概要
久々にスクレイピングで情報を取得するスクリプトを組みたくなったので組んで見る
言語
- ruby
使うライブラリ
- nokogiri
- mechanize
nokogiriはHTMLをパースする上では欠かせない子です。
net/httpで簡単なスクレイピングはできるがリダイレクトとかが発生する場合に難しいのでそのへんを簡単にやってくれるmechanizeを採用しました。
本題
スクレイピングの基本は
- 通信内容の理解
- コードに落とし込む
以上である。
1. 通信内容の理解
通信内容の理解ということで、基本的にサイトを訪れてデベロッパーツールを開いてNetworkタブを開きます。
そこで検索時にどんな通信が行われているのかを見てみます。
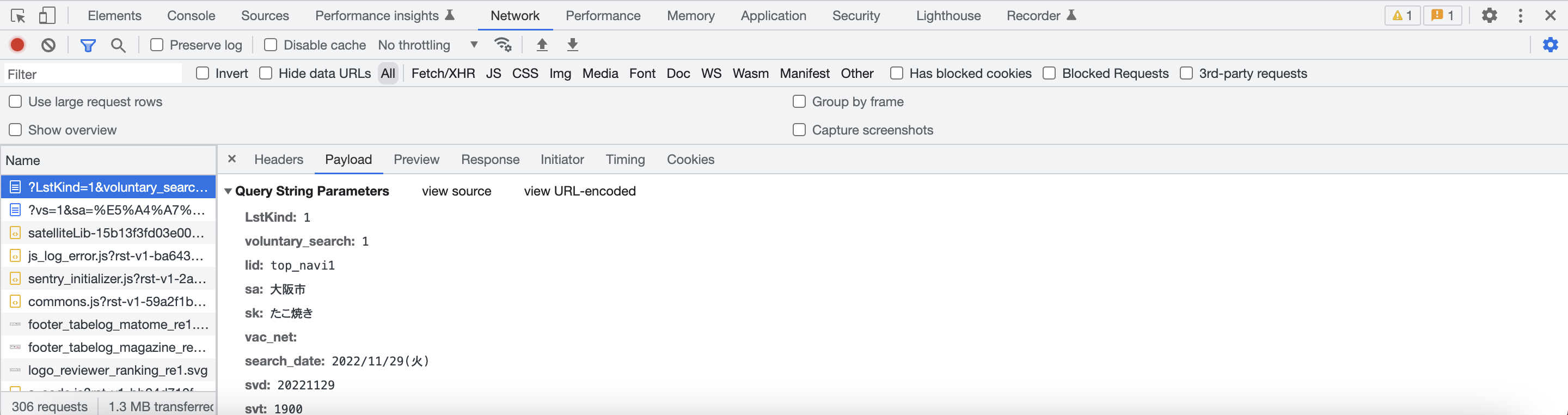
これがそうっぽいですね。
あとはこれをコードに落とし込むだけ
2. コードに落とし込む
ライブラリインストール
これをコードに落とし込むんですけど、まず最初に述べたライブラリを使うのでGemfileを作ってこんな感じに書きます。
source 'https://rubygems.org'
gem 'nokogiri'
gem 'mechanize'
必要なのはこの2つなのでこれを記載した上で
bundle install --path=.bundle
を実行
なんで--pathオプションをつけているかというとこれをつけないとグローバルに入っちゃってプロジェクトレベルの管理がしにくくなるからですね。
コーディング
これで準備ができたので実際のrubyのコードを書いてみましょう。
ファイル名は何でもいいのですが、crawler.rbとかにしましょうか
require 'uri'
require 'nokogiri'
require 'mechanize'
require 'kconv'
agent = Mechanize.new
area = '横浜'
keyword = 'たこ焼き'
page = agent.get("https://tabelog.com/rst/rstsearch/?LstKind=1&voluntary_search=1&lid=top_navi1&sa=%E5%A4%A7%E9%98%AA%E5%B8%82&sk=#{keyword}&vac_net=&search_date=2022%2F11%2F29%28%E7%81%AB%29&svd=20221129&svt=1900&svps=2&hfc=1&form_submit=&area_datatype=MajorMunicipal&area_id=27100&key_datatype=Genre3&key_id=40&sa_input=#{area}")
doc = Nokogiri::HTML.parse(page.body.toutf8, nil, 'utf-8')
puts '###ページタイトル取得###'
puts doc.title
puts "\n###検索ワード取得###"
puts doc.css('h2 strong').text
puts "\n###お店の名前を取得###"
doc.css('.list-rst__rst-name-target').map do |target|
puts target.text
end
細かいコードの解説はこの記事ではしません。
実行結果はこんな感じになるかと思います。
###ページタイトル取得###
横浜市でおすすめの美味しいたこ焼きをご紹介! | 食べログ
###検索ワード取得###
横浜市のたこ焼きのお店
###お店の名前を取得###
串カツ田中 綱島店
お好み焼き さ介
お好み焼ポン吉 本店
築地銀だこ モザイクモール港北店
ごっつええ本舗 CIAL横浜
めりけんはとば
じゃんぼ総本店 ジャンボ酒場 綱島駅前店
元天ねぎ蛸 MARK IS みなとみらい店
ポッポ 立場店
梅鉢流まみい
tacobe
築地銀だこ ウィング上大岡店
築地銀だこ まるい食遊館戸塚店
ドルフィン
お好み焼き ころんぶす 石川町北口駅前店
銀だこ酒場 新横浜店
たこ焼一久
串カツ田中 横浜西口店
60Hz
ポッポ ららぽーと横浜店
「横浜」「たこ焼き」で検索した結果がこんな感じで取得できます。
なにかに使うことがあれば...