「Mercari Price Suggestion Challenge」とは
Kaggleにて2018年2月21日まで開催中の、Mercariの出品時の価格査定機能のアルゴリズム改善に関するコンペティション。
https://about.mercari.com/press/news/article/20171122_kaggle/
2018年1月14日現在、約1500チームがコンペティションに参加中。
コンペティションのルール
与えられるデータの形式
トレーニングデータのカラムは「train_id」「name」「item_condition_id」「category_name」「brand_name」「price」「shipping」「item_description」の8つ。
テストデータは、ここから「price」を除いた7つで構成されている。
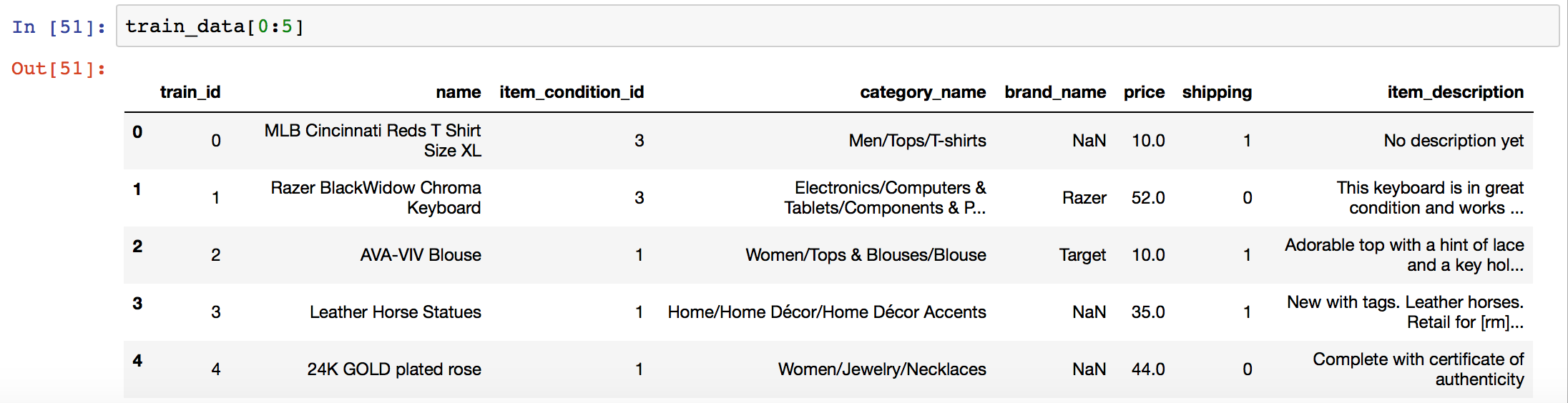
行数は、トレーニングデータが約148万行、テストデータが約69万行となっている。
評価関数
「price」を目的変数として、テストデータの「price」を他の7つのカラム(説明変数)から予測して、その精度を競うコンペティションであり、評価関数としてRMSLE(Root Mean Squared Logarithmic Error)を用いる。

RMSLEは下記のように計算が可能。
import math
# A function to calculate Root Mean Squared Logarithmic Error (RMSLE)
def rmsle(y, y_pred):
assert len(y) == len(y_pred)
terms_to_sum = [(math.log(y_pred[i] + 1) - math.log(y[i] + 1)) ** 2.0 for i,pred in enumerate(y_pred)]
return (sum(terms_to_sum) * (1.0/len(y))) ** 0.5
取り組んだアルゴリズム
xgboostの説明
今回学習に利用したアルゴリズムはxgboostと呼ばれる、Gradient BoostingとRandom Forestのアルゴリズムを組み合わせたアンサンブル学習を用いた。
理論的な説明は、下記の投稿を参考にした。
https://qiita.com/yh0sh/items/1df89b12a8dcd15bd5aa
実際の解析結果
以下にて実際に解析した内容について紹介。
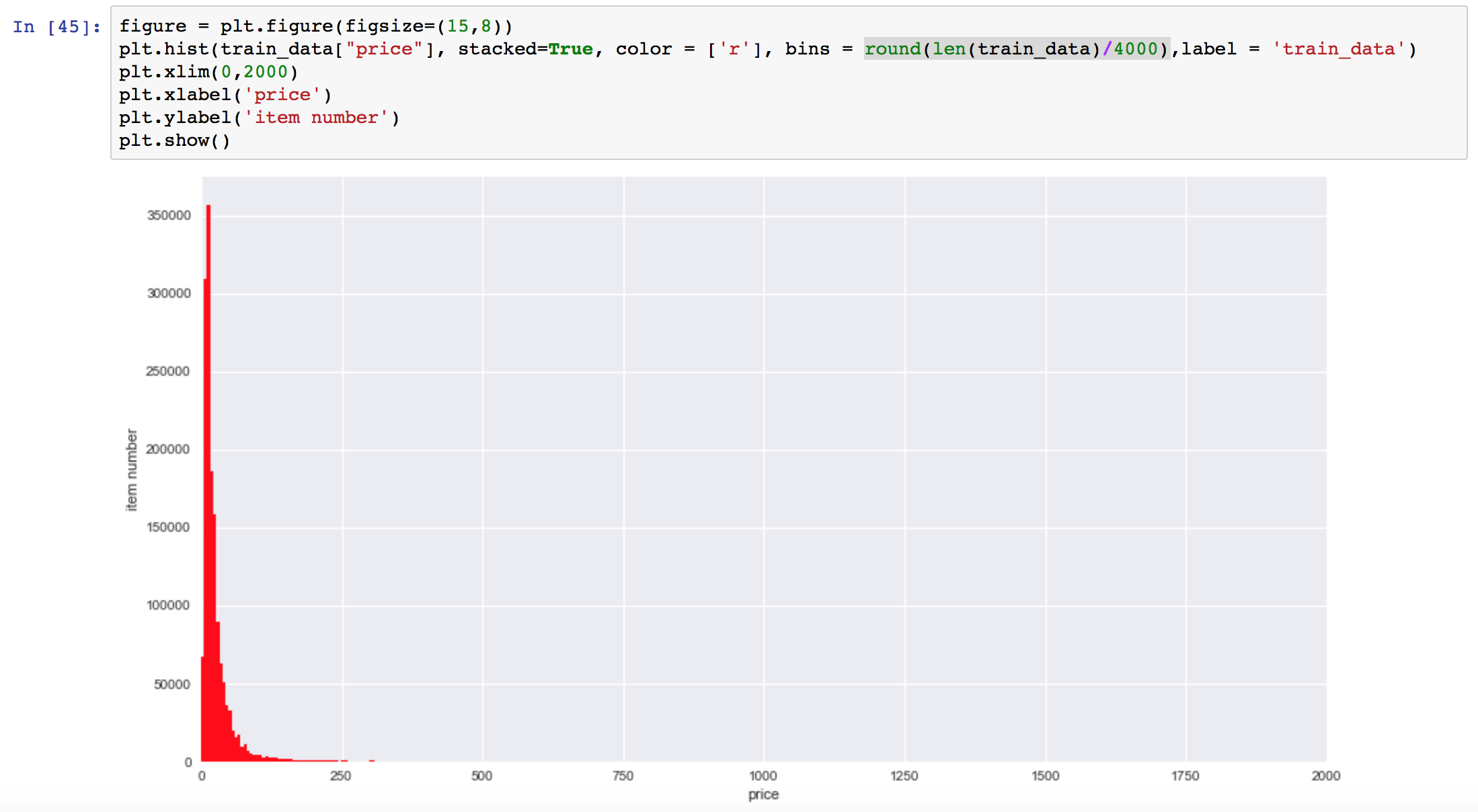
トレーニングデータの「price」の分布
トレーニングデータの目的変数である「price」をヒストグラムにプロットすると、下記のような分布となる。
大半のitemは数10ドル付近に分布しているが、最高金額のitemは2000ドル付近に存在しており、ロングテールの分布になっている。
xgboostに学習させるデータの準備
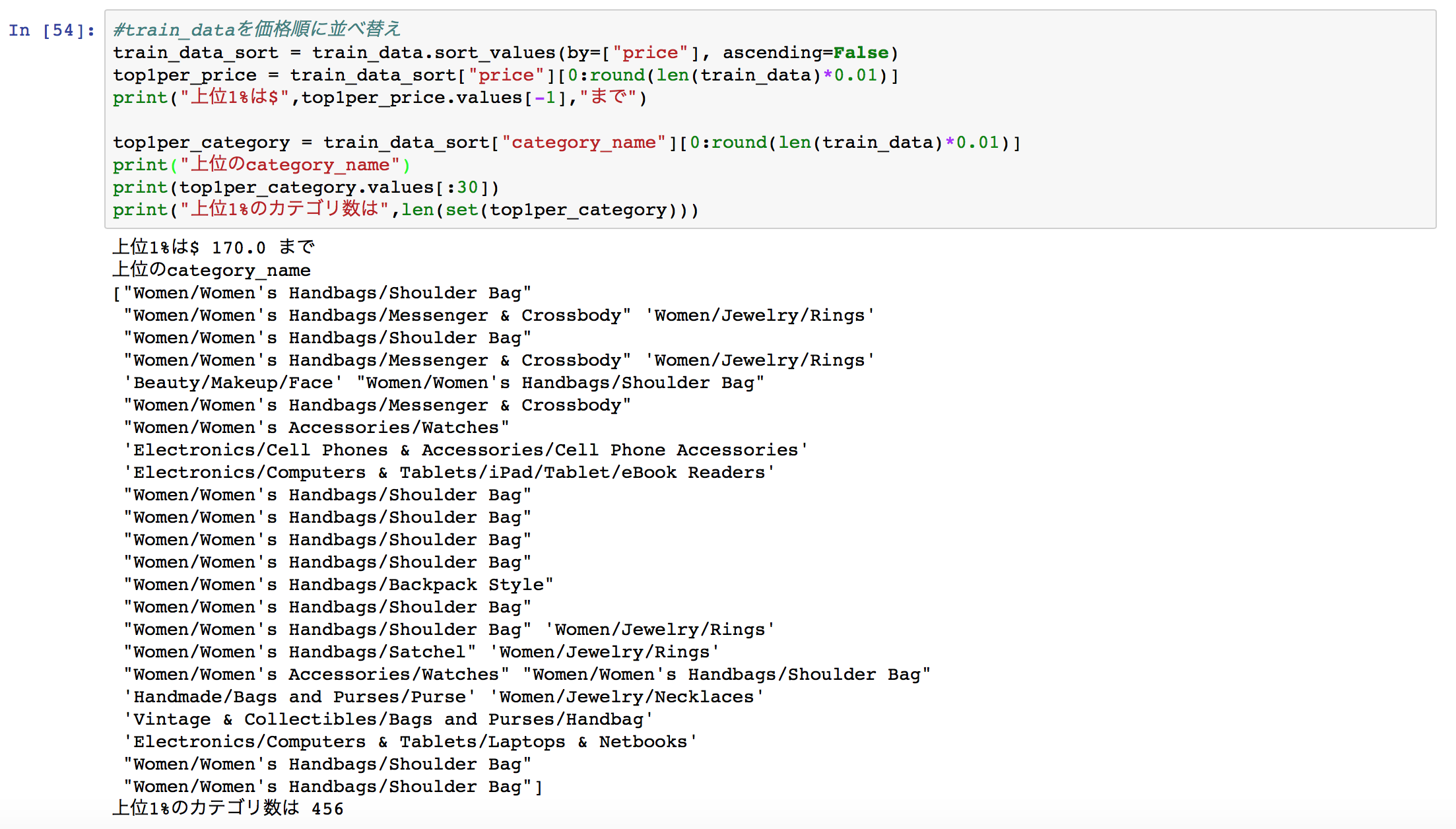
7つのカラム(説明変数)のうち、今回の解析では「category_name」に注目して解析を行った。
価格が上位1%の集団に含まれるitemは、170ドル以上のitemとなっており、上位の「category_name」を見ると"Women/Women's Handbags"や"Electronics/Computers"などの幾つかの特徴的なカテゴリが確認できたため、「category_name」を①高価なitemが含まれるcategory_name②その他一般的なitemのcategory_name③category_nameが空データのもの、の3種類に分けて学習を行った。
テキストデータの解析
7つのカラム(説明変数)の内、前述の「category_name」及び「brand_name」の2つのカラムをダミー変数に変換することで解析を行った。「name」と「item_description」のカラムは今回は使用しなかった。
以下はテキストデータをダミー変数に変換する際に利用したコード。
# brand_nameのダミーを作成
# 価格順に並び替え
df_descend = train_data.sort_values(by=["price"], ascending=False)
# 価格が上位1%のbrand_nameはダミー変換、それ以外のbrand_nameは"other-brand"に置換
brand_list = df_descend["brand_name"][0:round(len(train_data)*0.01)]
train_data_brand_name = train_data["brand_name"].fillna("NoData")
# others_brandに置換
train_data_brand_name[~train_data_brand_name.isin(brand_list)] = "others-brand"
# ダミー変数化
brand_name_dummies = pd.get_dummies(train_data_brand_name)
brand_name_dummies = pd.DataFrame(brand_name_dummies)
データの学習と予測データの出力
学習に用いたxgboostのコードとテストデータの「price」予測、出力データを作成するためのコードを下記。
学習条件に関しては最適化を行っておらず、パラメータのチューニングが必要。
# xgboostライブラリのimport
import xgboost as xib
# 学習
mod = xgb.XGBRegressor(learning_rate=0.1,max_depth=10,n_estimators=20)
mod.fit(train_data_x, train_data_y)
# テストデータのy(price)の予測
y_test_pred = mod.predict(test_data_x)
df_y_test = pd.DataFrame()
df_y_test_pred = pd.DataFrame(y_test_pred)
df_y_test_pred.index = test_data_x.index
# 出力データの作成
df_output = pd.DataFrame()
df_output["test_id"] = df_y_test_pred.index
df_output["price"] = df_y_test_pred.values
使用したコード全体
今回作成したコードは下記のgithubレポジトリに保存。
https://github.com/ishigen/mercari-with-Xgboost
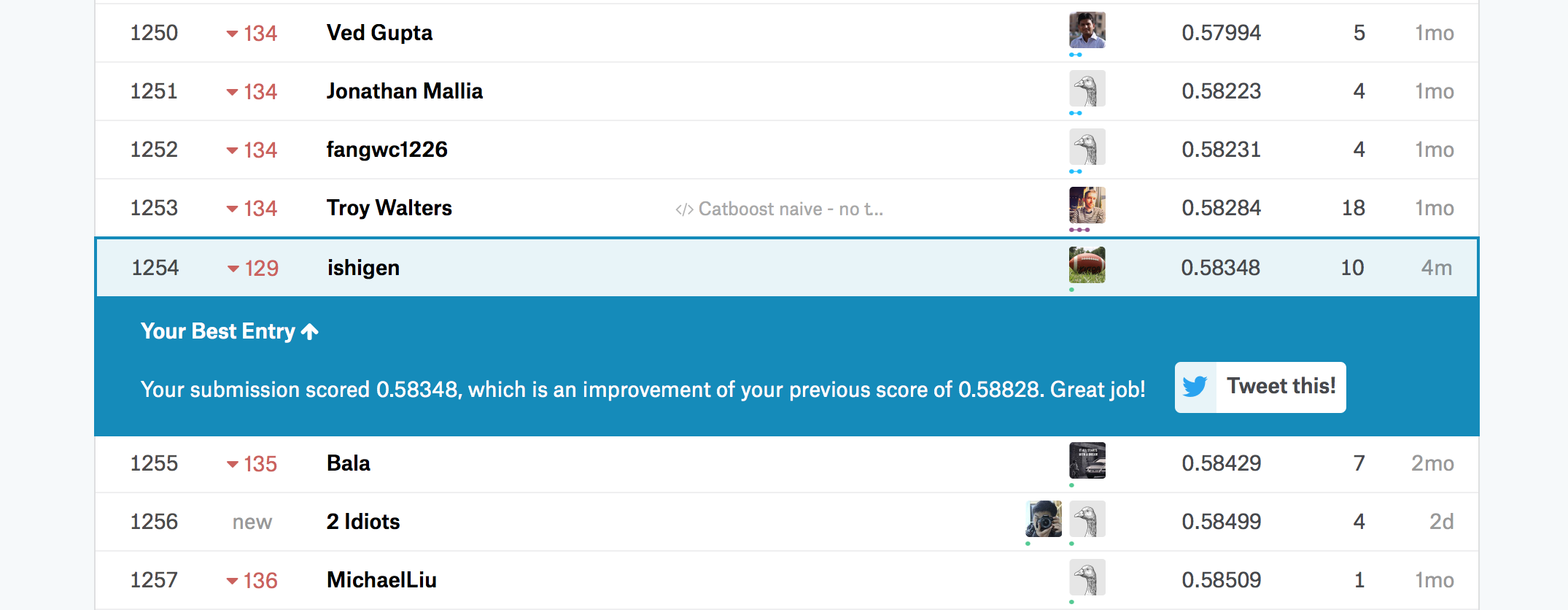
結果
今回の得点と順位は下記の通り。まだまだ改善が必要。
所感
基本的な解析だと高得点にはまだまだ遠いという感触。
kerasのライブラリやロングテールデータの解析手法などもう少し研究したい。