AWSなどのクラウドサービスへサーバーをそのまま移行します
CloudEndureの利用事例は徐々に増えているようですが、実際に移行してみた際に失敗したことや注意事項などがいろいろ見つかったため、記しておくことにしました。
ちなみに、「サルでもできる」とか「ネコでもできる」というのはよく使われますが、私はウサギ派なので「ウサギでもできる」というタイトルにしてみました。実際ウサギって身体の大きさの割に脳が小さいらしく…なんでもないです。
私自身、雑種のいわゆるミニウサギをもう12年間飼っていますが、めちゃくちゃ可愛いです!もうかなりのお爺ちゃんなので老化してきていますが、食欲旺盛、毎日元気です!
これまでのマイグレーションはほぼ全部OSの更新だった
2015年ころからお客様が保有しているWindowsサーバーのクラウドへのマイグレーションは数えきれないくらい実施してきましたが、これまでの案件の99%が新規OSをクラウドでデプロイして、その上に既存のアプリケーションやデータの移行を行うものでした。それは主にOSの保守切れやハードウェアの保守切れに伴う更改となるため、多くのお客様が最新もしくは最新に近いバージョンのOSを希望する、という事情がありました。
たった一つの例外は、VMベースで動作していた某小規模クラウドサービスの急なサービス終了に伴い、低予算&短納期でVMベースの大規模クラウドサービスへの移行だったため、「VMイメージをコピーした」というものです。これは同じVMベースだったためということがあるので、いわゆる「AWS、Azure、GCP、Alibaba」といった大御所ではなく、特殊な事例でした。
大規模な移行にはOSからアプリまでそのままの移行もアリ
「これまで」と書いたのは前職での話なのですが、転職して早速これまで関わったことがないような大規模案件にアサインされ、サーバ10台以上を一気にマイグレーションする案件を担当することになりましたので、早速CloudEndureを検証してみました。
ほかにもAWSであれば「VM Import」「Server Migration Service」といったものがありますが、以下のような短所があるため、あまり利用は拡大していなかったように見受けられました。(私自身、提案フェーズまでで業務利用はしていないのでわかりませんが)
それが2019年になって、イスラエルのCloudEndureをAWSが買収して無償化した時点から一気に形勢が変わりました。
- VM Import
- VMイメージをS3経由で転送する方法。(VM基盤専用)
CLIで操作。トラブルも多く、原因究明も困難との話。
差分転送が出いないため、移行時の工数と時間が相当に必要になる。 - Server Migration Service
- VMもしくはHyper-Vに転送用仮想アプライアンスを動作させて転送する方法。(仮想基盤専用)
定期的に差分転送が可能
それに対して…
- CloudEndure
- 移行対象サーバへエージェントをインストールして転送する方法。
継続的な差分転送が可能
現在動作しているOSへエージェントをインストールするだけで実行できるため、物理サーバからも直接移行できてしまうCloudEndureがダントツに敷居が低くて圧勝です。
(マイクロソフトの「Disk2vhd」というツールでHyper-V形式のVHD/VHDX化や、VMwareの「vCenter Converter」でVMDK形式のイメージは作れますが、その場合には当然差分転送は不可)
そんなわけで早速レプリカ準備を始めてみましょう
CloudEndureにサインイン
こちらからCloudEndureのページを開き、アカウントを作成します。メールとパスワードを入れるだけです。
以下のようなメールが送られてくるのでリンクを開けばアクティベーションされてログイン可能になります。
ログインします
ダッシュボードに表示されるライセンス数は10万ライセンス!!!
さすがに使いきれませんね。
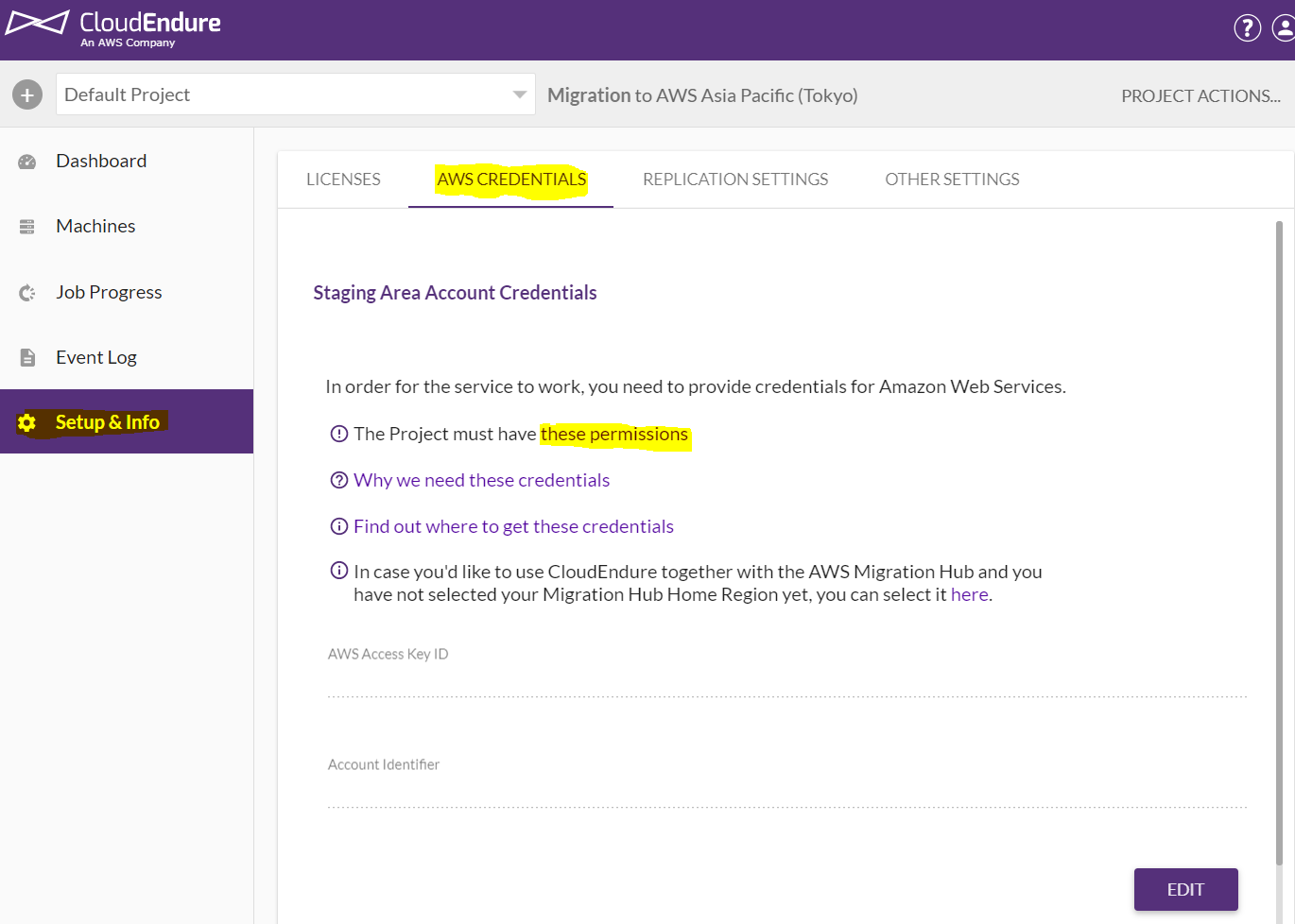
IAMユーザーを作成する
CloudEndureのサービス自体が移行に用いる変換サーバ用インスタンスや、移行後のインスタンスを作成する必要があるため、IAMユーザーを指定のポリシーで作成する必要があります。なので、まずはポリシー情報をコピペするために、画面右の「Setup&Info」→「AWS CREDENTIALS」→「The Project must have these permissions」
上記をクリックすると別窓で以下のようなポリシー定義のJSONが開きます。

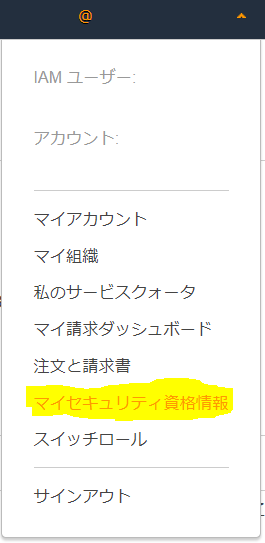
移行先となるAWSのアカウントで右上のユーザー名から「マイセキュリティ資格情報」を開きます。
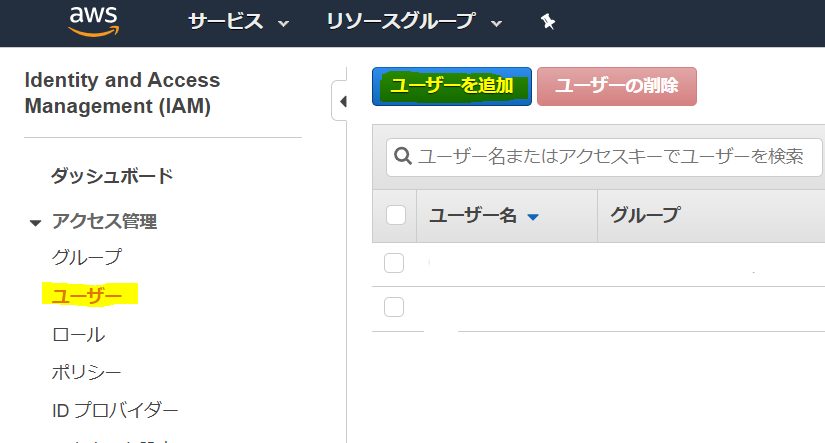
「ユーザー」→「ユーザーを追加」を選択します
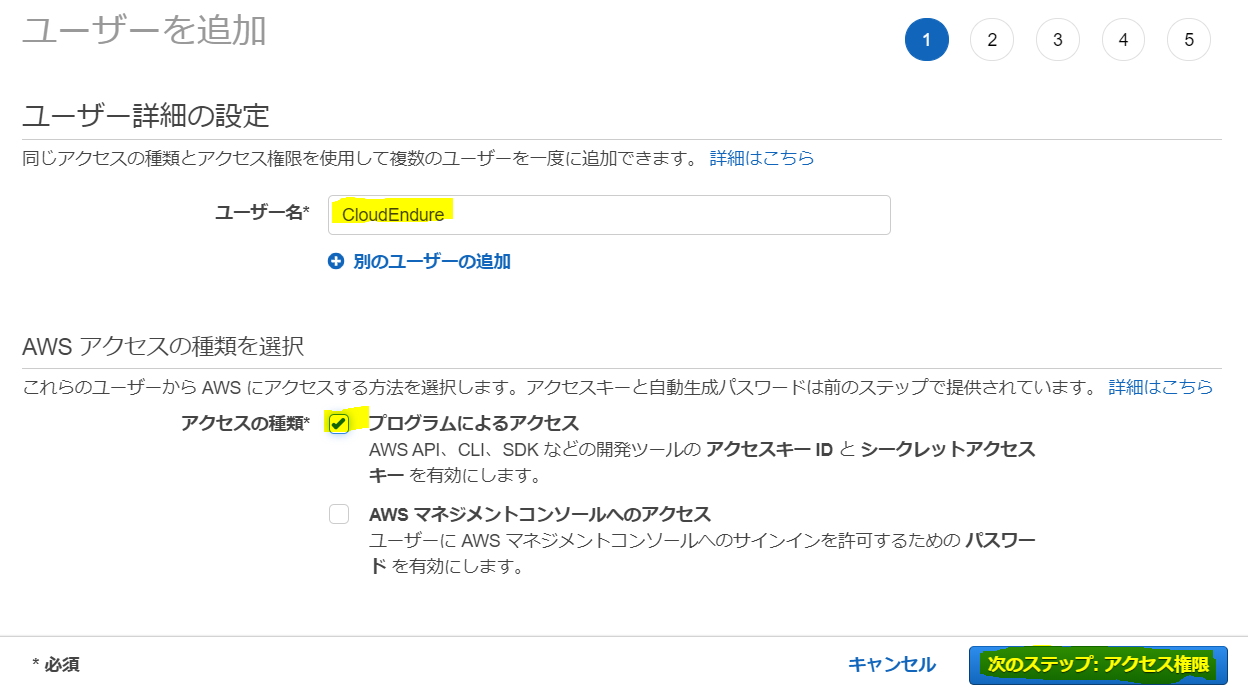
適切なユーザー名を入力し、アクセス種類は「プログラムによるアクセス」のみで「次のステップ」。
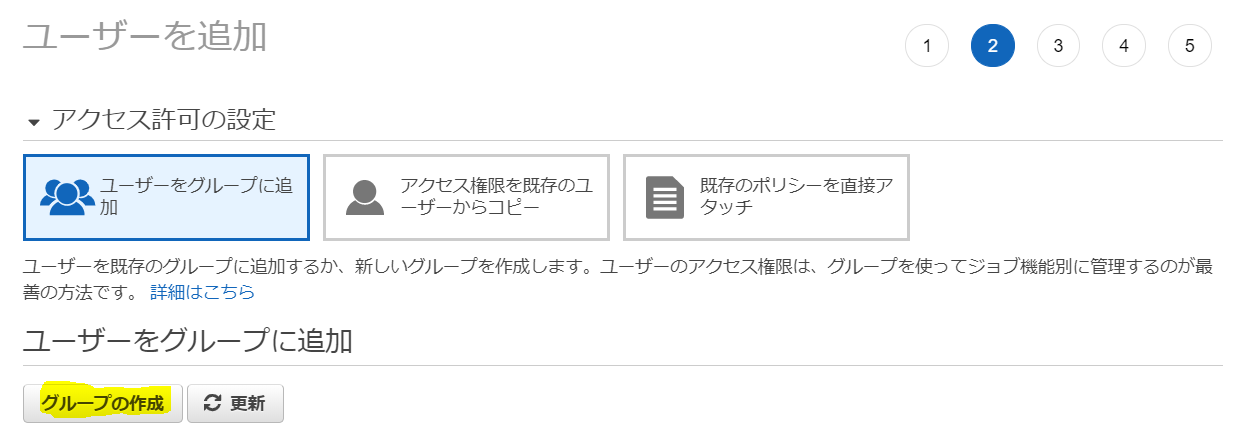
「グループの作成」をクリック
「グループ名」を適宜入力し、「ポリシーの作成」をクリック
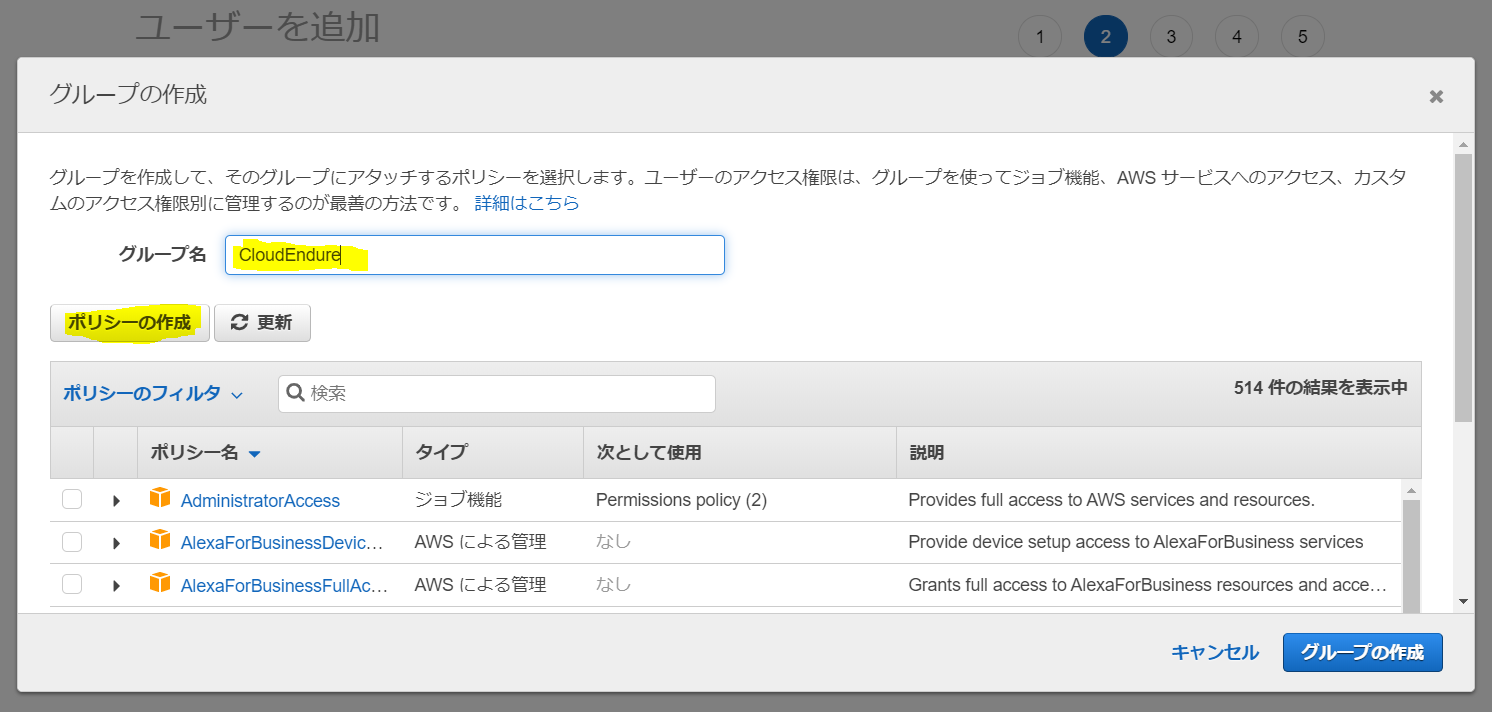
別窓が開くので、「JSON」を選択して、下の欄に先ほどのJSONをペーストし、「ポリシーの確認」をクリック。
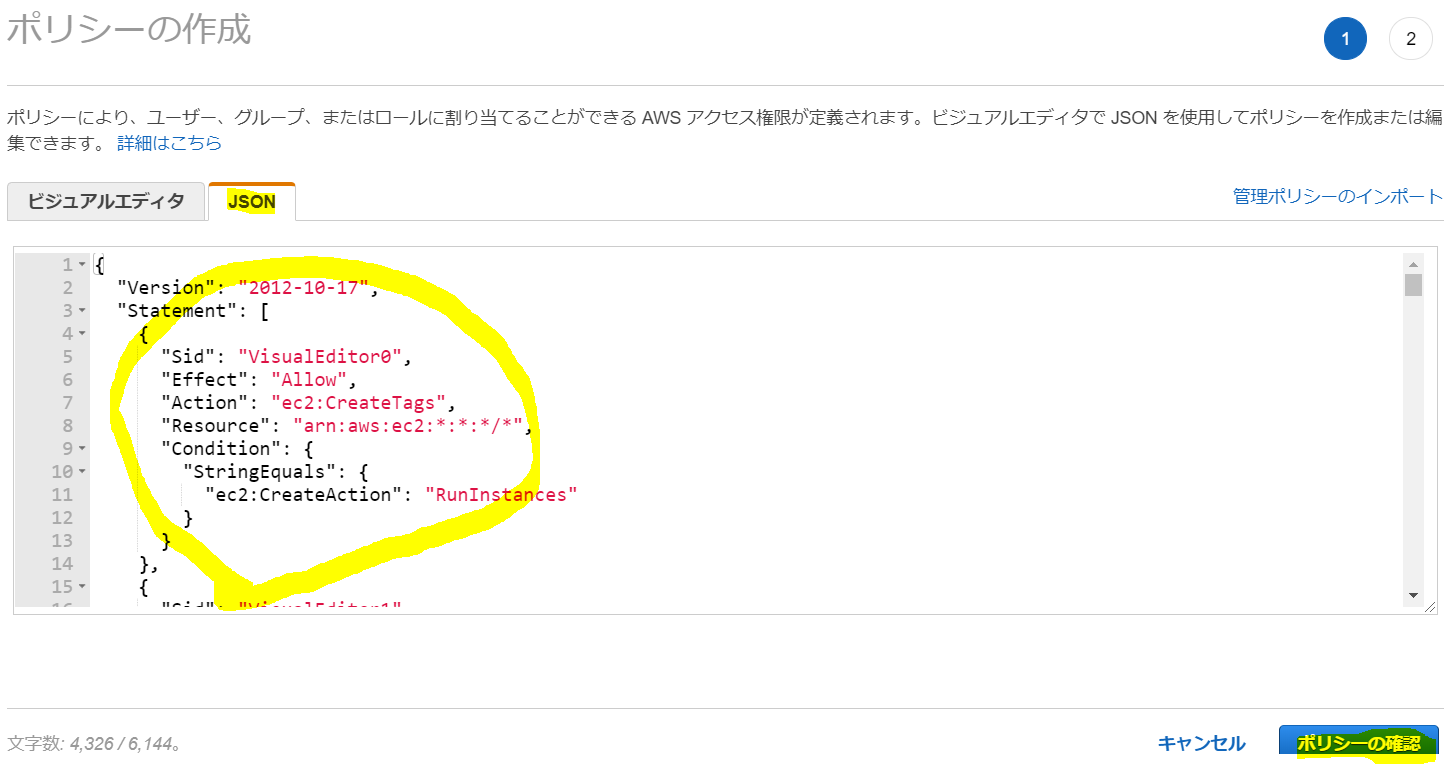
名前を適宜入力して「ポリシーの作成」をクリック
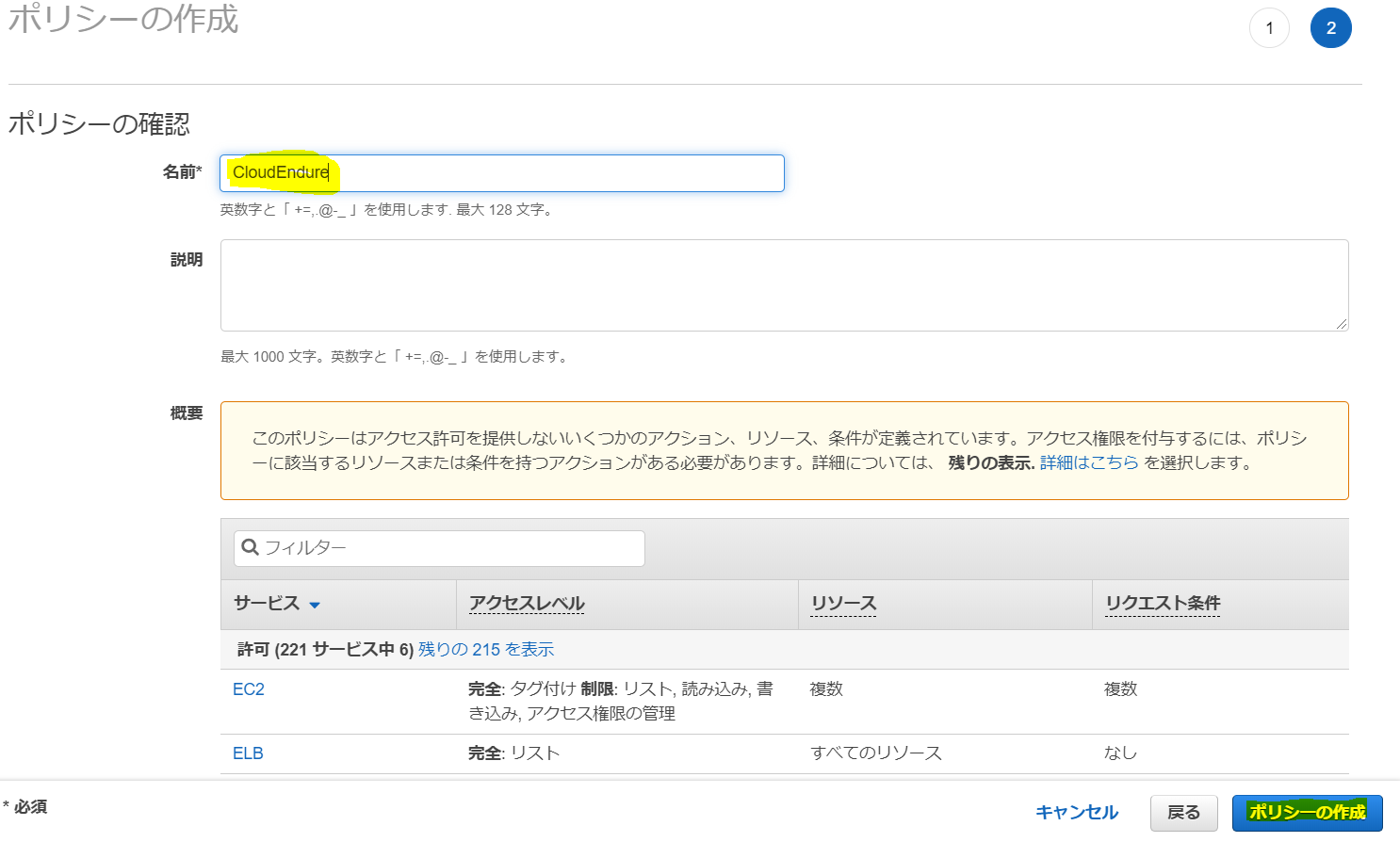
ここでさっきのグループ作成画面に戻り、今作成したポリシーを検索して見つけ、チェックを入れて「グループの作成」をクリック
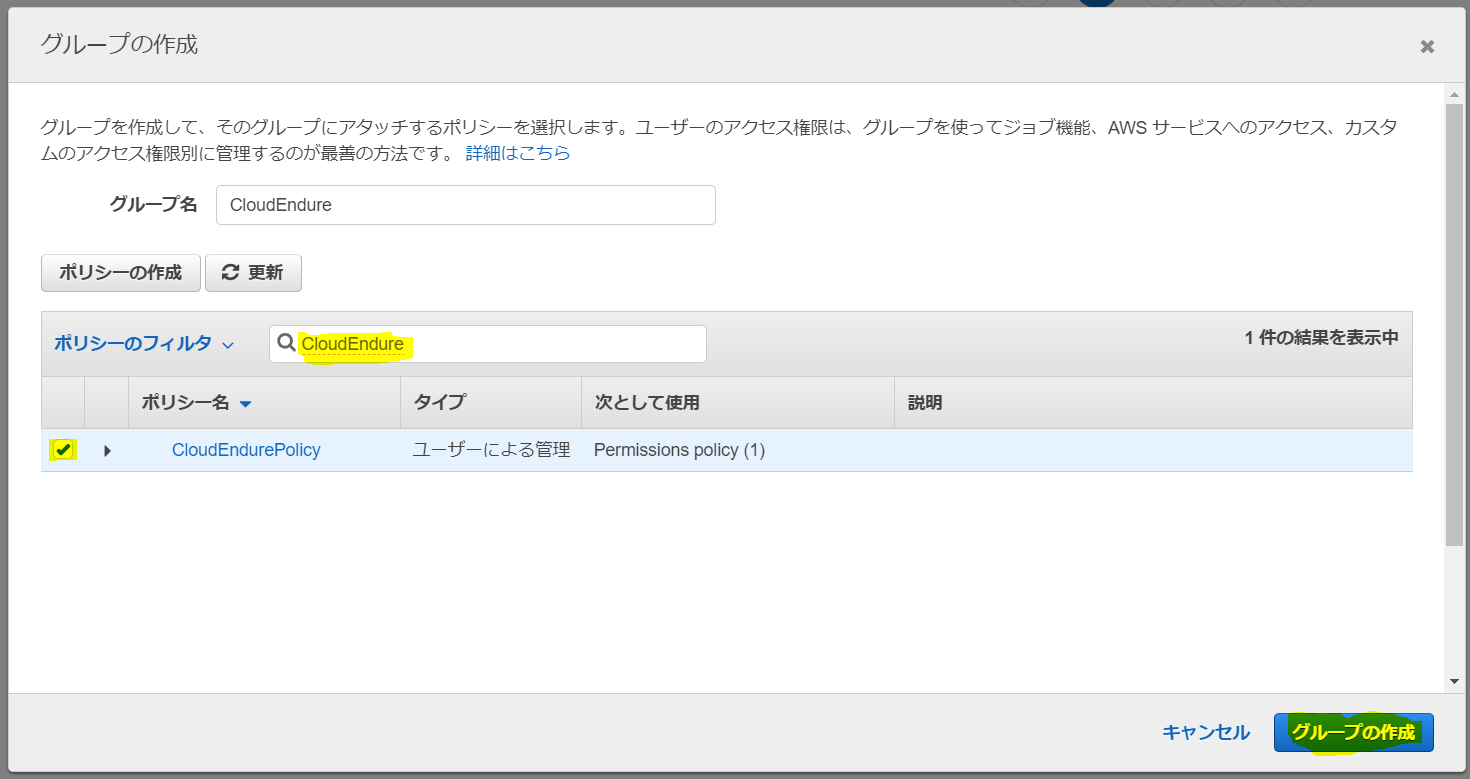
ユーザー追加画面に戻るので、今作成したグループを選択して「次のステップ」をクリック
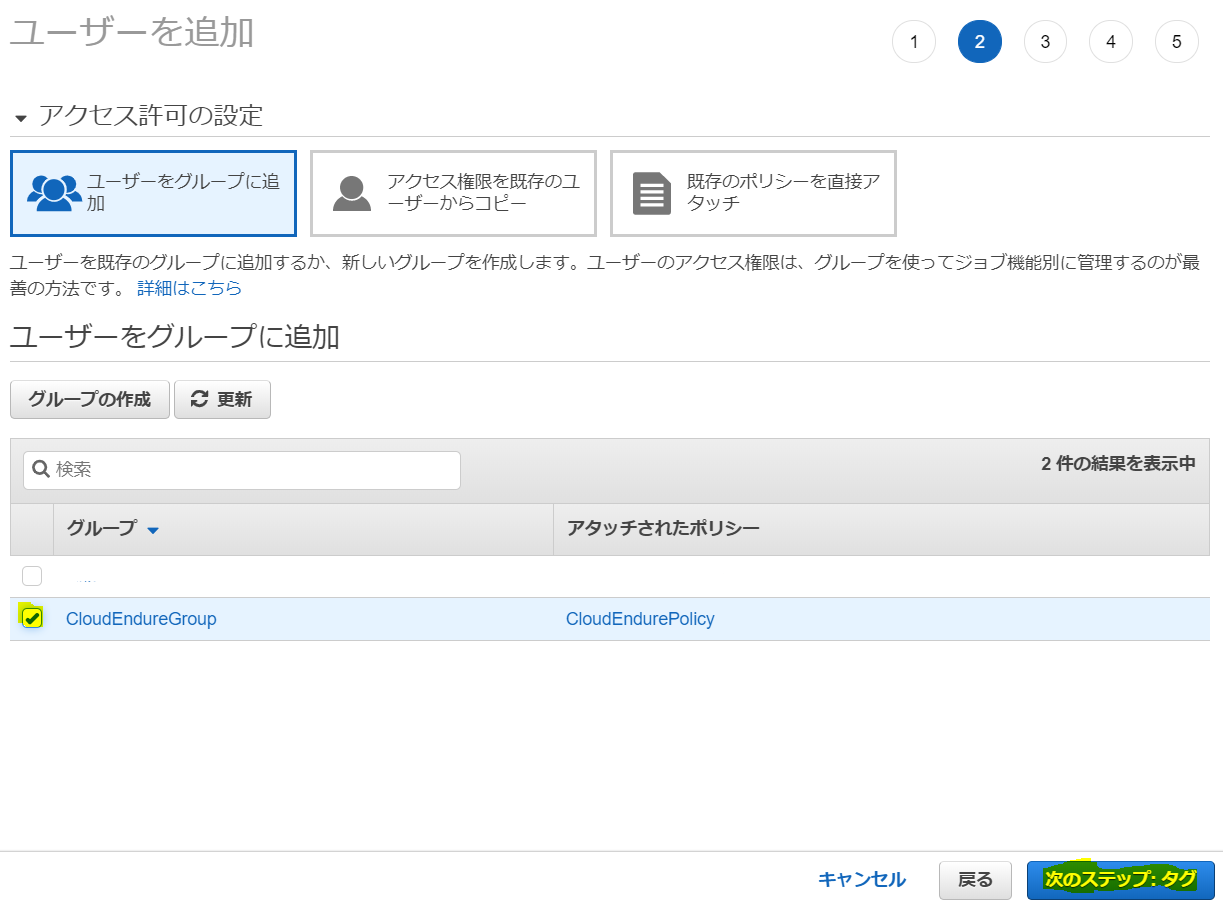
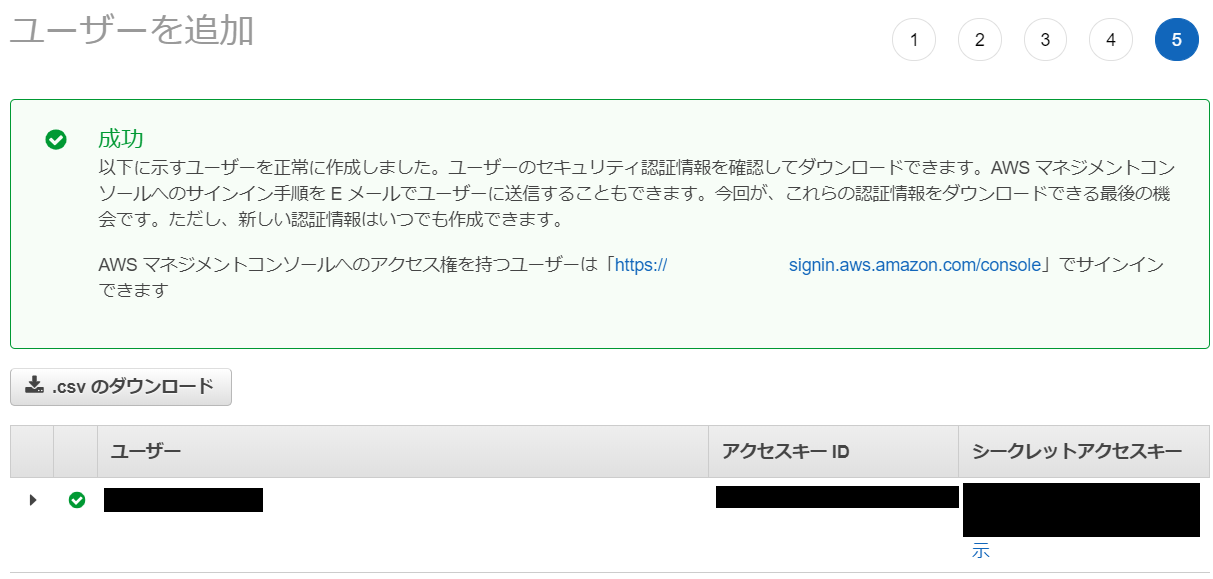
タグは好きに設定して、最後の確認を終えればIAM作成は完了です。アクセスキーとシークレットアクセスキーを保存しておきます。
移行先のAWSを設定します。
以下の設定は必須です。
- VPCとサブネットを作成
- 適切なセキュリティグループを作成
また、ネットワーク設定がDHCPに強制変更されてしまうので、特にドメイン環境の場合には以下の設定も必要です。
- DHCPオプションセットでDNSを有効なADサーバを設定しておく
この設定をしておかないと、なぜかローカルユーザーでもリモートデスクトップでログイン不可になってしまいました。
特にドメインコントローラーを移行する場合には指定されることが多い「127.0.0.1」のローカルループバックアドレスもDNSから消去されてしまいますので要注意です。
CloudEndureの移行パラメーター設定
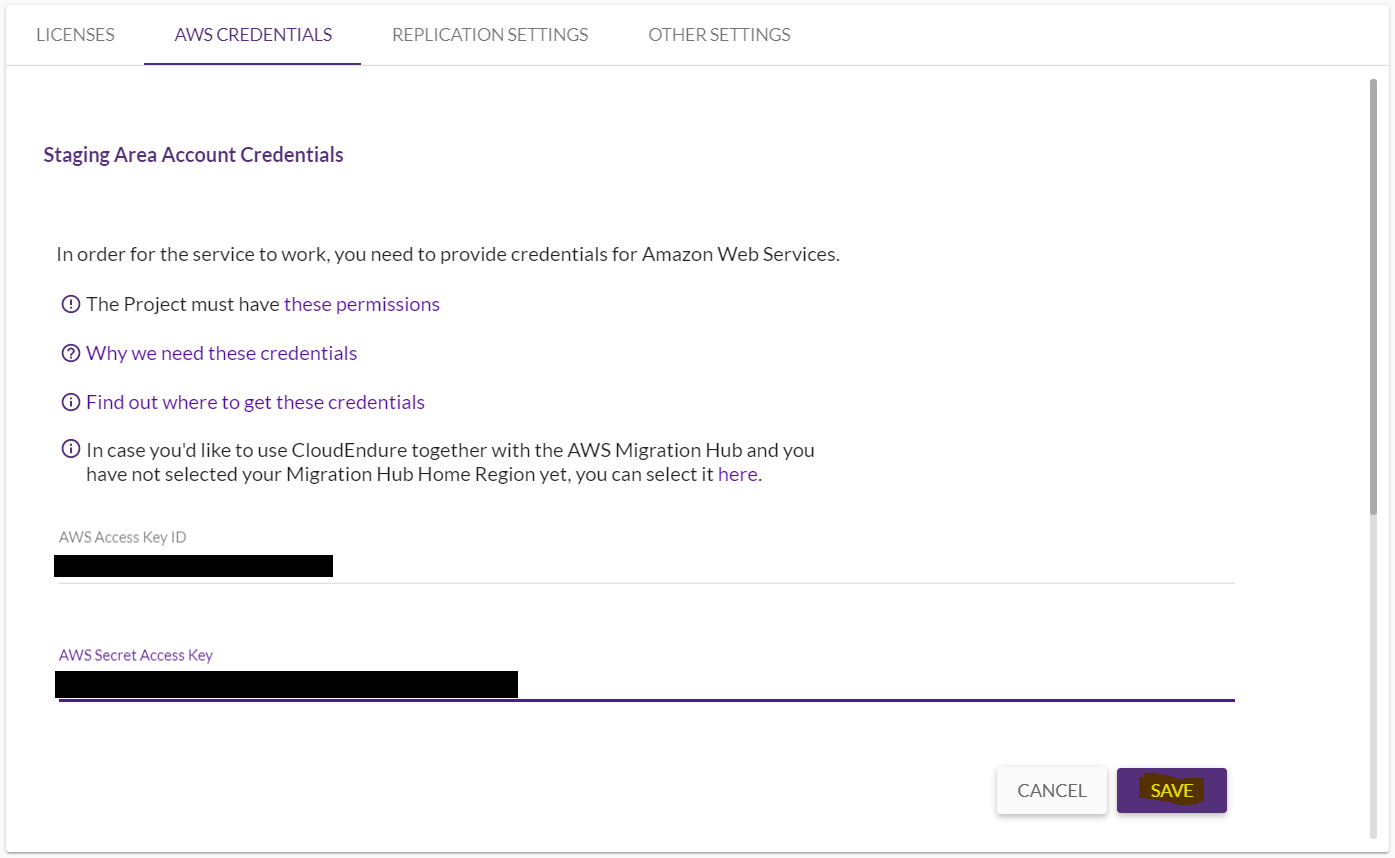
CloudEndureのWeb画面に戻り、アクセスキーとシークレットアクセスキーを入力して「SAVE」をクリックします。
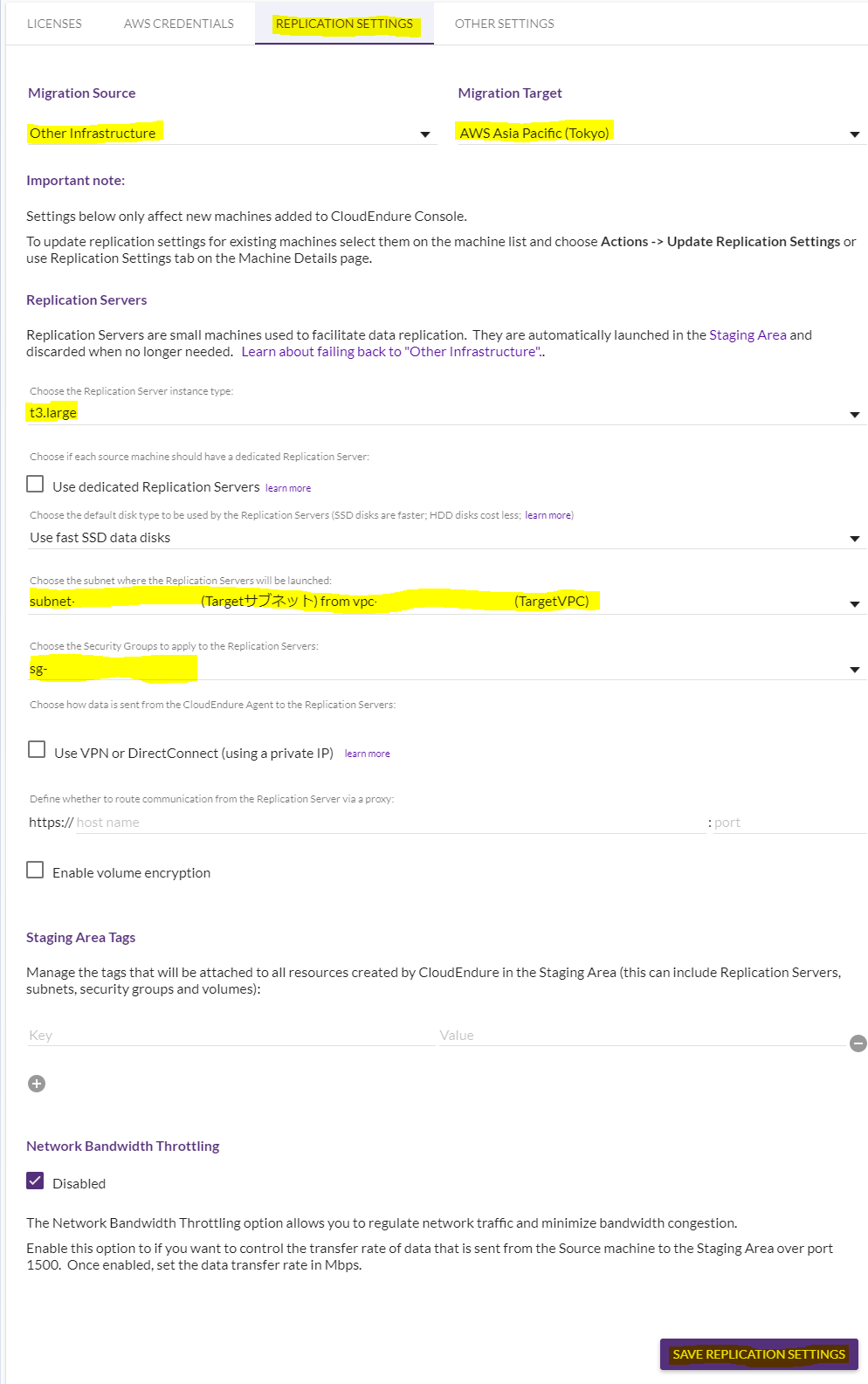
次に移行先の設定です。
画面上の「REPLICATION SETTINGS」タブを選択すると以下の画面になりますので、以下項目を設定します。
- Migration Souce
ソースの場所です。オンプレミス未対応しているのでその場合には「Other Infrastructure」を選択します。
- Migration Target
移行先の場所です。今回は「AWS Asia Pacific(Tokyo)」を選択します。
- Replication Servers
レプリカサーバーの詳細です。
インスタンスタイプ、VPC、サブネット、セキュリティーグループを選択できます。
こればレプリカする際に自動的に起動するサーバなので、適当に「t3.large」と、レプリカ先のサブネットを選択しました。
最後に右下の「SAVE REPLICATION SETTINGS」をクリックして設定項目を保存します。
レプリカ準備を開始する
この手順を実施すると、レプリカサーバが自動帝に起動して、移行元サーバのイメージ転送が始まります。
そして初回の転送が終わると、それ以降ずっと差分を転送し続けます。
初めにCloudEndureのWeb画面で右メニューから「Machines」を選択します。
すると、以下の画面になりますので、「Download・・・」を右クリックして「リンクのアドレスをコピー」します。
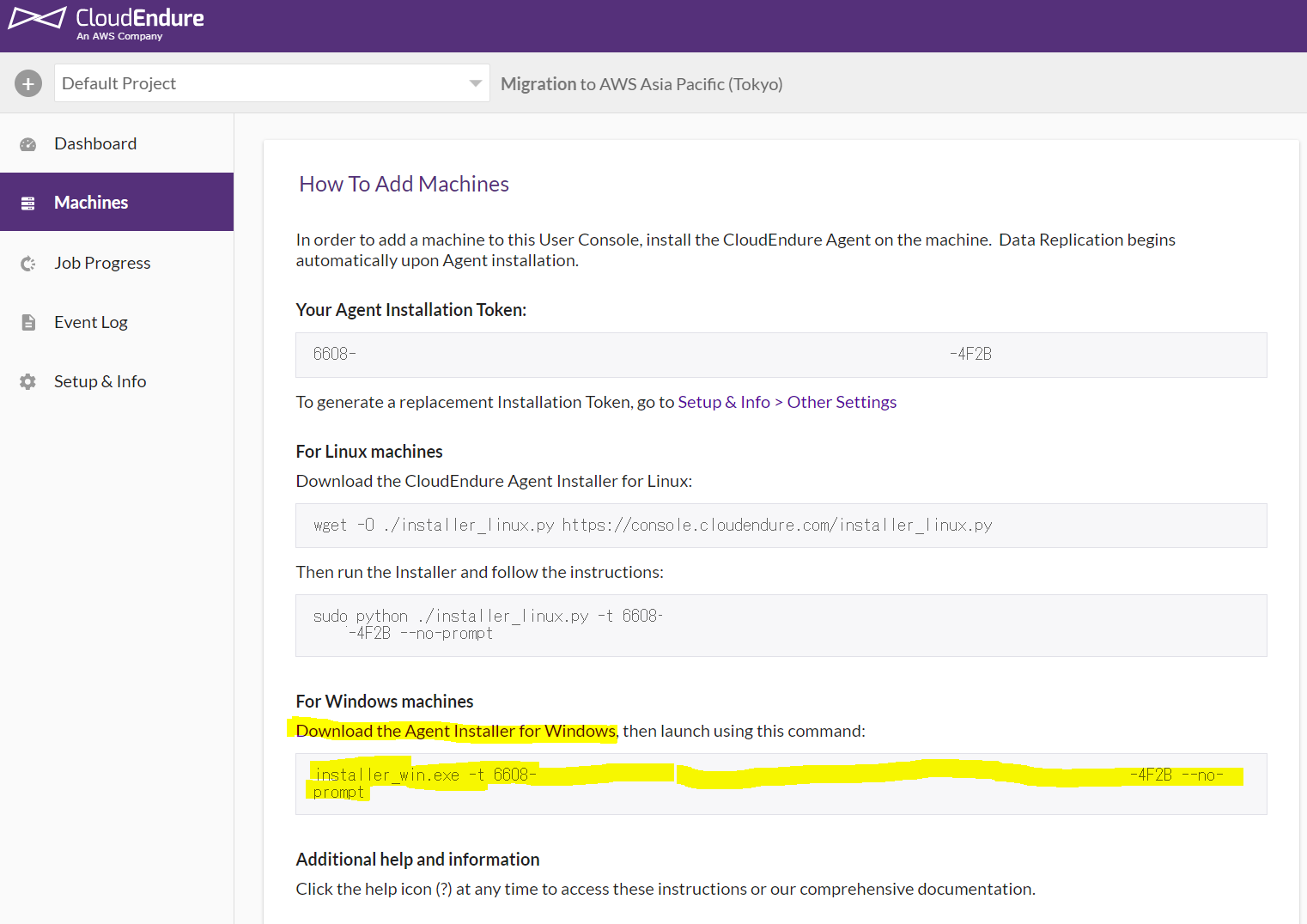
次に移行対象のサーバーにログインし、上のリンクアドレスをIEか何かで開き、対象のファイルを「名前を付けて保存」しておきます。(この場合はA:\に保存)
レプリカを開始する
レプリカはインストールが終わったら自動開始
CloudEndureのWebのリンクの下の行にあるコマンドをコピーして、サーバのコマンドラインにペーストして実行します。
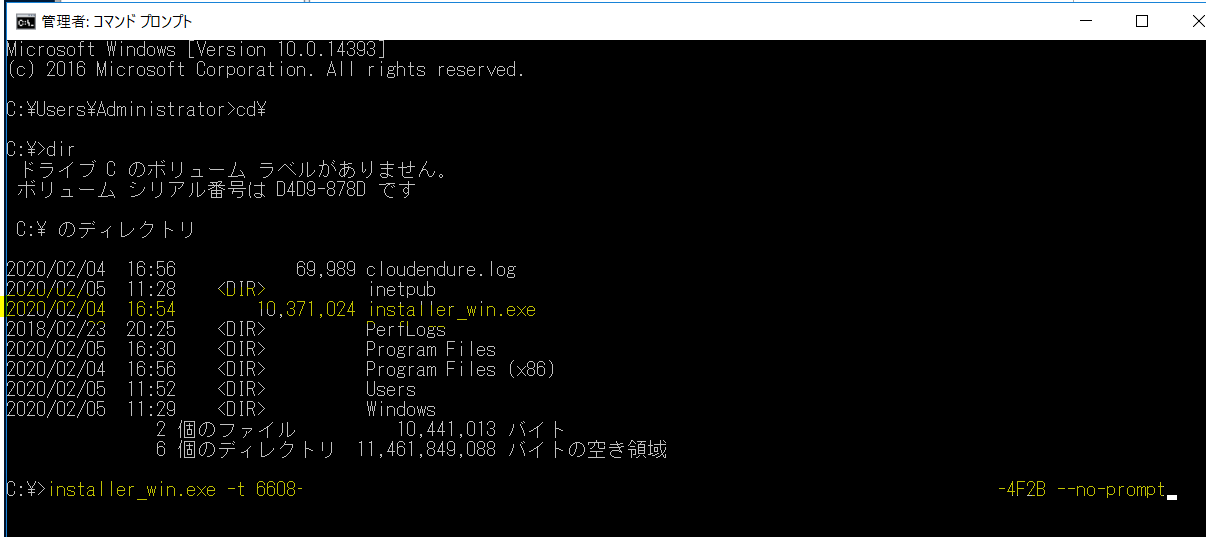
インストールが成功すると以下のようになります。
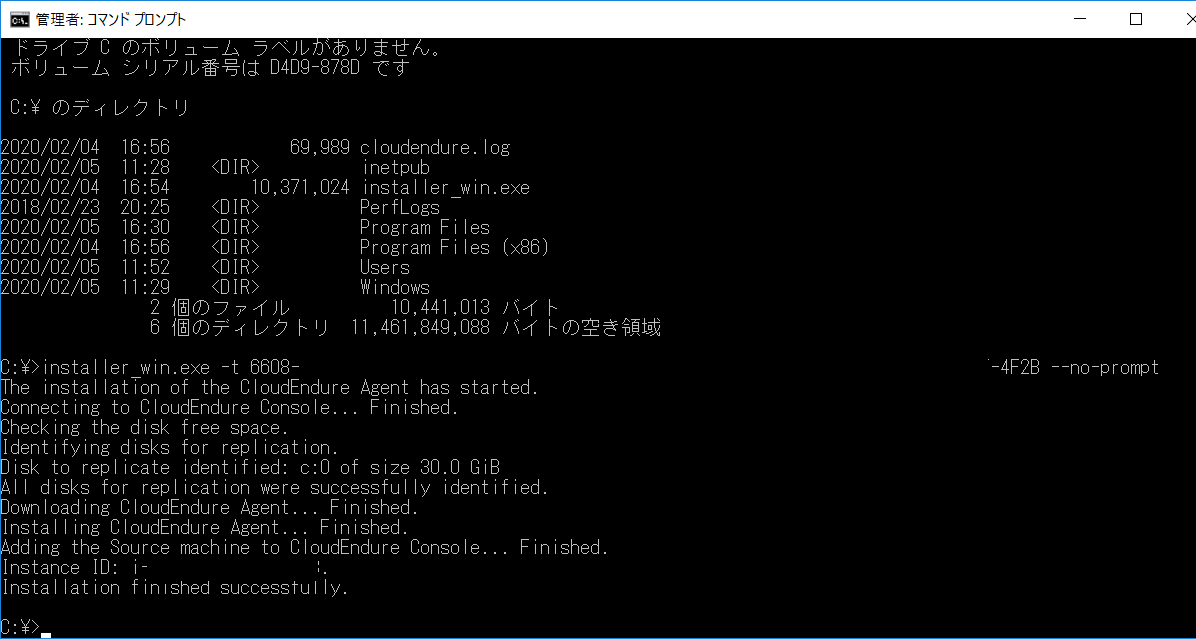
このように成功すると、この瞬間から自動的にレプリカが始まります。
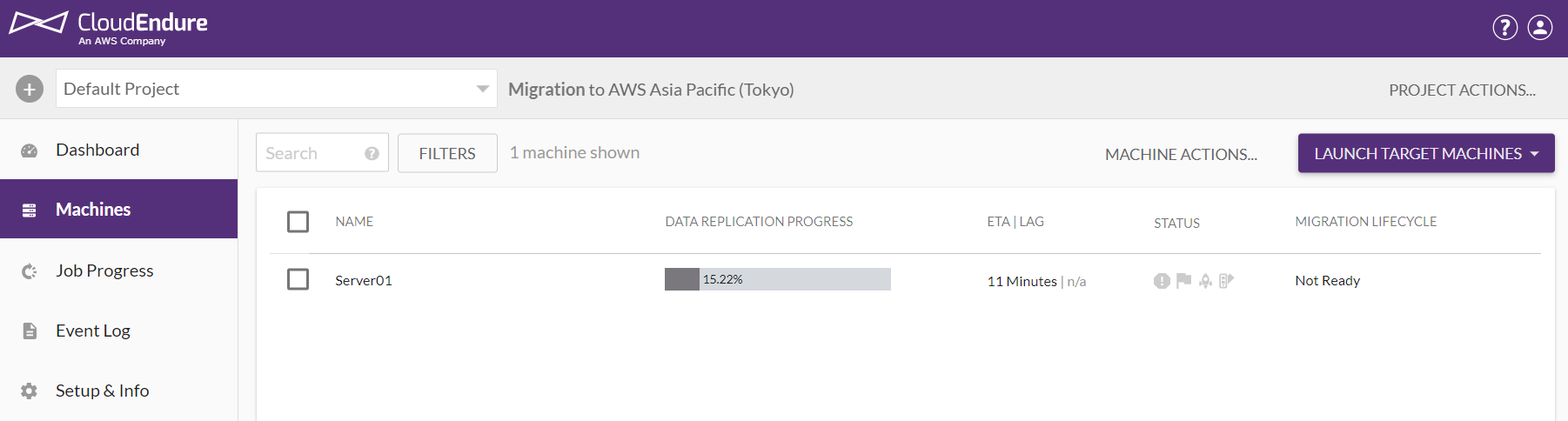
まずはこのグラフが100%に達するまで待ちましょう。
WindowsServer2016にAD機能を追加しただけのサーバはおよそ10分で完了しました。
レプリカ中
レプリカを開始して数分間はNW帯域目いっぱいの転送が発生します。
この検証はAWSの別VPC間での転送となりますので、300-500Mbps程度が連続していました。
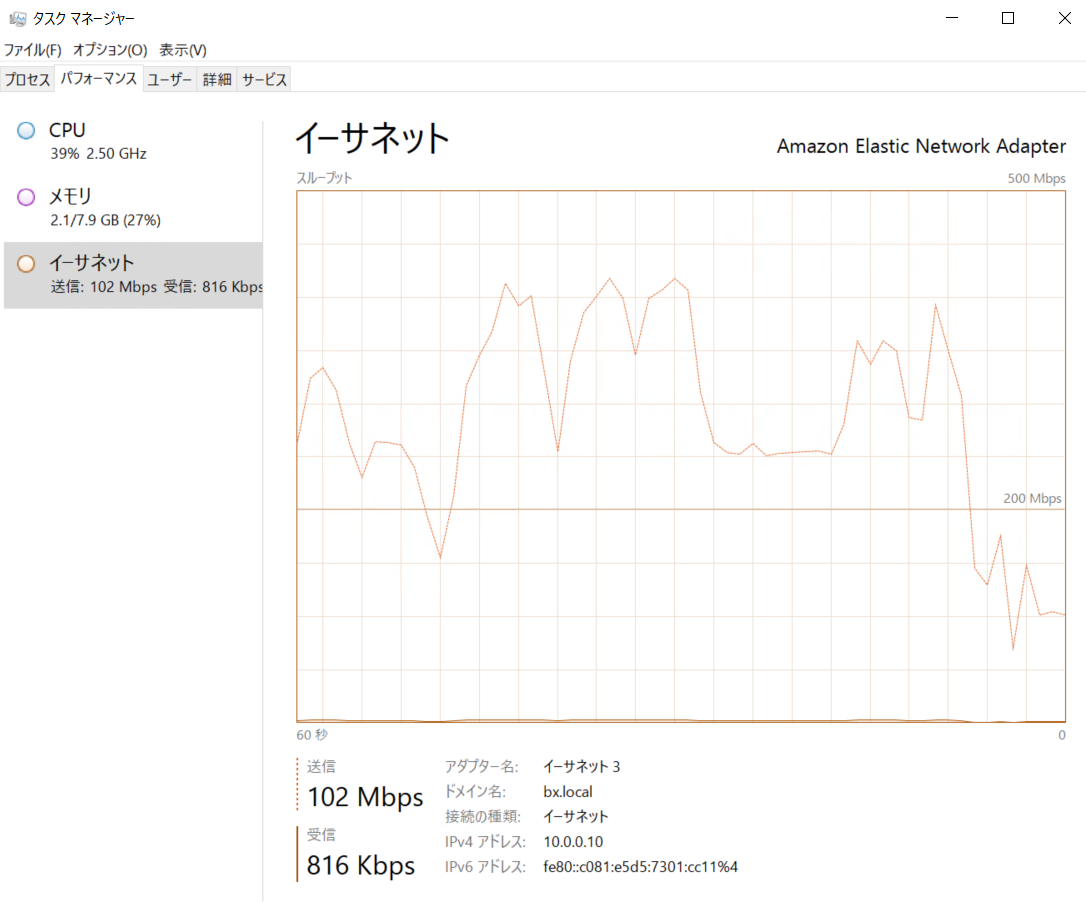
しばらくすると、以下のようにCloudEndureのWebコンソールで同期を完了している表示に代わります。

同期完了処理に移った際の使用帯域は以下のような感じで、数百Kbpsと約千分の一程度まで下がります。
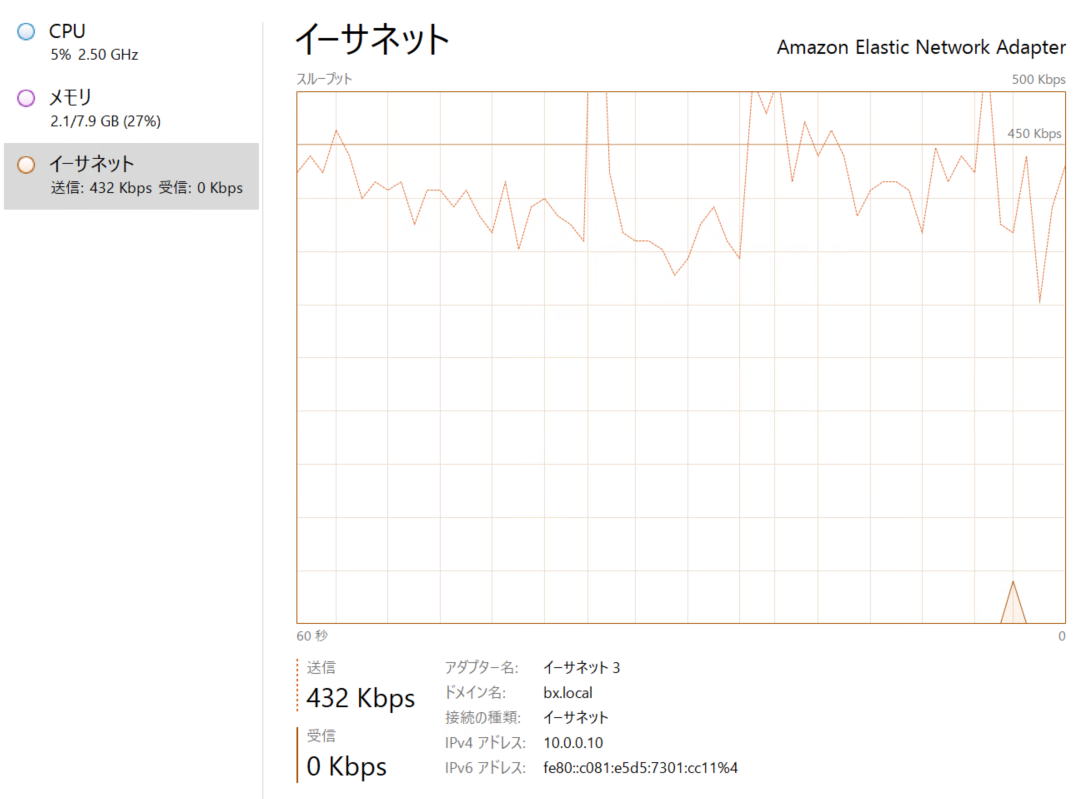
この状態も数分間かかりますが、今回の検証では約10分程度でレプリカが完了し、以下のような表示に変わりました。

この表示になったら、いつでもテストサーバーをデプロイできる状況です。
デプロイのテストを実施しよう
デプロイ前にパラメーターを確認しよう
ここまでくればあと一息です。
ワンタッチで目的のサーバをデプロイしましょう。
デプロイはCloudEndureのWebコンソールで右メニューのMachinesから目的のサーバを選択し、画面下の「LAUNCH TARGET MACHENE」から「TEST MODE」を選択するだけです。
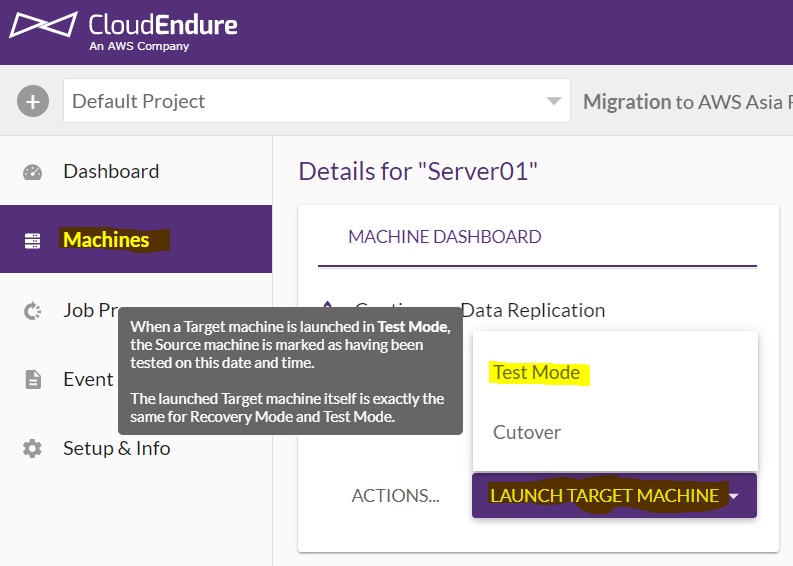
が、その前にどのようにデプロイするのか設定を確認しましょう。
以下のように「BLUE PRINT」タブに多くの設定項目が並びます。
特に留意する必要があるのが、以下になります。
- Machine Type
- インスタンスタイプを選択します
「Copy Source」で同じようなスペックも自動選択できますが、なぜかより大きなインスタンスタイプとなりました - Subnet
- 事前に作成しておいたサブネットを選択します
- Security Group
- 事前に作成しておいたセキュリティグループを選択します
- Private IP
- 「Custom」を選択して新しいVPC・サブネットに適切なものを設定します
- Disks
- ディフォルトで「Provisioned IOPS SSD」が選択されるため、「汎用SSD」で十分な場合には要変更です
このフェーズでAWSコンソールを見てみるとコンバーターが1台新規で出来あがります。
コンバートが終わって、新サーバの作成が始まると「Starting Creating…」に表示が変わります。
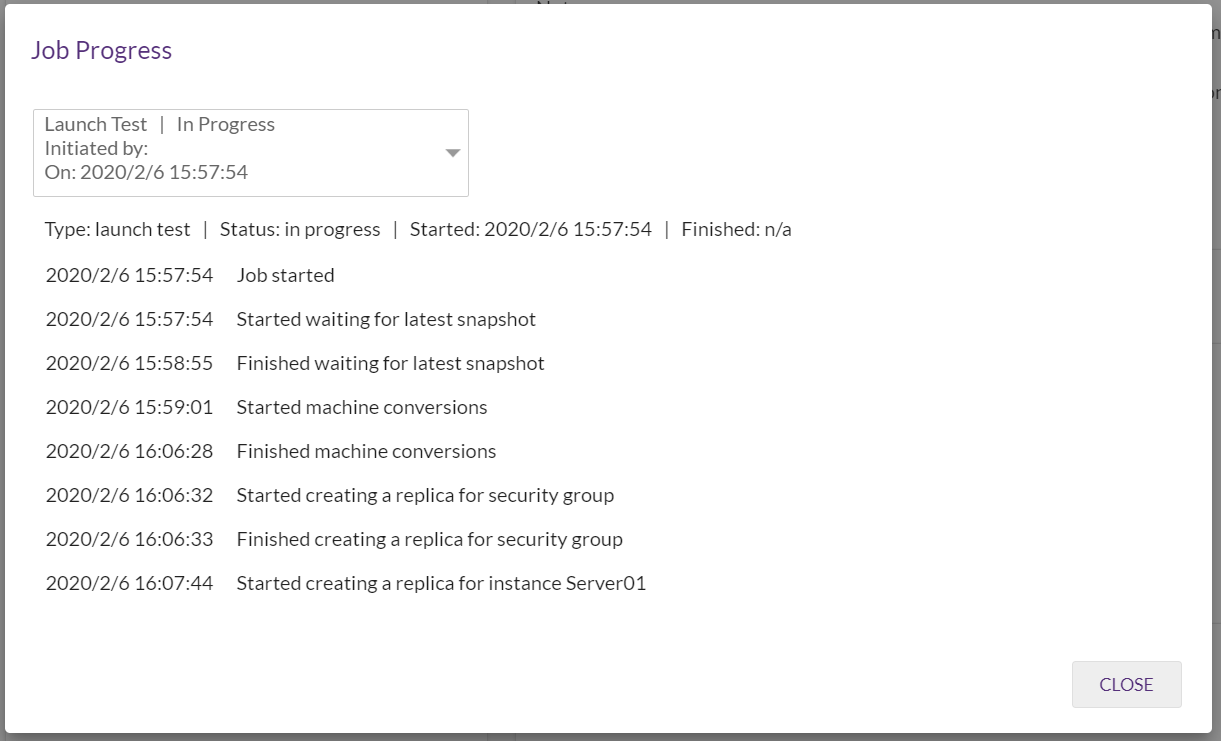
Job finishedと記録されました。
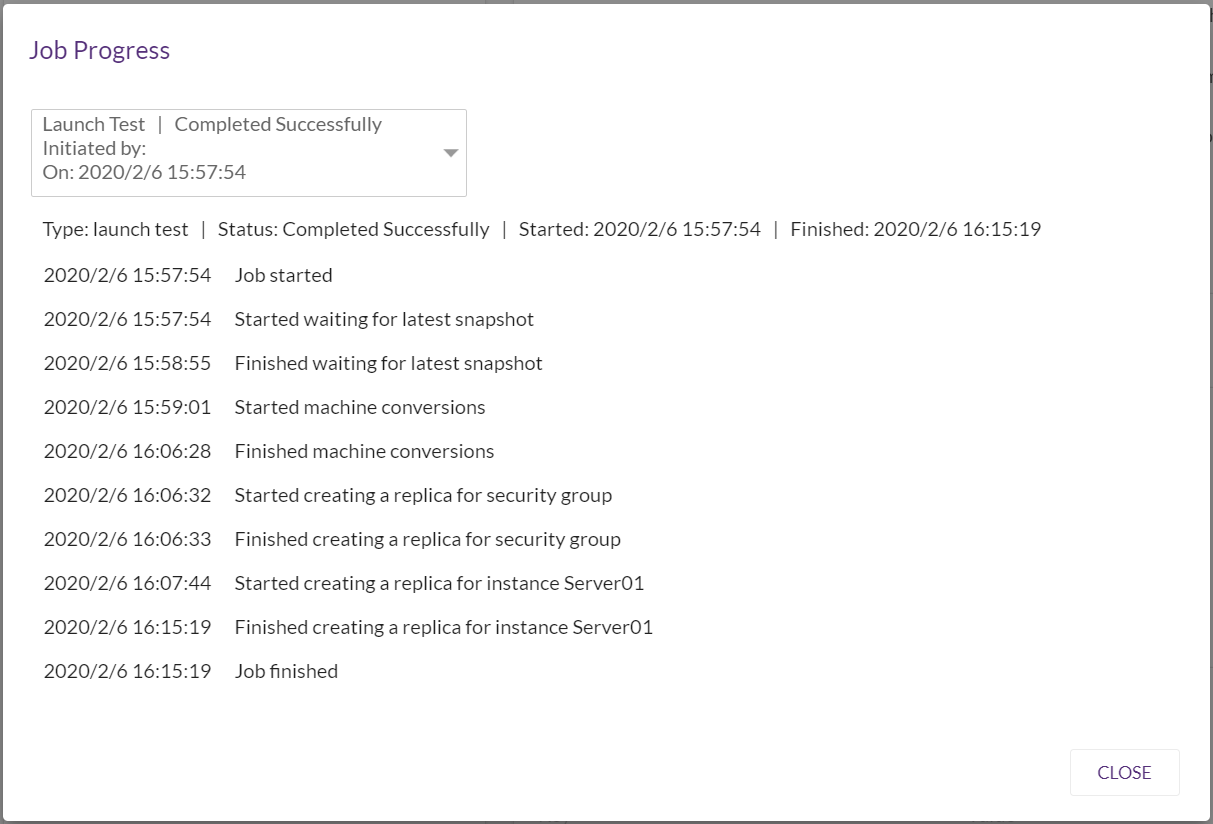
AWSコンソールを見てみると・・・
できました!

しかし、なぜかインスタンスタイプが「C4.large」になっています。
「Copy Source」を選択せずに指定したほうが良いかもしれません。後で変えられますが。
テストのデプロイが完了したので接続します
リモートデスクトップしましょう
早速接続してみましょう。
「パブリックIP」をコピーして…
お!RDPは有効になっていますね!
おっ!これも来た!いけるかっ?!
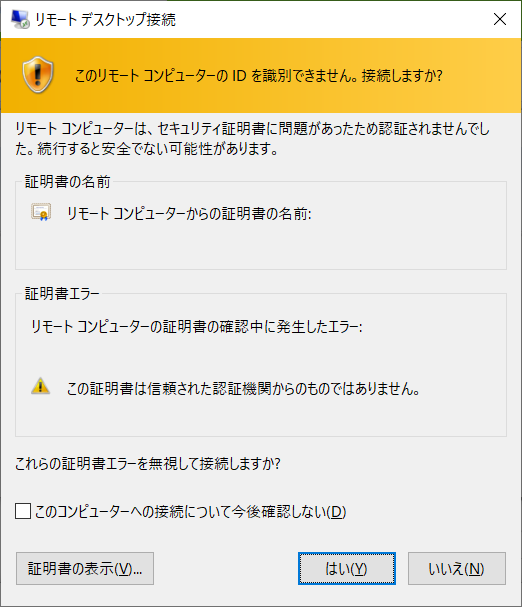
ここ、ドキドキしますね~

来ました~~~!
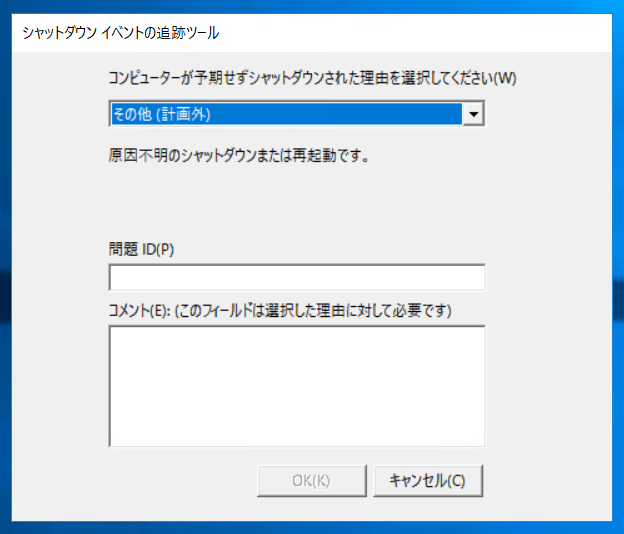
電源ONし続けている間にレプリカし続けるという仕様上、突然電源をぶち切られたような状況になるため、この表示が出ることは仕方ありませんが、逆にきちんとレプリカで来ていたことがわかると思います。
テストデプロイされたサーバーの状況は?
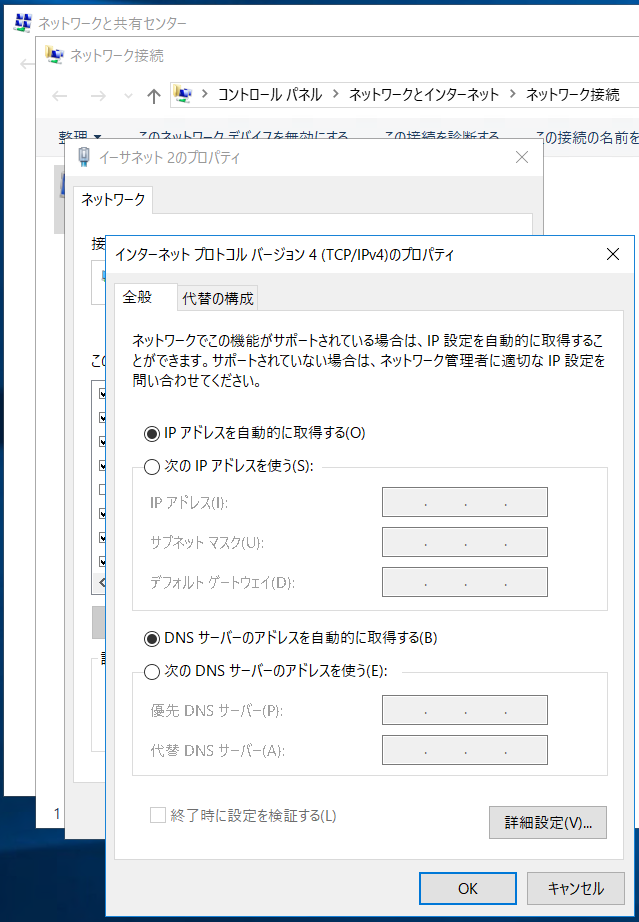
判明しているところとしては、IPアドレスやDNSサーバはDHCPに強制的に変更されます。
AWSはそれを推奨しているので当然ですね。
そのため、IPアドレスの固定はレプリカ時に、DNSの指定はDHCPオプションセットで行いましょう。
以上、テストのデプロイまででした
ちなみに、テストのデプロイを繰り返した場合、既存のデプロイされたインスタンスは自動的に削除され、最新のものだけが残るような動きとなりますので、無駄なゴミが残ることはないようです。
カットオーバーでデプロイする
続いてカットオーバーの実施です。
テストのデプロイで問題がなかった場合には、本番のデプロイとして「Cutover」を実施します。
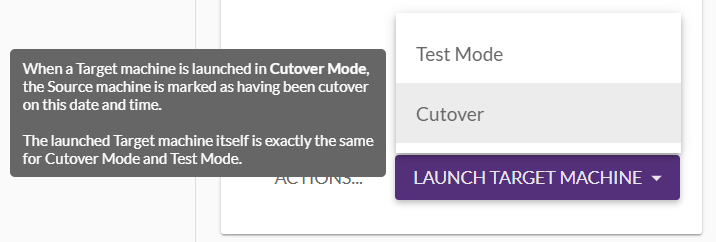
Cutoverの場合には、サブネットからインターネットGWからセキュリティグループなどをクリーンアップしているログが出ています。
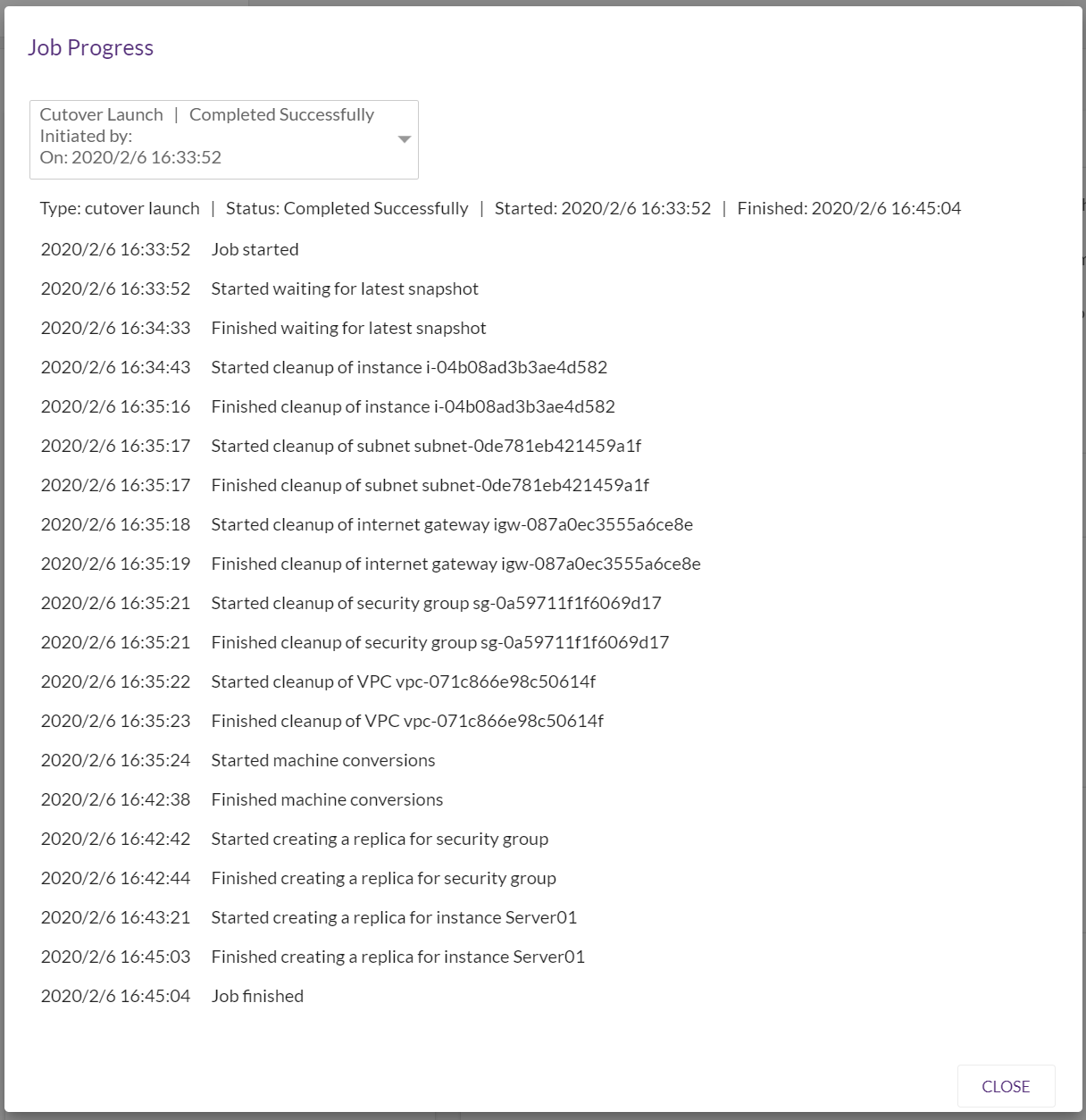
時間的にはテストとほぼ同じで、18-19分程度で出来上がりました。

カットオーバーされたサーバーの状況は?
早速リモートデスクトップしてみます。
コピーして…接続!と。
来ました!
よし!成功!
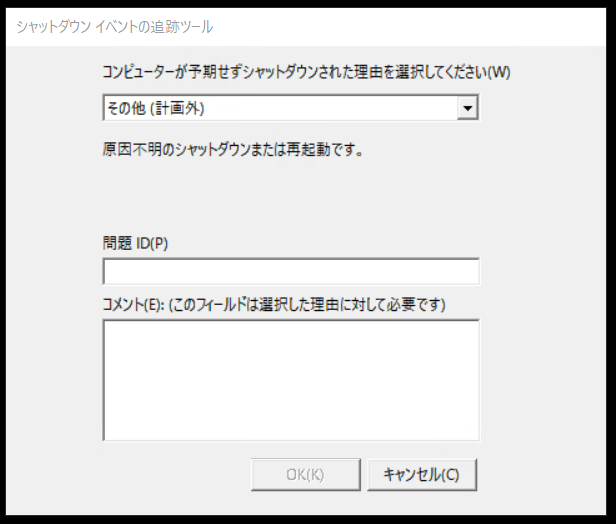
と、思ったけど、ちょっとまって。
なぜか「セーフモード」になってる・・・え。マジですか?
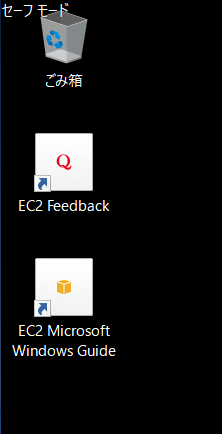
と、思ったら2分程度で突然リモートデスクトップが自動的に切断されてしまいました。自動再起動が走ったのかな?
もう一度RDP接続を・・・
直った!!!
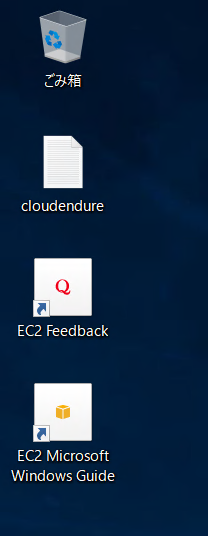
さっきは壁紙も黒一色で。あれ???と思ったのですが、もしかしたらCloudEndureのエージェントを削除して自動的に再起動が走ったのかもしれません。
→何度か試したところ、Cutoverデプロイした場合にはインスタンス起動の10分後(OS動作時間)に自動再起動が走るようです。
再起動後には通常モードで起動しているので、起動後は10分間ほったらかしてもいいかもしれません。
結果的には問題なしでした。
しかし、テストモードでのデプロイと挙動が異なるのが気になりますね。。。
嘘でした。テストモードでのデプロイも同じ挙動であることを確認しました。
単にテストモードでの確認したタイミングが10分経過していただけだったようです。
実際にもう一度試したところ、直後はセーフモードで起動し、10分後に自動で再起動するという、全く同じ挙動でした。
ネットワークのDHCPもテストモードと同様です。
ちなみに、CloudEndureのWebコンソールを見ると、「Cutover launched」という表示に変わっていますが、この状態でも何度でもCutoverすることができます。
オリジンサーバにやむを得ない事情で変更が生じた際や、Cutoverする際のパラメーターを間違えたり、思っていた動きと異なる動作をした際などに、Cutoverを何度でも実施できるのは心強いですね。
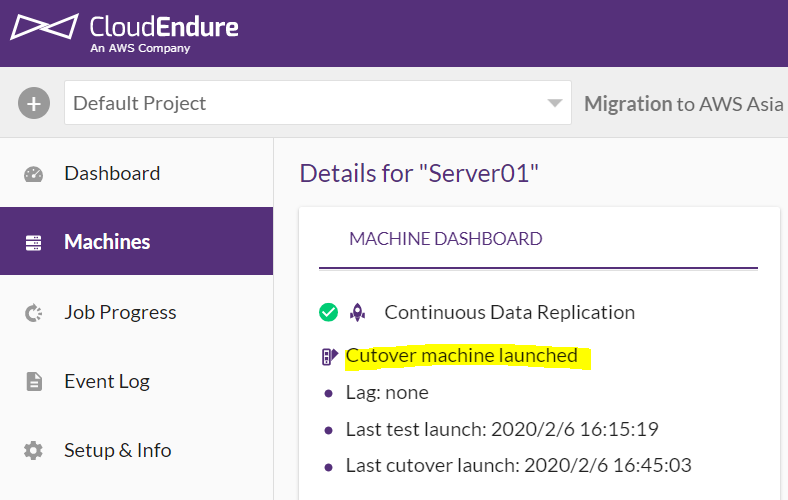
実際にインスタンスタイプを指定して再度Cutoverしてみました。できた!

以上、CloudEndureの検証レポートでした!
おまけ
最後に私が経験したエラーについて記述しておきます。
おまけ1 インスタンス作成時のリソース不足エラー
「ap-northeast-1dにc4.2xlargeのインスタンスの空きがありません」と言われました。
AWS東京リージョンに現在使用できるAZは3つありますが、AZによってまれにこのエラーが発生することがあります。今回は「ap-northeast-1d (apne1-az2)」でした。
その場合にはしばらく時間をおいてインスタンス分の空きが出るのを待つことでクリアできることもありますが、素直に別のインスタンスタイプを選択するほうが早く解決するでしょう。
この直後、t3.largeを再指定したところ、無事にCutoverが成功しました。

この場合の注意点としては、EBSボリュームまでは作成された後のAMIの起動に失敗しているので、Job終了時にEBSを後片付けしてくれないため、ごみが残ってしまいました。
下記のように状態が「Available」となっている利用されていないボリュームが溜まっていってしまう…ので、片づけましょう!
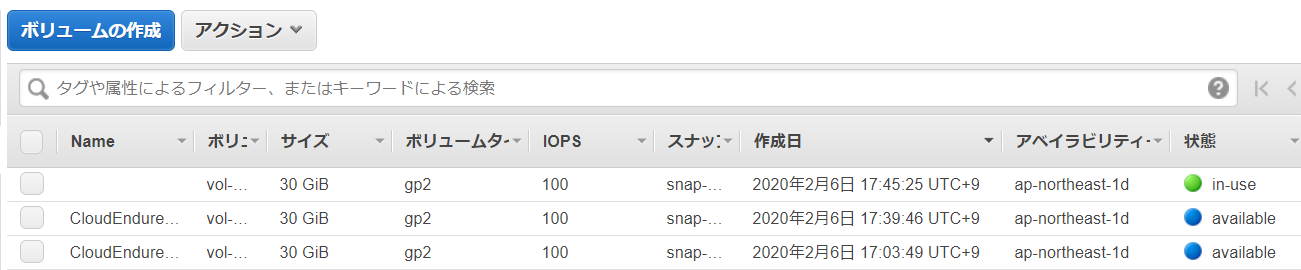
おまけ2 オリジンサーバを落としていた場合のエラー
「オリジンは停止しているけど、最後に同期したデータでデプロイできるのかな?」と思って試してみたら、見事にエラーで止まりました。エラーの内容はDNSの名前解決ができないというエラー。ちょっとわかりづらいですね。
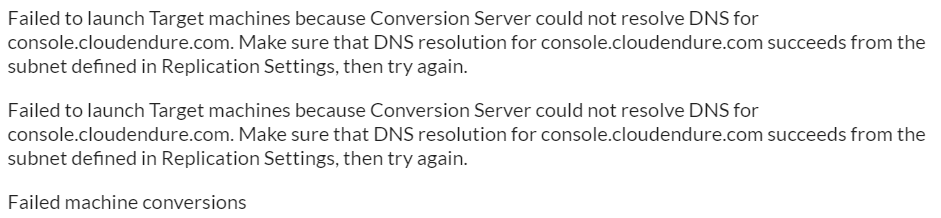
ちなみにこの場合にもAWS上に「CloudEndure Machine Converter」が残ってしまいますので、手動で削除する必要があるようです。
なお、夜間に落としていたオリジンサーバを起動すると、また同期処理が自動的に開始されます。
状態が「Continuous Data Replication」になれば同期が完了し、常時同期状態になっているので、デプロイ可能です。
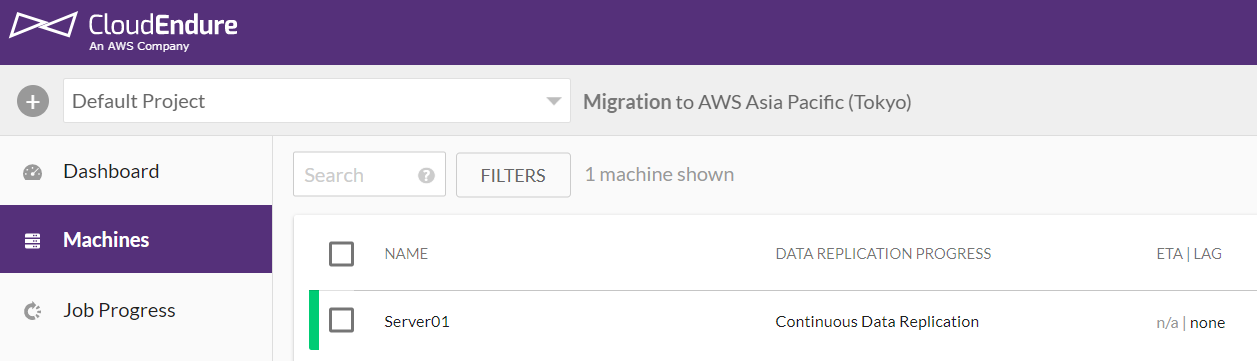
デプロイを実施すると、無事にデプロイが完了し(今回は停止状態でのデプロイを指定したのでStoppingになっています)、さらにコンバーターサーバは自動的にTerminatedされました。
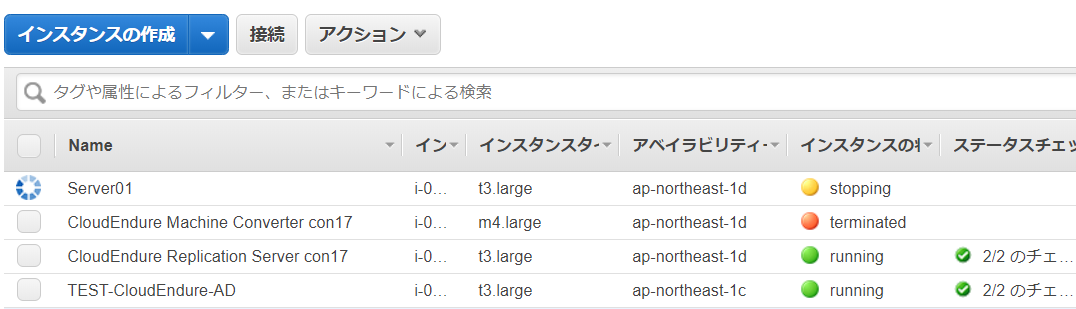
ちなみに、オリジンサーバを起動すると自動的にReplicationServerが起動する仕組みになっているようですね。オリジンを停止するとレプリケーションサーバも消える仕組みになっています。そのため、ClouedEndureのコンソールではレプリカサーバを検索して見つからない旨のエラーが出力されるのではないかと思います。