
はじめに
こんにちわ!突然で恐縮ですが、皆さん「Tidy Data 」(日本語では「整然データ」と訳されています。) というコトバを聞いたことがありますでしょうか?私は先日、Safari Books OnlineのPandas Data Analysis with Python FundamentalsというコースでPandasの勉強をしていたら、最後に「Tidy Data」という章が出てきてこのコトバを知りました。「Tidy Data」とは(R の世界において神とあがめられている)ハドリー・ウィッカム (Hadley Wickham) 氏のTidy Dataという論文(2014)で提唱された概念です。同論文は日本語訳もあり、翻訳の冒頭では以下のように紹介されています。
効果的なデータ分析に関して、「整然データ」という概念を提唱した論文 “Tidy Data” の全訳。整然データは、Rなどでデータ分析を容易にする有用な概念である。
Tidy Dataとは、要は「分析者の仕事の80%を占める」と言われるデータのクリーニング/整理作業をできるだけ簡単で効果的に行うための概念および手法です。同論文は著者の背景からRを念頭に置いて執筆されていますが、上述のSafari Onlineのコースではそれらデータ整理のパターンをPython/Pandasで実装する方法が紹介されていました。恥ずかしながらデータ分析におけるデータ整理の手法・メソドロジーをきちんと整理したものを読んだことがなかったので、非常に刺激を受けたことが当記事執筆の動機です。
![]() (2019/3/2) 当記事は2017/4月に投稿したのですが、この記事の元ネタ動画コースで講師を勤められたDaniel Y. Chenさんのpandas本「Pandas for Everyone」が「Pythonデータ分析/機械学習のための基本コーディング! pandasライブラリ活用入門」として2019/2/22に翻訳出版されました。整然データの説明もありますので、ご紹介しておきますネ。
(2019/3/2) 当記事は2017/4月に投稿したのですが、この記事の元ネタ動画コースで講師を勤められたDaniel Y. Chenさんのpandas本「Pandas for Everyone」が「Pythonデータ分析/機械学習のための基本コーディング! pandasライブラリ活用入門」として2019/2/22に翻訳出版されました。整然データの説明もありますので、ご紹介しておきますネ。

まずは日本語の記事をオススメ
Colorless Green Ideasというサイトの執筆者の方が日本語で同論文の翻訳&「整然データ」の考え方をとてもわかりやすく解説してくれています。
整然データ(Tidy Data)って要は何なのか?
については私の素人っぽい説明より上記の「整然データとは何か」の記事をご一読いただくのがベストですが、お忙しい方のために(すごく乱暴ですが)以下にサマリーします。
【始めに(アタリマエの話)】![]() (2019/10月) 説明例を変更しました1
(2019/10月) 説明例を変更しました1
下記は「医療機関で患者さんに行った処置と、その結果の値」の一覧表です。各人に対する各々の処置の結果を知りたい場合は行方向に見ればわかりますよね。行方向には各人の結果が並んでおり、それを「観測」と呼びます。また列方向には行った処置の種類が並んでいますね。これらを「変数」と呼びます。これは人間にはわかりやすい形ですね。
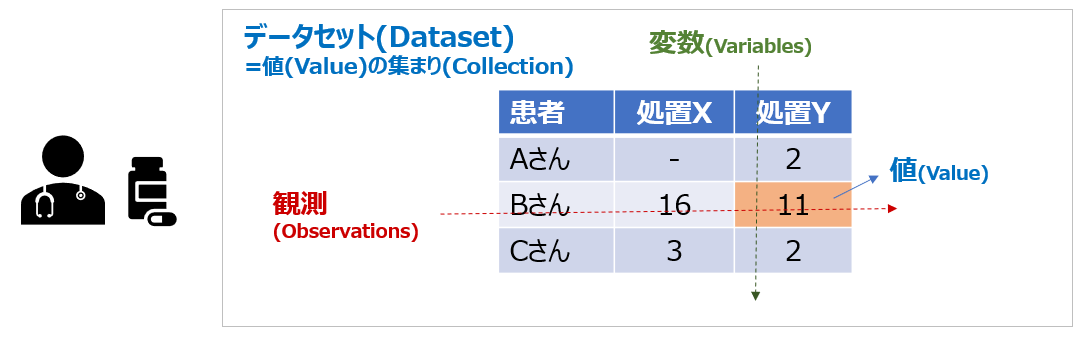
【データの意味と構造】
ここで「各患者さんに対して、ある処置を適用した結果の数値はこうだった」というデータ群(観測値)があったとして、それを実際にデータセットとして表現する場合には以下のように様々な**構造(structure)**で表現できます。
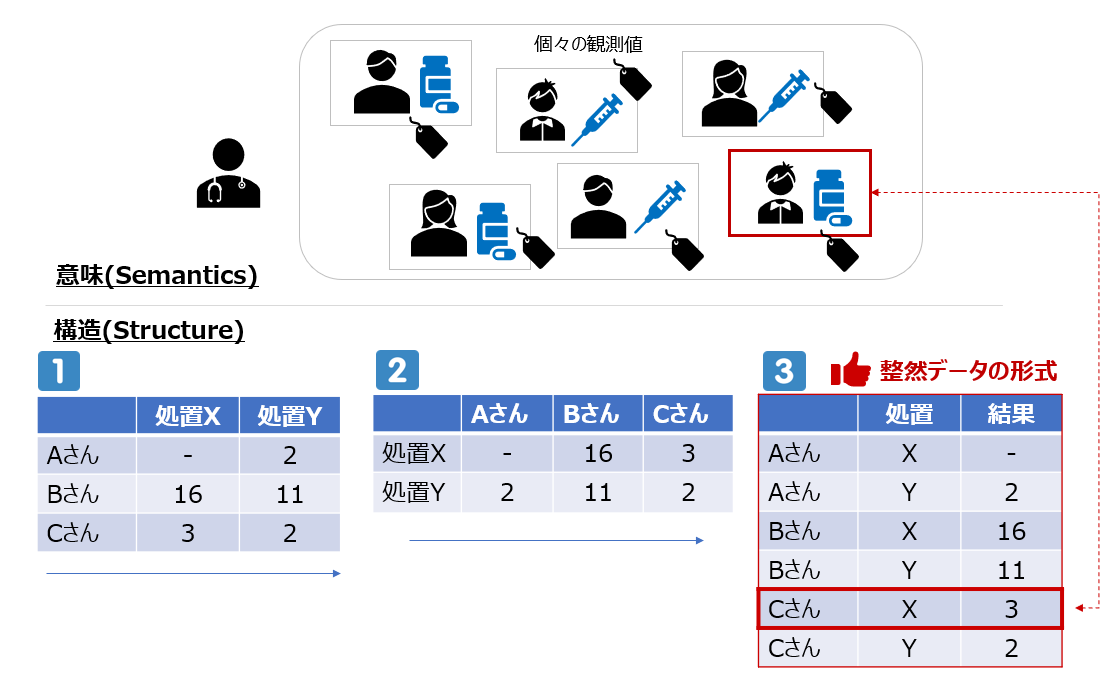
上図の構造のうち、![]() は一行に2つ、
は一行に2つ、![]() は一行に3つの観測値を含んでいますが、一番右の
は一行に3つの観測値を含んでいますが、一番右の![]() では一行の観測値は1つだけ(「Cさんに行った処置Xの結果、値は3だった」)です。つまり
では一行の観測値は1つだけ(「Cさんに行った処置Xの結果、値は3だった」)です。つまり![]() の形はデータの「意味(semantics)」と「構造(structure)」が、一致しているのです。これが「整然データ」の重要なポイントです。「整然データ」の論文では「(人間にとってのわかりやすさとは別に)データ分析においては、こちらの形の方が扱いやすいよ」という主張がなされています。(なぜそちらのほうが扱いやすいのか?については「整然データとは何か」記事の「構造と意味の合致の重要性」という箇所をご参照ください)
の形はデータの「意味(semantics)」と「構造(structure)」が、一致しているのです。これが「整然データ」の重要なポイントです。「整然データ」の論文では「(人間にとってのわかりやすさとは別に)データ分析においては、こちらの形の方が扱いやすいよ」という主張がなされています。(なぜそちらのほうが扱いやすいのか?については「整然データとは何か」記事の「構造と意味の合致の重要性」という箇所をご参照ください)
【つまり「整然データ」とは?】
極めて乱暴に言うなら
- 分析対象のデータは意味と構造を一致させた形に整理・変換したほうが、後でデータ分析(例えば集計やplottingなど)する時に扱いやすいよ~
- 分析対象のデータはちゃんと正規化(Normalization)しといたほうがいいよ~
ということかと思います。
雑然データセットの整然化(Tidying messy datasets)
「整然データ(Tidy Data)」論文の「雑然データセットの整然化」の章では、「よくある雑然データ(messy data)のパターン」を5つ挙げ、各々のデータ整理の方向性を示してくれています。以降、当記事ではそれらを実際にpandasでどうやって整理していくか、の例をご紹介します。
- 当然ながらコード・レベルでの実装方法は他にもいろいろあると思いますので、あくまで「例」です
- タイトル行は前述の日本語訳での表現を使わせて頂きました
- 例は基本的に元の論文に掲載されているものにしました
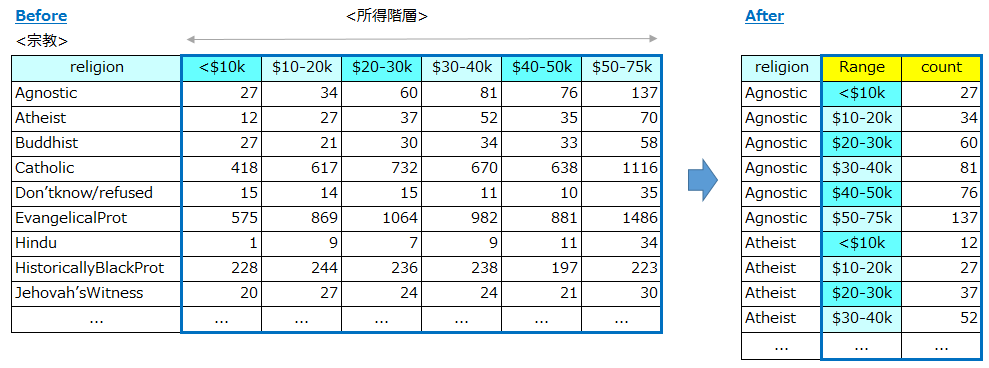
1.列見出しが、値であって変数名でない
Column headers are values, not variable names
【例】
下記はある調査での「宗教」と「所得階層」毎の人数をカウントしたものです。左側のテーブルでは「所得階層」は横軸で表現されていますが、「$10K以下」「$10-20K」など列の見出し自体が値を含んでいる点がよろしくありません。これを右側の「整然データ」の形に変換します。
【方法の説明】
この変換はpandasのmeltを使うと簡単に変換できます。
- id_vars= 基本軸となるカラムを指定します(上の例では「religion」)
- var_name= 変数(Variable)となるカラムに名前を付けます(上の例では「Range」)
- value_name= 値(Value)となるカラムに名前を付けます(上の例では「count」)
【pandasでの変換例】
In [1]: import pandas as pd
# データの読み込み
In [2]: df=pd.read_excel('data/02_Religion.xls')
In [3]: print(df.head())
religion <$10k $10-20k $20-30k $30-40k $40-50k $50-75k
0 Agnostic 27 34 60 81 76 137
1 Atheist 12 27 37 52 35 70
2 Buddhist 27 21 30 34 33 58
3 Catholic 418 617 732 670 638 1116
4 Don’tknow/refused 15 14 15 11 10 35
# meltの実行
In [4]: df_long = pd.melt(df ,id_vars='religion', var_name='range', value_name='count')
# tidy-dataの形式に変換されました
In [5]: print(df_long.head(n=10))
religion range count
0 Agnostic <$10k 27
1 Atheist <$10k 12
2 Buddhist <$10k 27
3 Catholic <$10k 418
4 Don’tknow/refused <$10k 15
5 EvangelicalProt <$10k 575
6 Hindu <$10k 1
7 HistoricallyBlackProt <$10k 228
8 Jehovah’sWitness <$10k 20
9 Jewish <$10k 19
【例2】
下記はビルボードのヒットチャートのデータセットです。年、曲名、アーティストなどのデータと共に、チャートにランクインした週の一週目、二週目、、の順位データを保持しています。
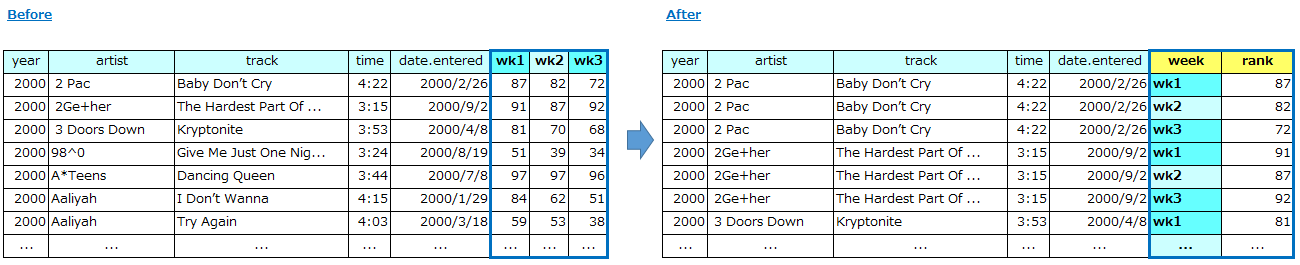
【方法の説明】
これも「整然データ」の形に直します。例1と同様にmeltを使えばいいのですが、この例では軸となるカラムが複数ありますので、id_vars=['year','artist','track','time','date.entered']のようにカラムをリストで指定します。あとは例1と同じです。
【pandasでの変換例】
# データの読み込み
In [15]: billboard = pd.read_excel('data/04_HitChart.xls')
In [16]: print(billboard.head())
year artist track time date.entered wk1 wk2 wk3
0 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 87 82 72
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 91 87 92
2 2000 3 Doors Down Kryptonite 03:53:00 2000-04-08 81 70 68
3 2000 98^0 Give Me Just One Nig... 03:24:00 2000-08-19 51 39 34
4 2000 A*Teens Dancing Queen 03:44:00 2000-07-08 97 97 96
# meltの実行(id_varsはリストで与える)
In [17]: billboard_long = pd.melt(billboard, id_vars=['year','artist','track','time','date.entered'], var_name='week', value_name
...: ='rank')
# tidy-dataの形式に変換されました
In [18]: print(billboard_long.head(n=10))
year artist track time date.entered week rank
0 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk1 87
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 wk1 91
2 2000 3 Doors Down Kryptonite 03:53:00 2000-04-08 wk1 81
3 2000 98^0 Give Me Just One Nig... 03:24:00 2000-08-19 wk1 51
4 2000 A*Teens Dancing Queen 03:44:00 2000-07-08 wk1 97
5 2000 Aaliyah I Don’t Wanna 04:15:00 2000-01-29 wk1 84
6 2000 Aaliyah Try Again 04:03:00 2000-03-18 wk1 59
7 2000 Adams, Yolanda Open My Heart 05:30:00 2000-08-26 wk1 76
8 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk2 82
9 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 wk2 87
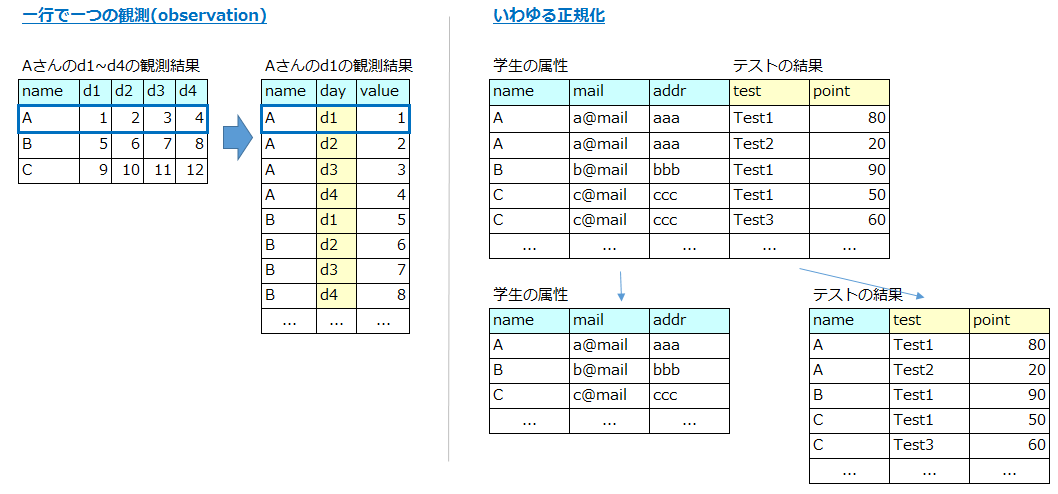
2. 複数の変数が、1つの列に格納されている
Multiple variables are stored in one column
【例】
これは結核 (TB) に関するデータで、「国」・「年」以外に「性別」と「年齢層」別の結核患者の人数を表しています。m014は男性(m)で0-14才、m1524は男性(m)で15-24才を意味します。このようにひとつのカラムに「性別」と「年齢層」の2つの変数が格納されていると、「男女別」「年齢層別」などの切り口で分析したい時によろしくありませんので、カラムを「性別」と「年齢層」に分離します。
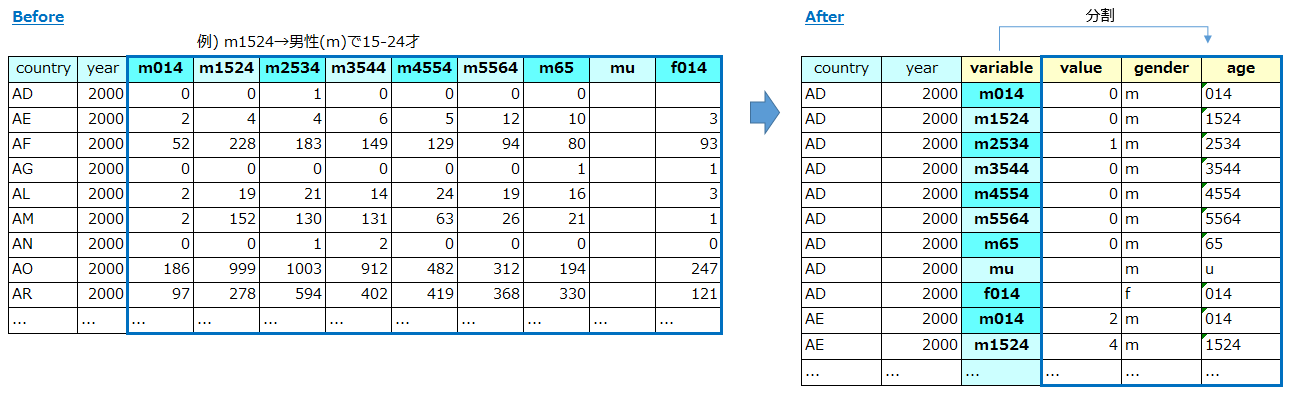
【方法の説明】
- まずは前の例と同様に「country」「year」を軸にmeltします。
- つぎにvariableカラムを「性別」と「年齢層」の2つのカラムに分割します。分割の方法は場合により様々でしょうが、今回は「カラム名の一文字目が性別を表す」ことを利用して一文字目と二文字目以降で分割します。
【pandasでの変換例】
# データの読み込み
In [2]: tb = pd.read_excel('data/05_TB.xls')
In [3]: print(tb.head())
country year m014 m1524 m2534 m3544 m4554 m5564 m65 mu f014
0 AD 2000 0.0 0.0 1.0 0.0 0 0 0.0 NaN NaN
1 AE 2000 2.0 4.0 4.0 6.0 5 12 10.0 NaN 3.0
2 AF 2000 52.0 228.0 183.0 149.0 129 94 80.0 NaN 93.0
3 AG 2000 0.0 0.0 0.0 0.0 0 0 1.0 NaN 1.0
4 AL 2000 2.0 19.0 21.0 14.0 24 19 16.0 NaN 3.0
# meltの実行
In [4]: tb_long = pd.melt(tb, id_vars=['country','year'], var_name='variable', value_name='value')
In [5]: print(tb_long.head(n=10))
country year variable value
0 AD 2000 m014 0.0
1 AE 2000 m014 2.0
2 AF 2000 m014 52.0
3 AG 2000 m014 0.0
4 AL 2000 m014 2.0
5 AM 2000 m014 2.0
6 AN 2000 m014 0.0
7 AO 2000 m014 186.0
8 AR 2000 m014 97.0
9 AS 2000 m014 NaN
# variableカラムの一文字目を抜き出してカラム「gender」を追加
In [6]: tb_long['gender'] = tb_long.variable.str[0]
# variableカラムの二文字目以降を抜き出してカラム「age」を追加
In [7]: tb_long['age'] = tb_long.variable.str[1:]
# genderとageのカラムがappendされました
In [8]: print(tb_long.head(n=10))
country year variable value gender age
0 AD 2000 m014 0.0 m 014
1 AE 2000 m014 2.0 m 014
2 AF 2000 m014 52.0 m 014
3 AG 2000 m014 0.0 m 014
4 AL 2000 m014 2.0 m 014
5 AM 2000 m014 2.0 m 014
6 AN 2000 m014 0.0 m 014
7 AO 2000 m014 186.0 m 014
8 AR 2000 m014 97.0 m 014
9 AS 2000 m014 NaN m 014
3. 変数が、行と列の両方に格納されている
Variables are stored in both rows and columns
【例】
これはメキシコのある気象観測所 (MX17004) での日々の気象データです。「年」・「月」軸に対して一日目(d1)、二日目(d2)、、と日が横軸に並んでいますが、更にelementカラムでその日の最高・最低気温の2つを行として持っています。観測した事実が行と列の両方に跨って格納されているのはよろしくありませんので、右側の形に整理します。
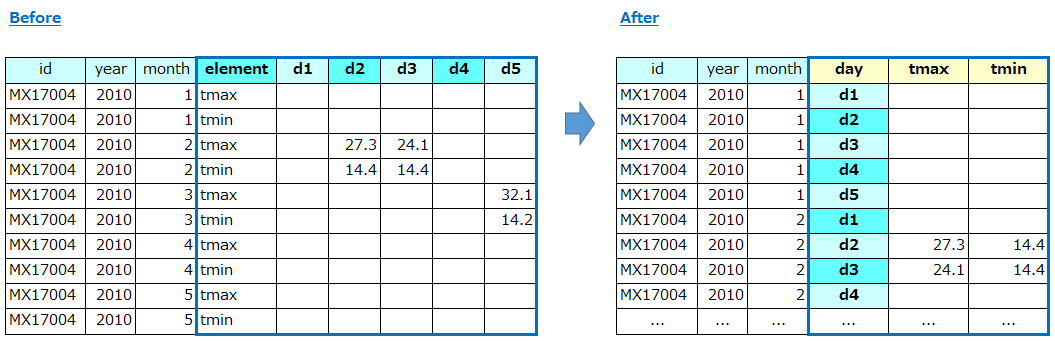
【方法の説明】
- まずは前の例と同様に「id」「year」「month」「element」を軸にmeltします。
- つぎにpivot_tableを使ってtmax, tminをカラムに昇格します。(pivot_tableはmeltの反対の動き、とも言えます)
- 最後に、pivot_tableの実行直後はindexがきれいになっていないので reset_index()で整えます。
【pandasでの変換例】
# データの読み込み
In [10]: weather = pd.read_excel('data/06_Weather.xls')
In [11]: print(weather.head())
id year month element d1 d2 d3 d4 d5 d6 d7 d8
0 MX17004 2010 1 tmax NaN NaN NaN NaN NaN NaN NaN NaN
1 MX17004 2010 1 tmin NaN NaN NaN NaN NaN NaN NaN NaN
2 MX17004 2010 2 tmax NaN 27.3 24.1 NaN NaN NaN NaN NaN
3 MX17004 2010 2 tmin NaN 14.4 14.4 NaN NaN NaN NaN NaN
4 MX17004 2010 3 tmax NaN NaN NaN NaN 32.1 NaN NaN NaN
# meltの実行
In [12]: weather_melt = pd.melt(weather,id_vars=['id','year','month','element'], var_name='day', value_name='temp')
In [13]: print(weather_melt.head(n=10))
id year month element day temp
0 MX17004 2010 1 tmax d1 NaN
1 MX17004 2010 1 tmin d1 NaN
2 MX17004 2010 2 tmax d1 NaN
3 MX17004 2010 2 tmin d1 NaN
4 MX17004 2010 3 tmax d1 NaN
5 MX17004 2010 3 tmin d1 NaN
6 MX17004 2010 4 tmax d1 NaN
7 MX17004 2010 4 tmin d1 NaN
8 MX17004 2010 5 tmax d1 NaN
9 MX17004 2010 5 tmin d1 NaN
# pivot_tableでelementカラムの値をカラムに昇格
In [14]: weather_tidy = weather_melt.pivot_table(index=['id','year','month','day'], columns='element', values='temp')
# 昇格できたがindexがイマイチ
In [15]: print(weather_tidy.head(n=10))
element tmax tmin
id year month day
MX17004 2010 1 d1 NaN NaN
d2 NaN NaN
d3 NaN NaN
d4 NaN NaN
d5 NaN NaN
d6 NaN NaN
d7 NaN NaN
d8 NaN NaN
2 d1 NaN NaN
d2 27.3 14.4
# reset_index()するときれいになる
In [16]: weather_tidy_flat = weather_tidy.reset_index()
In [17]: print(weather_tidy_flat.head(n=10))
element id year month day tmax tmin
0 MX17004 2010 1 d1 NaN NaN
1 MX17004 2010 1 d2 NaN NaN
2 MX17004 2010 1 d3 NaN NaN
3 MX17004 2010 1 d4 NaN NaN
4 MX17004 2010 1 d5 NaN NaN
5 MX17004 2010 1 d6 NaN NaN
6 MX17004 2010 1 d7 NaN NaN
7 MX17004 2010 1 d8 NaN NaN
8 MX17004 2010 2 d1 NaN NaN
9 MX17004 2010 2 d2 27.3 14.4
4. 観測の構成単位の類型が、同じ表に複数格納されている
Multiple types of observational units are stored in the same table
【例】
下記は「1.列見出しが、値であって変数名でない 」の例2のビルボードのヒットチャートの変換結果です。よく見るとこのデータセットは「曲に関する部分」と「ランキングに関する部分」が同じ表に格納されており、「曲に関する部分」は何度も繰り返されています 。「正規化」の観点で、これらは2つのデータセットに分割したほうが後々、よさそうです。
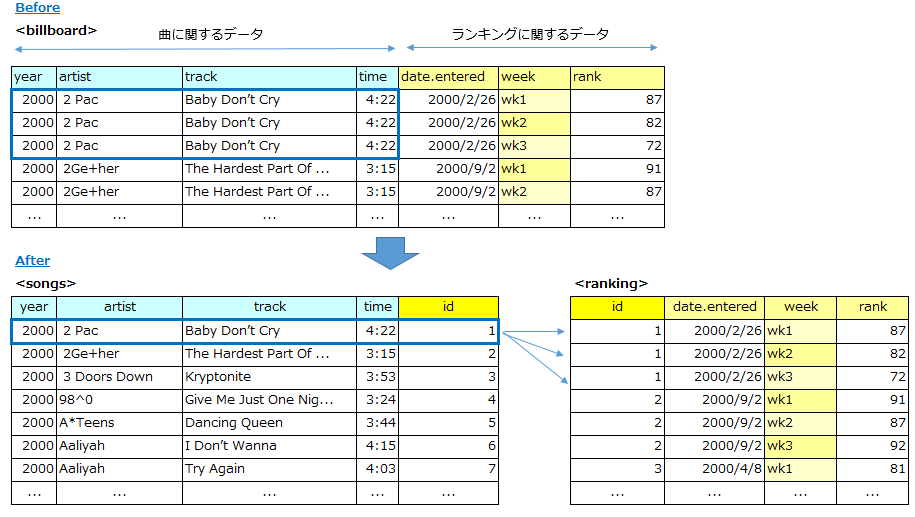
【方法の説明】
まず「曲に関する部分」は以下の手順で進めます。
- 曲に関するカラムのみを指定して新しいDataFrameを作る
- drop_duplicates()で重複を排除する
- 後で「ランキングに関する部分」とJOINするためのID列を生成する
「ランキングに関する部分」は以下の手順で進めます。
- 上記で作ったDataFrameと元のデータフレームをJOINして、ID列を生成する
- その後、ランキングに関するカラムのみを指定して新しいDataFrameを作る
【pandasでの変換例】
# データの確認
In [23]: print(billboard_long.head())
year artist track time date.entered week rank
0 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk1 87
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 wk1 91
2 2000 3 Doors Down Kryptonite 03:53:00 2000-04-08 wk1 81
3 2000 98^0 Give Me Just One Nig... 03:24:00 2000-08-19 wk1 51
4 2000 A*Teens Dancing Queen 03:44:00 2000-07-08 wk1 97
# 同一の曲のデータが繰り返されている
In [24]: print(billboard_long[billboard_long.track =='Baby Don’t Cry'].head())
year artist track time date.entered week rank
0 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk1 87
8 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk2 82
16 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk3 72
# 「曲に関する部分」で新しいDataFrameを作成(まだ繰り返し部分が重複したまま)
In [25]: billboard_songs = billboard_long[['year','artist','track','time']]
In [26]: billboard_songs.head(n=10)
Out[26]:
year artist track time
0 2000 2 Pac Baby Don’t Cry 04:22:00
1 2000 2Ge+her The Hardest Part Of ... 03:15:00
2 2000 3 Doors Down Kryptonite 03:53:00
3 2000 98^0 Give Me Just One Nig... 03:24:00
4 2000 A*Teens Dancing Queen 03:44:00
5 2000 Aaliyah I Don’t Wanna 04:15:00
6 2000 Aaliyah Try Again 04:03:00
7 2000 Adams, Yolanda Open My Heart 05:30:00
8 2000 2 Pac Baby Don’t Cry 04:22:00
9 2000 2Ge+her The Hardest Part Of ... 03:15:00
# 24行×4カラムある
In [27]: billboard_songs.shape
Out[27]: (24, 4)
# drop_duplicates()で重複を排除する
In [28]: billboard_songs = billboard_songs.drop_duplicates()
# 8行×4カラムになった
In [29]: billboard_songs.shape
Out[29]: (8, 4)
In [30]: print(billboard_songs.head())
year artist track time
0 2000 2 Pac Baby Don’t Cry 04:22:00
1 2000 2Ge+her The Hardest Part Of ... 03:15:00
2 2000 3 Doors Down Kryptonite 03:53:00
3 2000 98^0 Give Me Just One Nig... 03:24:00
4 2000 A*Teens Dancing Queen 03:44:00
# IDカラムを連番で生成して追加
In [31]: billboard_songs['id'] = range(len(billboard_songs))
# 「曲に関する部分」の完成
In [32]: print(billboard_songs.head())
year artist track time id
0 2000 2 Pac Baby Don’t Cry 04:22:00 0
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 1
2 2000 3 Doors Down Kryptonite 03:53:00 2
3 2000 98^0 Give Me Just One Nig... 03:24:00 3
4 2000 A*Teens Dancing Queen 03:44:00 4
# ここからは「ランキング」に関する部分
# 元のDataFrameと直前に作ったbillboard_songsのDataFrameをJOIN(merge)して新しいDataFrameを作成
In [33]: billboard_ratings = billboard_long.merge(billboard_songs, on=['year','artist','track','time'])
# IDカラムが追加された
In [34]: billboard_ratings.head()
Out[34]:
year artist track time date.entered week rank id
0 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk1 87 0
1 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk2 82 0
2 2000 2 Pac Baby Don’t Cry 04:22:00 2000-02-26 wk3 72 0
3 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 wk1 91 1
4 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02 wk2 87 1
# 「ランキングに関する部分」で新しいDataFrameを作成
In [35]: billboard_ratings = billboard_ratings[['id','date.entered','week','rank']]
# 「ランキングに関する部分」の完成
In [36]: print(billboard_ratings.head(n=10))
id date.entered week rank
0 0 2000-02-26 wk1 87
1 0 2000-02-26 wk2 82
2 0 2000-02-26 wk3 72
3 1 2000-09-02 wk1 91
4 1 2000-09-02 wk2 87
5 1 2000-09-02 wk3 92
6 2 2000-04-08 wk1 81
7 2 2000-04-08 wk2 70
8 2 2000-04-08 wk3 68
9 3 2000-08-19 wk1 51
5. 1つの観測の構成単位が、複数の表に格納されている
A single observational unit is stored in multiple tables
【例】
観測した事実が複数のデータセット群にバラバラに格納されていては、分析の際に不便です。以下のようにカラムのレイアウトが同一の複数のデータセット群を連結してひとつにします。
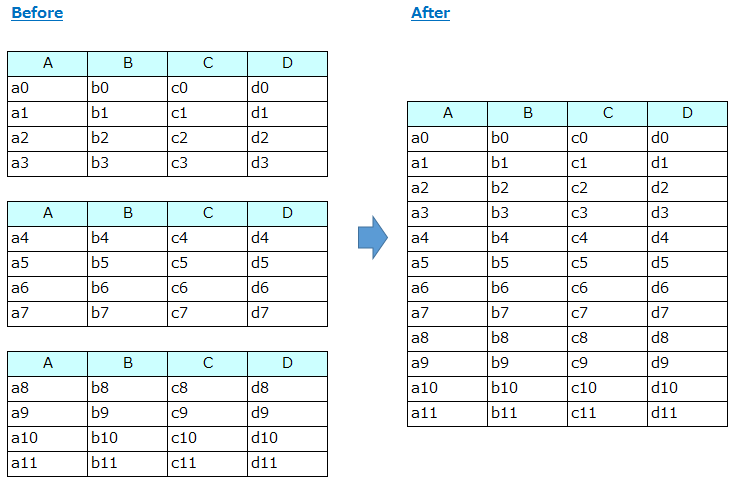
【方法の説明】
このケースはデータセットをconcatすればいいだけなので簡単ですが、データセットの数が多い場合には、いちいち pd.read_xxx()で読み込むのも大変です。globを使うと指定した条件に合う名前を持つファイルのリストが入手できますので、それを使ってconcatする方法をご紹介します。
【pandasでの変換例】
In [38]: import glob
# 条件に一致するファイル名のリスト
In [39]: concat_files = glob.glob('data/concat*')
In [40]: print(concat_files)
['data\\concat_1.csv', 'data\\concat_2.csv', 'data\\concat_3.csv']
In [41]: list_concat_df =[]
# ファイル毎にcsvファイルを読んでdfのリストにappendする
In [42]: for file in concat_files:
...: df = pd.read_csv(file)
...: list_concat_df.append(df)
...:
# 3つのDataFrameを持つリストができた
In [43]: print(list_concat_df)
[ A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3, A B C D
0 a4 b4 c4 d4
1 a5 b5 c5 d5
2 a6 b6 c6 d6
3 a7 b7 c7 d7, A B C D
0 a8 b8 c8 d8
1 a9 b9 c9 d9
2 a10 b10 c10 d10
3 a11 b11 c11 d11]
# 3つのDataFrameをappendしてひとつにし、インデックスを振りなおす
In [44]: concat_df = pd.concat(list_concat_df, ignore_index=True)
In [45]: print(concat_df)
A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
5 a5 b5 c5 d5
6 a6 b6 c6 d6
7 a7 b7 c7 d7
8 a8 b8 c8 d8
9 a9 b9 c9 d9
10 a10 b10 c10 d10
11 a11 b11 c11 d11
以下のようにリスト内包表記(list comprehension)を使って1-Liner的に書くこともできます。
In [46]: concat_files = glob.glob('data/concat*')
# ここ
In [47]: list_concat_df = [pd.read_csv(csv_file) for csv_file in concat_files]
# 以降は前の例と同じ
In [48]: print(list_concat_df)
[ A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3, A B C D
0 a4 b4 c4 d4
1 a5 b5 c5 d5
2 a6 b6 c6 d6
3 a7 b7 c7 d7, A B C D
0 a8 b8 c8 d8
1 a9 b9 c9 d9
2 a10 b10 c10 d10
3 a11 b11 c11 d11]
In [49]: concat_df = pd.concat(list_concat_df, ignore_index=True)
In [50]: print(concat_df)
A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
5 a5 b5 c5 d5
6 a6 b6 c6 d6
7 a7 b7 c7 d7
8 a8 b8 c8 d8
9 a9 b9 c9 d9
10 a10 b10 c10 d10
11 a11 b11 c11 d11
以上です。
pandasのmelt()やpivot_table()のTips的な情報(How)はネット上にもたくさんあって、それはそれで勉強になりましたが、Tidy Dataの論文のような概念/メソドロジー(WhyやWhat)の背景と結びつくと強力だなあ~、と実感した次第です。
ご参考までに
当記事の内容を皆様が手を動かして実感できるように、githubにJupyter Notebookとしてアップしました。データも付けていますのでそのまま動きます。ご興味があればダウンロードしてお試しくださいませ。
ishida330/tidy-data-in-pandas