背景
データ分析のインターン先で、個人タスクとしてFlaskでWebアプリケーションを作成したのですが、LINEのトークスクリプトが結構汚かったので、自分の整形方法を書いてみようと思います。
ちなみに今回の続編記事も書いておりますので、よかったらそちらもご覧ください!
お願い
かなり泥臭くデータ整形していると思います。
そんなことをしなくても「こうすれば良くない?」的なご指摘コメント等いただけたら幸いです。
また、LINEのトークを利用します。
他人とのトークは個人情報の宝庫なので、利用する際はちゃんと相手の許可を取り、扱いには十分気をつけましょう。
データの取り込み
LINEはtxt形式でトークスクリプトをダウンロードすることができます。
LINEアプリから取得したテキストファイルを、分析環境に持ってきます。
ちなみに僕はローカルのanacondaで分析します。
[LINE] {{user名}}とのトーク.txt
こんな感じのtxtファイルを触っていきます。python側では、
import pandas
df = pandas.read_csv("[LINE] {{user}}とのトーク.txt", sep='\n')
とすれば読み込むことができます。タブ形式で読み込むとかなり汚いデータフレームが出来上がるので、行ごとに読み込みます。
データの整形
ここからは皆さんが取得したテキストファイルの中身にもよりますが、LINEのテキストファイルの中身はこんな感じになっていますね。
[LINE] {{user}}とのトーク履歴
保存日時:yyyy/mm/dd hh:mm
2021/02/22(月)
11:19 me こんにちは!
2021/02/23(火)
15:00 user "ごめんなさい!
全然気づきませんでした!笑"
15:00 user [スタンプ]
me:筆者
user:話者
で会話を一部抜粋した形で掲載してみました。
この生データを見る限り、最初の3行を除けば、
行の形式種類は4パターンありそうです。
- yyyy/mm/dd(day)
- hh:mm 話者 context
- context
- 空白
分析し辛いったらありゃしないですが、これが生データです。笑
あるあるですが、コンペ用のデータではないのでしょうがないですねー。
上記の4パターン別で、データフレームを1行ずつ作成していこうと思います。
日付の取得
行によっては日付がない行もあるので、各行に日付を追加していきます。
アルゴリズムはコードをみていただけるとありがたいです。。。
import re
# 正規表現でトークから日付を取得し新しいカラムとして結合する
date_list = []
date_pattern = '(\d+)/(\d+)/\d+\(.?\)'
for talk in df['talks']:
result = re.match(date_pattern, talk)
if result:
date_t = result.group()
date_list.append(date_t)
else:
date_list.append(date_t)
df['date'] = date_list
# talksにおいて日付のカラムはもう必要ないので、そこがTrueのものをisin関数で消す
flag = df['talks'].isin(df['date'])
df = df[~flag]
df.dropna(inplace=True)
トークスクリプトの分割
「時間 話者 context」が1行でミックスされているので分解していきます。
# talks内を、時間、話者、トーク内容で分ける
time_l = []
user_l = []
talk_l = []
date_l = []
count = 0
for date, talk in zip(df['date'], df['talks']):
# もし正規表現で時間が取れたらスプリットして3つに分ける
if(re.match('(\d+):(\d+)', talk)):
try:
if(len(talk.split('\t')[0]) == 5):
date_l.append(date)
time_l.append(talk.split('\t')[0])
user_l.append(talk.split('\t')[1])
talk_l.append(talk.split('\t')[2])
count = count + 1
else:
continue
except:
talk_l.append("メッセージの送信取り消し")
count = count + 1
else:
talk_l[count-1] = talk_l[count-1] + talk
df = pandas.DataFrame({"date" : date_l,
"time" : time_l,
"user" : user_l,
"talk" : talk_l})
コードはこんな感じで、データフレームの上の方を見てみるとこんな感じになります。
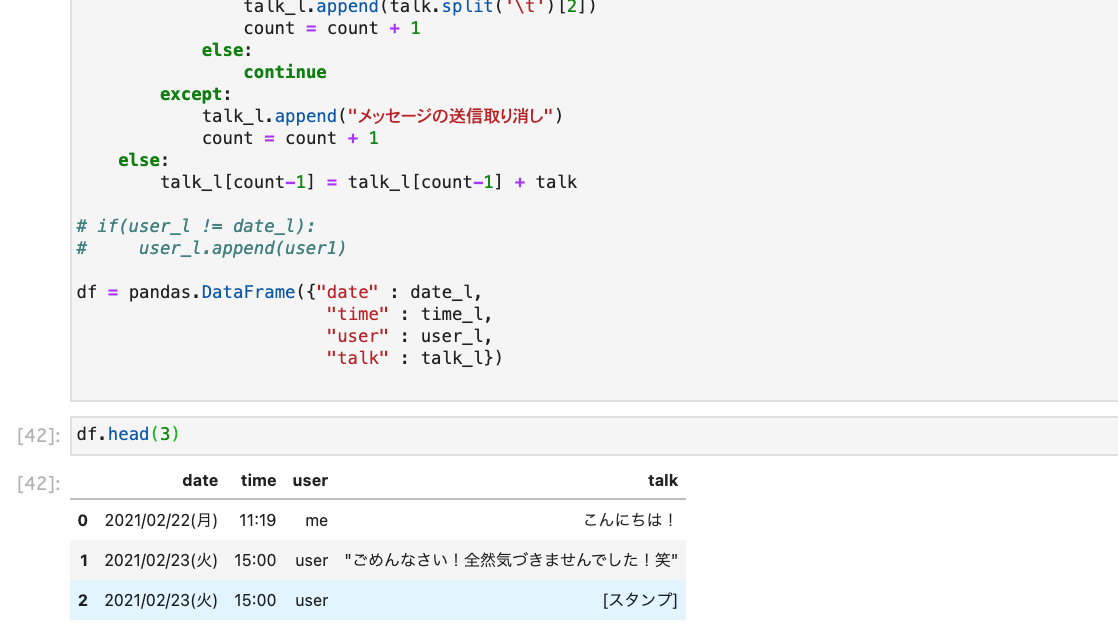
曜日データは今回使わないので、消してしまいます。
date_l = []
for date in df['date']:
date_l.append(date[:-3])
df['date'] = date_l
最後に
これでデータ分析の準備は終了です!
ここから自然言語処理をかけていくわけですね。
個人情報の流出等は十分に気をつけてください。