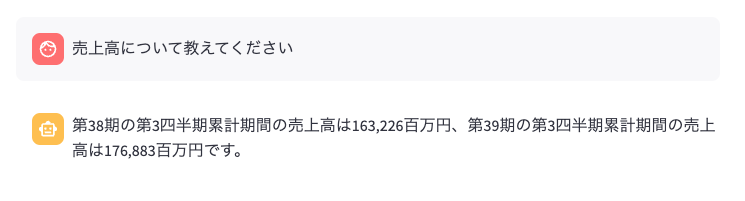
以下が報告書の抜粋なのですが、この表の中から第38期と第39期の両方の数字と単位を正確に回答してくれました。

5.最後に
Cohere社の様々なモデル(command R+, Embedd, Rerank)を利用たRAGの実装を試してみましたが、思っていた以上の精度でした。
LLMとして日本語に関しても試した範囲では全く問題ないレベルでした(というのも、古いcommandモデルやayaモデルを試していた経験から日本語対応したと言われても少し不安があった)。
簡単に試せるので検証用にはちょうど良い仕組みですね。皆さんもぜひお試しください。
以下のCohere社のBlogではsoon to be available on Oracle Cloud Infrastructure (OCI)とありますので、OCIをご利用の方にとっては嬉しいニュースですね。