中学校3年生の息子が卒業文集に載せる「○○ランキング表」なるものを「Rでつくりたい」と申し出てきたので、作り方を公開します。
息子が作っていたデータとその処理がdplyrの教科書的でした。
全国の中学生は似たようなものを作っていると思うけれど、参考にしてね。
データ概要
データはこんな感じです。
カラムに質問項目をが設定してあって、男子と女子それぞれで一番当てはまりそうな生徒の名前を記入していくみたいです。
「かわいい」とか「面白い」は分かりますが、「親と暮らす」とか「連帯保証人になる」とか意図不明ですね。
> colnames(data)
[1] "性別" "ボランティアを頑張る" "お金を稼ぐ"
[4] "親と一緒に暮らす" "合コンに出る" "国籍を変える"
[7] "騙される" "海外で暮らす" "ものを壊す"
[10] "変な人" "借金をする" "連帯保証人になる"
[13] "真面目" "うるさい" "面白い"
[16] "かっこいい" "かわいい"
head(data)
性別 ボランティアを頑張る お金を稼ぐ 親と一緒に暮らす 合コンに出る
1 男 信玄 謙信 正宗 輝元
2 女 氏家 兼続 元就 且元
3 男 秀吉 長政 謙信 輝元
4 女 氏家 秀忠 信繁 且元
5 男 長政 謙信 謙信 輝元
6 女 信繁 兼続 氏家 且元
国籍を変える 騙される 海外で暮らす ものを壊す 変な人 借金をする
1 秀吉 信長 尊氏 直義 定信 忠勝
2 秀忠 氏郷 且元 氏郷 秀忠 氏郷
3 秀吉 長政 秀吉 直義 直義 輝元
4 且元 元就 秀忠 兼続 元就 秀忠
5 勝頼 忠勝 勝家 定信 謙信 輝元
6 秀忠 信繁 秀忠 氏家 氏郷 且元
連帯保証人になる 真面目 うるさい 面白い かっこいい かわいい
1 成政 勝家 信忠 長秀 勝頼 謙信
2 信繁 忠興 秀忠 晴信 義元 信繁
3 信長 直義 直義 尊氏 直義 直義
4 信繁 元就 秀忠 秀忠 秀忠 元就
5 成政 秀吉 輝元 尊氏 信長 信長
6 信繁 元就 義元 秀忠 景勝 忠興
目標
やりたいことは、それぞれの項目ごとに投票された個人名をカウントして、男女別に得票数をあきらかにするということです。
中学生には大変かもしれませんが、R使いの考古学者は以下のコードで一撃です。
data %>%
gather(
key = 特徴 ,
value = 名前 ,ボランティアを頑張る ,お金を稼ぐ , 親と一緒に暮らす , 合コンに出る ,
国籍を変える , 騙される , 海外で暮らす ,ものを壊す ,変な人 ,借金をする ,連帯保証人になる ,
真面目 ,うるさい , 面白い ,かっこいい ,かわいい
) %>% # wide形式の表をlong形式に直します。
group_by(特徴 , 性別 , 名前) %>% # ランキング属性(特徴)、性別、個人名でグルーピングします。
summarize( 得票 = n() ) %>% # 得票集を集計します。
arrange( 特徴 , 性別 , desc(得票) ) %>% # ソートします。
write.csv("ランキング.csv") # csvに出力します。
結果はこんな感じです。
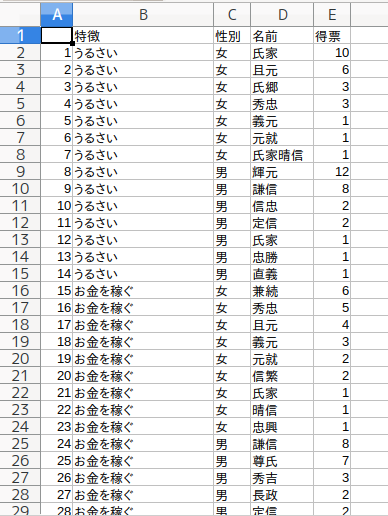
解説
最初はgather()でワイド型のデータをロング型に変換します。
data %>%
gather(
key = 特徴 ,
value = 名前 ,ボランティアを頑張る ,お金を稼ぐ , 親と一緒に暮らす , 合コンに出る ,
国籍を変える , 騙される , 海外で暮らす ,ものを壊す ,変な人 ,借金をする ,連帯保証人になる ,
真面目 ,うるさい , 面白い ,かっこいい ,かわいい
) %>% # wide形式の表をlong形式に直します。
head()
性別 特徴 名前
1 男 ボランティアを頑張る 信玄
2 女 ボランティアを頑張る 氏家
3 男 ボランティアを頑張る 秀吉
4 女 ボランティアを頑張る 氏家
5 男 ボランティアを頑張る 長政
6 女 ボランティアを頑張る 信繁
group_by()で特徴(設問項目)、性別、名前にグルーピングします。
data %>%
gather(key = 特徴 , value = 名前 ,ボランティアを頑張る ,お金を稼ぐ , 親と一緒に暮らす , 合コンに出る ,
国籍を変える , 騙される , 海外で暮らす ,ものを壊す ,変な人 ,借金をする ,連帯保証人になる ,真面目 ,うるさい ,
面白い ,かっこいい ,かわいい ) %>% # wide形式の表をlong形式に直します
group_by(特徴 , 性別 , 名前) %>% # ランキング属性(特徴)、性別、個人名でグルーピングします。
head()
性別 特徴 名前
<fct> <chr> <chr>
1 男 ボランティアを頑張る 信玄
2 女 ボランティアを頑張る 氏家
3 男 ボランティアを頑張る 秀吉
4 女 ボランティアを頑張る 氏家
5 男 ボランティアを頑張る 長政
6 女 ボランティアを頑張る 信繁
summarize()で特徴ごとで、性別ごと、名前ごとに個数を集計します。
n()はカウント関数です。
氏家さんが女性のうるさい人ランキングでかなり高得点を取っているのがわかります。
data %>%
gather(
key = 特徴 ,
value = 名前 ,ボランティアを頑張る ,お金を稼ぐ , 親と一緒に暮らす , 合コンに出る ,
国籍を変える , 騙される , 海外で暮らす ,ものを壊す ,変な人 ,借金をする ,連帯保証人になる ,
真面目 ,うるさい , 面白い ,かっこいい ,かわいい
) %>% # wide形式の表をlong形式に直します。
group_by(特徴 , 性別 , 名前) %>% # ランキング属性(特徴)、性別、個人名でグルーピングします。
summarize( 得票 = n() ) %>% # 得票集を集計します。
head()
特徴 性別 名前 得票
<chr> <fct> <chr> <int>
1 うるさい 女 且元 6
2 うるさい 女 義元 1
3 うるさい 女 元就 1
4 うるさい 女 氏家 10
5 うるさい 女 氏家晴信 1
6 うるさい 女 氏郷 3
arrange()で特徴ごと、性別ごと、得票数ごとにソートします。
desc(得票)は降順でソートです。
氏家さんと且元さんが女性のうるさいランキグングで高得点を取っていますね。
data %>%
gather(
key = 特徴 ,
value = 名前 ,ボランティアを頑張る ,お金を稼ぐ , 親と一緒に暮らす , 合コンに出る ,
国籍を変える , 騙される , 海外で暮らす ,ものを壊す ,変な人 ,借金をする ,連帯保証人になる ,
真面目 ,うるさい , 面白い ,かっこいい ,かわいい
) %>% # wide形式の表をlong形式に直します。
group_by(特徴 , 性別 , 名前) %>% # ランキング属性(特徴)、性別、個人名でグルーピングします。
summarize( 得票 = n() ) %>% # 得票集を集計します。
arrange( 特徴 , 性別 , desc(得票) ) %>% # ソートします。
head()
特徴 性別 名前 得票
<chr> <fct> <chr> <int>
1 うるさい 女 氏家 10
2 うるさい 女 且元 6
3 うるさい 女 氏郷 3
4 うるさい 女 秀忠 3
5 うるさい 女 義元 1
6 うるさい 女 元就 1
まとめ
今どきの中学生は何を考えているのかよくわからない、ということがよく分かりました。
とは言え、「ボランティアを頑張る」とか「親と一緒に暮らす」などという項目は、中学生が漠然と抱えている大人観や将来像が反映されているのでしょう。
こういうランキング表、私も小学校や中学校の卒業時に作った記憶がありますが、全国の小学生、中学生は今でも作っているのでしょうか?
以上、全国の中学生のためにお送りした「Rでつくる○○ランキング表作り方講座」を終わります。