はじめに
アプリケーション開発において、ユーザーが入力したデータを永続化するにはDBを利用して実現するのが、スタンダードでしょう。
そして、DBを適切に扱うには、排他制御と言う概念を把握することが重要です。
では、排他制御とは何でしょうか?
排他制御を辞書で引いてみると、適切に用語を解説してくれているページがありましたので、引用します。
《exclusive control》同時に複数のユーザーがアクセスできるファイルやデータベースにおいて、一方が処理中の場合、他方のアクセスを制限すること。それによりデータの整合性を保つ。ロック。
goo辞書 - 排他制御
引用した通りの内容ではありますが、排他制御は、同時にアクセスがあった場合にデータの整合性を保つために必要なものです。
”データの整合性が保たれている”と言う事は、アプリケーションが想定したデータ構造になっている事を意味しますし、逆に”データの整合性が保たれていない”と言う事は、データが壊れている状態とも言えるのです。
データが壊れていると、アプリケーション的には予期せぬデータが取得される可能性がありますので、それは当然予期せぬエラーの発生に繋がります。例えば以下のような事が考えられます。
- 本来存在するはずの値が、未入力になっている(nullなど)ので、エラーになる可能性がある
- 数値を期待していたのに、数値として解釈できない値が入っているので、数値解釈エラーになる可能性がある
また、意味的にデータが壊れてしまっている状態も、不整合の一種と言えます。
DBの教科書で排他制御を説明する題材として、銀行の預金残高の更新に関して説明しているのを見かけた事は無いでしょうか?
- Aさんの口座には、預金残高には1万円ある
- Aさんの口座にBさんが5千円振込する
- Aさんの口座にCさんが3千円振込する
上記を順に実行したとして、Aさんの口座の残高は最終的に、1万8千円になっている必要がありますが、適切に排他制御を行って預金残高を更新するように実装されていないと、預金残高に狂いが生じる可能性があるのです。
これが、意味的にデータが壊れると言う事です。
下図は、正常に口座情報が更新されたパターンです。
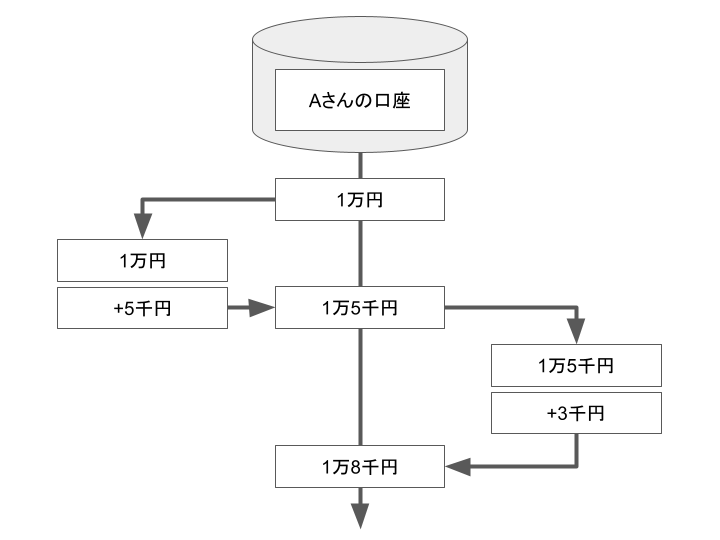
ただ、同時に更新されるとどうなるかと言うと…、排他制御に対して何も対策が無いと、下図のように最後に更新された情報で口座情報が更新される事になります。
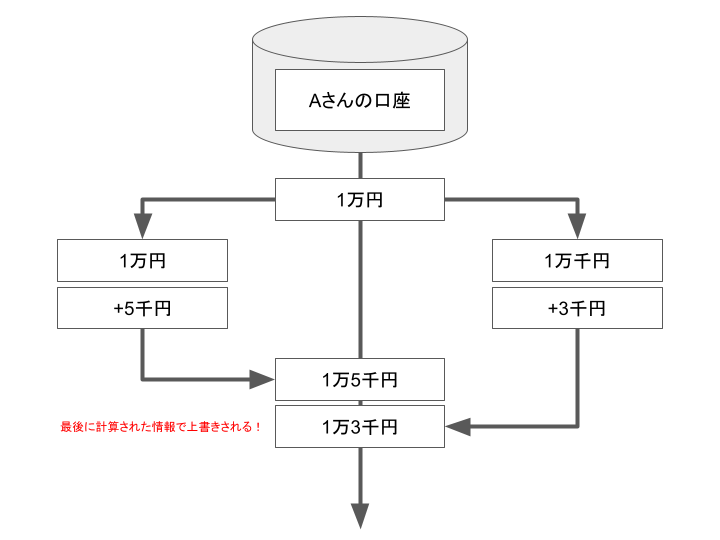
まとめると、以下のようになるでしょうか。
- 排他制御は同時実行時にデータの整合性を保つために重要なもの
- 排他制御をしっかり意識して設計・実装を行わないと、データの不整合が生じる事がある
- データの不整合には幾つか種類がある
- 予期せぬデータが生じる
- 意味的にデータが壊れる
前置きが長くなりましたが、本記事は、Webアプリケーション開発にフォーカスして、DBの排他制御についてまとめたものとなります。
なぜ『Webアプリケーション開発にフォーカス』と言う前置きを強調したのか?
Webアプリケーションは通常、三層構成になっています。
以下の通りですね。
- Webブラウザ
- Webアプリケーション
- DB
Webアプリケーションは、WebブラウザとWebアプリケーション間の通信に通常、http(https)プロトコルを用います。
DBと接続するのは、あくまでもWebアプリケーションが担いますので、WebブラウザからダイレクトにDBに接続する事はありません。
そして、http(https)プロトコルは、ステートレスプロトコルと言われています。
概念的に説明すると、通信のたびに、接続が開始され、データの通信が終わるとそのまま閉じられると考えて差し支えありません。
Webアプリケーションでは、画面の表示処理・画面の保存処理、と言ったものは、それぞれ別の通信により実現されるので、ユーザー的には連続性のある、画面の表示〜保存…と言う一連の操作が、DBの立場から見ると、実は非連続的なものになるのです。
後続で説明する、悲観的排他制御に関して、ネット上で良く見かける説明として、『行ロックして、排他制御が不要になったら最後にロックを解放する』と言う手続きで例示されているのですが、おそらくクライアントサーバーシステムのような二層構成の時代の名残として説明されているように思うのです。
そのため、本記事では、あくまでもWebアプリケーション開発における排他制御(クライアントサーバーシステムの事は考えない)と強調しています。
排他制御の種類
排他制御には、楽観的か悲観的かの2種類があります。
以下は、他サイトから引用したものです。
- 楽観ロック=楽観的排他制御
- 悲観ロック=悲観的排他制御
と読み替えてください。
楽観ロック(楽観的ロック)では、ある主体(利用者やプログラムなど)がシステムの共有資源(共有メモリ領域やデータベースの特定のレコードなど)にアクセスする際、資源を外部から利用できないようアクセス禁止にはしない。
悲観ロック(悲観的ロック)では、ある主体がシステムの共有資源を利用して処理を行っている最中に、頻繁に他の主体からの参照や変更の要求が行われる前提に立ち、処理開始時に他の主体によるアクセスを禁じる。
e-Words - 楽観ロック・悲観ロック
何やら小難しいように思われるかもしれませんが、本記事では、楽観的・悲観的かを考えるに当たり、実装には言及せずに、まずは概念として意味付けして行きます。
楽観的排他制御について
楽観的排他制御は、「きっと誰もデータを編集していないだろうな〜」、と言う前提で、排他制御をすると言う考え方です。
何らかの画面があると仮定して、楽観的排他制御では、その画面の保存ボタンを押す直前に初めて排他制御を行い、誰かが先に保存していないのであれば、そのまま保存を行い、誰かが先に保存しているようであれば、適切に判定を行いエラーにする、と言ったものになります。
まとめると、以下のような流れになります。
- (ブラウザ)画面を表示
- (ブラウザ)画面で保存ボタンを押す
- (アプリ)
- 排他制御を開始
- DBに変更を加える
- 排他制御を終了
悲観的排他制御について
悲観的排他制御は、「対象のデータは編集の頻度が多い。なので、編集開始時に”今編集中だから、誰も触らないでね!”って宣言しておく事を決まりにします」と言う考えで、早い段階で排他制御を開始するものです。
何らかの画面があると仮定します。その画面でデータを表示した瞬間に、排他制御を開始します。
誰かが先に排他制御を開始していれば、当然編集が行えないので、エラーにします。
排他制御の開始に成功すれば、誰も編集していないと言う前提の元、落ち着いてデータの編集を行い保存できると言う事になります。
保存やキャンセルを行なった際に、ロックを解放することで、排他制御の終了とします。
まとめると、以下のような流れになります。
- (ブラウザ)画面を表示
- (アプリ)
- 排他制御を開始
- (ブラウザ)画面で保存ボタンを押す
- (アプリ)
- DBに変更を加える
- 排他制御を終了
- (ブラウザ)画面でキャンセルボタンを押す
- (アプリ)
- 排他制御を終了
楽観的 vs 悲観的 vs 完全後勝
では、楽観的か悲観的かを適切に判断して、設計するにはどうすれば良いでしょうか?
ズバリ言うと、アプリケーションの要件次第でしょう。
仮に、楽観的排他制御方式を採用した場合で、保存時に排他が開始できない(既に誰かが保存した後)場合、ユーザーには画面の再表示を促して、入力をやり直してもらうと言う流れになるかと思います。
そのため、ユーザビリティ的には、悲観的排他制御に軍配が上がると言えるかと思います。
しかしながら、悲観的排他制御は、実装コスト・運用コストが、楽観的なそれと比べると高くなります。
また、アプリケーションは、ロックの解放を確実に行えるとは限りません。
Webアプリケーションにおいては、ブラウザを直接閉じてしまった場合の動作を適切にアプリケーションに伝達できるとは限りません。
また、対象端末が予期せぬ原因でそのままシャットダウンする(停電、OSの不具合によるブルースクリーン)と言う事もあり、ロックの解放を確実にWebアプリケーションに伝達できるとは限りません。
そのため、悲観的排他制御を採用するにしても、ロックの解放漏れがあった場合の運用対処についても、セットで考えなければなりません。
例えば、ロックの手動解放画面を提供して、何かあった場合に手動で解放できるUIを提供する…と言った事です。
(これは、クラサバでも発生する可能性があるので、そう言う意味では悲観的排他制御のロック解放漏れ問題は、どのような形態であっても考慮が必要です)
個人的見解を述べさせてもらうと、基本は楽観的排他制御を適用するのがベターかと思います。
全体は楽観的排他制御で囲みつつ、もし、特別な要件がある場合に、一部を悲観的排他制御の対象とするのが良いのではないかと、思っています。
また、完全後勝と言う第三の選択肢もあります。
これは、例えば備考みたいな入力項目があって、排他制御なしで、そのまま更新しちゃっても不整合は起きえない(最後に保存ボタンを押したユーザーの情報が適用されると言う意味でデータが壊れない)と整理して、「排他制御なしで完全に後勝ちにしてしまえ!」と言うものです。
オンライン処理やバッチ処理が複雑に絡み合い、楽観的排他制御だけで囲むと、ユーザビリティが低下する場合においては(バッチ処理で高頻度にトランザクションデータを書き換えてしまい、Web側の画面で高頻度で排他エラーが発生して、通常業務に支障を来すと言うケース)、一部を後勝にすると言う判断も正しかったりしますので、あえて排他制御を行わない組み合わせも、選択肢として無いことはありません。
実装について
排他制御の種類と概念について、理解が深まったところで、具体的にどのような実装をすれば良いのかについて考えて行きましょう。
楽観的排他制御の実装
楽観的排他制御の説明で良く見かけるのは、対象のテーブルに、バージョン列やタイムスタンプ列を設けると言うものです。
画面表示時(データ編集の基準となったタイミング)に対象データのバージョン値(またはタイムスタンプ値)を内部で隠し持っておいて、保存時に、隠し持った値・現在の値を比較します。
一致していなかったら既に誰かが保存した後であると判断できます。
一致していたら、最後に自らがバージョン値(タイムスタンプ値)を更新してコミットします。
実装には幾つか種類があり、考えられる限り、以下があるかと思います。
- UPDATEのWHERE句に対象列と隠し持った値が等価であるかの条件を含める
- SELECT ~ FOR UPDATEにより、処理のはじめで行ロックして、その結果の値・隠し持った値の一致確認を行う
下図は、SELECT ~ FOR UPDATEのパターンによる図解です。
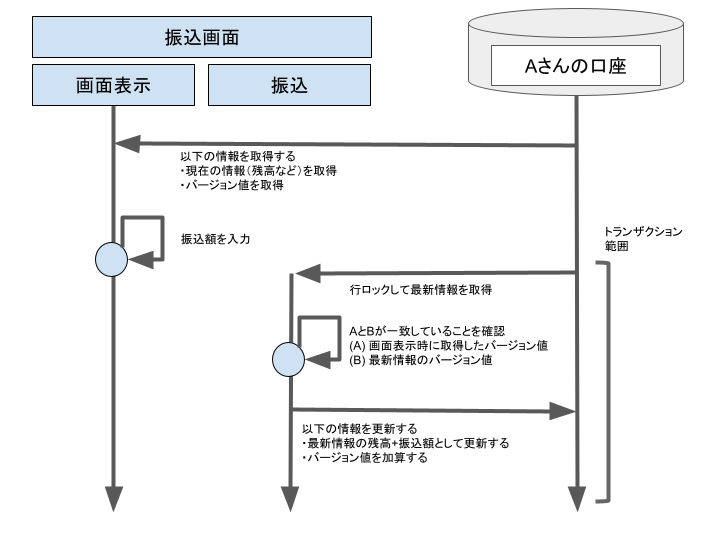
両者ともに同じ事が行えるかと思いますが、私は後者の手法である『SELECT ~ FOR UPDATE』の方が好みだったりします。
ただ、後者で処理を実装するのであれば、注意しなければ行けないとことがあります。
それは、『SELECT ~ FOR UPDATE』開始後に初めて排他的になるので、その後で、対象データに対する最新データの取得や、その最新データに対するチェック(などが必要であれば)、を実施しなければ行けないのです。
例えば、最初に話した、銀行口座の残高の例で行くと、『SELECT ~ FOR UPDATE』後に取得した最新データに対して、『現在の残高+振込額』と言う計算をしないと、不整合が発生する可能性があります。
また、データモデルが複雑化することで、考慮しなければ行けないことも増えるかと思います。
例えば、とある画面で保存を行った際に、1対Nの親子関係のテーブルに同時に保存しなければいけないような場合などです。
この場合、親と子の両方にバージョン(タイムスタンプ)チェックを行う必要があるのでしょうか?
例えば親と子、両方に対して問答無用でバージョンチェックをするのも一つの正解でしょうし、親のみに対してバージョンチェックをすると言うのも正解だと言えるでしょう。
これは、アプリケーションの取り決め(プロトコル)ですので、絶対の正解と言うのも、無いかと思います。
こう言った様々な切り口で思考を巡らせて、排他制御が適切に行われるように、設計して行く事が大事であると思います。
悲観的排他制御の実装
Webアプリケーションにおける悲観的排他制御の実装は、前述したように…
ユーザー的には連続的な操作であっても、Webアプリケーション的には非連続的な操作になり、DBの立場で見ると、トランザクションは別物になります。
(非連続的なので、トランザクションが毎回別物になってしまうので)
そのため、DBのトランザクションを利用した行ロックによる仕組みは除外して考えたいです。
Webアプリケーションでも、頑張れば一部のコネクションをグローバル化して行ロックし続けると言うのも不可能では無いかとは思いますが、通常の動作から逸脱したものになるので、現実的ではないように思います。
こちらについても、絶対の正解と言うのは無いと思うので、あくまでも「こんな実装例はどうか?」と言う範疇になります。
例えばこんなテーブルを用意すると良いのではないでしょうか?
lock(ロックテーブル)
| 物理名 | 論理名 |
|---|---|
| category(PK) | カテゴリ |
| pk_value(PK) | PK値 |
| create_user_id | 作成ユーザーID |
| created_at | 作成日時 |
カテゴリには、任意の値を入れます。例えば画面名でも良いですし、データの名称でも良いかもしれません。PK値には、そのカテゴリに対する一意な値を設定します。
これら二つをPKにすれば、この組み合わせで一意性が保たれるので、登録に成功すればロック成功、PK違反であればロック失敗、となります。
作成ユーザーIDカラムには、その名の通り作成したユーザーのIDを設定して、作成した日時を、作成日時カラムに設定します。
作成ユーザーIDが、自身と同じ場合は自ユーザーが編集中と言う意味になりますし、異なる場合には、他ユーザーがロック中なので自身は編集できない事になります。
下図は、ロックテーブルを用いた図解です。
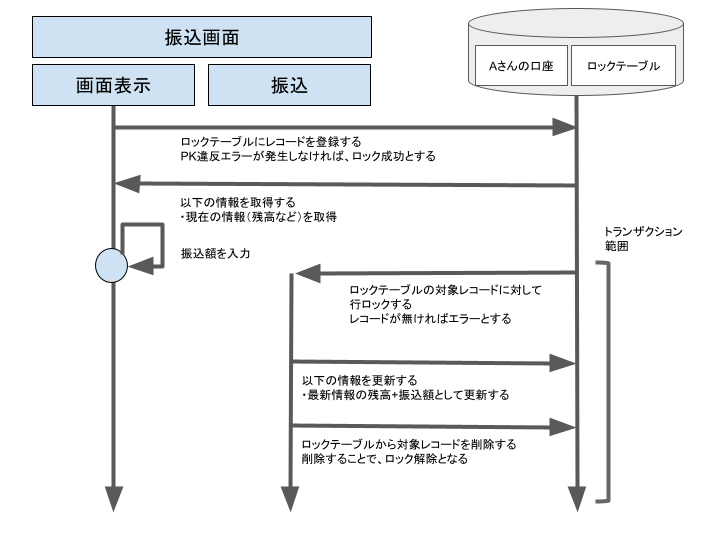
こちらのテーブルを活用すれば悲観的排他制御は実装できるので、あとは、アプリケーションの取り決め(プロトコル)をどのようにするかの話になり、データの不整合が発生しないように適切な設計を行えば良いかと思います。
設計のコツなど
排他制御をどうしようか…、と考える頃には、既にデータ項目などは洗い出された後でしょう。
そして、データ項目が洗い出されていれば、自ずと画面の入出力項目、外部システム(があれば)の連携項目なども決まっている事でしょう。
そんな中、適切に排他制御が為されているかを担保するためには、データの動きが俯瞰(ふかん)して見られる資料があると有用に思います。
例えば、アプリケーションの各テーブル別・各機能別のCRUD(Create、Read、Update、Delete)マトリックス表を作成するのです。こうすると、データ全体を俯瞰して見る事ができます。
この資料から、
「機能Aで保存するタイミングで、同じ機能でも同時に保存されたら?」
「機能Aのデータは、機能Bでも実は保存される。じゃあ、機能Aと機能Bで同時に保存されたら?」
と言った感じでケース別に考えて、不整合が起きえないかを考慮して行けば、正しい排他制御が導出できるのではないかと思いました。
おわりに
巷のネット上の記事でも、楽観的・排他的制御の方法について、実装ベースまで踏み込んで解説していたりする記事がありましたが、自分の認識と異なり混乱する部分があったので、改めて自分なりに整理したく、こうしてまとめてみました。