はじめに
word2vecで有名になったように、単語のベクトル空間への埋め込みは様々な分野で広く使われています。
しかし、多くの手法で埋め込んだ先のベクトルの各要素の意味付けは特に意識されていません。
例えば、「日本」を300次元のベクトル空間み、173番目の要素の値が大きくなっていたとします。しかし173番目の軸が何を意味するか分からないので、そこから「日本」という単語に対する何の洞察も得ることが出来ません。
ということで今回は
という論文を紹介します。
単語ベクトルを回転させて、単語ベクトルの各要素に解釈しやすい意味を持たせるという手法です。
日本語の単語ベクトルを使用して簡単な実験を行い、ベクトルの要素の意味がどれほど分かりやすくなるか観察してみました。
手法概略
定式化
手法は極めてシンプルです。
n:単語数 \\
k:単語の埋め込み先の次元 \\
A:単語ベクトル群 (n × k の行列 ) \\
T:学習対象の回転行列 (k × k の行列) \\
として
B = AT
という形で新しい単語ベクトル群$B$を作ります。
この時、新しい単語ベクトルの各要素が「分かりやすく」なるように次のような誤差関数$f(B)$を考え、この$f(B)$を最小化するように$T$を学習します。
f(B) = (1 − κ) \sum_{i=1}^n\sum_{j=1}^k\sum_{l=1, l\neq j}^k b_{ij}^2 b_{il}^2 + \\
κ \sum_{i=1}^k\sum_{j=1}^n\sum_{l=1, l\neq j}^n b_{ji}^2 b_{li}^2
ここで$b_{ij}$は$B$の各要素で$κ$はハイパーパラメータです。
$f(B)$の第1項の$b_{ij}^2 b_{il}^2$は、$b_{ij}^2$または$b_{il}^2$のどちらかが0に近ければ小さくなります。つまり、この部分を最小化するには 各単語ベクトルで絶対値の大きい要素をできるだけ少なくする ことになります。また、同様に第2項は ベクトルの同じ要素の絶対値が大きくなる単語をできるだけ少なくする と小さくなります。
つまり、$f(B)$を最小化すると、
- 単語ベクトル内で絶対値の大きい要素は少なくなり
- 同じベクトル要素が大きい単語は意味的に似た単語のみ
であるような単語ベクトルが得られることが期待できます。
ベクトルのある軸の値が大きい単語を集めてくれば、その軸の意味が推定できることになります。
この手法の利点
PCAなどを利用しても、有用な軸を見つけて、似たような単語のマッピングなどはできますが、本手法の利点は
- 単語ベクトルの次元
- 単語ベクトルのノルム
を変更せずに、意味が分かりやすい軸をとって単語をマッピングできることにあります。
英語での実験結果
論文では次のような実験結果が紹介されていました。
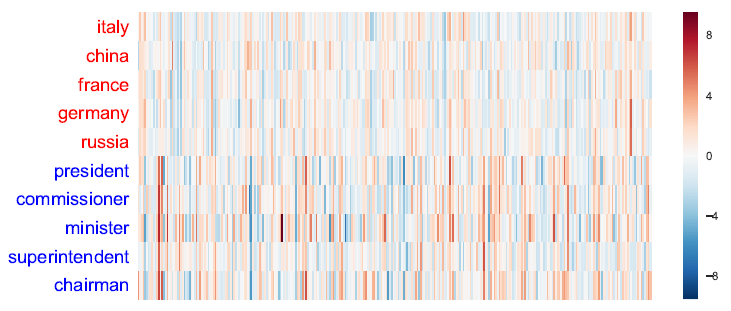
単語ごとに単語ベクトルの要素をヒートマップ化したものです。
回転前の単語ベクトル
回転後の単語ベクトル
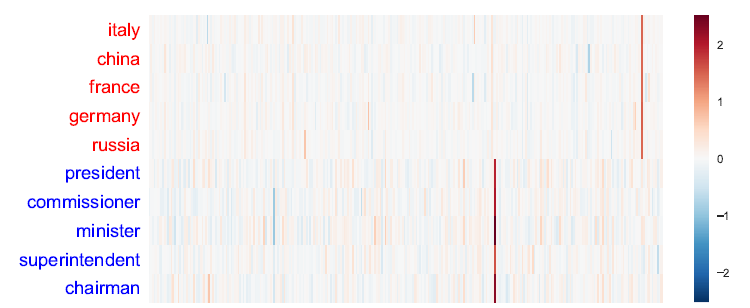
本手法によって単語ベクトルの回転を行うと、「国家」を現す軸と「役職」を現す軸が分かりやすく強調されるのが観察できます。
日本語での実験
日本語の単語ベクトルでも同じようなことが出来るのか実験してみました。
回転前の単語ベクトルとして、fasttextの学習済みモデルから700000単語分サンプリングしてきて使用しました。
回転行列の学習は著者らのコードを若干修正して実行しました。
実験結果
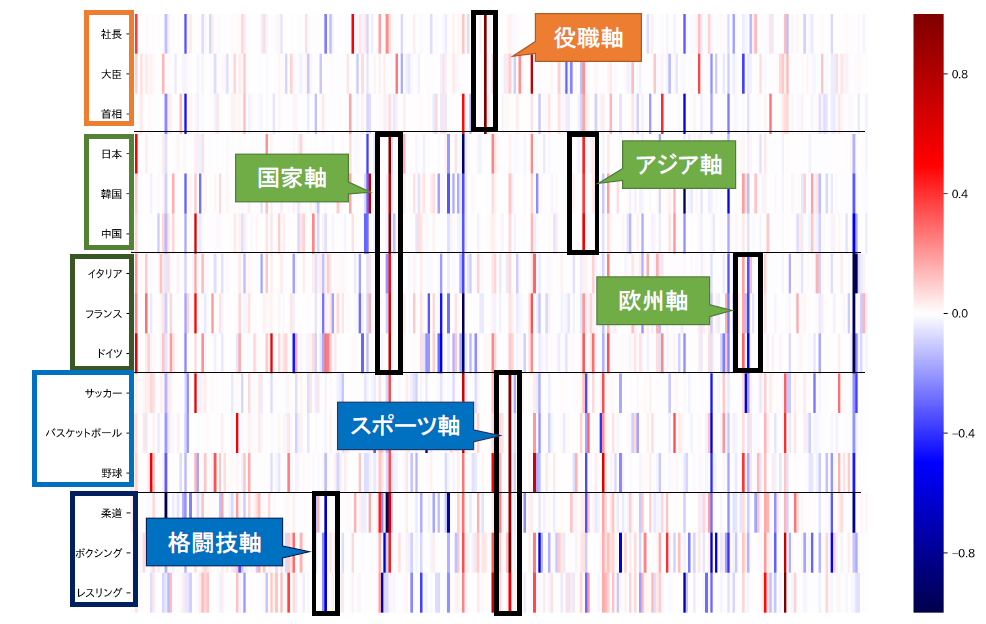
論文に紹介されていた英語の結果ほどきれいな結果は出ませんでした。
しかし、上の図のように、意味が分かりやすい軸もいくつか確認できました。
(「中国」という単語には「国家」「アジア」「大国」など複数の意味的要素があるはずで、上で紹介した論文の結果は若干きれいすぎる気がします。陽には記載されていませんでしたが、もとの単語ベクトルとして、図に記載されている10単語のみしか使用していないのかもしれません。)
まとめ
各軸に意味を持たせるような、単語ベクトルの回転方法を紹介しました。
日本語の単語ベクトルで簡単な実験を行い、回転後のベクトルのいくつかの軸に意味が見出せそうであることを確認しました。
本手法を用いれば、単語ベクトルを用いる種々の手法の解釈性がより高まると期待できます。