本記事の概要
弊社サービスの問い合わせ対応用Slackチャンネルのトーク履歴を使用してRAGを作成しました。
最初は、「問い合わせ対応が自動化できる!」と、期待に胸を膨らませて夢いっぱいだったのですが、開発を進めるにつれて淡い幻想にすぎない気がしてきました。
本記事では、具体的にどのあたりが良くなかったのか、また、それを改善するにはどういったことが考えられるのかをまとめていきたいと思います。
(具体的な実装については、この記事では触れません)
はじめに:弊社における社内の問い合わせ対応に関して
弊社は、主に、インターネット上の行動ログを基にしたマーケティングのためのSaaS製品を提供しています。(詳しくはこちら:https://www.valuesccg.com/service/ )
社内において、これらのサービスに対して質問がある場合は、専用のSlackチャンネルで私たち開発チームに質問することができます。お客様からの質問やシステムの詳細な仕様の質問など、毎日、何かしらの質問とそれに対する回答が行われています。
つまり、このSlackチャンネルは、弊社のSaaS製品に関する情報の宝庫となっています。
しかし、現状、それらの情報をうまく活用できていないように感じています。例えば、新しい質問の内容が過去の質問の内容と重複していたり、Slackでの情報検索に慣れていない人にとっては、うまく質問を探しきれなかったりします。また、そもそも、Slackの検索をすること自体に手間と時間がかかるという課題もありました。
そこで、半年前にまだRAGという言葉も知らなかった私は以下のように思いました。
「このSlackチャンネルの情報をGPTに与えてオリジナルAIを作れば、問い合わせ対応を自動化できるのでは?」と。
正直に言うと大分甘かったです。実際に実装してみるとそんな都合のいいものではなさそうでした。
そこで今回は、Slackのトーク履歴を使用したRAGに関して、
- 完成したRAGの全体像
- 良くなかった点
- 改善点
などの話を書いていこうと思います。
Slackのデータを使用したRAGに関して、リアルな感想をお求めの方はぜひ最後までご覧ください。
※「そもそもRAGとは何ぞや」という方は、こちらのAWSによるRAGの説明をご覧ください。本記事はRAGを知っている前提で記述していきます。
完成したRAGのざっくりとした全体像
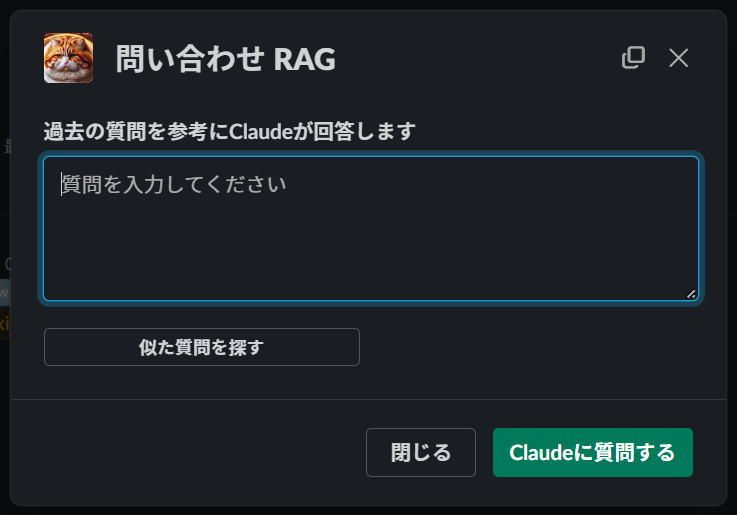
ざっくりとしたUI
実装は、Slackアプリとして行いました。
Slackのショートカットからアプリを開くと以下のようなモーダルが出現し、開発チームの代わりにClaudeへ質問できます。Claudeには、参考にしたスレッドのリンクを引用しつつユーザからの質問に答えるように、裏で言っておきました(システムプロンプト)。
「似た質問を探す」ボタンを押せば、ベクトル検索でヒットした過去のスレッドのリンクが高速で表示されます。
ざっくりとした使用技術
言語:TypeScript
ライブラリ:LangChain.js、Bolt for JavaScript
LLM:Amazon Bedrock(Claude)
Embedding:Amazon Titan Embeddings G1 - Text
ベクトルDB:Chroma DB
デプロイ先:Amazon EC2
当初は、LLMにGPTを使用しようと考えていました。しかし、GPTにプロンプトを送信すると、最大30日間、OpenAIに送信したプロンプトが保存されることになります。(参考:https://openai.com/enterprise-privacy )開発当初は、OpenAIの情報漏洩の記憶も新しく、社外秘のデータがOpenAIに保存されることに対して懸念がありました。
そこで、今回は、AWSの信頼性を考慮し、LLMにAmazon BedrockからClaudeを採用しました。(参考:https://aws.amazon.com/jp/bedrock/faqs/)
データ保護の観点でGPTの使用をためらっている方には、ぜひともAmazon Bedrockの使用を検討してみてください。
ざっくりと良かった点
Slackの検索機能と比較し、RAGが優れていると感じたのは検索の手軽さです。
Slackの検索は単語ベースで行われます。入力されたクエリを細かく単語に分解し、類似した意味を持つ単語まで含めて、幅広く検索します。これにより、結果として大量のスレッドがヒットし、目的の情報を見つけ出すのに骨が折れる場合もあります。
一方で、RAGの検索は文章ベースで行われます。質問文をそのままの文章形式で検索し、類似度の高い順にスレッドが表示されます。結果的に大量のスレッドから目的の情報を探す手間はかかりません。
まとめると、検索クエリの粒度の差により、RAGの方が手軽に情報探索を行えると思いました。
(今回、「似た質問を探す」ボタンを実装したのはそのためです)
本題:良くなかった点
今回、特に良くなかった点は、Slackのトーク履歴を そのまま 使用したことだと考えています。
Slackのトーク履歴には、例えば、弊社のサービス名や機能の名前、質問の背景など、弊社のことを知らない人にとって未知の前提知識が多分に含まれています。もちろん、LLMは弊社の基本的な社内知識を知りません。
また、例の問い合わせ専用チャンネルは、非常に具体的なシステムの仕様の話が行われる場です。
そして、Slackというコミュニケーションツールの性質上、口語的な表現やフランクな表現が含まれている場合もあります。
つまり、AIにとって理解しづらい文体で書かれた未知の難しい社内情報を参考に回答してもらうことになります。たとえ人間に同じことを頼んだとしても、なかなか良い回答は返ってこないのではないでしょうか?
要するに、Slackのトーク履歴は、AIが理解しやすい文章という観点において、非常に質の低いデータだと思います。これは、LLMに対してのみならず、ベクトル検索に使用したEmbeddingのAIに対しても言えることかもしれません。
これを踏まえて、開発当時、Claudeの2.1を用いて口語表現を文語表現に変換するなどの前処理を試みました。(当時、Claude3は発表されていませんでした)しかし、文章自体の意味が変わってしまったり、情報が抜け落ちたりするなど、あまりいい結果は得られませんでした。
時間の都合もあり、今回はデータの前処理を見送ったのですが、現在はClaude3が登場するなど、将来的に見れば、現実的な精度の前処理が可能になるかもしれません。
改善点
とりあえず、LLMへクエリを投げる前段に、基本的な社内情報を取得する仕組みは必要だと思います。
他にも、前述したように、Embeddingの前にデータの前処理を行うことも考えられます。
しかし、そもそも、Slackのトーク履歴の生データをそのまま使用する方向性から再検討した方が良いかもしれません。社内の情報は、基本的な情報だけでなく、Slackで行われた些細なやりとりも含めて、正確な文語表現に変換し、構造化して整備するのはどうでしょうか?これはRAGとして利用するデータの話だけでなく、社内の全ての情報に関してです。
「社内の情報を整備しましょう」という話は、以前から言われていることだと思いますが、自社でAIやAIツールを用意する時代において、これまでとは比べ物にならないくらい、情報整備の優先度・重要性が増しているのかもしれません。
最後に感想
最近、「エンジニアの代替になるAIが登場!」みたいなニュースを頻繁に見かけて戦々恐々としています。とりあえず、AIを使う側に回っておけば、AIが活躍する領域に対して理解が深まり、やつらに代替されないキャリアのポジショニングができるのでは!?とか私は考えています。皆さんはどう思いますか?
私は、そんな感じでこれからもAI系の取り組みをできる限り頑張りたいと思います。
皆さんも一緒に頑張りましょう。
P.S.
弊社には、Googleの20%ルール的な制度が存在し、個人のプロジェクトを持つことができます。今回のRAGは、その一環で作りました。弊社に興味のある方はこちらをご覧ください。良ければ一緒に働きましょう。