要は(TL;DR;)
Watson VRでイメージ画像の中から自分の検出したい物体を(複数)見つけ出せるようになりました。興味の対象=「何を見つけたいか」は利用者がUIツール上で簡単に指定できます。
ってか、要はWatson VRでこういうの↓↓が簡単にできるようになったよ、ってことです。
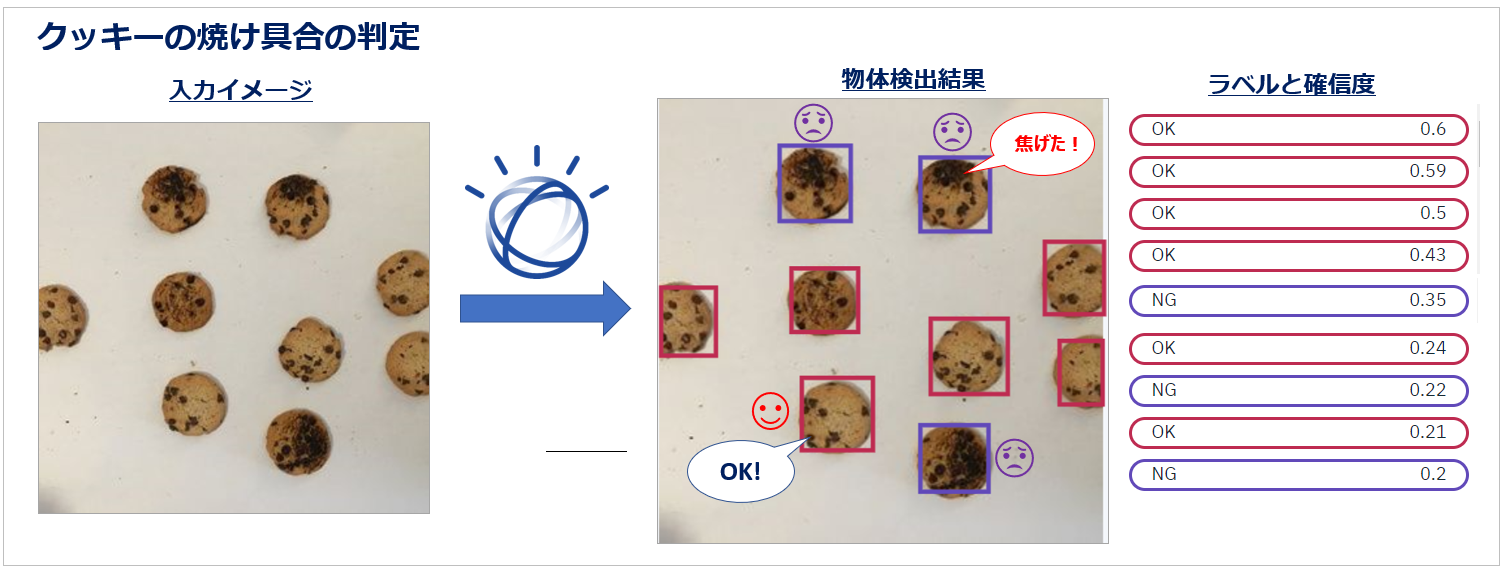
事前準備として、UIツールでイメージ中の「いい感じでやけたクッキー」の部分を枠で囲って「OK」とラベルを付けます。同様に「焦げてしまったクッキー」の部分を枠で囲って「NG」とラベルを付けます。この作業を何枚かのイメージに繰り返すと、あとはAIがよしなに処理してくれて「クッキーの焼け具合の判別器」(カスタム物体検出モデル)が簡単に作れるんです!
はじめに
こんにちわ!石田です。Watson VR(Visual Recognition)のカスタム物体検知(Object Detection)の機能はずっとベータで提供されてきましたが、10月に正式に利用可能(GA)になりました。(![]() IBM Watson Visual Recognition: Custom Object Detection Generally Available ご存知の方も多いと思いますが、この機能はPowerAI Visionで提供されてきたものを移植したものです。遅まきながらザクっとご紹介します。
IBM Watson Visual Recognition: Custom Object Detection Generally Available ご存知の方も多いと思いますが、この機能はPowerAI Visionで提供されてきたものを移植したものです。遅まきながらザクっとご紹介します。
物体検知(Object Detection)って何?
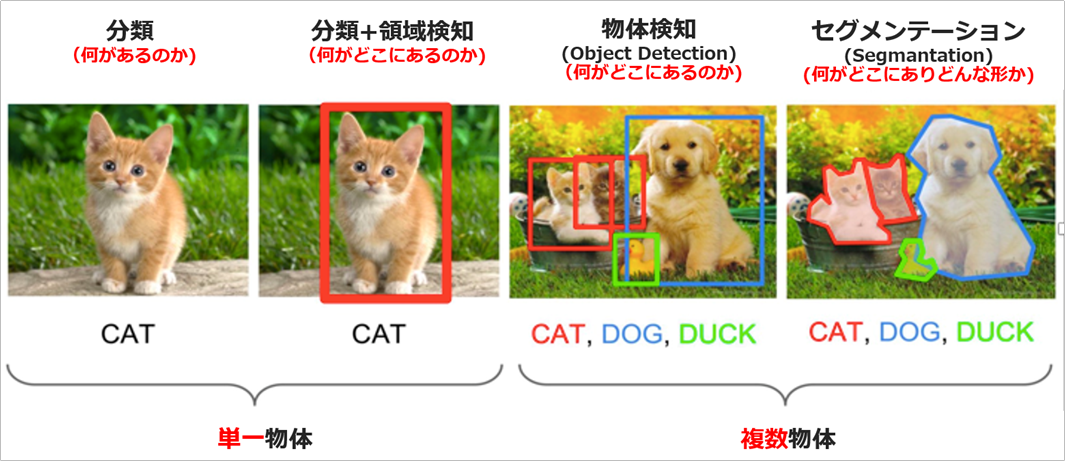
上がイメージ認識のおおまかな分類です。Watson VRは従来、一番左の「分類」機能として①一般種別(IBM側でトレーニングしたモデル) ②カスタム種別(お客様自身がトレーニングできるモデル)をご提供してきました。今回の物体検知は一枚のイメージ中で**「何がどこにあるのか」**=お好みのカスタムの物体を複数検知できるものです。
(なおPowerAI Visionでは分類や物体検知だけでなく、最右の「セグメンテーション」の機能も提供してます)
ユースケースは?
以下のような場面での利用が考えられます。
- 不良品検出
- 異常検知
- 行動監視
- 医療画像解析
- マーケティング
- 顔認識
- 有名人の認識
- 風景認識
なお一点注意点ですが、CODは静止画・イメージを対象にするものであって、動画は直接は入力できません。よって生産現場でのリアルタイムの不良品検知など、動画的な内容の物体検知に使う場合は、監視カメラ~OpenCVなど噛ませて使うことになります。(要はOpenCV噛ませてパラパラ漫画みたいな感じのことを行います)
やってみた
Watson Studioの起動
Watson Studioを起動します
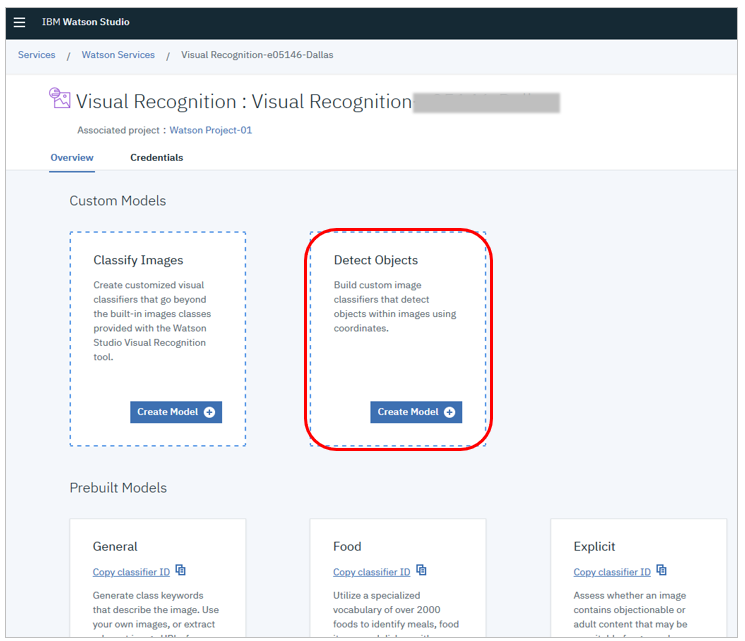
「Detect Objects」で「Create Model」ボタン
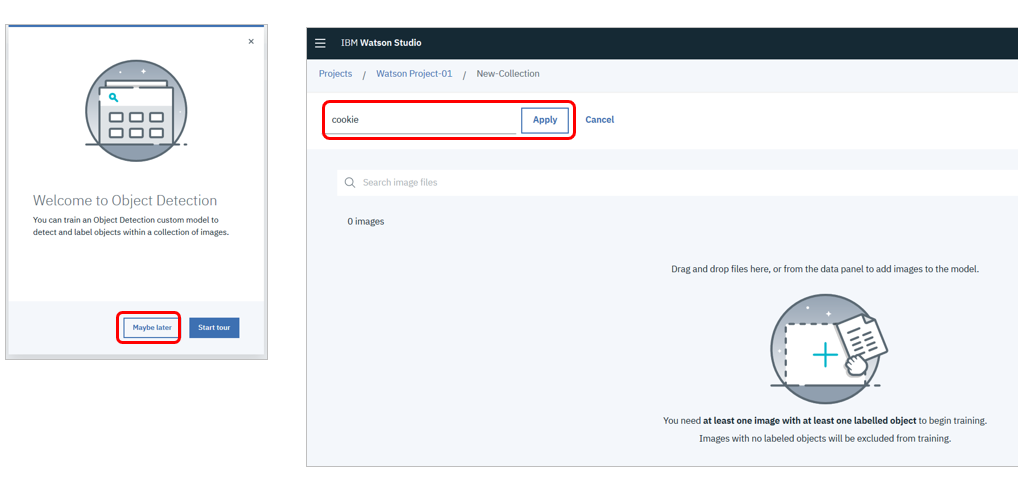
Welcomeパネルは今はスキップします。初期パネルで名前を「Cookie」として「Apply」ボタン
イメージ(教師データ)の入手とアップロード
cookieの写真のデータセットをココからダウンロードします。cookie-image.zipを解凍するとtrain.zip(トレーニング用のイメージ)とtest.zip(テスト用のイメージ)の2つのファイルが作成されます。
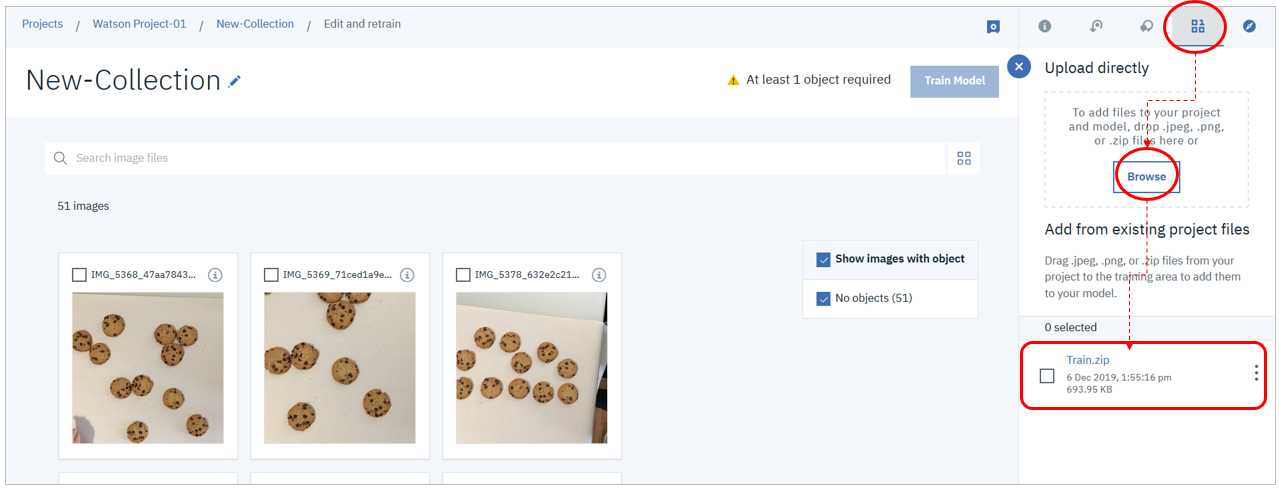
右上のデータペインを開き、「Browse」ボタンで直前にダウンロードしたTrain.zipを選択します。(または直接ドラッグ&ドロップ) 自動的にzipファイルがアップロードのうえ解凍され、左側にイメージが表示されます。(jgp/png以外が含まれているよ、という警告は無視してください)
イメージへのラベル付け(トレーニング)
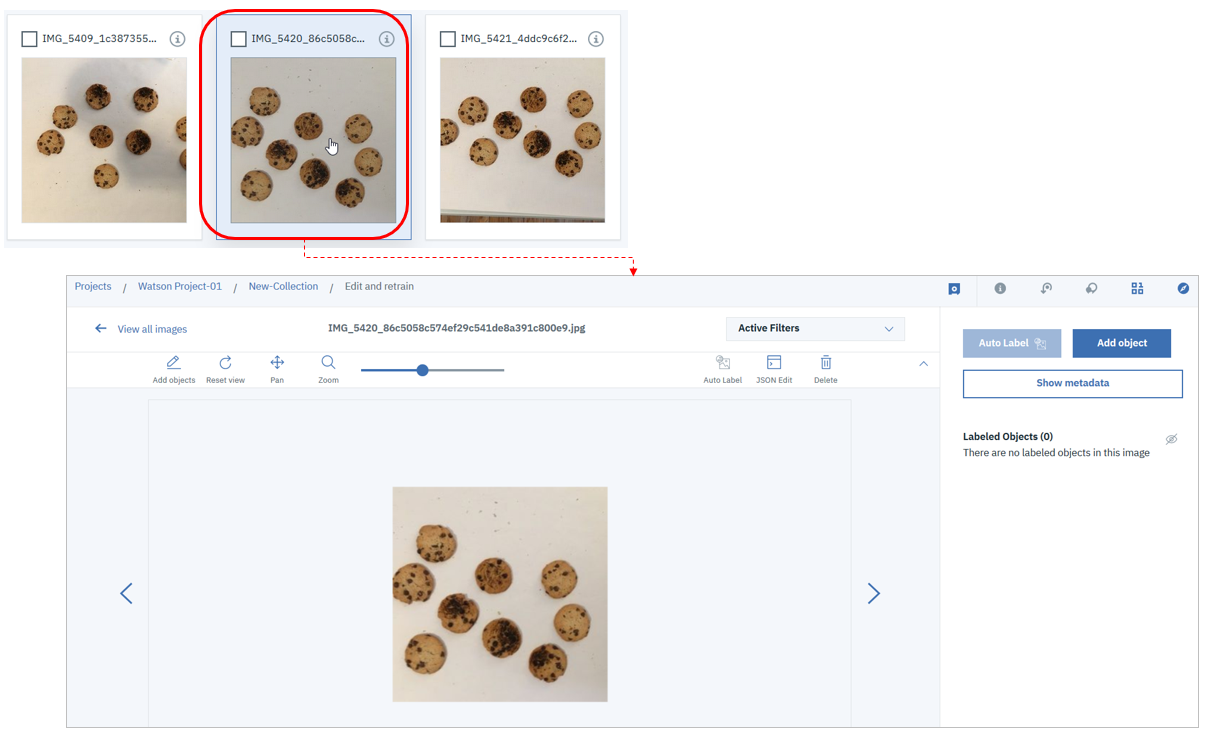
今回はきちんと焼けたクッキーと焦げてしまったクッキーを識別したいので、両方が写っているイメージを適当に選んでダブルクリップします。するとラベル付けのツールが起動します。このツールを使って、1枚のイメージ上に「このクッキーはOKだよ」(OKというラベルを付ける)、「こっちのクッキー焦げているのでNGだよ」(NGというラベルを付ける)とラベル付けを行います。
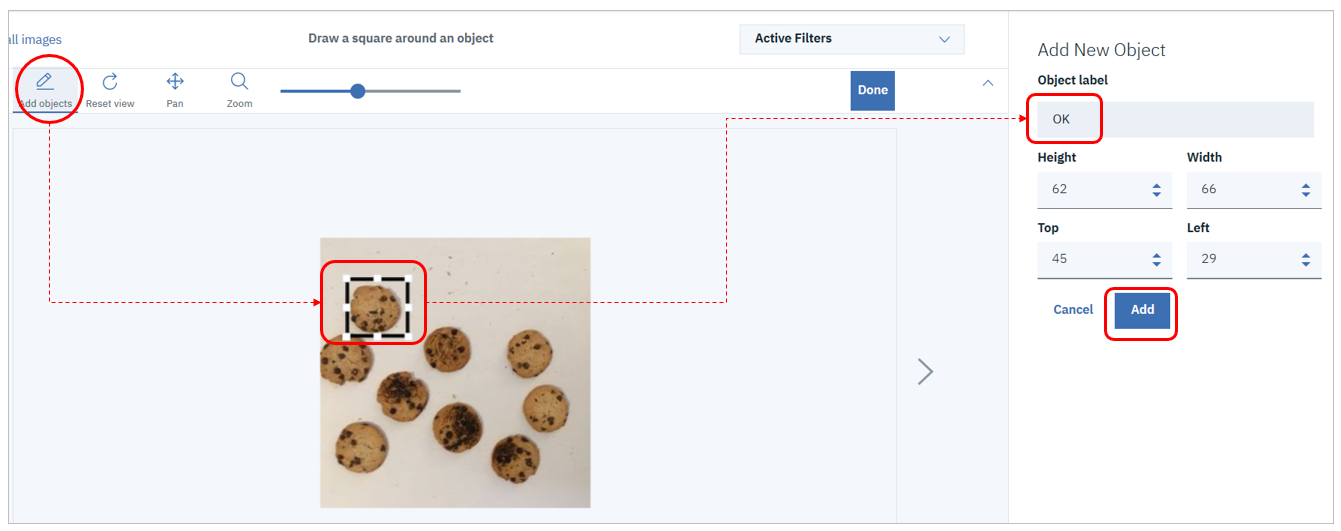
実際の操作としては左上の「Add Objects」ボタンを押すとカーソルが範囲を選択できるようになるので、うまく焼けたクッキーを四角の範囲で選択して、ラベルとして「OK」と入力のうえ「Add」します。(ラベルは分類の際のカテゴリー値になるだけなので、なんでもいいです)1枚のイメージ上の焦げたクッキーの場合も同様に範囲を選択して「NG」というラベルを付けます。この作業を1枚のイメージ上で繰り返していきます。なお、ラベル付けは1枚のイメージ上の全オブジェクトに行わなくても大丈夫です。
言葉では伝わりずらいのでアニメーションにしました。こんな感じ、です。(高速再生)

このような感じであと数枚~数十枚のラベル付けを行います。(左右の<>ボタンで次のイメージに移動できます)
(オプション) 自動ラベリング
1枚のイメージには上記のような感じでラベル付けを行っておきますが、イメージが何百・何千もあったら、死んでしまいますよね。。。その辺を楽にすると共に、教師データの数を増やして精度も上げるために、自動ラベリングの機能が付いています。

上のように一部のイメージだけトレーニングした段階で「Auto Label」ボタンを押せば、ツールはその場で一時なモデルを作り、そのモデルで別のイメージを判定した結果を表示してくれます。ユーザーはいちいちオブジェクトを囲ってラベルを付けて、という操作ではなく、単に「結果があっているかどうか」を確認すればいい(または間違っているならラベルを選びなおす)だけで済みます。
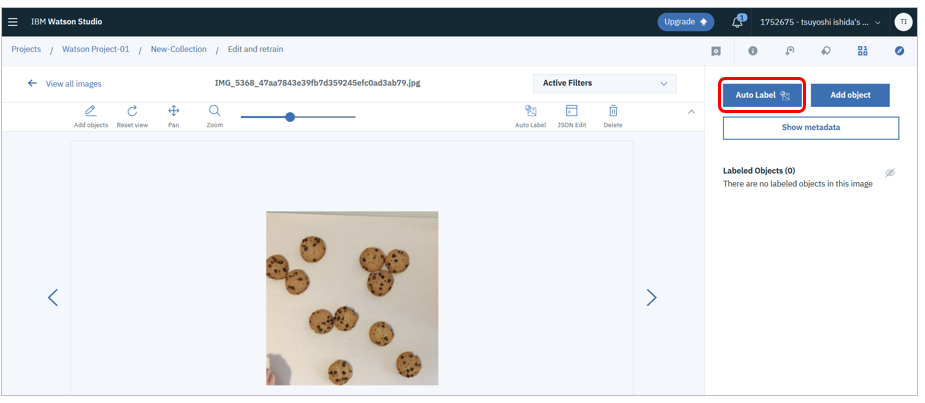
具体的には、新しいイメージを表示した後にAuto Label」ボタンを押すと
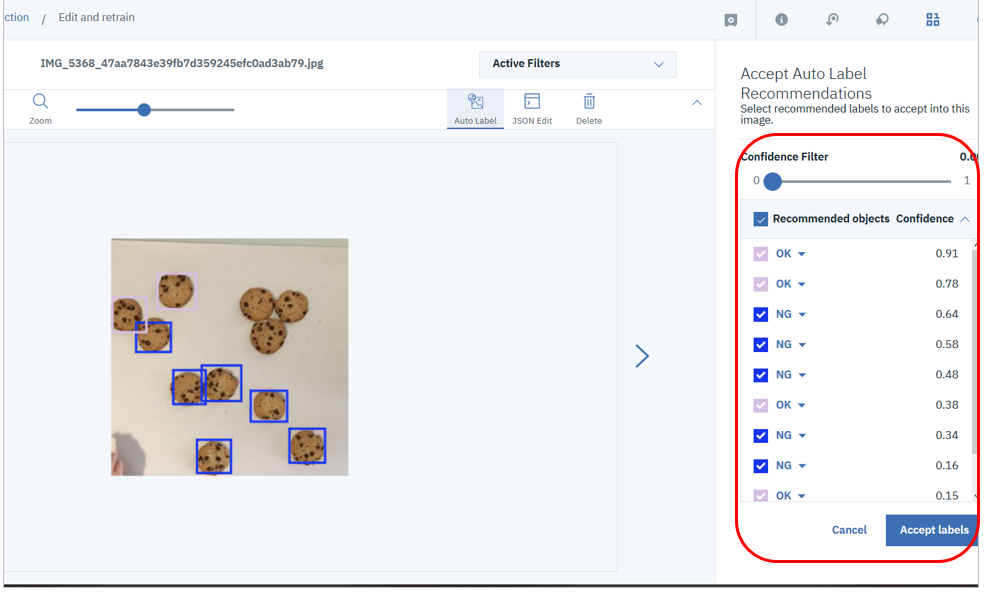
そのイメージからラベルを検出してくれるので、受け入れるなり直すなりして「Accept Labels」ボタンで確定します。(1枚のイメージから複数のラベルを検出しますが、特定のラベルをクリックすれば、イメージ上のどこの枠に該当するか、をビジュアルに表示してくれます) 1
なお、以下(ドキュメントには書いてないので)非公式/ご参考までのお話。一般にディープラーニング(CNN)を使ったイメージの判定では、モデルの精度を上げるために1枚のイメージから様々なバリエーション2のイメージを生成してトレーニングに利用します。CODでも内部的にmirror flipping/hue/saturation/brightness/contrast and scale expansionなどの手法でイメージのバリエーションを生成してトレーニング・データを補強して、精度を上げる工夫を入れているそうです。
 Liteプランでラべル付けを実行しているとこんなのメッセージが出るかもしれません。
Liteプランでラべル付けを実行しているとこんなのメッセージが出るかもしれません。
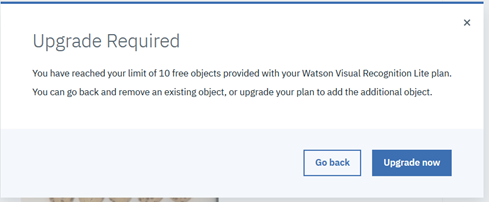
Upgrade Required
You have reached your limit of 10 free objects provided with your Watson Visual Recognition Lite plan.You can go back and remove an existing object, or upgrade your plan to add the additional object.
これは「一枚のイメージでのオブジェクトの検知は10個までだよ」ってことです。よってラベル付けするオブジェクトを減らして、1枚のイメージでの検出数を10個以内にすれば先に進めます。(「全体で10個しかダメなの?!」と思い、焦りました)もちろん、おススメに従ってUpgradeするのでもオーケーです。
モデル作成(トレーニング)
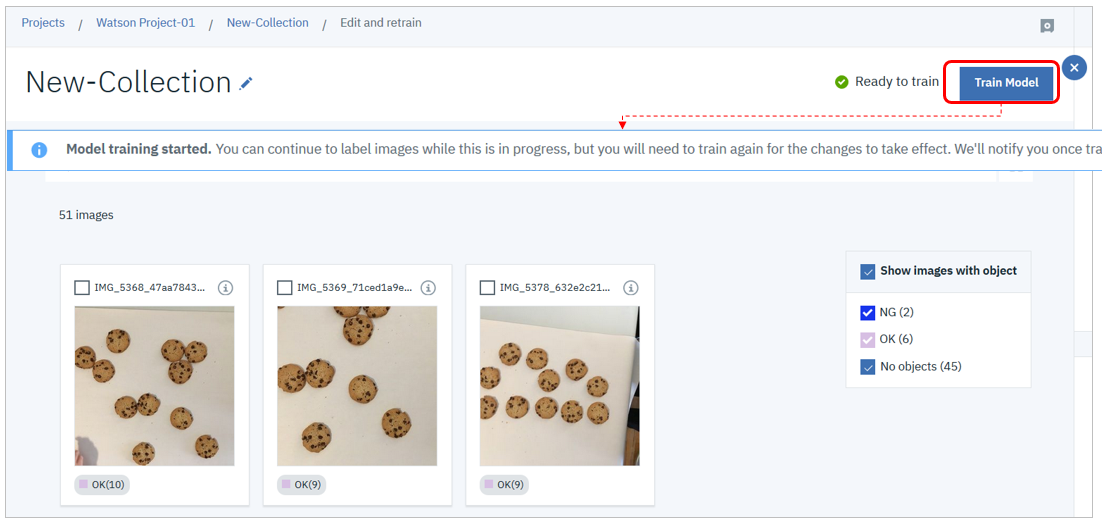
ある程度の枚数をラべル付けすると「Ready to Train」が選べるようになるので、実行します。トレーニングは時間がかかるので非同期実行になります。終わるまで別の作業ができますので、しばしお待ちください。(このクッキーのサンプルデータを使った場合は5-10分位です)
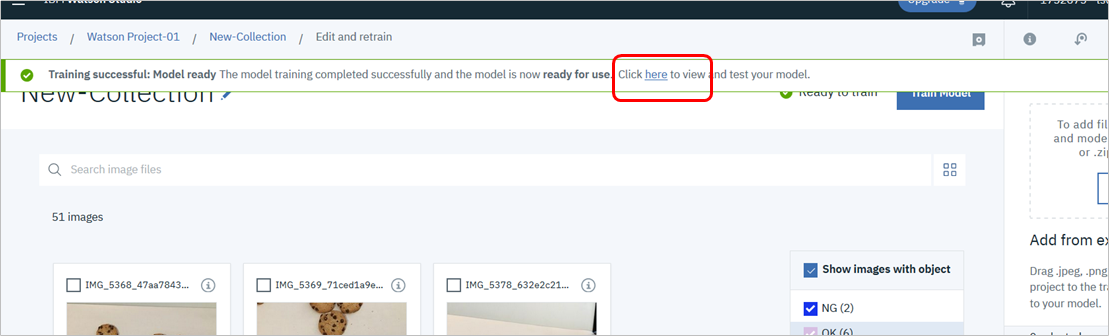
終わったらメッセージのhereをクリックしてテスト・パネルに遷移します。
テスト
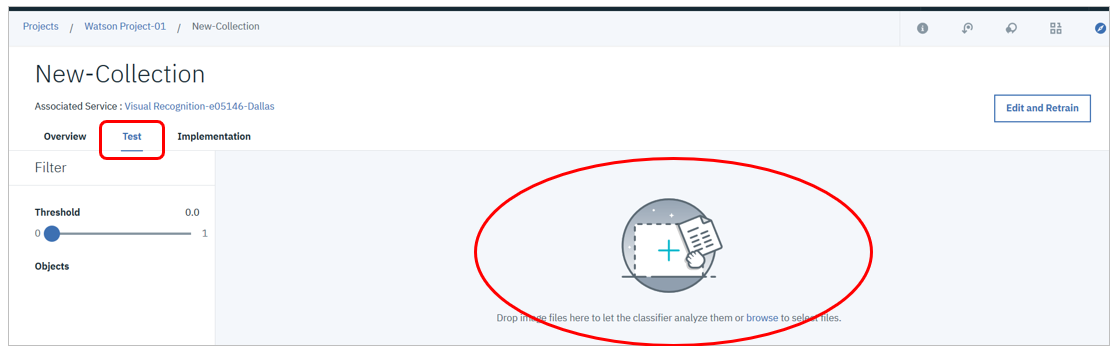
冒頭でダウンロードしたTest.zipを解凍し、「Test」のタブを選んでから*.jpgを適当な個数分、アップロード(またはドラッグ&ドロップ)します。
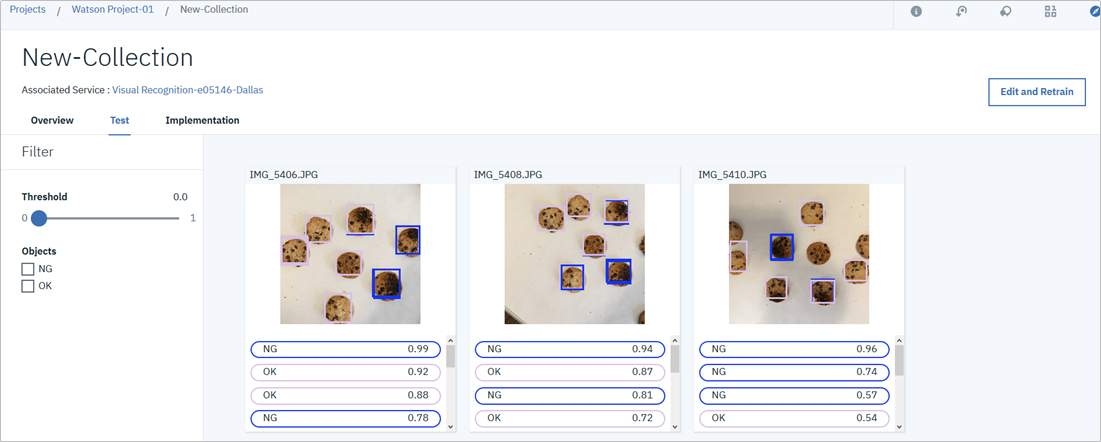
このようにイメージ中の物体(今はうまく焼けたクッキーと焦げてしまったクッキー)が検出されていますね?
APIで呼び出してみる
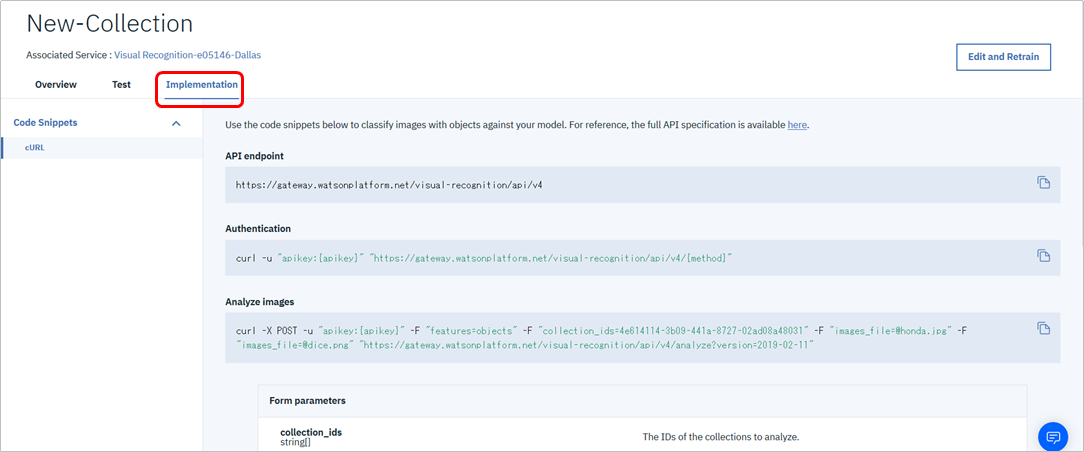
トレーニングが終われば、すでにVR CODのモデルは本番としてインターネットに公開されています。オブジェクト検出を行うならAPIをたたけばいいだけで、そのための情報は「Implementation」タブにあります。
C:\Temp\Test>curl -X POST -u "apikey:HjGSYFwe-KAy6BzyTnrZHD0DzfGM1T2H7URVSvt6PXfN" -F "features=objects" -F "collection_ids=4e614114-3b09-441a-8727-02ad08a48031" -F "images_file=@IMG_5600.JPG" "https://gateway.watsonplatform.net/visual-recognition/api/v4/analyze?version=2019-02-11"
{
"images": [
{
"source": {
"type": "file",
"filename": "IMG_5600.JPG"
},
"dimensions": {
"height": 300,
"width": 300
},
"objects": {
"collections": [
{
"collection_id": "4e614114-3b09-441a-8727-02ad08a48031",
"objects": [
{
"object": "OK",
"location": {
"left": 59,
"top": 27,
"width": 49,
"height": 46
},
"score": 0.5223111
}
]
}
]
}
}
]
}
細かいですが、上記でAPIの戻りが1件なのはデフォルトのthreahholdが0.5以上だからです。下記のように実際は複数のオブジェクトを認識しています。複数のオブジェクトを検知したければ適宜threashholdを指定してください。
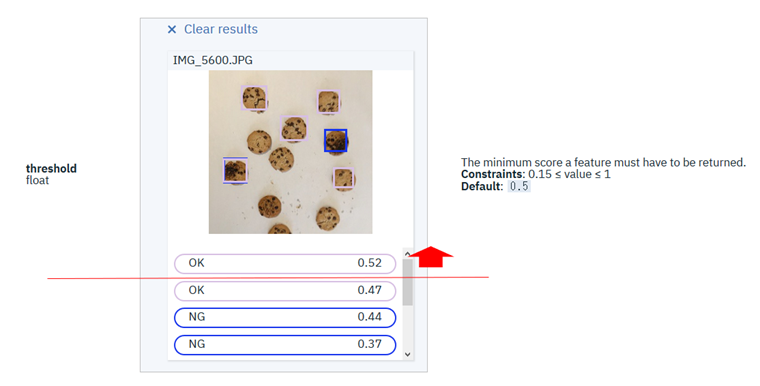
![]() テストではイメージ内の検出オブジェクトは四角い枠に囲まれてラベルと共に表示されていますが、これはVR CODのツールがAPIのレスポンスJSON中のlocationの値を受け取って自分で描画しているものです。VR CODのAPIがイメージ中の検出オブジェクトを枠で囲った形のイメージを生成して返してくれるわけではありませんので、お間違え無きよう。
テストではイメージ内の検出オブジェクトは四角い枠に囲まれてラベルと共に表示されていますが、これはVR CODのツールがAPIのレスポンスJSON中のlocationの値を受け取って自分で描画しているものです。VR CODのAPIがイメージ中の検出オブジェクトを枠で囲った形のイメージを生成して返してくれるわけではありませんので、お間違え無きよう。
ということで、従来、カスタムの物体判別は自分で画像を何千枚も集めたり、CNNのモデルを長時間かけてトレーニング、チューニングしたり、とかなりの時間と手間がかかるものでしたが、Visual Recognitionのカスタム物体検出を使うとすごく簡単にカスタムの物体検出ができます。Liteプランで使えますので、一度遊んでみて下さいませ! 以上です。