目次
・目的
・本記事の説明の流れ
・使用するデータ
・数値or文字に変換
・日付型への変換
・日付型データの差分抽出
・日付型データの増分
・大文字・小文字・頭文字のみ大文字に変換
・前後の空白削除
・文字列の連結
・文字列の抽出
・最後に
・宣伝
※本記事はサンプルデータを使用します
サンプルデータは「使用するデータ」にて掲載しております。
目的
Pythonでデータ加工・分析はするがSASをあまり使ったことがない人向けに、SAS言語学習の導入として使ってもらうため本記事を投稿しております。
Pythonは普段触っている一方でSASを触ったことがない方、もしくはSASを普段使っているがPythonも挑戦してみたいといった方に本記事はおすすめです。
本記事の説明の流れ
各章でのデータ加工手法の説明
→Pythonのコーディング方法
→SASのコーディング方法
の流れで進めていきます。
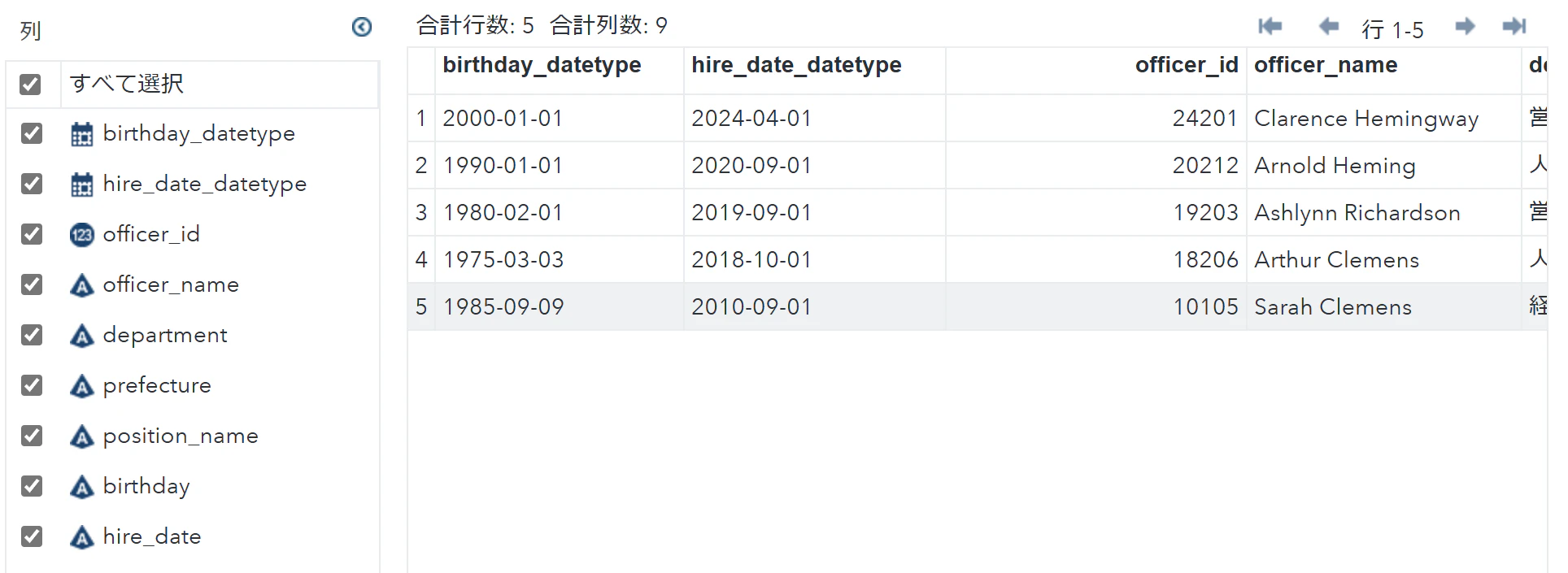
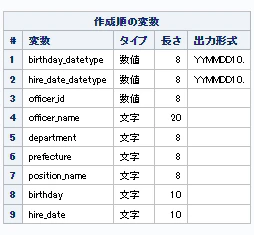
使用するデータ
Python
import pandas as pd
data_shain = pd.DataFrame({
"officer_id":[24201,20212,19203,18206,10105],
"officer_name" :["Clarence Hemingway","Arnold Hemingway","Ashlynn Richardson","Arthur Clemens","Sarah Clemens"],
"department":["営業","人事","営業","人事","経理"],
"prefecture":["埼玉","愛知","静岡","千葉","岐阜"],
"position_name":["unknown","課長","部長","課長","課長"],
"birthday":["2000-01-01","1990-01-01","1980-02-01","1975-03-03","1985-09-09"],
"hire_date":["2024-04-01","2020-09-01","2019-09-01","2018-10-01","2010-09-01"]
})
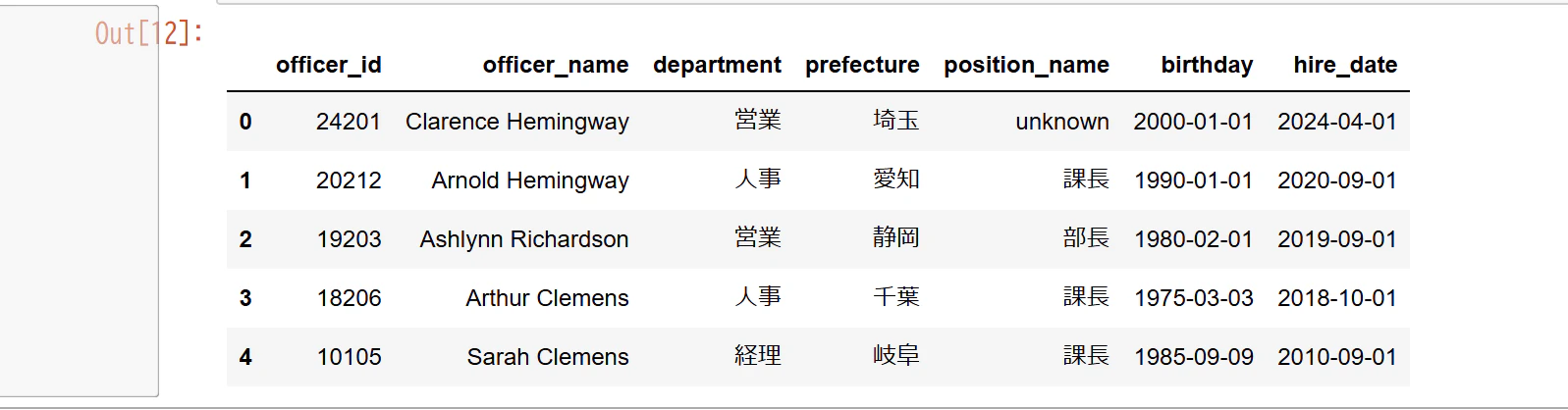
#データ内容の確認
print(data_shain.dtypes)
データ内容

SAS
data work.data_shain;
input officer_id 5. +1 officer_name $20. department $ prefecture $ position_name $ birthday $10. +1 hire_date $10.;
datalines;
24201 Clarence Hemingway 営業 埼玉 unknown 2000-01-01 2024-04-01
20212 Arnold Heming 人事 愛知 課長 1990-01-01 2020-09-01
19203 Ashlynn Richardson 営業 静岡 部長 1980-02-01 2019-09-01
18206 Arthur Clemens 人事 千葉 課長 1975-03-03 2018-10-01
10105 Sarah Clemens 経理 岐阜 課長 1985-09-09 2010-09-01
;
run;
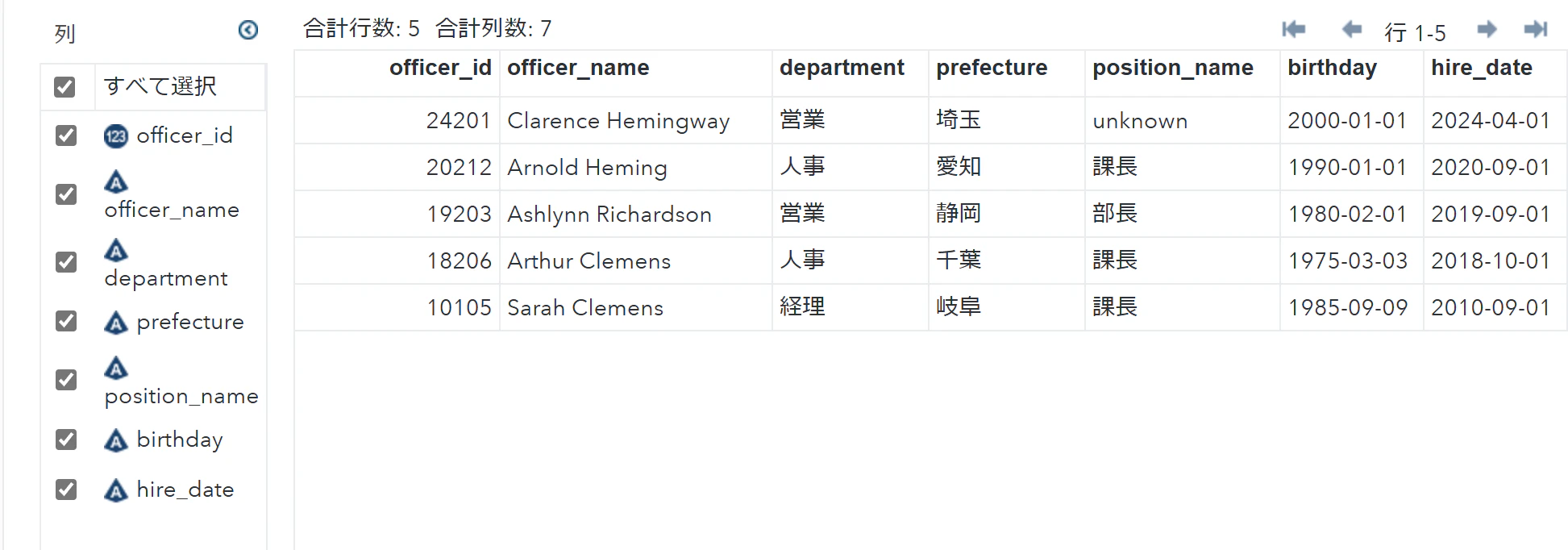
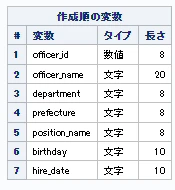
/* データ型確認用 */
proc contents data=data_shain varnum;
run;
データ内容
数値or文字に変換
Python
#変換用に元データをコピー
data_shain_int_str = data_shain.copy()
#数値型を文字型(str型)に変換
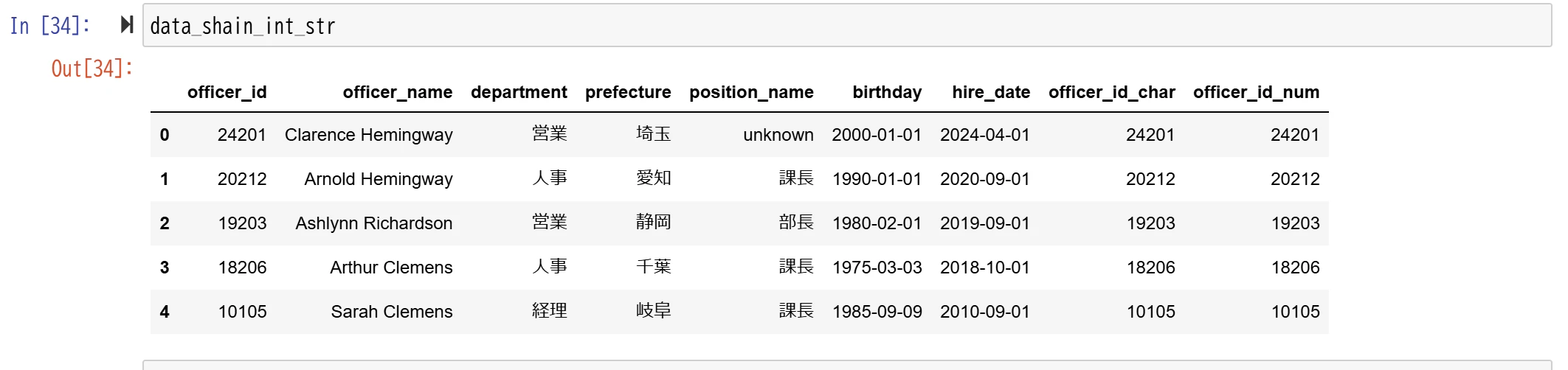
data_shain_int_str.loc[:,"officer_id_char"] = data_shain_int_str.loc[:,"officer_id"].astype('str')
#文字型を数値型(int64型)に変換
data_shain_int_str.loc[:,"officer_id_num"] = data_shain_int_str.loc[:,"officer_id_char"].astype('int64')
#データ型の確認
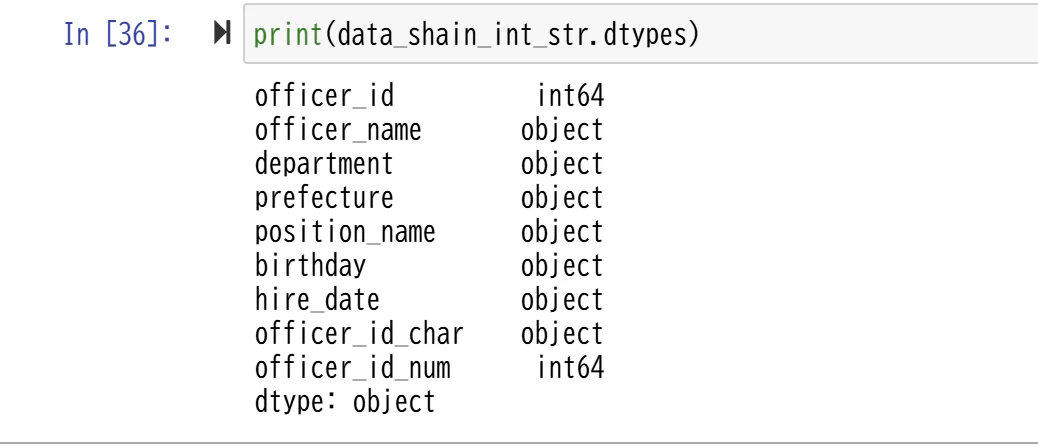
print(data_shain_int_str.dtypes)
SAS
data work.data_shain_num_char;
set work.data_shain;
officer_id_char = put(officer_id,best5.); /* 数値型を文字型(best型,データ長5)に変換 */
officer_id_num = input(officer_id_char,5.);/* 文字型を数値型に変換(データ長5) */
run;
/*データ型の確認*/
proc contents data=work.data_shain_num_char varnum;
run;
解説
Pythonではastype()関数でデータ型を変換しています。
一方でSASでは以下のように変換します。
/* 数値型から文字型への変換 */
変換後の変数名 = put(変換する変数名,データ型);
/* 文字型から数値型への変換 */
変換後の変数名 = input(変換する変数名,データ型);
日付型への変換
Python
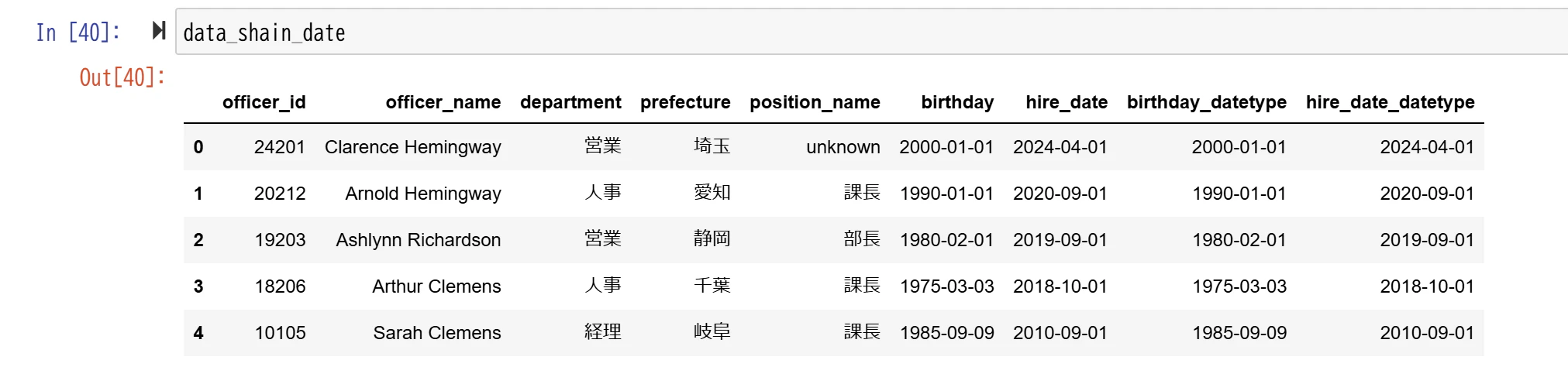
data_shain_date = data_shain.copy()
data_shain_date.loc[:,"birthday_datetype"] = pd.to_datetime(data_shain_date.loc[:,"birthday"] ,errors="coerce",infer_datetime_format=True)
data_shain_date.loc[:,"hire_date_datetype"] = pd.to_datetime(data_shain_date.loc[:,"hire_date"] ,errors="coerce",infer_datetime_format=True)
#データ型確認
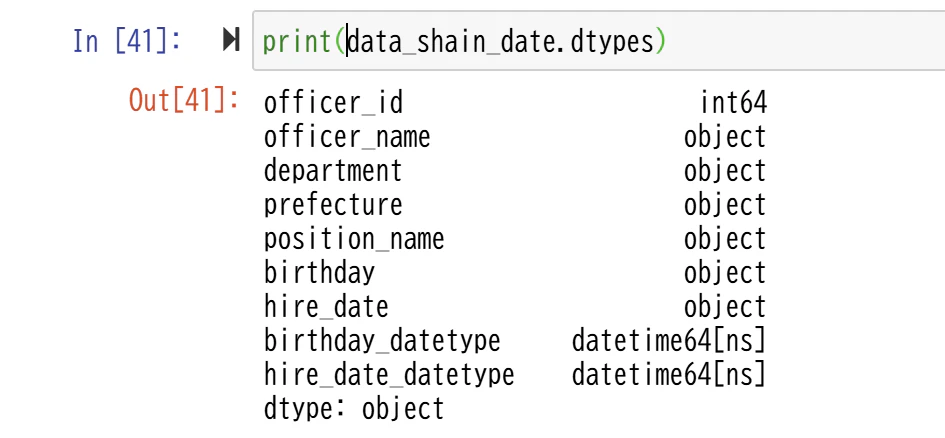
print(data_shain_date.dtypes)
SAS
data work.data_shain_date;
set work.data_shain;
birthday_datetype = input(birthday,yymmdd10.); /* input()でsas日付型に変換 */
hire_date_datetype = input(hire_date,yymmdd10.); /* input()でsas日付型に変換 */
format birthday_datetype hire_date_datetype yymmdd10.; /* 日付の表示形式を適用 */
run;
/* データ型確認用 */
proc contents data=work.data_shain_date varnum;
run;
解説
Pythonではpandasのto_datetime()関数でdatetime64型に変換しました。
↓参考までに日付変換でのオプションです
一方でSASでは以下のように文字列を日付型に変換します。
①設定した変数をinput関数でSAS日付の数値型に定義
変数名 = input(文字型変数,対応する日付型);
/* 今回はyymmdd10.が当てはまるためyymmdd10.に表示形式を適用 */
②formatステートメントで新たな変数の表示形式を適用
format 変数名 データ型;
/* 以下のように変数をまとめて設定可能 */
format 変数名1 変数名2 データ型;
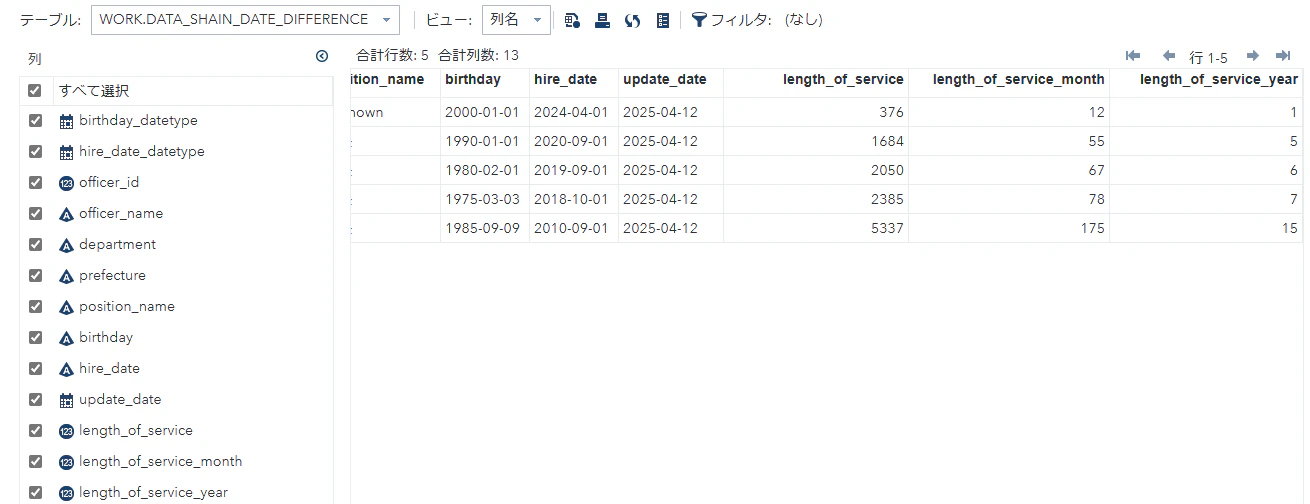
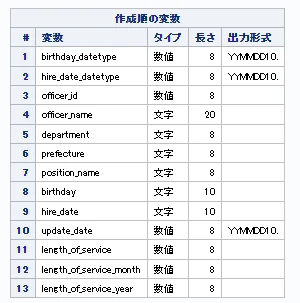
日付型データの差分抽出
Python
# 日時計算のため、一時的に現在の日付を格納
import datetime
from monthdelta import monthmod
# 「日付型への変換」で作成したデータを使用
data_shain_date_difference = data_shain_date.copy()
today = pd.to_datetime(datetime.date.today())
data_shain_date_difference = data_shain_date_difference.assign(update_date = today)
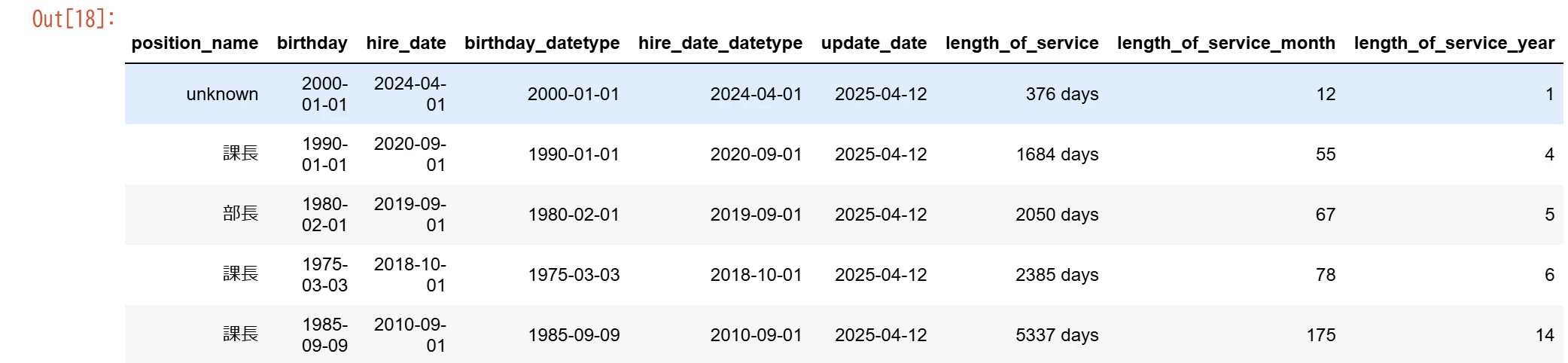
#入社日から現在の日付までの日数を計算
data_shain_date_difference.loc[:,"length_of_service"] = data_shain_date_difference.loc[:,"update_date"] - data_shain_date_difference.loc[:,"hire_date_datetype"]
#入社日から現在の日付までの月数を計算
def calc_delta_month(row):
return monthmod(row["hire_date_datetype"], row["update_date"])[0].months
data_shain_date_difference.loc[:,"length_of_service_month"] = data_shain_date_difference.apply(calc_delta_month,axis=1)
#入社日から現在の日付までの年数を計算
def calc_delta_year(row):
return monthmod(row["hire_date_datetype"], row["update_date"])[0].months//12
data_shain_date_difference.loc[:,"length_of_service_year"] = data_shain_date_difference.apply(calc_delta_year,axis=1)
# データ型の確認
print(data_shain_date_difference.dtypes)
SAS
data work.data_shain_date_difference;
set work.data_shain_date; /* 「日付型への変換」で作成したデータを使用 */
update_date = today();/* 計算のため一時的に今日の日付をSAS日付型で定義 */
format update_date yymmdd10.; /* 表示形式を適用 */
length_of_service = intck('day',hire_date_datetype,update_date);
length_of_service_month = intck('month',hire_date_datetype,update_date);
length_of_service_year = intck('year',hire_date_datetype,update_date);
run;
/* データ確認用 */
proc contents data=work.data_shain_date_difference varnum;
run;
解説
Pythonでは日付型データの引き算で日数の差分が出力されます。
datetime型の変数同士で引き算をするとデータ型はtimedelta型になります。
一方で月・年単位での差分を抽出するにはmonthdeltaパッケージのmonthmod関数を使用します。
monthmod関数で出力されるデータ型はint型です。
※monthmod関数は引数にdataframeの列名を指定してもエラーになるため、
あらかじめ関数を作成してdata.apply(関数名,axis=1)で出力します。
SASでは以下のようにINTCK()関数を使用して開始日と終了日の差分を出力します。
変数名 = INTCK('計算する期間の単位(例:day,monthなど)',開始日付,終了日付);
/* intck('day',開始日付,終了日付) のように指定する */
/* 'day'を'month'や'year'に変えれば単位を変更できる */
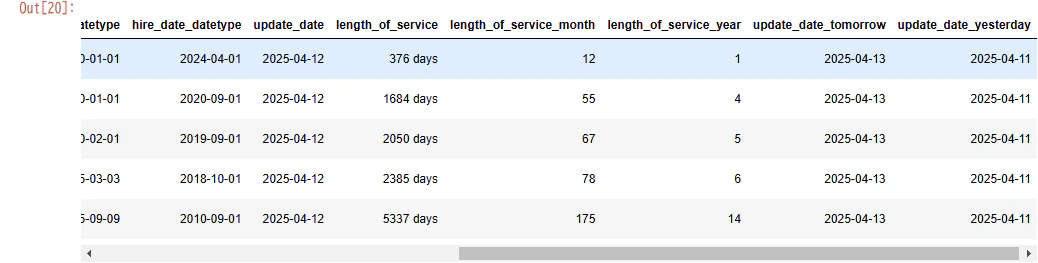
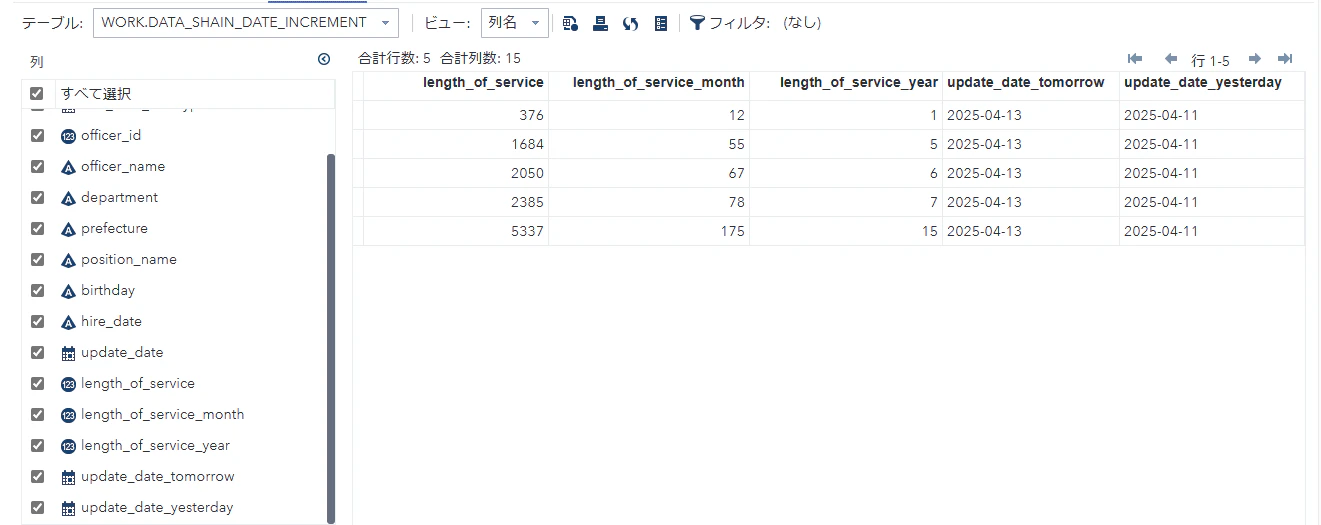
日付型データの増分
Python
import datetime
# 「日付データの差分抽出」で作成したデータを使用
import datetime
# 「日付データの差分抽出」で作成したデータを使用
data_shain_date_increment = data_shain_date_difference.copy()
data_shain_date_increment.loc[:,"update_date_tomorrow"] = data_shain_date_increment.loc[:,"update_date"] + datetime.timedelta(days=1)
data_shain_date_increment.loc[:,"update_date_yesterday"] = data_shain_date_increment.loc[:,"update_date"] + datetime.timedelta(days=-1)
#データ型確認用
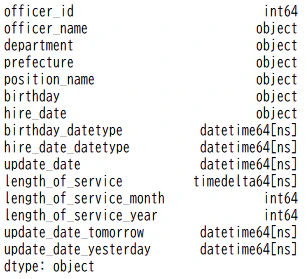
print(data_shain_date_increment.dtypes)
SAS
data work.data_shain_date_increment;
set work.data_shain_date_difference; /* 「日付型データの差分抽出」で作成したデータを使用 */
update_tomorrow = intnx('day',update_date,1);
update_yesterday = intnx('day',update_date,-1);
format update_tomorrow update_yesterday yymmdd10.;
run;
/* データ確認用 */
proc contents data=work.data_shain_date_increment varnum;
run;
解説
Pythonでは増分する値をdatetime.timedelta(days=増分値)でtimedelta型に変換して足し算する流れで増分できます。数値をマイナスにすれば減算もできます。
SASはINTNX関数で日付データを増分します。
SASでも数値をマイナスにすれば減算できます。
増分後の変数 = INTNX('増分する期間の単位(例:day,monthなど)',開始日付,増分する数値);
/* INTNX('day',開始日付,3) のように指定する */
/* 'day'を'month'や'year'に変えれば単位を変更できる */
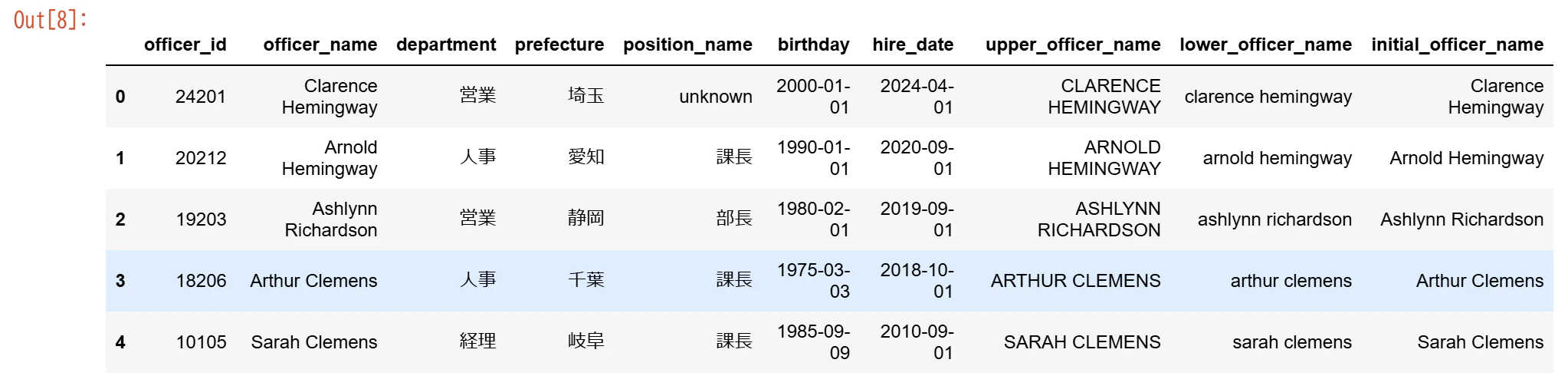
大文字_小文字_各単語の頭文字のみ大文字に変換
Python
#変換用に元データをコピー
data_shain_upper_lower = data_shain.copy()
#大文字に変換
data_shain_upper_lower.loc[:,"upper_officer_name"] = data_shain_upper_lower.loc[:,"officer_name"].str.upper()
#小文字に変換
data_shain_upper_lower.loc[:,"lower_officer_name"] = data_shain_upper_lower.loc[:,"officer_name"].str.lower()
#各単語の頭文字のみ大文字に変換
data_shain_upper_lower.loc[:,"initial_officer_name"] = data_shain_upper_lower.loc[:,"officer_name"].str.title()
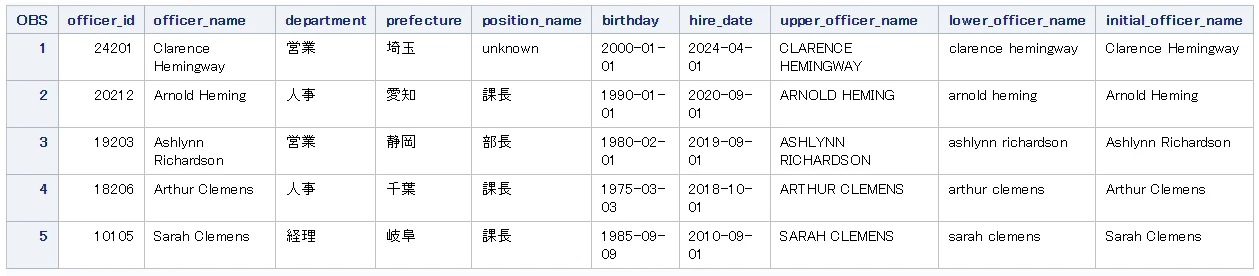
SAS
data data_shain_upper_lower;
set data_shain;
/* 大文字に変換 */
upper_officer_name = upcase(officer_name);
/* 小文字に変換 */
lower_officer_name = lowcase(officer_name);
/* 各単語の頭文字のみ大文字に変換 */
initial_officer_name = propcase(officer_name);
run;
解説
Pythonでは以下の関数で大文字/小文字の変換ができます。
lower() →小文字に変換
upper() →大文字に変換
title() →各単語の頭文字のみ大文字に変換
一方SASでは以下のように大文字/小文字の変換ができます。
upcase(引数) →大文字に変換
lowcase(引数) →小文字に変換
propcase(引数) →各単語の頭文字のみ大文字に変換
前後の空白削除
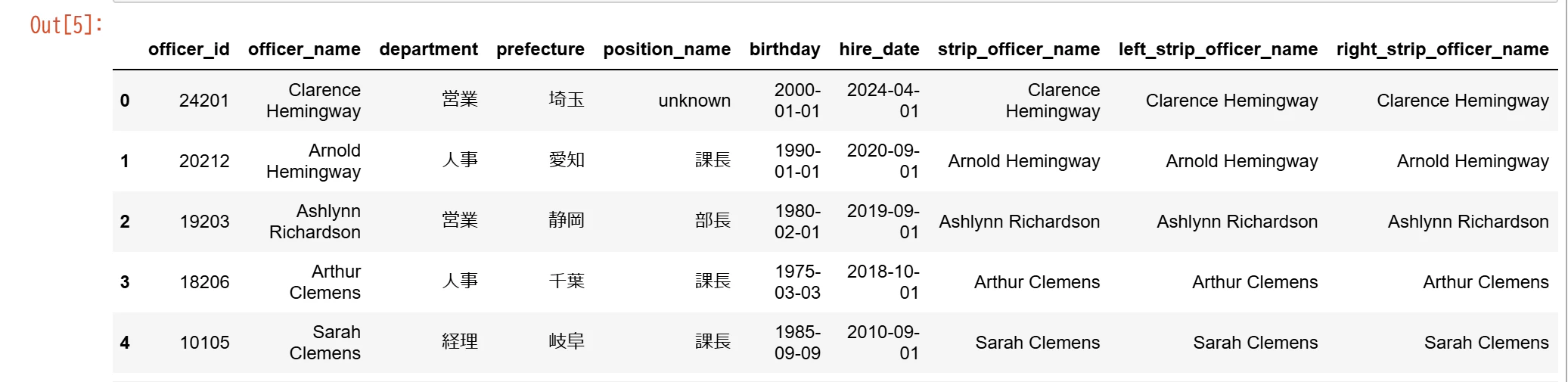
Python
#変換用に元データをコピー
data_shain_strip = data_shain.copy()
#テスト用に空白を追加
data_shain_strip.loc[:,"officer_name"] = " " + data_shain_strip.loc[:,"officer_name"] + " "
#左右の空白削除
data_shain_strip.loc[:,"strip_officer_name"] = data_shain_strip.loc[:,"officer_name"].str.strip()
#左側の空白削除
data_shain_strip.loc[:,"left_strip_officer_name"] = data_shain_strip.loc[:,"officer_name"].str.lstrip()
#右側の空白削除
data_shain_strip.loc[:,"right_strip_officer_name"] = data_shain_strip.loc[:,"officer_name"].str.rstrip()
SAS
data data_shain_trim;
set data_shain;
/* テスト用に空白を追加 */
officer_name_blank = ' '||officer_name||' ';
/* 左右の空白削除 */
officer_name_strip = strip(officer_name_blank);
/* 右側の空白削除 */
officer_name_trim = trimn(officer_name_blank);
/* 左側の空白を削除 */
officer_name_left = left(trimn(officer_name_blank));
run;

解説
Pythonでは以下のように空白を削除します。
strip() →左右の空白削除
rstrip() →右側の空白削除
lstrip() →左側の空白削除
一方でSASでは以下のように空白を削除します。
strip(引数) →左右の空白削除
trimn(引数) →右側の空白削除
left(trimn(引数)) →左側の空白を削除
/* 処理の流れ:left()で文字列を左側に寄せて空白を右側に寄せる→trimn()で右側の空白を削除する */
文字列の連結
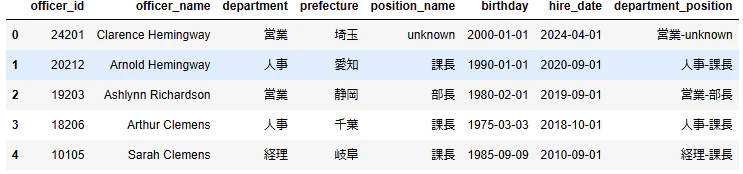
Python
#変換用に元データをコピー
data_shain_cat = data_shain.copy()
#文字列の連結
data_shain_cat.loc[:,"department_position"] = data_shain_cat.loc[:,"department"].str.cat(data_shain_cat.loc[:,"position_name"],sep='-')
SAS
data data_shain_cat;
set data_shain;
/* 左右の空白を削除せず連結 */
department_position_cat = cat(department,'-',position_name);
/* 左右の空白を削除して連結 */
department_position_catx = catx('-',department,position_name);
run;

解説
Pythonではcat()を使用することで連結ができます。
(本コードではstr.cat()を使用することでSeries同士の連結をしています)
区切り文字を連結文に入れたい場合はsep='区切り文字'を引数に追加します。
一方SASでは以下のようにcat()やcatx()等で連結することができます。
cat()は引数に指定した変数をそのまま連結しますが、catx()は左右の空白を削除したうえで連結します。
またcatx()は区切り文字を指定できますがcat()は区切り文字を指定できません。
連結文字列1 = cat(変数1,変数2,変数3);
連結文字列2 = catx('区切り文字',変数1,変数2,変数3);
他にも連結するための関数はあるので参考までに...
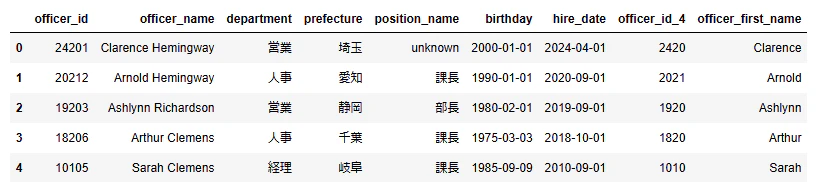
文字列の抽出
Python
#変換用に元データをコピー
data_shain_extract = data_shain.copy()
#officer_idから左詰め4桁を抽出
data_shain_extract.loc[:,"officer_id_4"] = data_shain.loc[:,"officer_id"].astype(str).str[0:4]
#区切り文字(空白)を利用して名前のみ取り出す
data_shain_extract.loc[:,"officer_first_name"] = data_shain.loc[:,"officer_name"].str.split(" ").str.get(0)
SAS
data data_shain_extract;
set data_shain;
/* officer_idから左詰め4桁を抽出(数値→文字列→空白削除→文字列抽出) */
officer_id_4 = substr(left(put(officer_id,best12.)),1,4);
/* 区切り文字(空白)を利用して名前のみ取り出す */
officer_first_name = scan(officer_name,1,' ');
run;
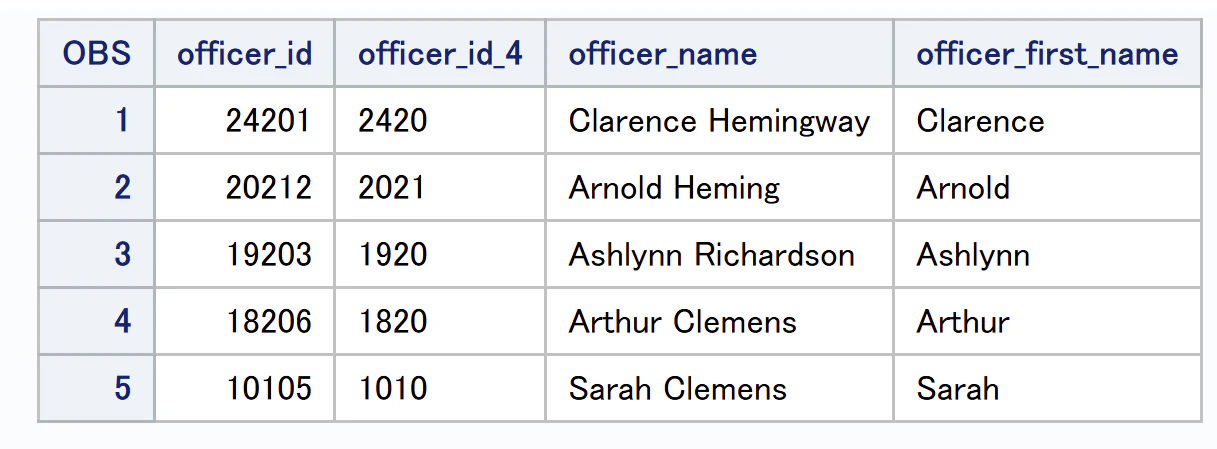
解説
Pythonの抽出手法は以下の通りです。
・文字列の位置を指定する方法
①officer_idがint型であるためint型のデータをstr型に変換。
②str[]で文字の位置を指定して抽出。
※Pythonでの頭文字の位置は0になります。
・区切り文字を利用した方法
①split(" ")で区切り文字の前後を配列の要素に変換
②get(0)で最初の要素を取得する流れで名前のみを抽出。
SASは以下の通りです。
・文字列の位置を指定する方法
①officer_idが数値型なためput()で文字型に変換。
②左側に空白があるためleft()で文字列を左詰め。
③文字列の1番目から4文字分を指定して抽出。
※SASでの頭文字の位置は1になります。
・区切り文字を利用した方法
scan()を利用して抽出。
文字抽出変数1 = substr(変数1,文字列の位置,文字数);
/* 文字数を指定しない場合、最後の文字まで抽出される */
文字抽出変数2 = scan(変数1,番号,'区切り文字');
/* 区切り文字で変数1を区切る→何番目の文字列かを指定することで抽出。 */
最後に
本記事では関数でのデータ加工の手法を説明しました。
次回はデータの結合手法をPython,SAS両方で説明していきます。
また、SASは本来有料ですが、無料で学習できるSAS OnDemand for Academicsがあるので、SASを始めてみたい方は以下のSAS社のサイトから確認してみてください
宣伝
株式会社ジールはMicrosoft Azure やAWS(Amazon Web Services)、Google Cloud Platform(GCP)、Oracle Cloud Infrastructure(OCI)など、多彩なクラウドプラットフォーム構築・運用の知見を有しています。そのため、複数のクラウドサービスを組み合わせるマルチクラウド環境においても、ベンダーロックインを回避し、お客様のご要望に応じた最適なクラウドプラットフォームの構築・運用への対応が可能です。
https://www.zdh.co.jp/products-services/cloud-data/