PDFの表からデータを取り出すtabulizerパッケージです。下記のTwitter記事を参考にしました。
PDFに埋まっているテーブルデータを開放してあげるには、Rを使えば以下の4行でできちゃいます!
— Kan Nishida (@KanAugust) April 21, 2020
library(tabulizer)
library(purrr)
df_list <- tabulizer::extract_tables("file.pdf") %>%
purrr::map_dfr(https://t.co/Bz4BWtBUrJ.frame) pic.twitter.com/k9kYelorDj
パッケージ読み込み
library(tidyverse)
library(tabulizer)
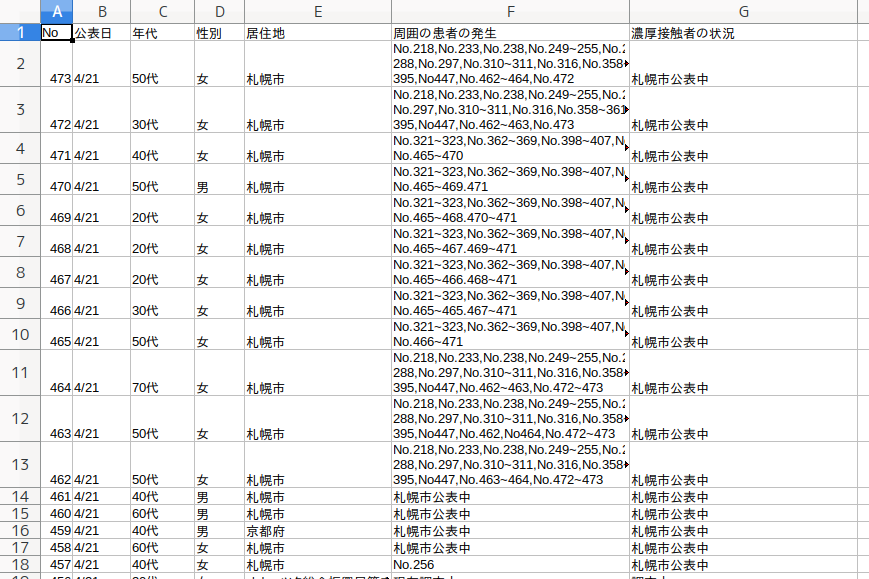
あつかう表はこのような形式。北海道庁が公開しているコロナウィルス感染症のPDFデータです。
説明すべきことはあまりありません。map_dfr()はapply系の関数です。初めて使用しましたが、便利です。
tb <-
tabulizer::extract_tables("0421.pdf") %>% # pdfデータを読み込み
purrr::map_dfr(as.data.frame) %>% # data.frame形式に変換
as_tibble() %>% # tibble形式に変換(やらなくても良いけど)
filter(V2 !="(公表)" , V2 !="公表日" ) # データとして読み込まれたヘッダ行を削除
# カラム名をrename
colnames(tb) <-
c("No","公表日","年代","性別","居住地","周囲の患者の発生", "濃厚接触者の状況")
# csv書き出し
tb %>%
write_csv("0421.csv")
無事に全てのデータが書き出されました。