追記
本記事は2020年11月24日のe-govの大幅アップデート前に書かれたものです。
このe-gov更新により法令のPDF自体も提供されるようになったため、以下で紹介したスクリプトは少なくとも見やすいPDFを作るという目的で利用することはもうないかと思います。
(一応2020年11月24日現在の仕様で動くようにはしています。)
はじめに
インターネット上で法令を参照しようと考えた場合、総務省により公開されているe-Gov法令検索や法令apiを利用することになりますがレイアウトが微妙だったりxmlのスタイルシートが提供されていなかったりといずれもあまり使い勝手がよろしくありません。
qiitaの過去の記事で法令apiを利用しようとしたものとして、
- (移動・再投稿)e-Gov法令APIとXML Pythonを用いた特定ワードが含まれる条文抽出
- 法令APIを利用したリサーチツールを自作してみた【SmartRoppo】
- e-Gov 法令データを活用したいメモ
などがあり、オンライン環境で法令を見るのであればこれらを参照すればよいのですが、オフライン環境での法令利用や印刷して紙媒体での利用をしたいときもあるので、法令apiから取得した法令を以下のように適切なレイアウトのpdfにするスクリプトを作成しました。

なお、このレイアウトは、Japanese Law PDF + XML 日本の法律のPDFとXMLで公開されているpdfを参考にして配置していますが、こちらのホームページの更新が2016年で止まっているため自分で作ってみたという次第です。
以下で使い方等について縷々述べていますが、単に使うだけであれば[(法学徒のための)環境構築](# (法学徒のための)環境構築)と[使い方](# 使い方)を見れば足りるかと思います。法令apiを自分で扱ったりあるいは私のコードを改変するなどしたい方の参考にするために[コードの解説](# コードの解説)も書いてあります。また[注意事項](# 注意事項)では適切に動作しない場合を記載していますのでご留意ください。
(法学徒のための)環境構築
基本的には法学学習者の役に立つように作っていますが、法学学習者でPythonやTeXになじみのある方も必ずしも多くないと思いますので、環境構築について少し詳しめに述べておきます。
PythonおよびTeXは使えるという方には不要ですので読み飛ばしてください。
Pythonを導入する
Pythonの公式サイトからPythonの最新版をダウンロードします。
写真のDownloadsのタブからお使いのOS(WindowsかMacOSのいずれかだと思います)向けのものを選択してください。
細かい過程でわからないことがあれば、導入を解説したwebページは多くありますので(例えば https://gammasoft.jp/blog/python-install-and-code-run/ など)そちらも参照して下さい。
ダウンロードの上インストールができたらPythonの準備は完了です。
TeXを導入する
TeX Liveをインストールしてください( https://texwiki.texjp.org/?TeX%20Live など参照)。TeXに関しては法学学習者の中にPythonよりは使っている方が多そうなので加えると、現状使っているTeXに関する利用環境でタイプセットの方法としてLuaLaTeXを選択できる場合はそれで何も問題ありません。
インストールが完了したらTeXworksを起動して"編集"タブから"設定"を選びその中の"タイプセット"タブのタイプセットの方法の"デフォルト"をLuaLaTeXに設定しておきます。
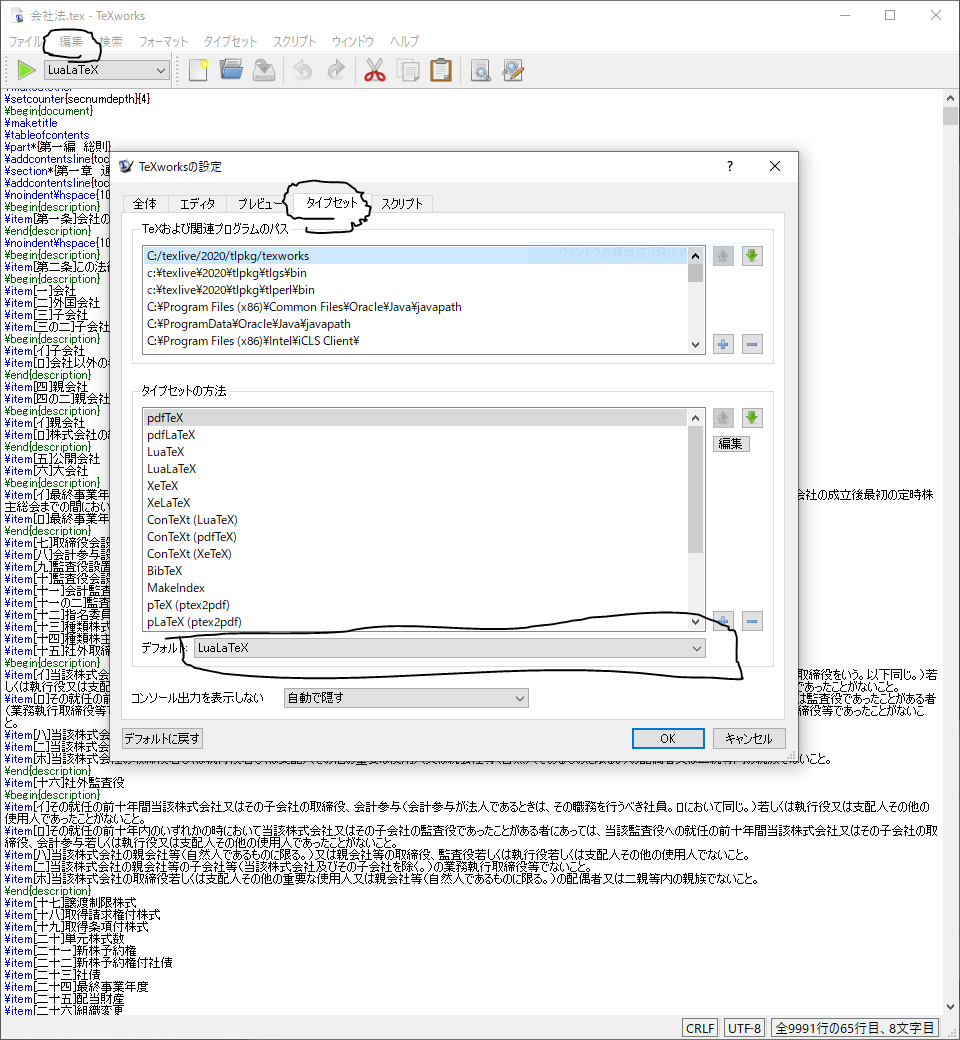
TeXに関してはこれで設定は完了です。
その他躓きそうな点
[使い方](# 使い方)のうち躓く可能性がある部分を詳細に述べておきます。
コードのダウンロード
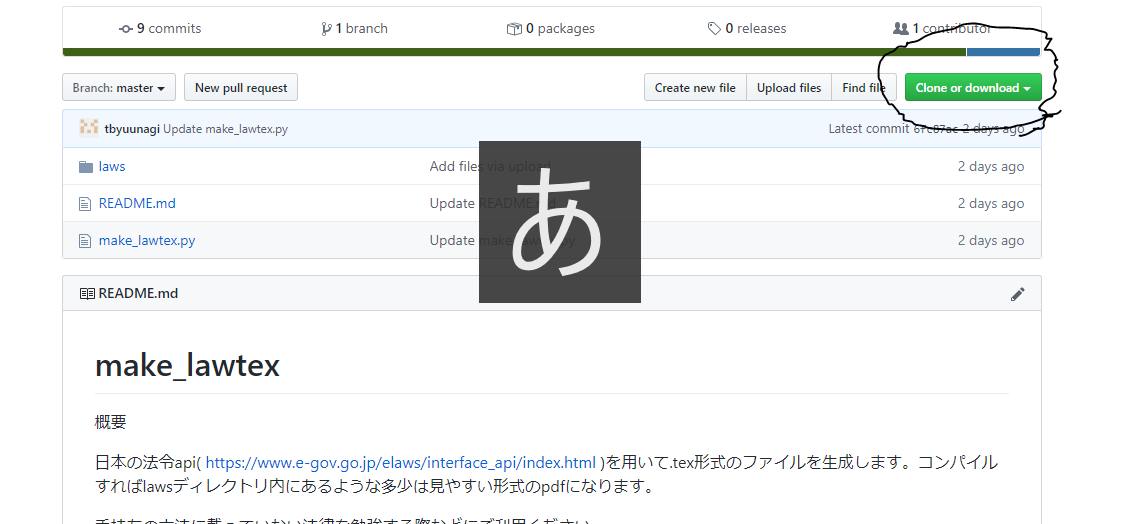
https://github.com/tbyuunagi/make_lawtex にアクセスしたうえ写真のClone or downloadを押してください。
requestsのダウンロード
Windowsであればコマンドプロンプト、Macであればターミナルを開いて( https://techacademy.jp/magazine/5318 や https://techacademy.jp/magazine/5155 を参照)"pip install requests"を入力して実行してください。
make_lawtex.pyの実行
ダウンロードしたmake_lawtex.pyをダブルクリックして実行される([使い方](# 使い方)で書かれたとおりになる)のであれば問題はないです。
ダブルクリックしてメモ帳などが開かれてしまう場合はWindowsであれば https://boukenki.info/python-py-file-doubleclick-kidou-jikkou-houhou/ などを、Macであれば https://yutori-gi.com/pythonscript-run/ などを参照して.pyファイルをPythonから開く設定をしてください。
使い方
コードは以下にあります。
https://github.com/tbyuunagi/make_lawtex
PythonおよびLuaLaTexが使える環境であれば問題なく動くはずです。Windows10、Ubuntu18.04での動作は確認しています。
Pythonのライブラリであるrequestsをインストールします。
$ pip install requests
make_lawtex.pyを実行すると
検索したいキーワードを入れてください
とプリントされるので探したい法令名の一部または全部を入力してください。
そうすると
1 民法
2 民法施行法 抄
3 動産及び債権の譲渡の対抗要件に関する民法の特例等に関する法律
4 電子消費者契約に関する民法の特例に関する法律
5 総務大臣の所管に属する特例民法法人の監督に関する省令
6 東日本大震災に伴う相続の承認又は放棄をすべき期間に係る民法の特例に関する法律
7 民法第九百九条の二に規定する法務省令で定める額を定める省令
8 民法第四百四条第三項に規定する期及び同条第五項の規定による基準割合の告示に関する省令
どれですか?
のような形で選択肢が番号とともに示される(例は"民法"で検索した場合)ので求めている法令を番号で入力してください。
これでPythonの処理は終了してlawsのディレクトリ下に"法令名".xml(法令apiから取得したもの)と"法令名".texが生成されます(民法であれば民法.xmlと民法.tex)。
ここで生成された.texのファイルをLuaLaTeXによってタイプセットすると冒頭に示したようなレイアウトのpdfファイルになります。
例えばTeXLiveを導入したうえでTeXworksを使う場合以下の図の青で囲った部分をLuaLaTeXに設定することになります。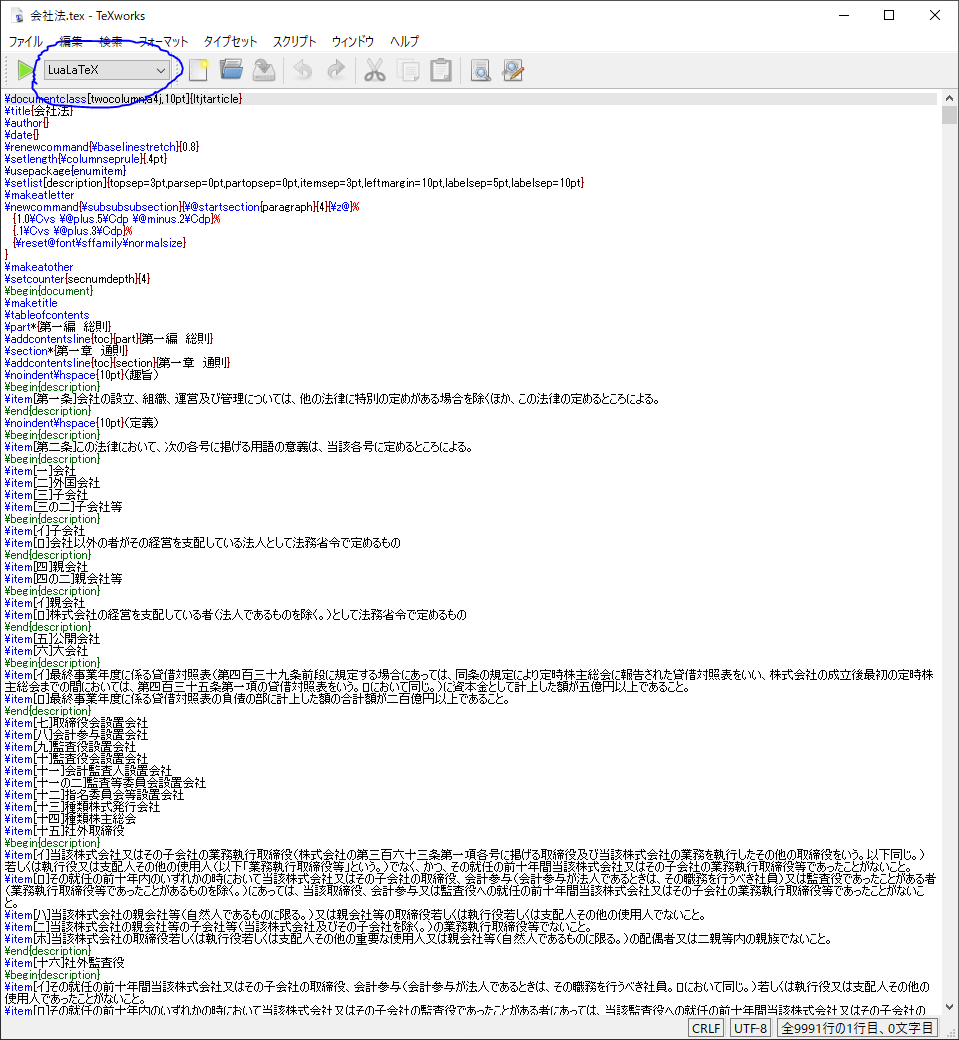
なお、目次の表示を正しいページで行うために3回タイプセットを行う必要があります(https://cns-guide.sfc.keio.ac.jp/2000/8/3/5.html など参照)。正直面倒なことをしていて正しくないような気もするのですがTeXについて詳しくないのでわかりません。より適切な方法をご存じの方がいれば指摘していただけると嬉しいです。
コードの解説
同様の用途で法令apiを使いたい場合はもちろん、それ以外の用途で法令apiを使いたい場合にもある程度流用可能かと思いますので躓いた部分やややこしかったの解説をしておきます。
法令API仕様書(Version1)を適宜参照するので詳しく読む場合はこちらもご用意ください。以下で特に断りなく「仕様書」といったときはこれを指していると思ってください。
import requests
import os
import xml.etree.ElementTree as ET
以上が使用しているライブラリです。
# 法令リストを取得してxmlファイルを保存、更新するときだけ使う
def get_lawlist():
r = requests.get('https://elaws.e-gov.go.jp/api/1/lawlists/1')
root = ET.fromstring(r.text)
tree = ET.ElementTree(element=root)
if not os.path.exists('laws/'):
os.mkdir('laws')
tree.write('laws/lawlist.xml', encoding='utf-8', xml_declaration=True)
return
法令名一覧取得API(仕様書5,10頁)にアクセスして法令名一覧のxmlファイルを取得します。以下で法令名の検索を行うときにはこのxmlファイルを利用しています。
デフォルトでは
r = requests.get('https://elaws.e-gov.go.jp/api/1/lawlists/1')
として法令種別を全法令にしていますが府省令はいらないなどあれば仕様書10頁4.2の項を参照してurlの末尾を変更してください。
# 法令名一覧から特定の法律をキーワードで検索した上で法令の正式名称と法令番号を返す関数
def search_Laws(key):
tree = ET.parse('laws/lawlist.xml')
root = tree.getroot()
LawName_list = []
LawNo_list = []
for child in root[1]:
if child.tag != 'Category':
if key in child[0].text:
LawName_list.append(child[0].text)
LawNo_list.append(child[1].text)
return LawName_list, LawNo_list
コメントの通り、キーワードを引数としてキーワードを含む法令をリストとして返す関数です。
法令apiを扱う際の注意事項として、前掲の法令名一覧取得APIから取得したxmlの中身を見ればわかる通り、ある法律は我々が名前として認識しているもの("民法"など、LawName)のほかに和暦n年法律第m号("明治二十九年法律第八十九号"など、LawNo)のような属性が与えられています。もちろん人類は法律第何号というのを見てもそれが何に関する法律かわからないのですが、法令apiにおいてはこの法律第何号が特定の法律を指定するためのユニークなキーになっている(get_LawContent()を参照)のでこれらのLawNoと我々が認識しやすいLawNameを合わせて管理できるようにしておくことが必要です。
# 入出力
def get_Law(search_Laws):
LawName_list = search_Laws[0]
LawNo_list = search_Laws[1]
if len (LawName_list) == 0:
print('当てはまる法令がありません')
return None
if len(LawName_list) == 1:
return LawName_list[0], LawNo_list[0]
for i,x in enumerate(LawName_list):
print(i+1,x)
print('どれですか?')
input_num = int(input())-1
LawName = LawName_list[input_num]
LawNo = LawNo_list[input_num]
return LawName, LawNo
キーワードと一致する法令を列挙し選ばせるという入出力部分です。
列挙される法令の数に制限がされていないので"法"で検索したりすると大変なことになります。このような動作が不快であれば適宜制限をしてください。
# get_Lawの結果を用いて内容を取得し、当該法令名で保存
def get_LawContent(get_Law):
LawName = get_Law[0]
LawNo = get_Law[1]
r = requests.get('https://elaws.e-gov.go.jp/api/1/lawdata/'+LawNo)
root = ET.fromstring(r.text)
tree = ET.ElementTree(element=root)
if not os.path.exists('laws/'):
os.mkdir('laws')
tree.write('laws/' + LawName + '.xml', encoding='utf-8', xml_declaration=True)
return LawName
法令取得API(仕様書6頁)を用いて目的の法令を取得します。すでに少し述べた通り
r = requests.get('https://elaws.e-gov.go.jp/api/1/lawdata/'+LawNo)
の行のurl末尾で指定すべきは法律第何号のようなLawNoであるということは認識しておきましょう。
また、[注意事項](# 注意事項)の通り一部の法令についてはそもそも法令apiによって取得できないのでこの関数によって取得することはできません。
def main():
get_lawlist()
Law_Name = search_get_LawContent()
result = xml_to_tex(Law_Name)
return result
実行用です。常に最新のリストを使うという観点からget_lawlist()を毎回実行することにしているのですが、lawlist.xmlがそこそこのデータサイズであるせいで処理が若干遅くなります。
get_lawlist()は一度実行してしまえば何度もやる必要のない処理ではあるので2回目以降はこの行をコメントアウトしても問題なかろうと思います。
以上が関数の解説となります。
説明していないものは見ればわかると思います。
生成されるレイアウトが気に食わない場合は、出来上がったTeXファイルとxml_to_tex()関数を見比べて必要な範囲で訂正してください。無駄に長くなっていますが、プリアンブルの部分は初めのあたり(make_lawtex.pyの79行目)にすべて書いてあるのでレイアウトとの関係ではここを修正すれば足りるはずです。
注意事項
一部の法令はデータサイズの関係などで法令apiによって取得できません。具体的には https://www.e-gov.go.jp/elaws/interface_api/index.html の制限事項の部分を見てほしいのですが、法学学習で必要そうでかつ取得できないものとしては所得税法や租税特別措置法などがあります(大体は別表がたくさんついている法律です)。 近いうちに対応するつもりではいますが現状はこれらの法令は取得できない旨をご了承ください。
make_lawtex.pyでこれらの法令を取得しようとすると
とプリントされるかと思います。
ここに書いてある通り、これらの法令は上記のgithubのリポジトリのtaishogai_lawsのディレクトリにxml、tex、pdfをすべて保存してあるので適宜こちらからダウンロードしてください(あまりスマートな方法ではないと思いますが、いい方法が思いつかないためこうなっています)。
おわりに
再配布、改変、自作発言すべてフリーなのでご自由にお使いください。不具合、改善案(コードだけでなく本記事についても)があればここのコメントやgithubのプルリクエスト、あるいは私のTwitterなどにお知らせいただけると幸いです。