記事を書いたきっかけ
データ分析のインターン業務中に、violinプロットを用いて可視化したデータを説明する機会がありました。
その時に、「あれ、ここって平均値だっけ?中央値だっけ?」とわからなくなったのが怖くなり、調べたのがきっかけです。
violinプロットに関しては、日本語での検索結果は実装方法ばかりで具体的にどう読むのかを書いた記事が現状少ないように思えました。
この辺英語で調べたら一発だったので、翻訳も交えて自分のためにまとめようと思います。

概要
データの可視化で非常にお世話になるヴァイオリンプロットについて詳しくなります。
実装
ヴァイオリンプロット??ってなっている人のために、秒で動くipynbファイルを用意しました。
よかったら飛んで見てみてください。
サンプルコードは下記二つのURLから持ってきたものです。
基本的な読み方
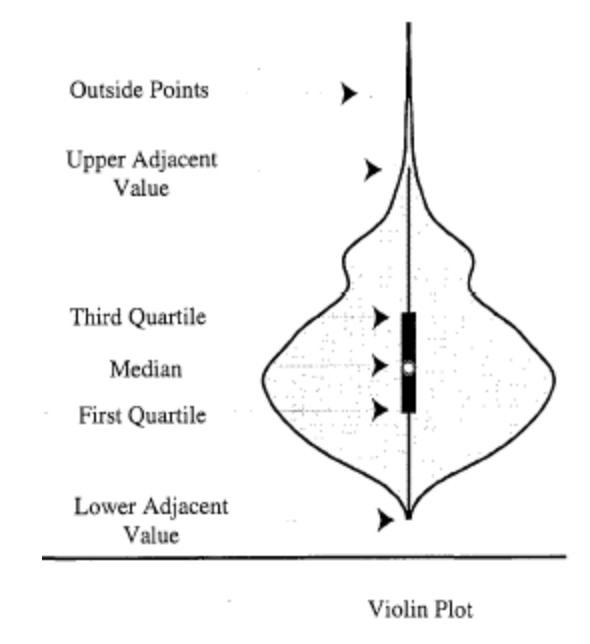
上から順に読んでみると、
- Outside Points : 分布の外部
- Upper Adjacent Value : 分布の最上位(外れ値は除く)
- Third Quartile : 第3四分位数
- Median : 中央値
- First Quartile : 第1四分位数
- Lower Adjacent Value : 分布の最下位(外れ値は除く)
こんな感じです。真ん中の浮遊系モンスターの格みたいな白い部分が中央値で、元々は箱ひげ図がベースになっていることがわかります。
横にふわふわ広がっているのはカーネル密度推定といいます。
カーネル密度推定の説明は省略させていただきますが、大雑把にデータの分布のしやすさと認識すればいいのではないでしょうか?(統計に強いお方、ご意見あればコメントいただけると幸いです。)
ヴァイオリンプロットの読み方は一旦ここまで。
実際の読み取り
可視化して終わり!
では分析の価値は生まれません。
なので、上記で紹介したcolabの、可視化したデータを少し読み取っていきます。
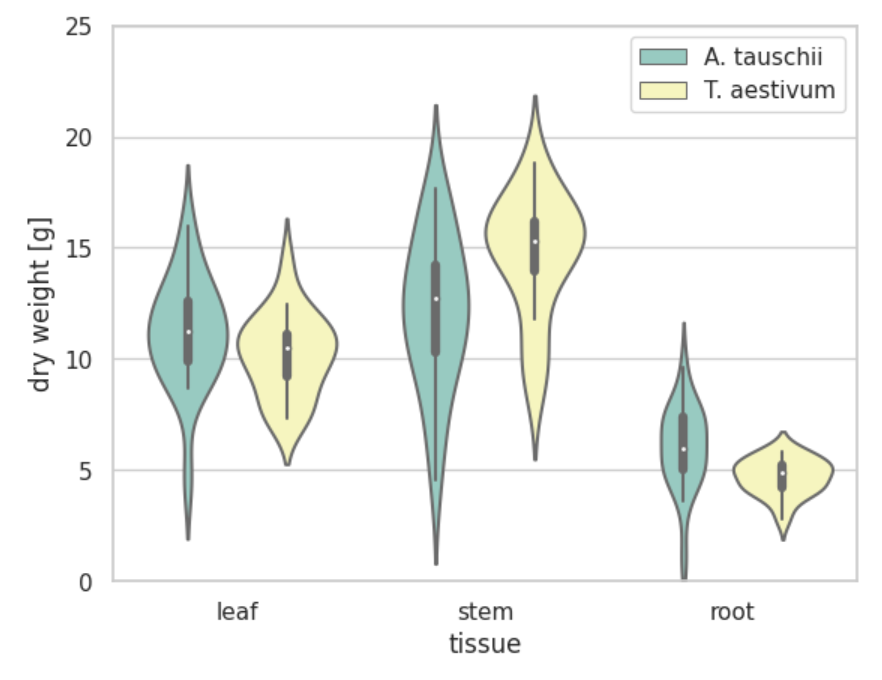
このヴァイオリンプロットはまず、
- A.tauschii
- T.aestivum
の2グループに分かれています。この2つを比較したいのでしょう。
ここではAとBのグループということにします。
パラメータとしては、leaf, stem tissue, rootがあります。
縦軸にはdry weightを取っているので、3つのパラメータごとにdry weightがどう分布しているかを言語化していこうと思います。
全体感としては
- dry weight[g]はstem tissue, leaf, rootで大きい順に並びそう
- AよりもBの方がデータにまとまりがありそう
- stem tissueのみBがより重い傾向にありそう
次にパラメータごとに見ていくと、
- leaf
- dry weightの中央値の違いは1g以下だが、Aの方がより重い重さを示すデータが多く含まれている
- Bに安定して10~11あたりの重さを示す傾向がありそう
- Bの7.5gあたりが若干膨らんでいることから、最小値を示すデータが複数あったことがわかる
- stem tissue
- Aのデータにはばらつきが目立つ
- Bの最小値がAの中央値とほぼ同値と、違いが際立っている
- root
- Aの中央値がBの最大値であり、違いが際立つ
- Bは比較材料の中で分布が最も狭い
こんな感じで可視化したデータを言語化していきます。
データ分析とはいっても、基本的にやることは仮説検証です。
なので仮説がないことには結論が出せないのですが、ここでは、適当に
仮説:AとBの違いによって、ある植物の部位の乾燥重量は変わるのだろうか?
結論:変わる。なぜなら、乾燥重量(dry weight)はBグループのstem tissueのみが重い傾向にあり、leaf, rootはAグループの方が重いという特徴が見られるから。
とでもしておきましょう。
以上です!
ご精読ありがとうございました!