はじめに
こんにちは、普段はPHPを主に使っている伊藤です。
先日とある読み上げソフトを使って遊んでいたら、
月の上限に引っかかってしまいました。
有料版に登録すれば文字数制限は増えるのですが、
ケチな私は「遊ぶ分には自作できないかなー」と考えたのです。
検索してみるとGoogle様に誂え向きなAPIがあるじゃないですか!
と言うわけで、早速自作を開始してみます。
Text-to-Speechの有効化
- 今回はGoogleから提供されているAPIの
Text-to-Speechを利用して作成していきます。まずはGCPにアクセスし、新規プロジェクトの作成、もしくは既存プロジェクトを選択します。 - 次に、左のメニューから
ライブラリを選択し、Text-to-Speechと入力しましょう。そうすると、いくつかAPIの候補が出てくると思いますが、今回はText-to-Speechを選択します。
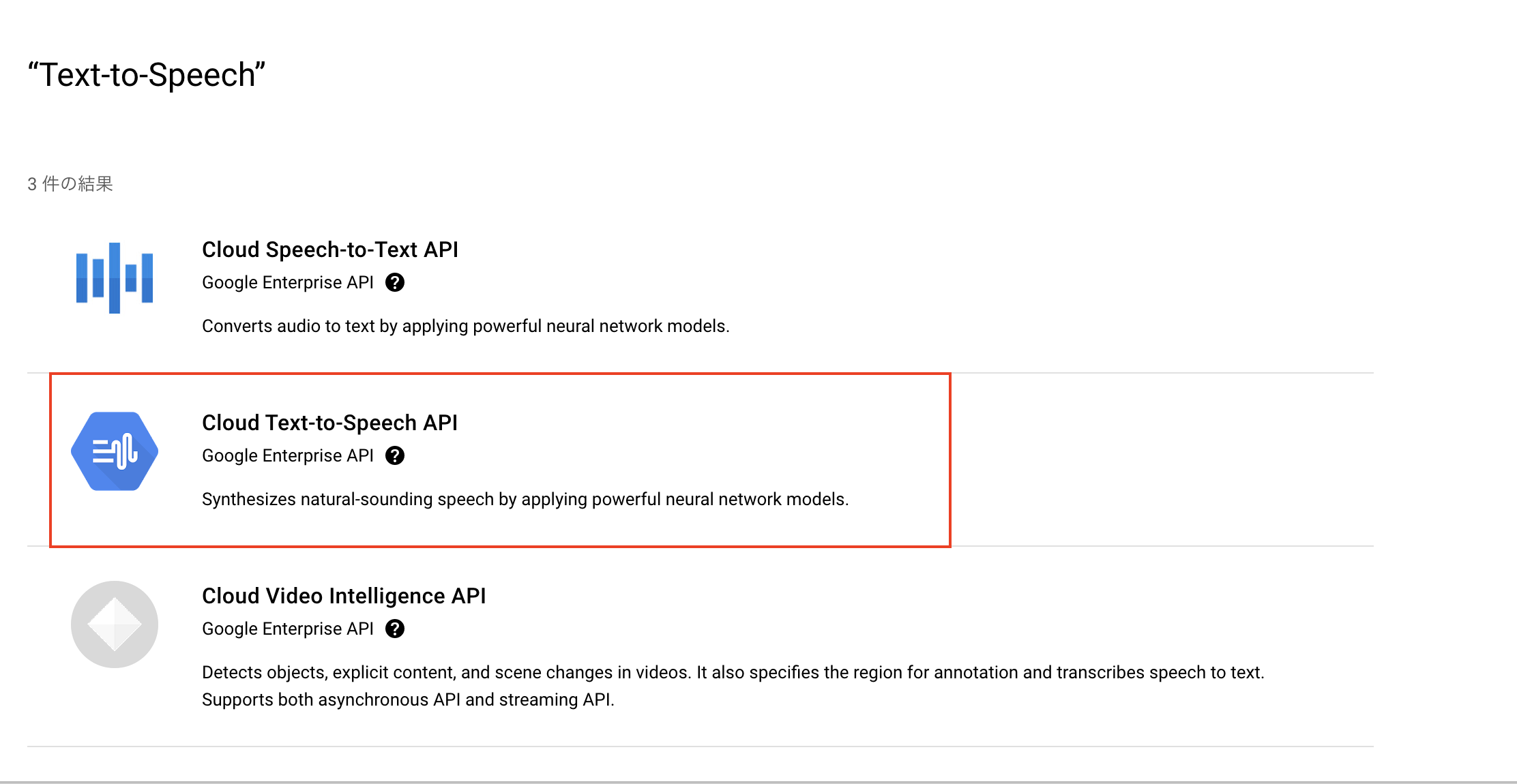
- APIを選択したら、
有効にするをクリックします。このAPIは従量課金制のため、課金情報の登録が必要になります。そのため、課金ユーザーを登録していない場合は登録を促されるので登録を行います。※登録手順は割愛します
秘密鍵の作成
- APIを有効化したら、左メニューから
認証情報にアクセスし、+認証情報を作成をクリックします。そうするといくつかメニューが出ますので、サービスアカウントをクリックします

- 必要な情報を入力します。まずは適当なサービスアカウントを入力し登録します。ロール等は設定しなくても大丈夫です。
- 作成すると、
サービスアカウントに追加されていると思いますので、メール欄のリンクをクリックします。キーを選択し、鍵を追加をクリックしてjsonを選択すると、jsonファイルがDLされますので、こちらを今回使用していきます。
作成
- さて、設定等が全て終わったら早速作成を開始します。まずはGoogleのクイックスタートのページへアクセスしておきます。
- まずはクライアントライブラリをインストールします。今回はPythonを利用するので、記述通りに以下のコマンドを実行します
$ pip install --upgrade google-cloud-texttospeech
- インストールが完了したら、クライアント ライブラリの使用のソースをコピーし貼り付けます。コメントは不要なので、取り除いたものが以下になります。
from google.cloud import texttospeech
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text="Hello, World!")
voice = texttospeech.VoiceSelectionParams(
language_code="en-US", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
with open("output.mp3", "wb") as out:
# Write the response to the output file.
out.write(response.audio_content)
print('Audio content written to file "output.mp3"')
- このままでは実行できません。先ほど登録した秘密鍵を読み込ませる必要があります。方法としては2種類で、クイックスタートにもあるとおり環境変数に登録する方法と、pythonの環境変数から読み込ませる方法があります。今回は後者の方法を利用しますので、以下のコードを追加します
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'secret_key.json'
- 同階層に、先ほどDLした秘密鍵を配置する必要がありますので注意してください。
- これで実行すると、output.mp3というファイルが生成されると思います。
Hello, World!と再生されれば成功です。
日本語で再生
- 日本語で再生するには言語の設定を少し変更します。具体的には以下の部分を変更すればOKです
voice = texttospeech.VoiceSelectionParams(
- language_code="en-US", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
+ language_code="ja-JP", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
画面から操作できるようにする
- このままでは、わざわざソースコードを変更しないと設定値が変更できないため非常に面倒くさいです。なので画面から設定値を変えられるようにします。
Streamlit
- 今回はstreamlitを使用します。インストールしていない場合は、以下のコマンドを実行してStreamlitをインストールします。
$ pip install streamlit
- Streamlitって何?っという方はたくさんいい記事がありますのでそちらを参考にしてください。
- インストールができたら、以下コマンドを実行してサンプル画面にアクセスできる事を確認します
$ streamlit hello
-
http://localhost:8501 にアクセスし、以下のような画面が表示されれば成功です

- ※ pythonのバージョンが3.9.7の場合エラーが出る場合があります、その場合はpythonのバージョンを上げてみて再実行してみてください
ソースコード
- では実際に実装をしていきます。最終的なソースは以下になります。
import os
import streamlit as st
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './secret_key.json'
from google.cloud import texttospeech
def speech(text, lang='日本語', gender='default', speakingRate=1):
# 話者の性別配列
genderType = {
'デフォルト': texttospeech.SsmlVoiceGender.SSML_VOICE_GENDER_UNSPECIFIED,
'男性': texttospeech.SsmlVoiceGender.MALE,
'女性': texttospeech.SsmlVoiceGender.FEMALE,
'中性': texttospeech.SsmlVoiceGender.NEUTRAL,
}
# 言語配列
langDic = {
'日本語': 'ja-JP',
'英語': 'en-US',
}
# クライアントをセット
client = texttospeech.TextToSpeechClient()
# 生成する文字をセット
synthesisInput = texttospeech.SynthesisInput(text=text)
# 話者の設定
voice = texttospeech.VoiceSelectionParams(
language_code=langDic[lang],
ssml_gender=genderType[gender]
)
# 出力音声の設定
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
speaking_rate=speakingRate
)
# 生成
response = client.synthesize_speech(
input=synthesisInput, voice=voice, audio_config=audio_config
)
return response
# 生成音声のDLリンク生成
def audio_downloader(bynary, fileName):
bin_str = base64.b64encode(bynary).decode()
href = f'<a href="data:application/octet-stream;base64,{bin_str}" download="{os.path.basename(fileName)}">音声ファイルDL</a>'
return href
# ここからフロント画面の制御
st.title('テキスト読み上げアプリ')
# 入力方法選択
inputOption = st.selectbox('入力タイプ',('直接入力', 'テキストファイル'))
# 空で宣言しておく
inputData = None
if inputOption == '直接入力':
inputData = st.text_area('こちらにテキストを入力してください', 'サンプル文')
else:
uplodedFile = st.file_uploader('テキストファイルをアップロードしてください',['txt'])
if uplodedFile is not None:
content = uplodedFile.read()
inputData = content.decode()
if inputData is not None:
st.write('入力値')
st.markdown('```' + inputData + '```')
st.markdown('## パラメータ設定')
lang = st.selectbox('言語を選択してください', ('日本語', '英語'))
gender = st.selectbox('性別を選択してください',('デフォルト', '男性', '女性', '中性'))
speakingRate = st.slider('話す速度を設定してください',0.3, 2.0, 1.0, 0.1)
st.markdown('## 音声生成')
st.write('以下の文章で音声が生成されます')
st.markdown('```' + inputData + '```')
if st.button('音声生成を開始'):
comment = st.empty()
comment.write('音声を出力します')
response = speech(inputData, lang, gender, speakingRate)
st.audio(response.audio_content)
comment.write('完了しました')
st.markdown(audio_downloader(response.audio_content, 'download.mp3', 'audio'), unsafe_allow_html=True)
- では、何をしているかを確認します
- まずは必要なモジュール等の記述をしています
import os
import streamlit as st
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './secret_key.json'
from google.cloud import texttospeech
- 次に、入力された値によって話者等を変更するための辞書を作成しておきます。言語は他にもいくつかありますが、今回は日本語と英語のみに絞ります
# 話者の性別
genderType = {
'デフォルト': texttospeech.SsmlVoiceGender.SSML_VOICE_GENDER_UNSPECIFIED,
'男性': texttospeech.SsmlVoiceGender.MALE,
'女性': texttospeech.SsmlVoiceGender.FEMALE,
'中性': texttospeech.SsmlVoiceGender.NEUTRAL,
}
# 言語
langDic = {
'日本語': 'ja-JP',
'英語': 'en-US',
}
- 次に、実際に音声の作成までを行います
# クライアントをセット
client = texttospeech.TextToSpeechClient()
# 生成する文字をセット(フロントで入力された文字が入ります)
synthesisInput = texttospeech.SynthesisInput(text=text)
# 話者の設定(言語と話者の設定をします)
voice = texttospeech.VoiceSelectionParams(
language_code = langDic[lang],
ssml_gender = genderType[gender]
)
# 出力音声の設定(形式と、音声の読み上げスピードを設定します)
audio_config = texttospeech.AudioConfig(
audio_encoding = texttospeech.AudioEncoding.MP3,
speaking_rate = speakingRate
)
# 生成
response = client.synthesize_speech(
input = synthesisInput,
voice = voice,
audio_config = audio_config
)
# 生成したものを返す
return response
- ついでに生成した音声はDLしたいと思うので、DL用のリンクを生成する関数を作成します
# 生成音声のDLリンク生成
def audio_downloader(bynary, fileName):
bin_str = base64.b64encode(bynary).decode()
href = f'<a href="data:application/octet-stream;base64,{bin_str}" download="{os.path.basename(fileName)}">音声ファイルDL</a>'
return href
- これで音声の生成関連に関しては完了です。
- 次に、実際に入力する画面を作成していきます。
streamlitはマークダウンが使えるので便利ですね。
st.title('テキスト読み上げアプリ')
# 入力方法選択
inputOption = st.selectbox('入力タイプ',('直接入力', 'テキストファイル'))
# 空で宣言しておく
inputData = None
if inputOption == '直接入力':
# 直接入力が選ばれた場合
inputData = st.text_area('こちらにテキストを入力してください', 'サンプル文')
else:
# テキストファイルが選ばれた場合
uplodedFile = st.file_uploader('テキストファイルをアップロードしてください',['txt'])
if uplodedFile is not None:
content = uplodedFile.read()
inputData = content.decode()
if inputData is not None:
st.write('入力値')
st.markdown('```' + inputData + '```')
st.markdown('## パラメータ設定')
lang = st.selectbox('言語を選択してください', ('日本語', '英語'))
gender = st.selectbox('性別を選択してください',('デフォルト', '男性', '女性', '中性'))
speakingRate = st.slider('話す速度を設定してください',0.3, 2.0, 1.0, 0.1)
st.markdown('## 音声生成')
st.write('以下の文章で音声が生成されます')
st.markdown('```' + inputData + '```')
if st.button('音声生成を開始'):
# ボタンが押された時の処理
comment = st.empty()
comment.write('音声を出力します')
response = speech(inputData, lang, gender, speakingRate)
st.audio(response.audio_content)
comment.write('完了しました')
# DL用リンクを作成
st.markdown(audio_downloader(response.audio_content, 'download.mp3', 'audio'), unsafe_allow_html=True)
- 実際にできた画面はこちらです

- 音声生成を開始を押すと、音声が生成されます
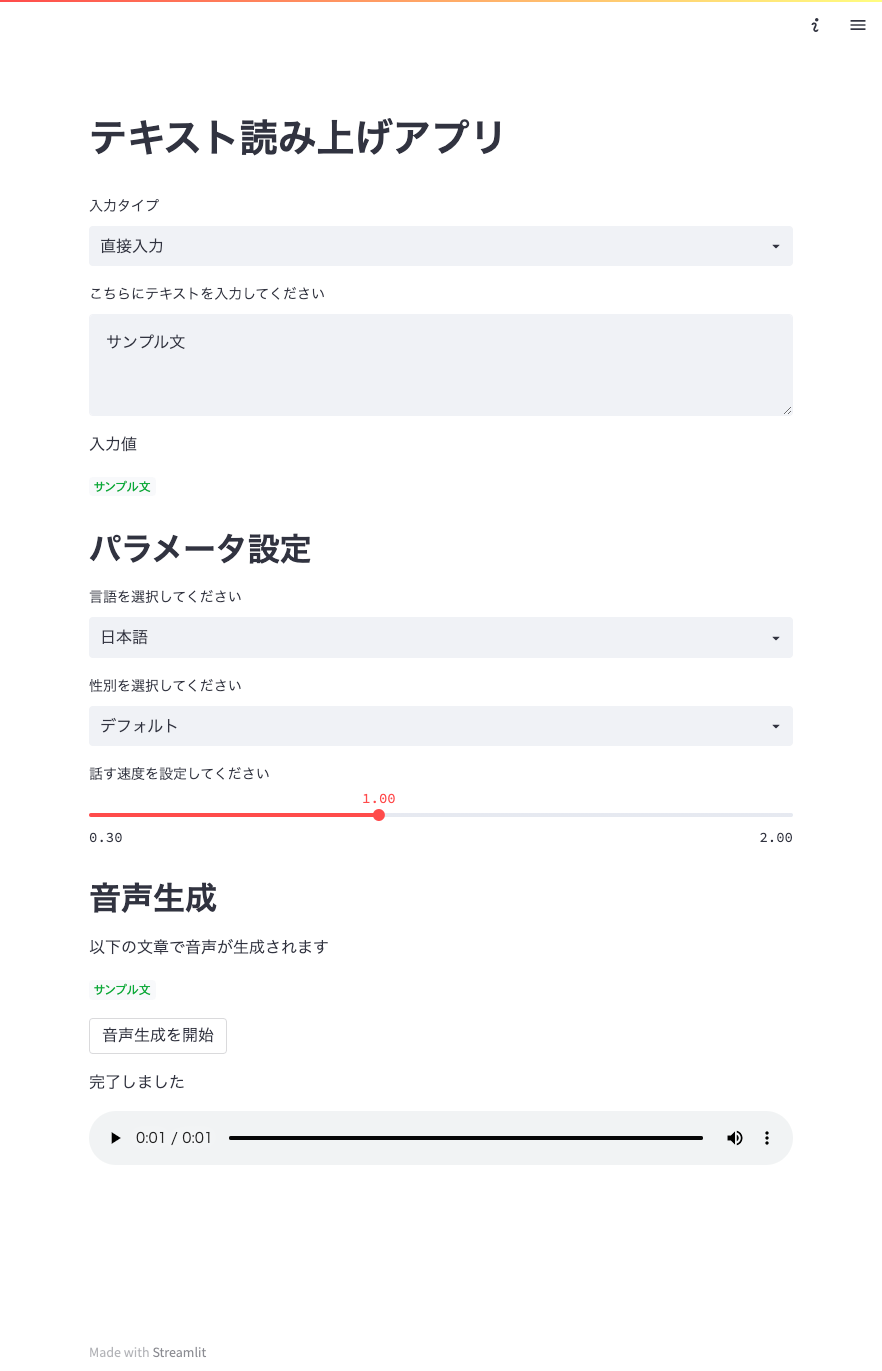
- 再生して、想定通りの音声が流れれば成功です
終わりに
いかがだったでしょうか? とても簡単に読み上げソフトが出来上がってしまいました。
これも全てGoogle様のおかげです。もう足を向けて眠れませんね。
追加で実装したいもの
- 日本語から英語に変換する機能
- 話者のパターンの設定
ではでは、失礼します。