はじめに
このブログはAI/ML on AWS Advent Calendar 2022の12日目の記事です。
re:invent2022で発表されたAmazon SageMaker Notebooksの新機能を触ってみて、具体的な実装方法やどのようなメリットがあるかを整理したいと思います。
Amazon SageMaker Notebooksとは
Amazon SageMaker Notebooksは、SageMakerの各機能と統合された 2 種類のフルマネージド型 Jupyter Notebook を提供しています。Amazon SageMaker Studio ノートブックとAmazon SageMaker ノートブックインスタンスです。
今回ご紹介する新機能はAmazon SageMaker Studio ノートブックのアップデートとなります。
Amazon SageMaker Studio ノートブック
Amazon SageMaker Studio ノートブックは、機械学習用の統合開発環境 (IDE) である Amazon SageMaker Studio で起動できるノートブックです。Jupyter NotebookにSageMakerやその他のAWSサービスの機能を簡単に呼び出せる拡張機能が追加されており、モデルのトレーニングやデバッグ、実験の追跡、モデルのデプロイとモニタリング、パイプラインの管理まで、機械学習開発のために必要なあらゆるツールを揃えている非常に優れた機能です。
アーキテクチャも優れており、必要な時に必要な分のマシンスペックを迅速に用意できるようになっています。以前Amazon SageMaker Studioのアーキテクチャでまとめたので、詳しい仕組みに興味があればご覧ください。
新機能1:built-in data preparation capability(DataWranglerの組み込み)
SageMaker Studio ノートブックで、Data Wranglerの機能によるGUIでのデータ準備・分析が可能になりました。
利用方法は非常にシンプルで、SageMaker Studio ノートブックで、PandasのDataFrameを使ってデータを読み込むのみで、統計値、データ分布、欠損値、無効なデータ、外れ値などのデータ品質の問題を特定するための情報を自動で分析・可視化してくれます。
利用方法
まずは、SageMaker Studio ノートブックを起動します。こちらでも触れられていますが、UIが刷新されて、以前からご利用されている方は初見だとびっくりするかもしれません。
ノートブックを起動したら、DataWranglerの機能を利用するために、pipでsagemaker_datawranglerのパッケージをSageMaker Studio ノートブックにインストールします。
!pip install sagemaker_datawrangler
ここでは、DataWranglerのチュートリアルでも題材となっているTitanic datasetで新機能を利用したデータ準備・分析をしていこうと思います。
!wget https://s3.us-west-2.amazonaws.com/amazon-sagemaker-data-wrangler-documentation-artifacts/walkthrough_titanic.csv
データをダウンロードしたら、pandasのDataFrameでデータを読み込みます。
import pandas as pd
import sagemaker_datawrangler
df = pd.read_csv('walkthrough_titanic.csv')
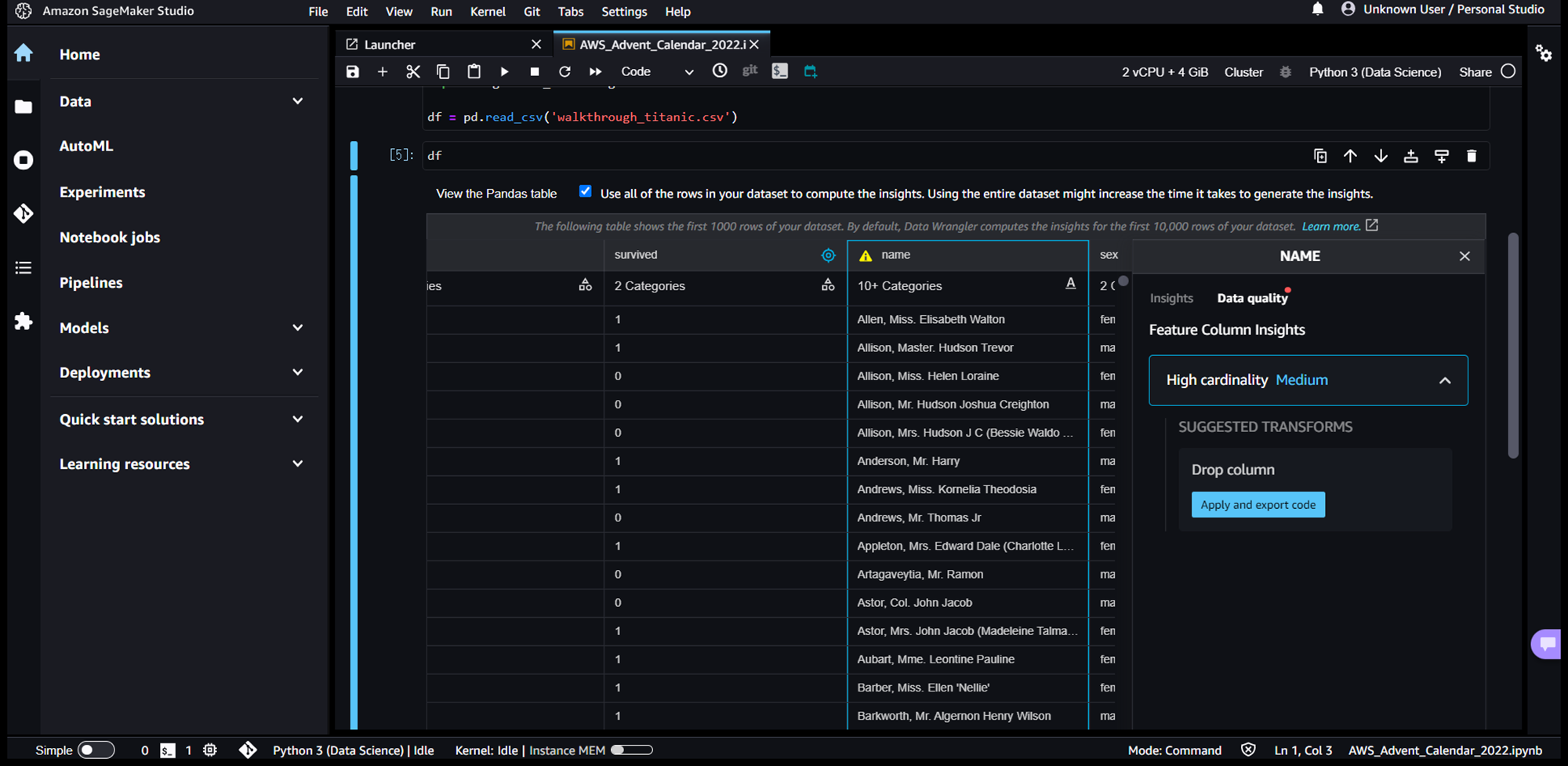
そして、以下赤枠のようにdfを表示するだけで、自動でDataWranglerがデータを分析し、可視化を実施してくれます。通常は、df.describe()やdf.value_counts()を使って統計値や要素数を確認していくことが多いと思いますが、コードを書く必要もなくよく実施する集計作業をやってくれて便利です。
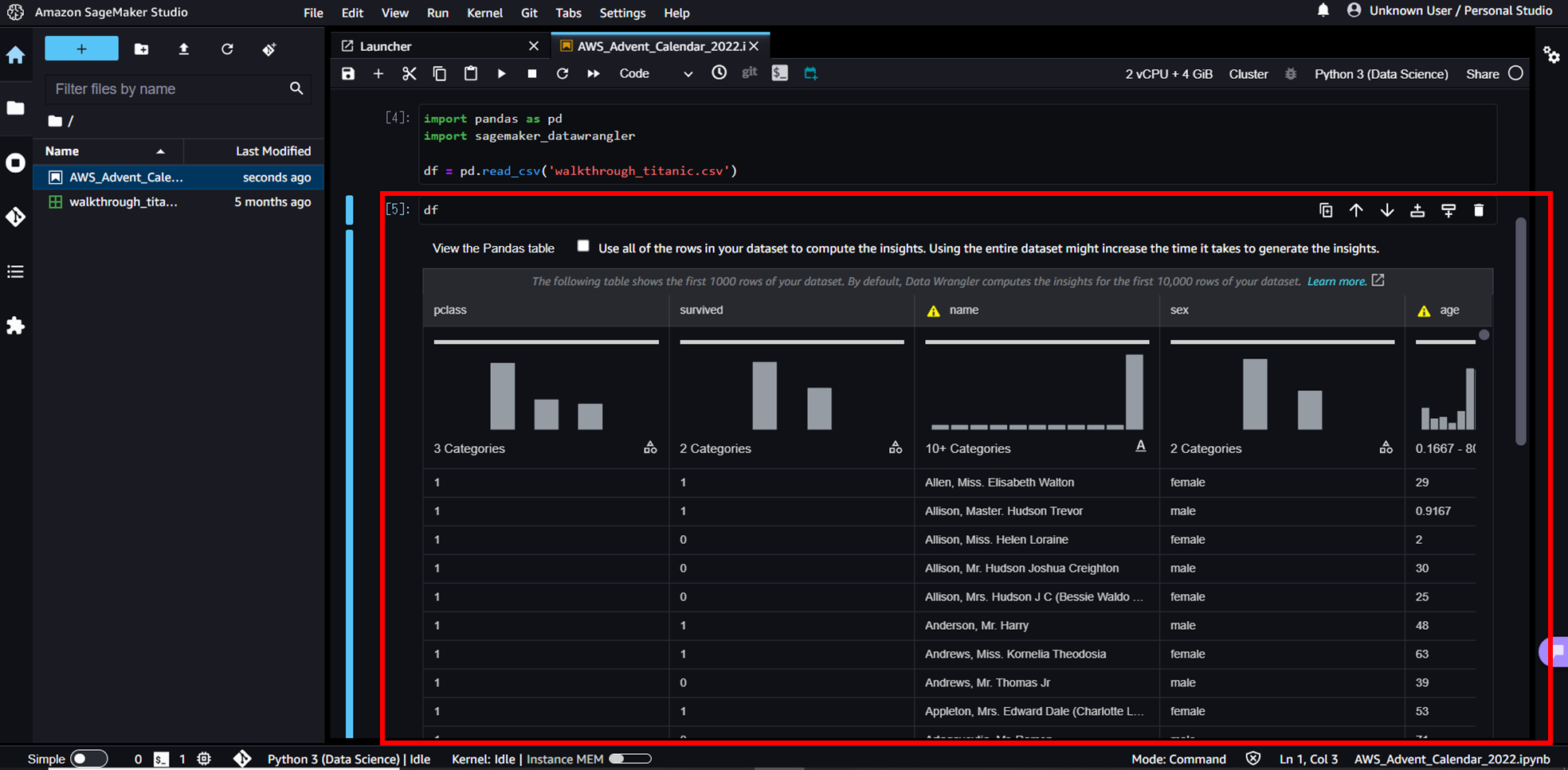
「View the Pandas table」を押下すると、表示をデータテーブルに切り替えることもできます。
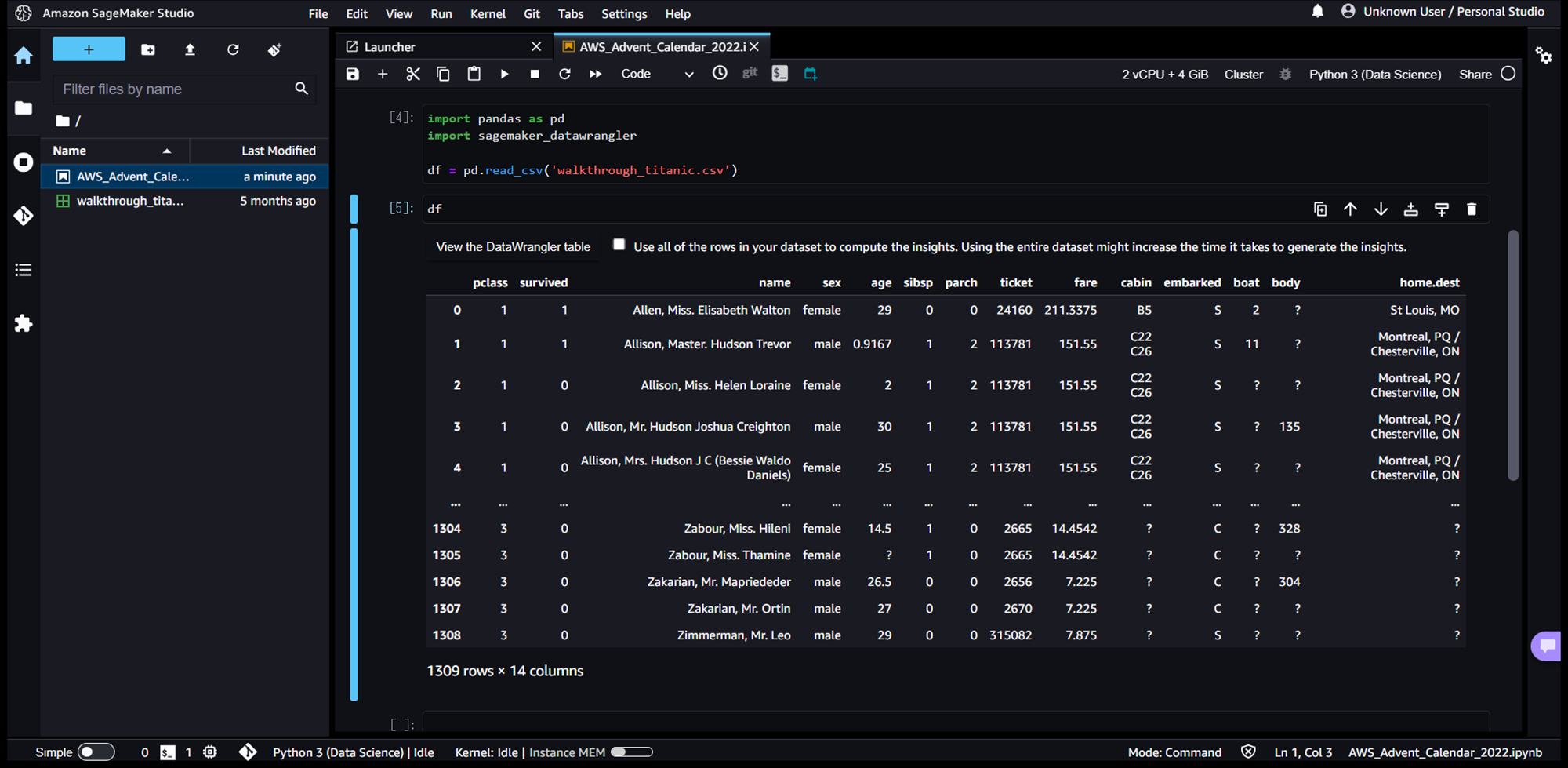
続いて、カラムを押下すると、赤枠のように詳細ビューが起動します。カラム内の平均値、最大値、最小値、要素数といった統計値算出や、データ品質(欠損値や不正な値)チェックを実施してくれます。
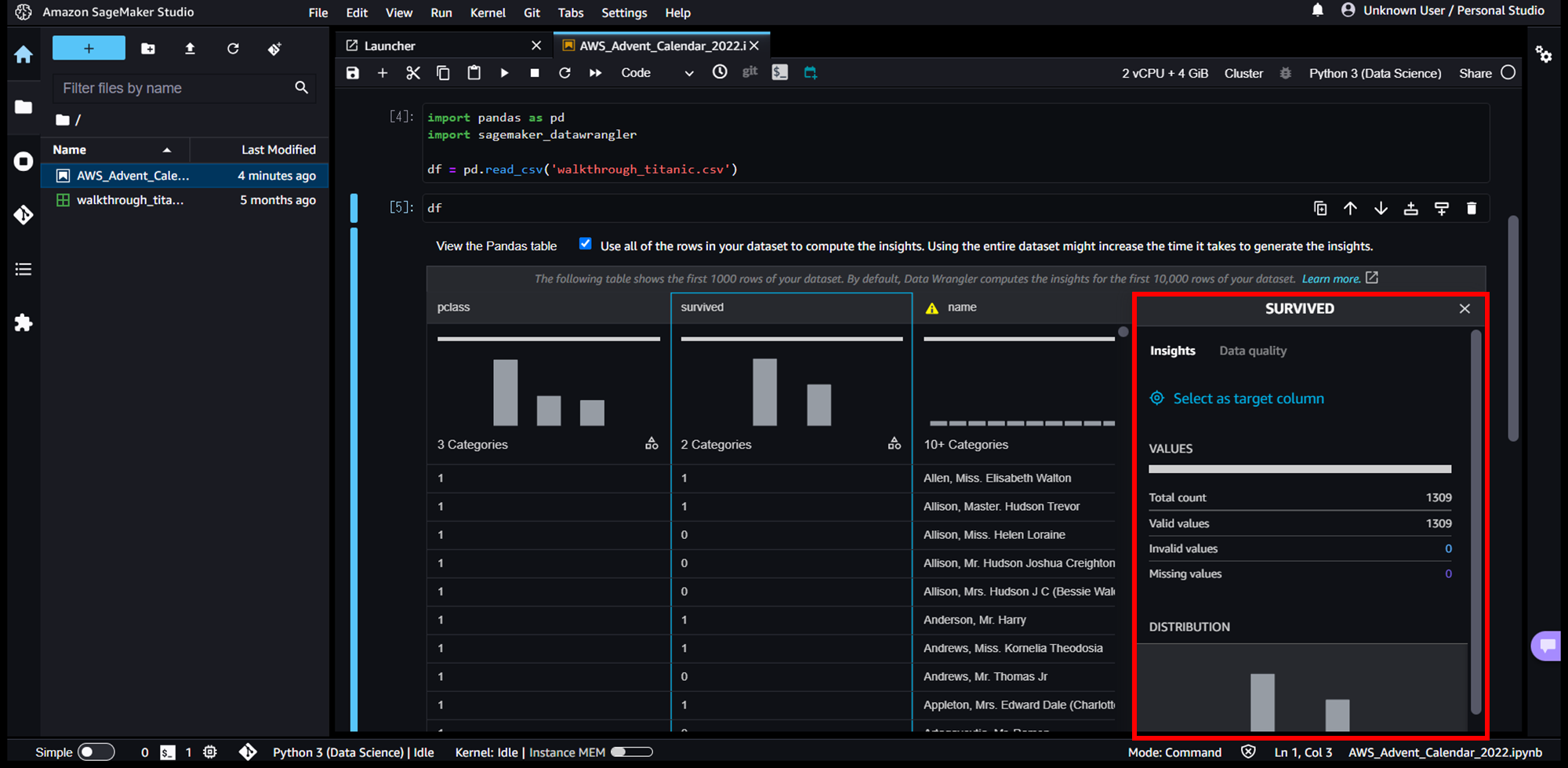
データ品質に問題がある場合、カラム名に注意マークが表示され、詳細ビューの「Data quality」タブでどのような問題があるかを確認することができます。例えば、nameカラムは「High cardinality」となっており、カラム内にデータ種類が多すぎることがすぐに分かります。タブ内の「SUGGESTED TRANSFORMS」で、データ品質の問題を解決する推奨のデータ変換を提案してくれます。
「Apply and export code」を押下すると、UI で直接適用でき、データ品質の改善結果を確認することができます。
サポートされているすべてのデータ変換のリストについては、公式ドキュメントで公開されています。不均衡データの判定・変換など目的変数に特化したデータ品質にも対応しており、よく実施するデータ変換には対応していそうです。
また、データ変換を適用すると、SageMaker Studio ノートブックはコードを自動的に生成して、別のノートブック セルでそれらのデータ準備手順を再現してくれます。
注意マークがついていたすべてのカラムに対して推奨のデータ変換を適用して生成されたコードは以下で、これを実行すると元データの変換を再現できます。GUIで実施したデータ変換をいざ本番環境にデプロイする際に、このようなコード生成機能があると非常にありがたいと思います。
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True)
# Code to Drop column for column: name to resolve warning: High cardinality
output_df=output_df.drop(columns=['name'])
# Code to Replace with new value for column: age to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['age']=output_df['age'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: fare to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['fare']=output_df['fare'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: cabin to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['cabin']=output_df['cabin'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: embarked to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['embarked']=output_df['embarked'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: boat to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['boat']=output_df['boat'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: body to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['body']=output_df['body'].replace('?', 'Other', regex=False)
# Code to Replace with new value for column: home.dest to resolve warning: Disguised missing values
generic_value = 'Other'
output_df['home.dest']=output_df['home.dest'].replace('?', 'Other', regex=False)
新機能2:SageMaker Notebook Job(ノートブックジョブ)
SageMaker Studio ノートブックで実装したコードをジョブ実行できるようになりました。
これまでは、ノートブック上でインタラクティブに構築したコードをバッチジョブとして実行しようとすると、Pythonファイル化、Dockerイメージの準備、Amazon SageMaker Pipelines、AWS Lambda、Amazon EventBridgeなど様々なサービス・機能を組み合わせてインフラの設定や本番環境へのデプロイ設計をする必要があり、広範なスキルセットが必要かつ時間もかかる作業だったと思います。
ノートブックジョブにより、数回クリックするだけで、ノートブックをそのまま、またはパラメータ化して実行できるようになりました。即時実行(Run now)または、スケジュール起動(Schedule)の2種類を設定することができます。
アーキテクチャ図がAWS公式ブログでも説明されています。
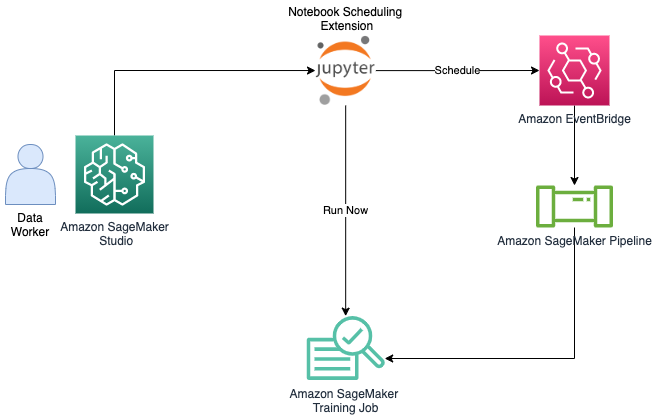
- 即時実行(Run now):SageMaker Studioでノートブックジョブの設定で、即時実行(Run now)を選択すると、TrainingJobのインスタンスが起動し、ジョブを実行します。
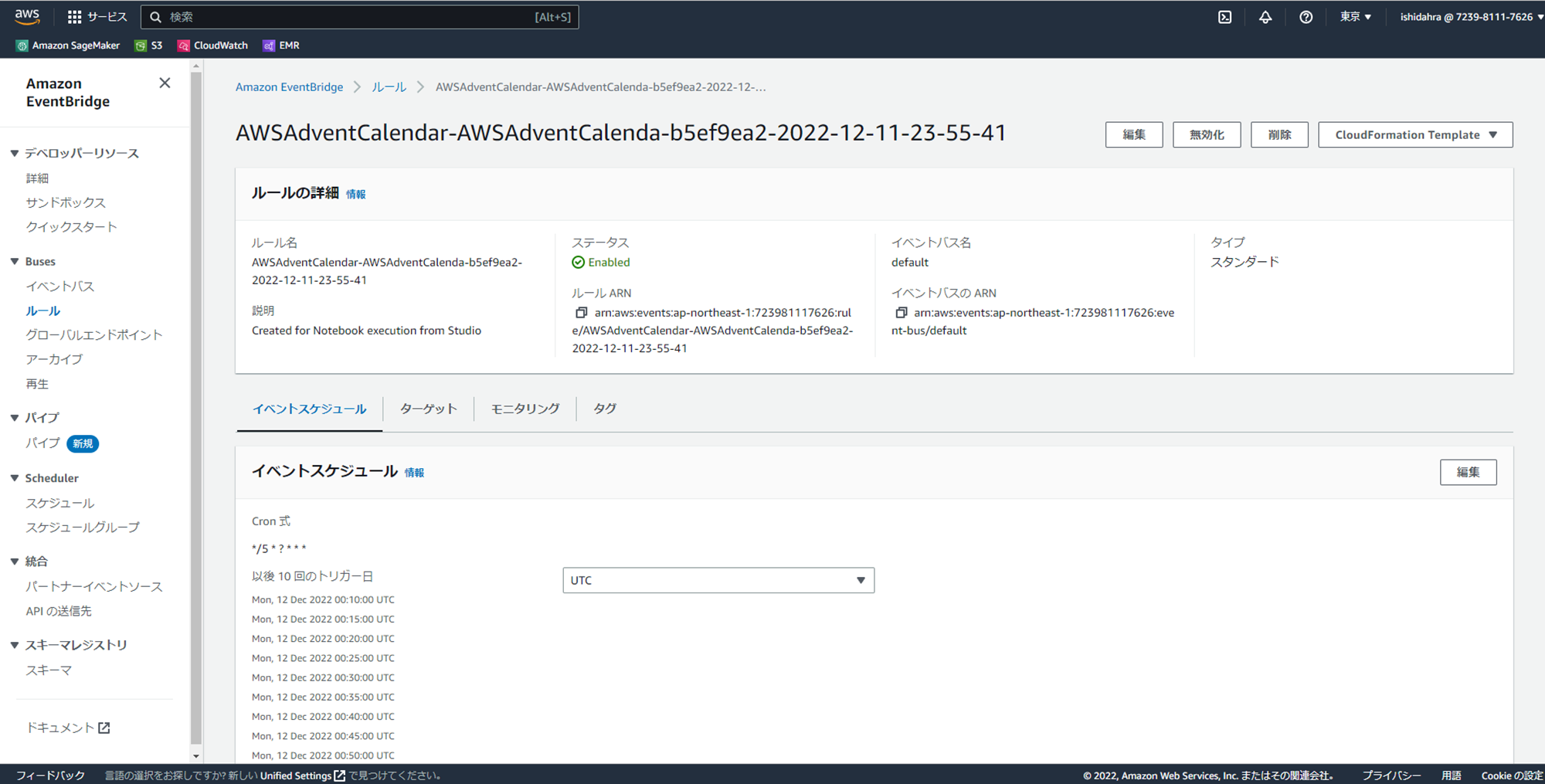
- スケジュール起動(Schedule):SageMaker Studioでノートブックジョブの設定で、スケジュール起動(Schedule)を選択すると、Cronを指定することができます。設定が完了すると、Amazon EventBridgeからSageMaker Pipelineを起動するイベントルールが自動で生成され、SageMaker PipelineからCron設定に基づき、TrainingJobのインスタンスが起動し、ジョブを実行します。
利用方法
利用準備(IAMロール設定)
はじめに、ノートブックジョブを実行するために、SageMaker 実行ロール(DomainまたはUserProfileに紐づけたIAMロール)に追加の権限を追加する必要がある場合があります。
SageMaker 実行ロールの信頼関係にevents.amazonaws.comを追加します。これは、スケジュール起動のために裏でEventBridgeと連携するためです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
また、SageMaker 実行ロールに以下のポリシーを定義します。こちらは公式ドキュメントを参照したポリシーですが、かなり大雑把で機能を動作するための最小権限にはなっていなさそうなので、ユースケースに合わせてポリシーの絞り込みを実施した方がよいかなと思います。
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":"iam:PassRole",
"Resource":"arn:aws:iam::*:role/*",
"Condition":{
"StringLike":{
"iam:PassedToService":[
"sagemaker.amazonaws.com",
"events.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"events:TagResource",
"events:DeleteRule",
"events:PutTargets",
"events:DescribeRule",
"events:PutRule",
"events:RemoveTargets",
"events:DisableRule",
"events:EnableRule"
],
"Resource":"*",
"Condition":{
"StringEquals":{
"aws:ResourceTag/sagemaker:is-scheduling-notebook-job":"true"
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:CreateBucket",
"s3:PutBucketVersioning",
"s3:PutEncryptionConfiguration"
],
"Resource":"arn:aws:s3:::sagemaker-automated-execution-*"
},
{
"Effect":"Allow",
"Action":[
"sagemaker:ListTags"
],
"Resource":[
"arn:aws:sagemaker:*:*:user-profile/*",
"arn:aws:sagemaker:*:*:space/*",
"arn:aws:sagemaker:*:*:training-job/*",
"arn:aws:sagemaker:*:*:pipeline/*"
]
},
{
"Effect":"Allow",
"Action":[
"sagemaker:AddTags"
],
"Resource":[
"arn:aws:sagemaker:*:*:training-job/*",
"arn:aws:sagemaker:*:*:pipeline/*"
]
},
{
"Effect":"Allow",
"Action":[
"ec2:CreateNetworkInterface",
"ec2:CreateNetworkInterfacePermission",
"ec2:CreateVpcEndpoint",
"ec2:DeleteNetworkInterface",
"ec2:DeleteNetworkInterfacePermission",
"ec2:DescribeDhcpOptions",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeVpcs",
"ecr:BatchCheckLayerAvailability",
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer",
"ecr:GetAuthorizationToken",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetEncryptionConfiguration",
"s3:PutObject",
"s3:DeleteObject",
"s3:GetObject",
"sagemaker:DescribeDomain",
"sagemaker:DescribeUserProfile",
"sagemaker:DescribeSpace",
"sagemaker:DescribeStudioLifecycleConfig",
"sagemaker:DescribeImageVersion",
"sagemaker:DescribeAppImageConfig",
"sagemaker:CreateTrainingJob",
"sagemaker:DescribeTrainingJob",
"sagemaker:StopTrainingJob",
"sagemaker:Search",
"sagemaker:CreatePipeline",
"sagemaker:DescribePipeline",
"sagemaker:DeletePipeline",
"sagemaker:StartPipelineExecution"
],
"Resource":"*"
}
]
}
即時実行(Run now)
新機能1用に作成したSageMaker Studio ノートブック(AWS_Advent_Calendar_2022.ipynb)をジョブ化しようと思います。実行されていることを確認するために、S3にデータ変換後のデータをS3に格納するセルを追加しておきます。
output_df.to_csv('output.csv')
!aws s3 cp ./output.csv s3://sagemaker-ishidahra01-advent/output.csv
まずは、画面上部にある赤枠のアイコンをクリックします。
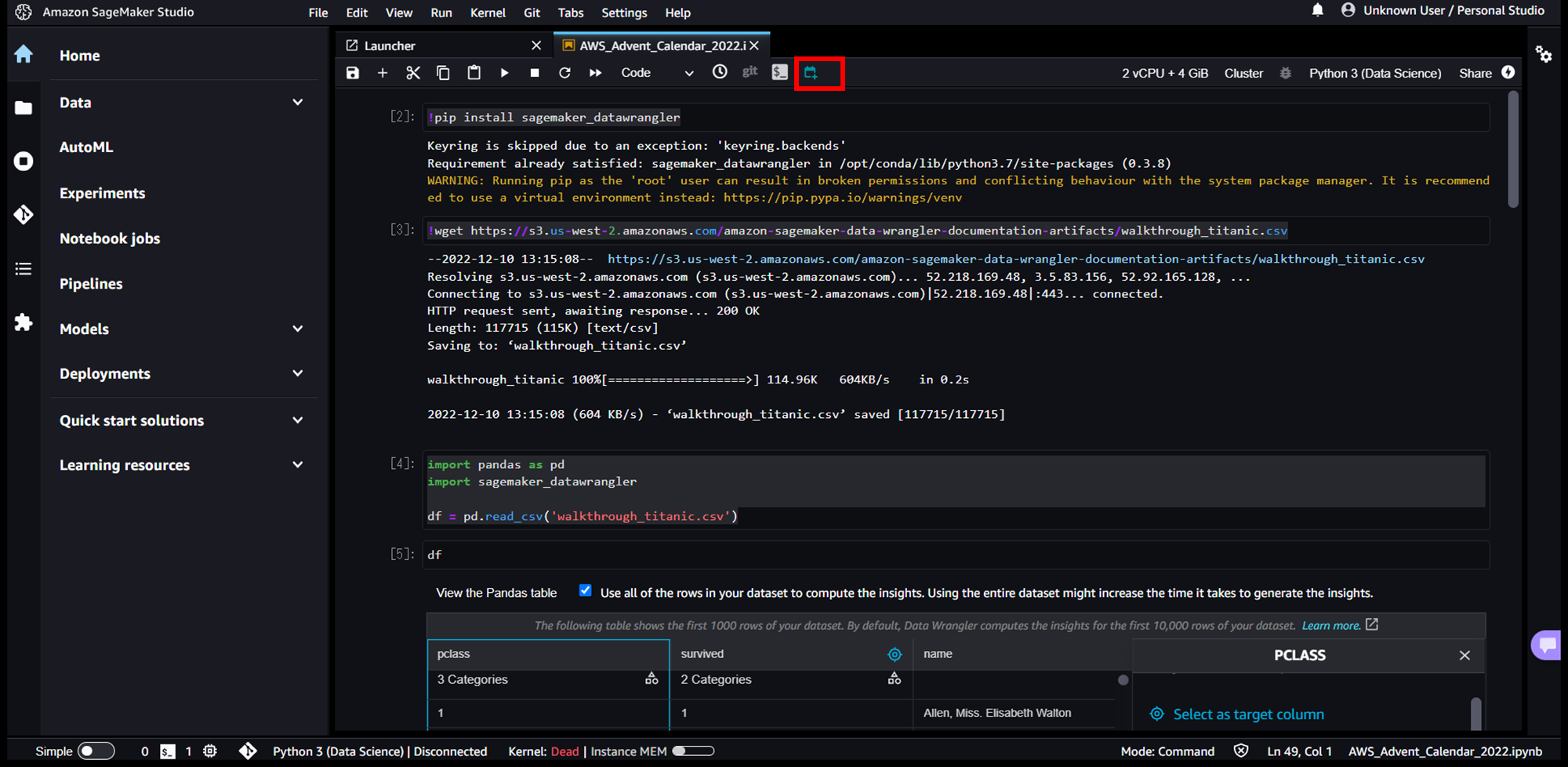
ノートブックジョブの設定画面が表示されるので、「Run now」を選択して、「Create」を押下します。
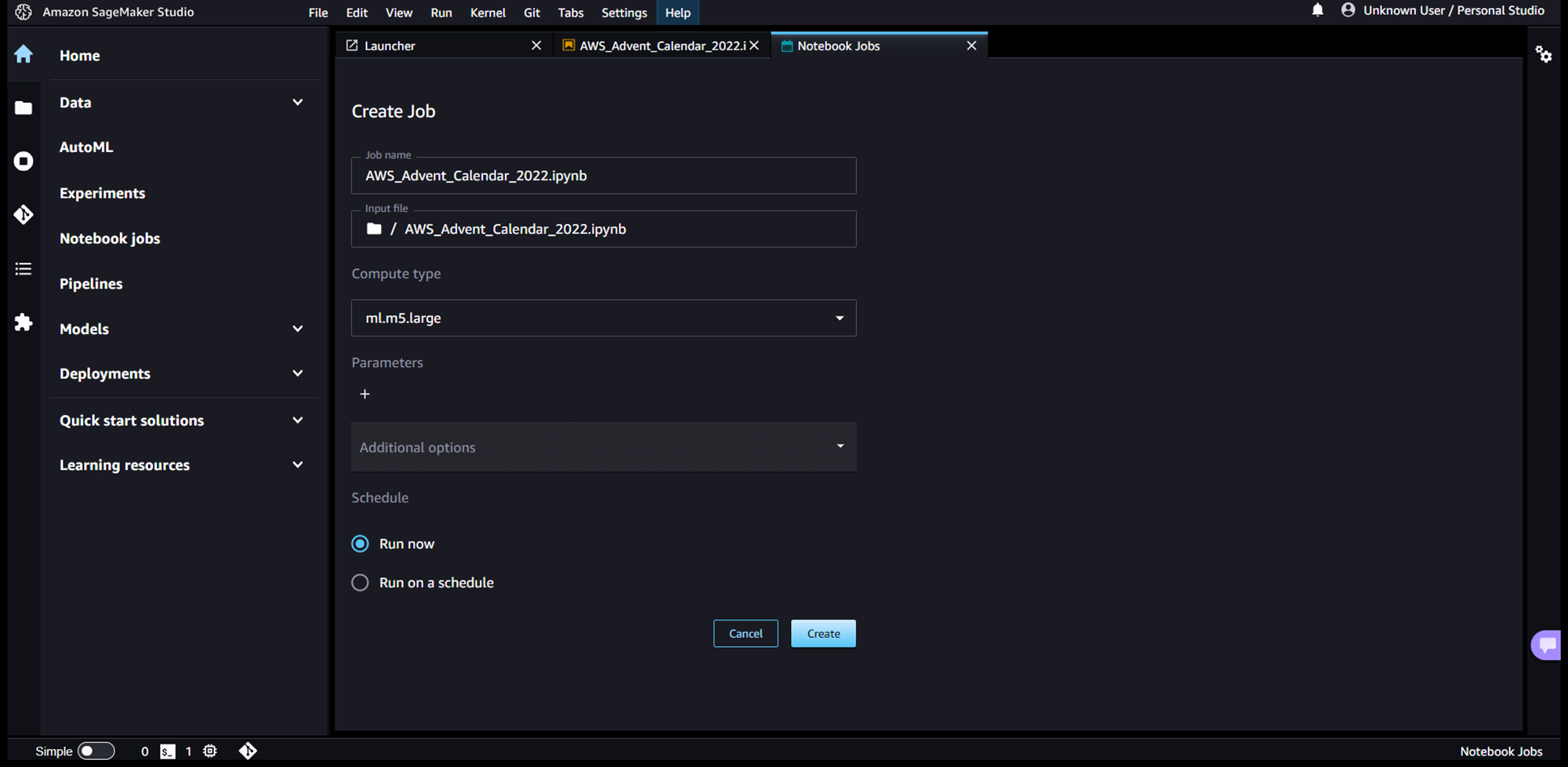
そうすると、ノートブックジョブが即時起動され、以下のようにダッシュボード画面にジョブが表示されます。
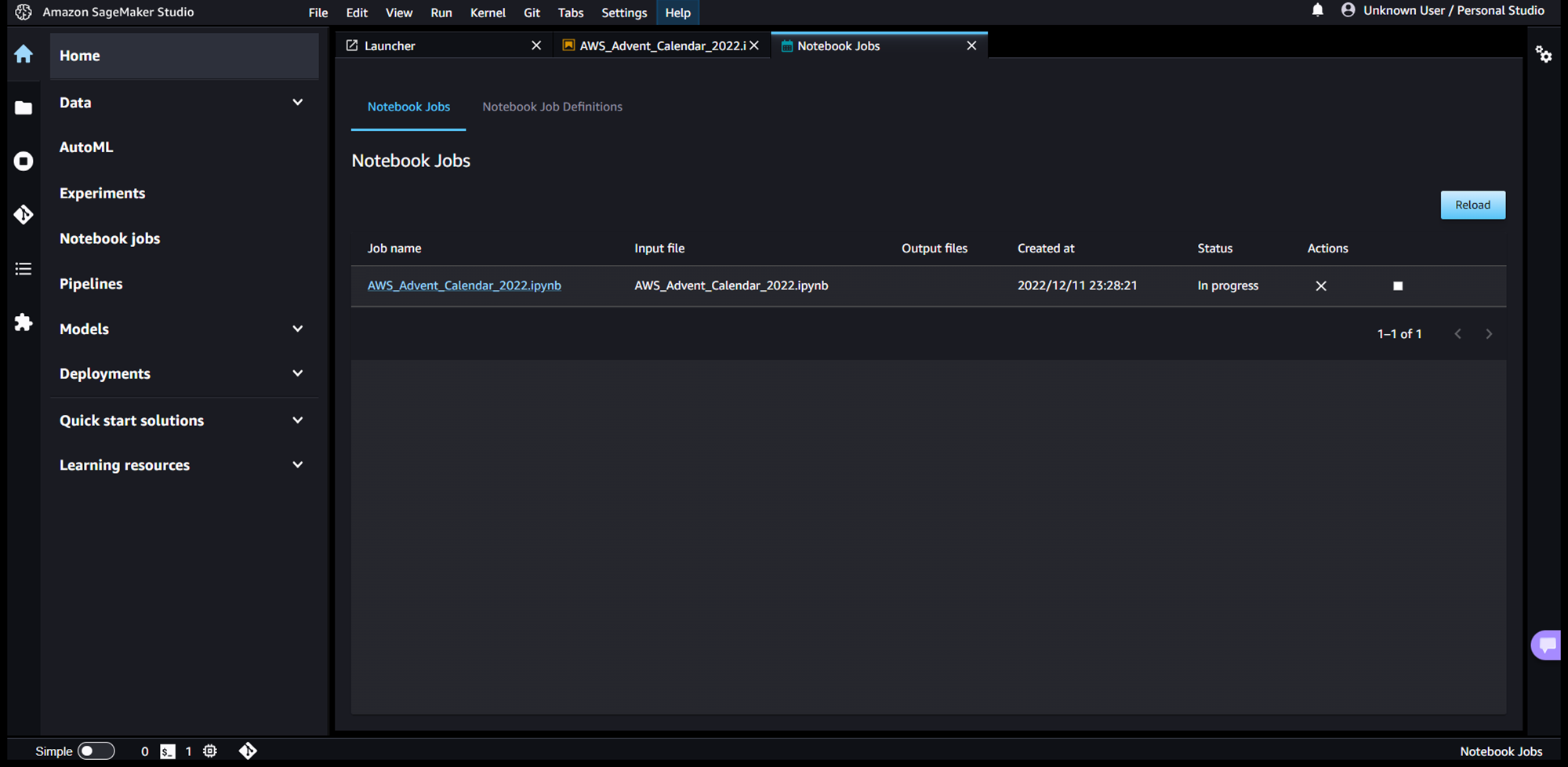
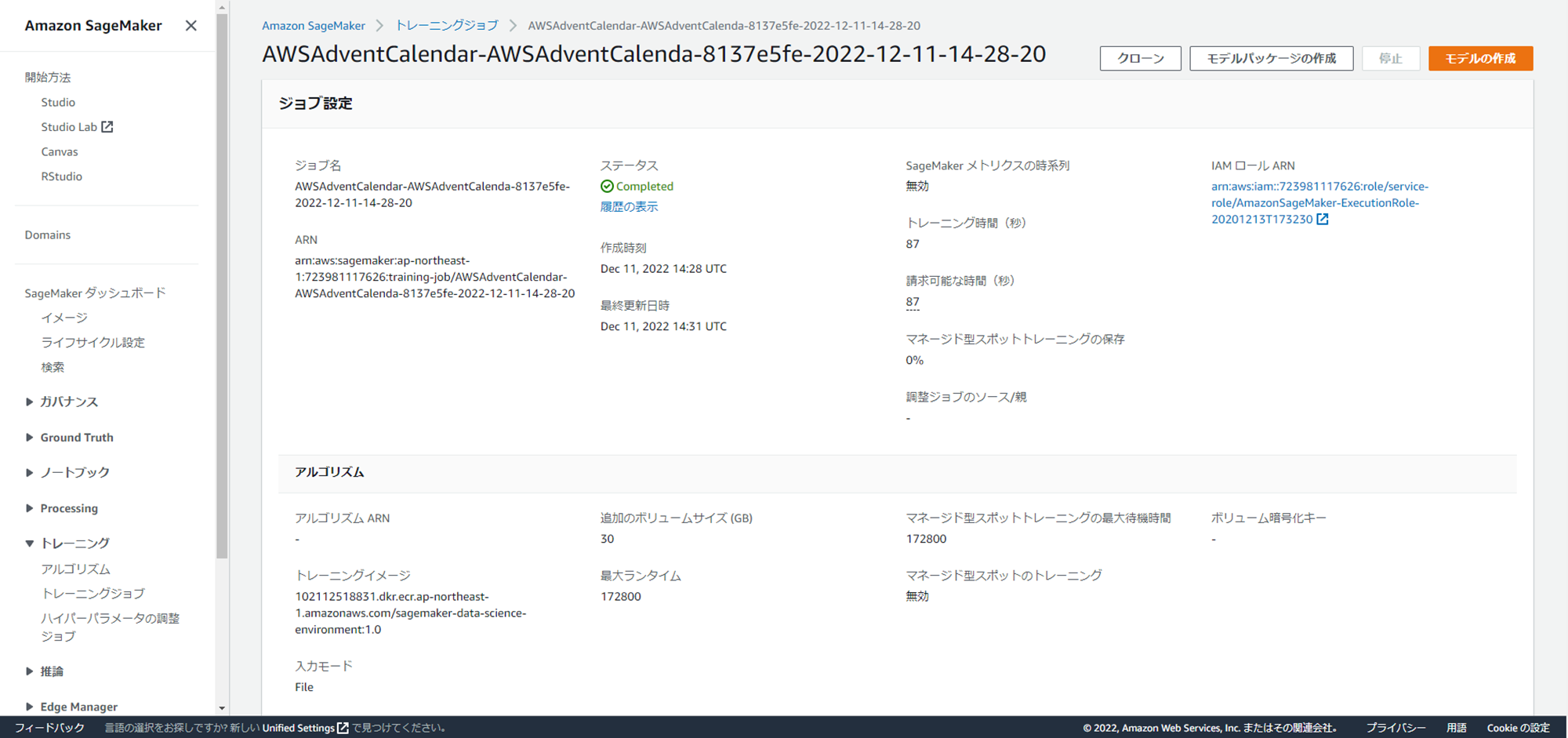
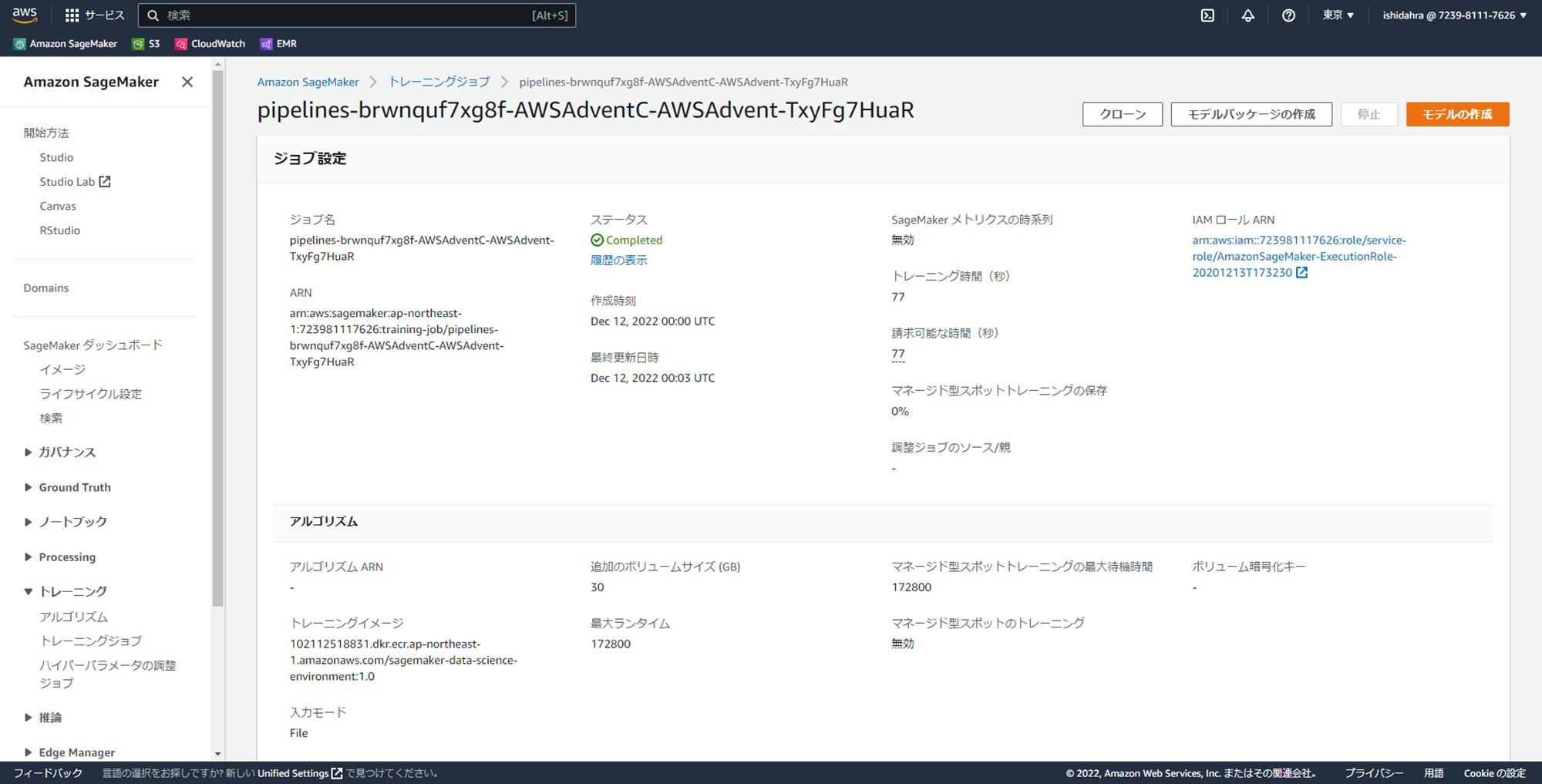
マネジメントコンソールからTrainingJobの実行履歴を確認すると、アーキテクチャ図に記載されている通り、TrainingJobでインスタンスが起動されていることが分かります。
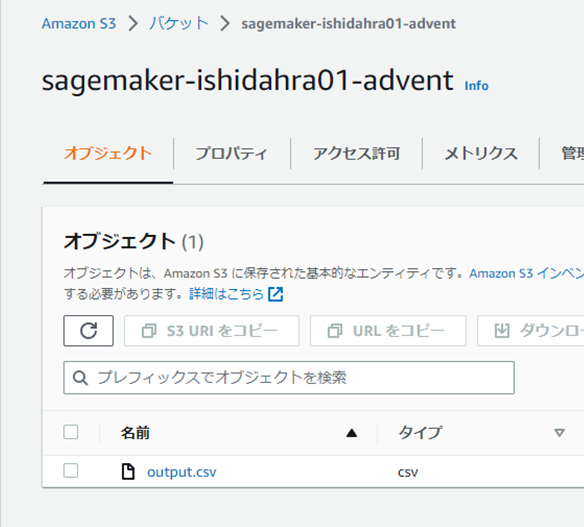
ノートブックジョブが完了となったら、S3にデータ変換後のデータが格納されており、正しく動作できたことが確認できました。
スケジュール起動(Schedule)
こちらも、新機能1用に作成したSageMaker Studio ノートブック(AWS_Advent_Calendar_2022.ipynb)をジョブ化しようと思います。
まずは、画面上部にある赤枠のアイコンをクリックします。
ノートブックジョブの設定画面が表示されるので、「Run on a schedule」を選択すると、スケジュールの設定項目が表示されます。いくつか組み込みの設定項目がありますが、ここでは、Cronで「5分ごとの実行スケジュール」を指定してみます。
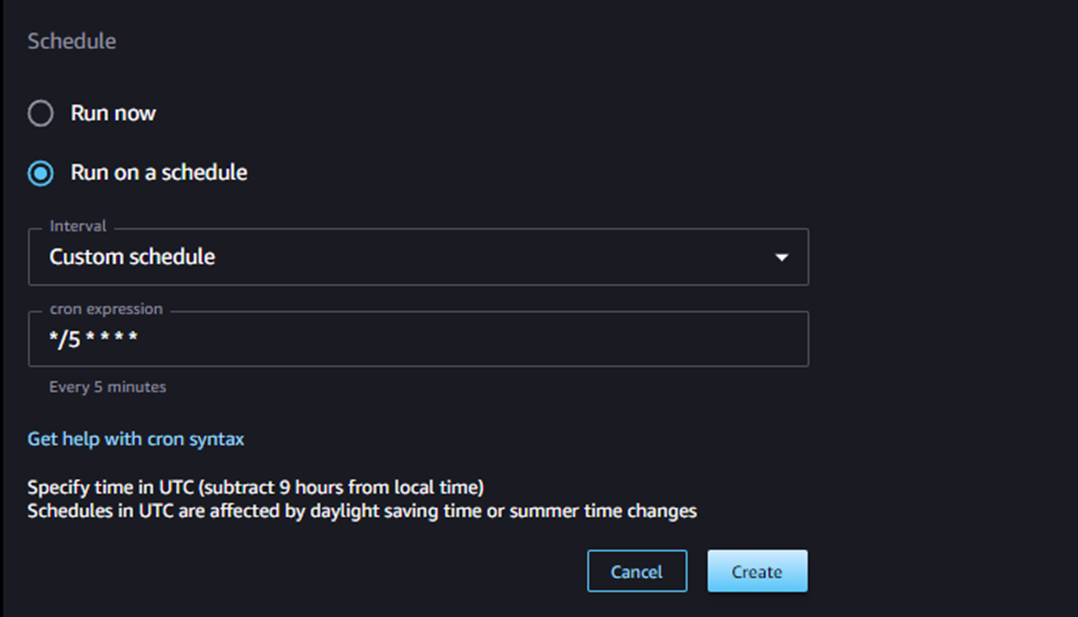
作成すると、ノートブックジョブが定義され、以下のようにダッシュボード画面にジョブ定義が表示されます。
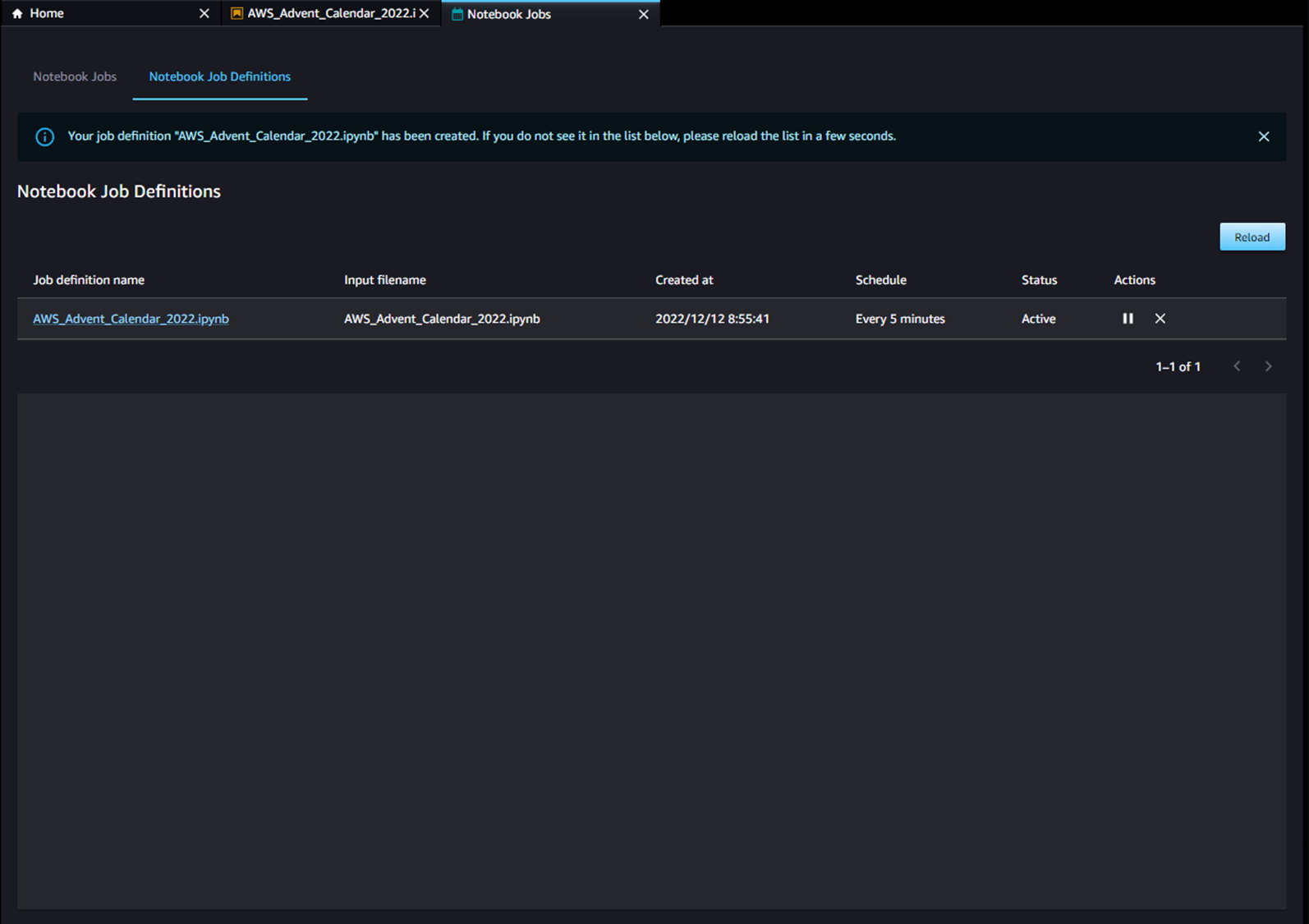
マネジメントコンソールからEventBridgeのコンソールを開くと、アーキテクチャ図に記載されている通り、設定したCronと、SageMaker Pipelineをターゲットにしたイベントルールが自動で設定されていることを確認できます。
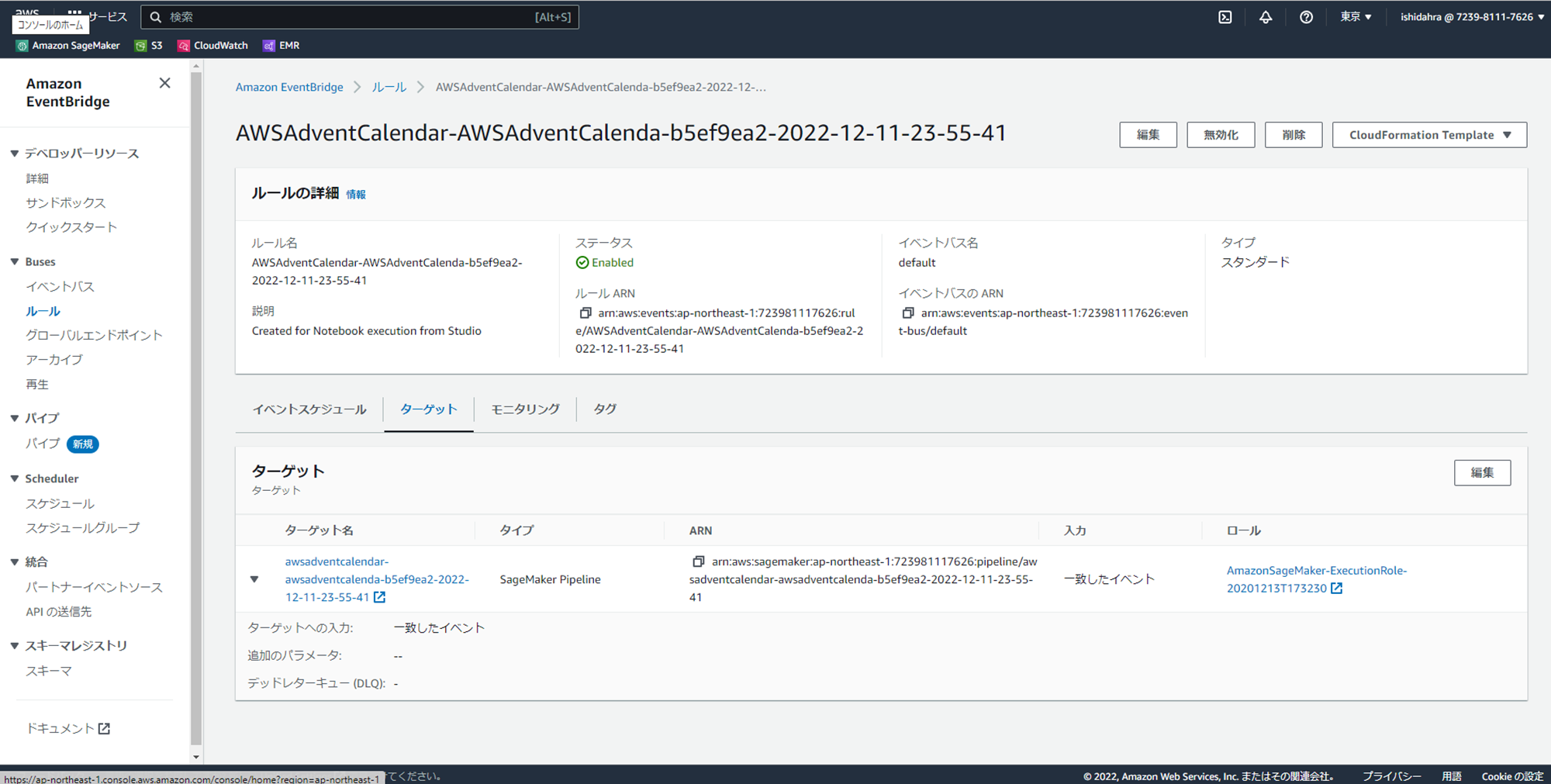
5分ほど待って、定期実行されていることを確認します。
SageMaker Studioから、SageMaker Pipelineのダッシュボードを開くと、5分おきに実行されていることを確認できます。
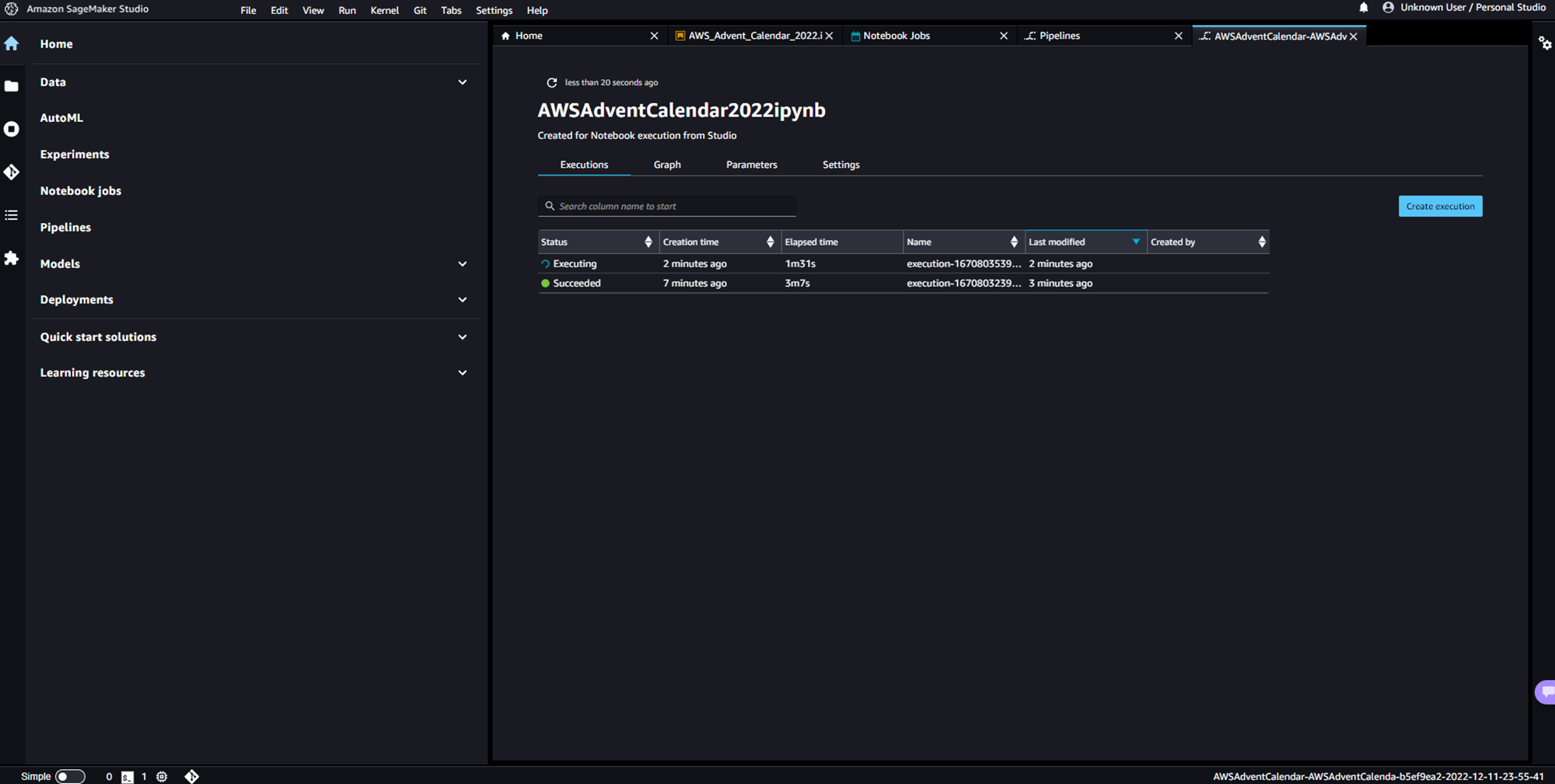
また、SageMaker PipelineからTrainingJobでインスタンスが起動されノートブックジョブが実行されていることが分かります。
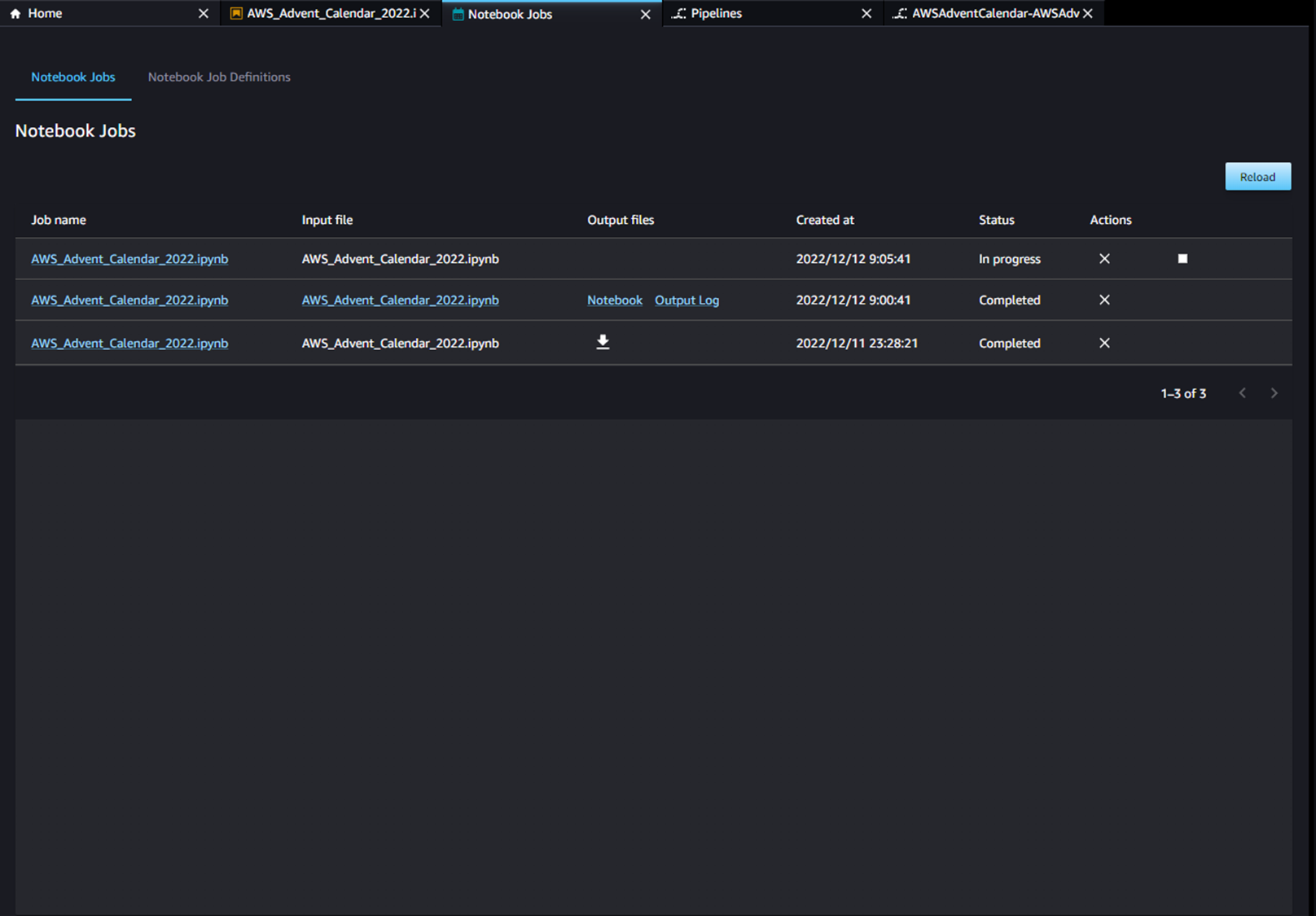
同様にノートブックジョブのダッシュボードからも5分おきに設定したノートブックジョブが実行されていることが確認できます。
スケジュール起動された、ノートブックジョブの完了後に、S3にデータ変換後のデータが格納されており、正しく動作できたことが確認できました。
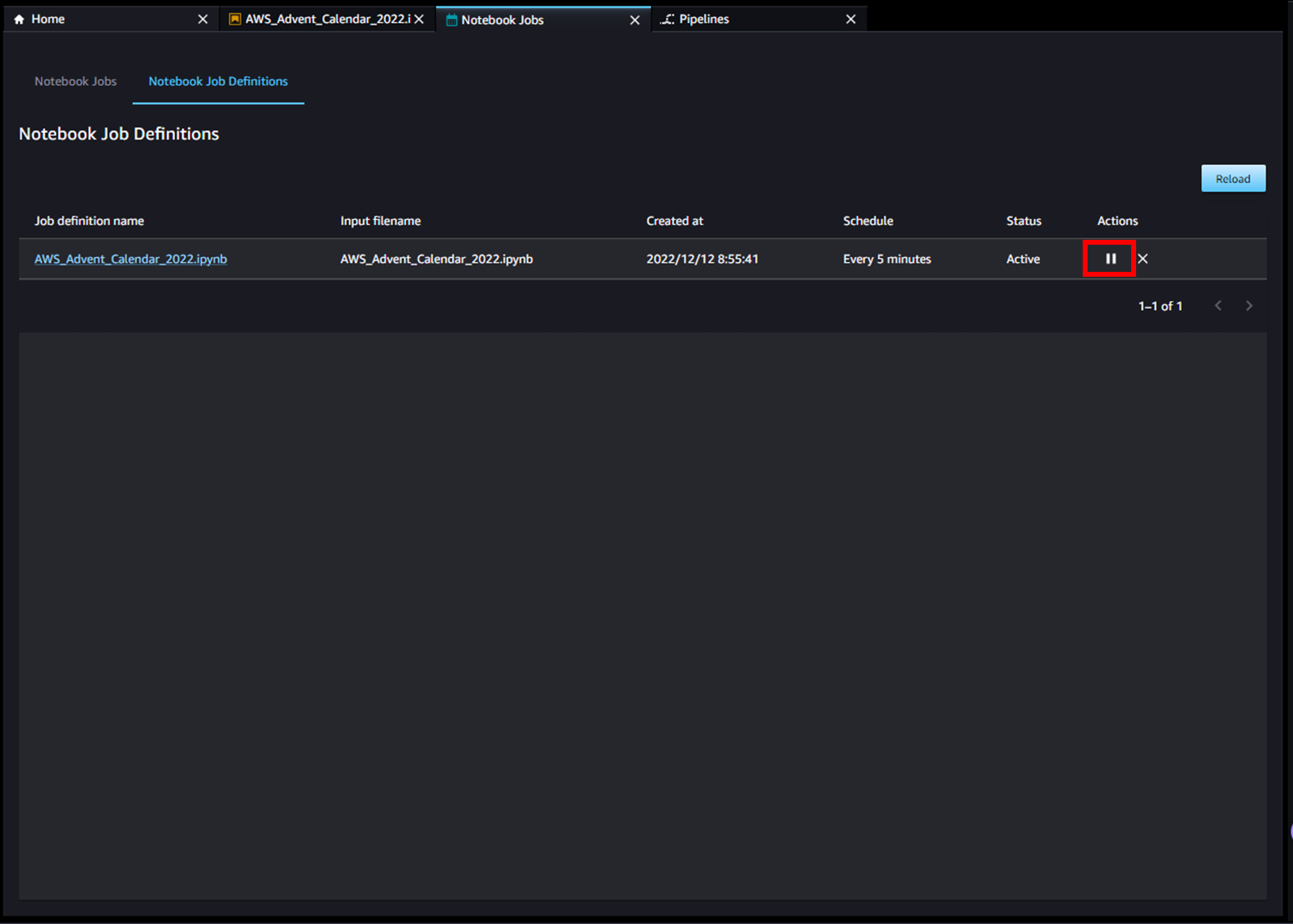
スケジュール起動は、ノートブックジョブのダッシュボードから赤枠の停止ボタンを押下することで停止することができます。
まとめ
今回は、re:invent2022で発表されたAmazon SageMaker Notebooksの以下2つの新機能について、メリットや操作方法を整理しました。どちらも、機械学習開発に携わっている人にはメリットが非常に大きく、とてもありがたいアップデートだったのではと思います。
- 新機能1:built-in data preparation capability(DataWranglerの組み込み)
- 新機能2:SageMaker Notebook Job(ノートブックジョブ)
その他にも、気になるアップデート情報がたくさんあったので、試してみたいと思います。(時間があったらまたまとめようかな、、、)