Computer VisionのフレームワークやAPIについて調べる機会があり、ここではgluoncvについて調べたことをまとめます。
Computer Visionのフレームワーク、API一覧
下二つは物体検出を簡単に行えるものとして紹介されている記事をいくつか目にしていたのですが、gluoncvはQiitaの記事にはなさそうということで簡単に調査。(2019/01/20時点)
gluoncv
Gluonが公開してるconputer visionのツールキット
提供されている機能は以下
- 画像認識
- 物体検出
- セマンティックセグメンテーション
- インスタンスセグメンテーション
- Re-ID
- GAN
開発中の機能
- Keypointdetection
- Depthprediction
セマンティックセグメンテーションとインスタンスセグメンテーションの違いを知らなかった。
セマンティックセグメンテーション:物体の位置をセル単位で検出
インスタンスセグメンテーション:一つ一つの物体の位置をセル単位で検出
・・・まだ理解不足感満載
Gluonのサポートフレームワーク
機械学習のフレームワークMXNetを利用
pre-trained modelの精度
精度一覧
modelの精度をCOCOのカテゴリ全80種類に対してそれぞれmAPをグラフ化されていてカテゴリ毎に一番精度の良いモデルが異なっているのが、わかって面白い。
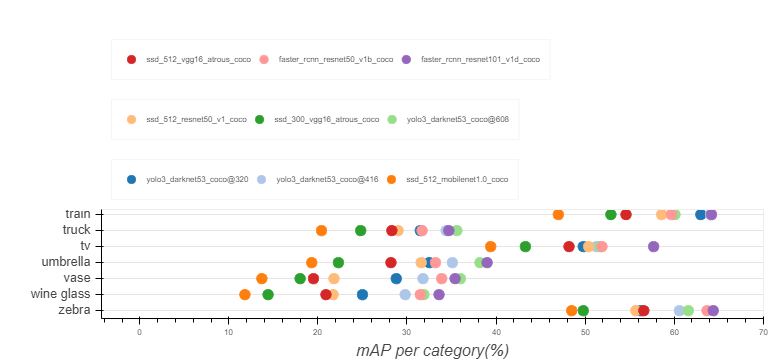
大体、faster_rcnn_resnet101_v1、yolo3_darknet53がmAP上位を占めていますが、その分、検出速度はかなり落ちます。
| pre-trained model | mAP | Throughputs |
|---|---|---|
| faster_rcnn_resnet101_v1d_coco | 40.100 | 4.141 |
| yolo3_darknet53_coco(608x608) | 37 | 43.701 |
| ssd_512_resnet50_v1_voc | 30.500 | 111.132 |
チュートリアル
学習済みモデルのfine tuningの例として記載されていたピカチュウの物体検出がおもしろそうだったので試してみました。finetune_detection
google colabで以下のnotebookを実行
finetune_detection.ipynb
以下を追加、変更
# cudaのバージョン確認
!ls -l /usr/local/cuda
# cudaのバージョンにあわせてmxnetとgluoncvをインストール
!pip install mxnet-cu92
!pip install gluoncv --upgrade
以下のセルはエラーになるのでコメントアウトしてください。
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_custom', classes=classes,
pretrained_base=False, transfer='voc')
直前に実行しているreset_classとgcv.model_zoo.get_modelをまとめて実行する例なので、実行する必要はありません。
githubにissueとして上がっていましたが、2つのissueがまとめて報告されていたので、おそらくスルーされたままcloseされちゃってるようでした。
あとはそのままnotebookを下まで実行するだけで、以下のようにピカチュウを検出した結果が表示されます。
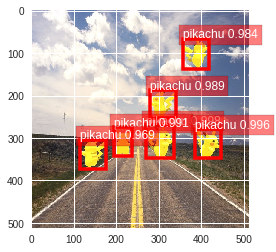
学習した画像は以下(一例)



フリーの3dオブジェクトを適当な背景に重ねて画像を作成してるみたいです。
学習内容は以下
学習データ枚数:900枚
epock:2
google colaboでの学習時間:5分
このくらいで、こんなに検出できちゃうの?!って感じたので、他の画像でもテストしてみました。
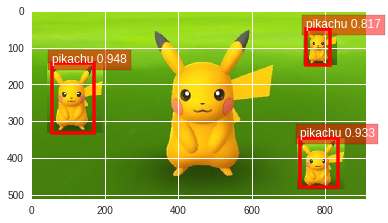
中央の大きいピカチュウだと、検出されなかったので、ピカチュウのサイズを学習データと合わせて貼り付けたところ検出しました。
学習データのピカチュウをランダムにサイズ変更したら中央のピカチュウも検出できそうな気がします。
score(信頼度)で、表示する検出結果を決めてると思うのですが、どこで閾値を変更できるのかなど、まだまだ調べたりないのでもう少し調査したら、また更新するかもです。
参考
https://cdn-ssl-devio-img.classmethod.jp/wp-content/uploads/2018/12/GluonCV.pdf
【無料】4大深層学習フレームワークをGPU版Colaboratoryとlocaltunnelで使い倒そう【簡単】