これはTeX & LaTeX Advent Calendar 2017の11日目の記事です。10日はAcetaminophenさんのTeX Live 2017 注目ポイントまとめでした。12日はtattsanさんの担当です。
初めましてこんにちは、文系初心者でもTeXで美しい縦書きを、という壁に挑戦している者です。ウェブサイトで公開した記事との重複も多いですが、どうぞ一席おつきあいください。
筆者は普段、小説を始めとする散文を組むことを目的としてTeXを使っているので、数式モードや論文向けの体裁は一切使いません。何故InDesignではなくTeXなのかと言えば、ひとえに「プレーンなテキストファイルから高品位なPDFが得られるから」という点に尽きると思っているので、その特性は存分に活用したいです。具体的には執筆時、特定のエディタに依存せず、PCでもスマホでも好きなアプリで書くことができる点や、校正段階に入ってからストーリー自体に直したいところが出てきたとしても、元原稿とレイアウト用の形式を行ったりきたりせずにワンソースを修正するだけで済む点などです。
そしてそういうタイプのフォーマットなら、欲を言えば覚えることが少なくて済むように、マークアップはできるだけ軽量であって欲しいし、その原稿から直感的に仕上がりのイメージを掴めるようなデザインになっていて欲しいです。
そんなわけで大方針として「文中における\は少なければ少ないほどいい」を掲げて、TeXで可能な限りWYSIWYGかつ軽量な文書作りを目指してみます。
Markdown使えや
前提
- 初心者による誰向けかよく分からない記事。
- 横書き、jsarticleクラスを使用。
- ファイルの文字コードはUTF-8。Unicodeにある字は全て直接入力しているものとする。
- タイプセットはupLaTeX+dvipdfmx。
- 数式は書かない。
- 外国語は、出てきてもヨーロッパ諸語まで(ヘブライ語とかタイ語は対象外)。
- 初期設定は以下。
\documentclass[uplatex]{jsarticle}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{textcomp}
\begin{document}
\end{docnment}
エスケープ
数式は書かないと決めてしまったので、エスケープの必要な特殊記号のうちのいくつかが特殊記号でなくせます。\catcode`[char]=[num]コマンドで特殊記号をただの記号扱いにし、そのまま文中に書けるようにしました。
\catcode`\$=12 %数式モードへの移行
\catcode`\&=12 %表のセルの区切り
\catcode`\_=12 %下付きの添字
\catcode`\|=12 %表の縦の罫線
\catcode`\^=12 %上付きの添字
これをプリアンブルの一番下に書きます(もしかしたら\begin{document}の直後の方が安全かも)。
さすがにバックスラッシュと波括弧をただの記号にすることはできませんが、上記の中身は場合によって変わると思います。上付き文字を使いたければ\catcode`\^=12を抜けばいいし、~(チルダ)をそのまま出力したければ一行追加するといいです。
これでURL等がエスケープなしで書けるようになりました。
改行
Markdownとも共通する改行の問題です。知っての通りTeXではソースにおいて、間に空行を挟むと段落が改まり改行されます。段落中での強制改行には、Markdownで半角スペース2つを入れるように、行末に\\をつけます。
散文においてこの方式は全く意図通りではない上、ミスの元です。これを見たままの改行に変えてしまいましょう。以下のマクロを使います。
{\catcode`\^^M=\active%
\gdef\xobeylines{\catcode`\^^M\active \def^^M{\par\leavevmode}}%
\global\def^^M{\par\leavevmode}}
\AtBeginDocument{\xobeylines}
これは元々のTeXのコマンドである\obeylinesを改変したものです。行末の改行文字、この場合はUNIXのデフォルトである^M=LFを全て\parに置き換えることで、毎行ごとに空行を挟んでいるのと同じことになります。1
これで改行がWYSIWYGになる上、空行も入れたら入れた分見たままで出力されます。詳しくはここで解説しています。
インデント
ここは好みが分かれます。筆者は行頭の1字下げもWYSIWYGにしたいんですが、毎行必ず入るインデントは「文」じゃなくて「空間」だろう、と思う方もいらっしゃるでしょう。
そういう場合は行頭で字下げをせず、jsarticleのデフォルトである1字下げに任せます。
WYSIWYGにしたい方は、各行頭で全角スペースによる1字下げを行い、クラスの設定の方を切ります。\parindent = 0ptをプリアンブルに追加してください。
英語以外の欧文
ラテン・アルファベットの言語
各国語の文字やさまざまな記号を直接入力できるのがupLaTeXのいいところですが、英語に含まれないアクセント付きアルファベットは、そのまま書くと予期せぬ出力になってしまいます。
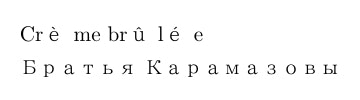
現状ではアクセントつきアルファベットはkcatcode = 15、すなわち「CJK」のカテゴリーに入っているため全角文字になっている上、半角アルファベットとの間に余計な空隙が入っています。\'{e}のようなアクセントコマンドを用いれば欧文として組まれますが、WYSIWYGにということでこのやり方は避けます。
pxcjkcatパッケージで、文字が属するブロックの扱い方を変更してやることで、直接入力からの出力を実現しました。
\usepackage[prefercjkvar]{pxcjkcat}
\cjkcategory{latn1,latnA}{noncjk}
最初の行でまずモード設定しています。4つあるモードのうち現実的に使うのは、英語・ギリシャ語・キリル文字が欧文扱いになるprefercjkvarか、最低限のCJK文字のみ和文扱いであとは全部欧文扱いのprefernoncjkになるかと思います。
後者を指定すれば広い範囲を欧文扱いできますが、日本語を主とする文章を書いている時は、前者の方が何かとエラーになりにくいです。基本的に、いわゆる全角の“リッチな”記号の入ったブロックは欧文扱いにしても出力できません。個人的にはprefercjkvarを指定した上で、欧文扱いにしたいブロックを2行目で追加していく方式をおすすめします。
ブロックが属するカテゴリーは以下の5つです。
- noncjk (15): 欧文扱い
- kanji [または han] (16): 漢字扱い
- kana (17): 仮名扱い
- cjk (18): 「その他の和文」扱い
- hangul (19): ハングル扱い
ここでは英希露に加えてUnicodeのLatin-1 SupplementとLatin Extended-Aをnoncjkで欧文扱いにしています。Latin Extended-Bあたりまででほとんどのヨーロッパ語はカバーできると思いますが、欧文扱いの範囲をさらに広げることもできます。詳しくはpxcjkcatのREADMEを参照してください。
ロシア語とギリシャ語
残念ながら、キリル文字とギリシャ文字は扱いを変更しても、コマンドを全く使わずにベタ書きすることはできません。以下のように_欧文としての_出力用エンコーディングLGR, T2Aを追加して、Babelの命令で囲ってやるか局所的にエンコーディングを切り替えるかしてやる必要があります。
\usepackage[LGR,T2A,T1]{fontenc} %LGRがギリシャ、T2Aがキリル
\usepackage[greek,russian,english,japanese]{babel}
%%%%%%%%%%%%%%%%%%%%%%%
caféにおいて、\foreignlanguage{greek}{Ἀριστοτέλης}はこう言った
︙
\fontencoding{LGR}\selectfont %ギリシャ語が固まっているところは局所的に切り替える
Πλάτωνの``Πολιτεία''中のἬρの神話では、
\fontencoding{T1}\selectfont %元に戻す

コマンドを短く
ベタ書きで書く“普通の”テキストはかなりWYSIWYGにできました。あとは太字(強調)や見出しや引用など、いかなる形式においても意味的にマークアップが必要な部分です。ここでは文中のコマンドをなるたけ減らすという観点から、マクロによって一種のエイリアス、短縮形を設定してみることにしました。
(※LaTeXマクロについては「完全攻略! LaTeX のマクロ定義」で学習・復習してください)
(※TeXレベルのマクロも、ここでは\def\名前{中身}という、LaTeXレベルと変わらない単純なものしか使いません)
ここで登場するのは**newunicodechar**パッケージです。
これは\newunicodechar{<文字>}{<展開する中身>}のように記述することで、Unicodeの任意の1文字をあたかも\newcommand{\<名前>}{<中身>}の形で設定するLaTeXマクロであるかのように扱えるという、筆者からすると夢のようなパッケージです。
実演
実際にやってみました。強調のためのコマンド\emph{}を例に取ります。
newunicodecharは和文扱いの文字は命令化できません。なので先ほどやった、pxcjkcatによって欧文扱いになっているブロックから記号を選びます。
今はASCII文字に加え、主要なウムラウト・アクセント文字と若干の記号を含むLatin-1 Supplementと、よりマイナーなアクセント文字のLatin Extended-Aが欧文です。ここでは¡:U+00A1のINVERTED EXCLAMATION MARKを選びました(スペイン語を使わないという前提)。
これを使ってnewunicodecharで定義して、次のように書けるようにしました。
\usepackage{newunicodechar}
\newunicodechar{¡}{\emph}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
聖堂にある古代ローマの地下室に据えられた祭壇に¡{山羊の印}が発見されたからか、オート=ヴィエンヌの¡{黒の男}がかの¡{三語}を口走ったからかを詰問していた。
もちろんこれを読みやすいと思うかどうかは人それぞれです。シンタックスハイライトが効かなくなるのでその分見にくくなりますし、アルファベットのコマンドの方が本文と分けられていいという方もいるでしょう。
ただ筆者は記号やアルファベットが少なければ少ないほど嬉しいタチなので、これで大分書きやすくなったと思っています。
(ちなみに多分頑張れば波括弧の量を減らしたり、記号で挟んでなんちゃってMarkdown的なことができたりするんだと思います。筆者がTeX初心者のため、原始的な置き換えに留まっています。)
記号に幅を
Latin-1 Supplementだけではすぐに記号が底を尽きます。“自分が絶対に本文で使わないであろう記号”のブロックを欧文扱いにしてやることで、マクロに使える記号の量が増えます。なるたけ意味を連想しやすい記号がいいですね。
例として箇条書きまわりを軽量化してみます。シンタックスは\begin{<itemize/enumerate/descriptionのどれか>}~\end{<どれか>}で環境を作り、各項目の頭に\itemをつけるんでした。
itemはただ置き換えればいいだけなので簡単ですね。
(と言いつつGeneral Punctuationの壁にぶつかりました。本当はビュレット•を使いたかったんですが、これは三点リーダや米印といった、和文扱いでないと困る記号がたくさん属している「General Punctuation」ブロック(sym04)に入っています。なので欧文扱いは諦めざるを得ませんでした。General Punctuationしねばいいのに)
気を取り直して、本文にうっかり出てくるリスクが低そうな「Miscellaneous Symbols and Arrows」(sym26)を欧文扱いにします。そこからアスタリスクに似たU+2B51 BLACK SMALL STAR ⭑を選び、Markdown風のリスト表記にしてみました。
\cjkcategory{latn1,latnA,sym26}{noncjk}
\newunicodechar{⭑}{\item}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\begin{itemize} %改行マクロの副作用で改行文字のコメントアウト必須です
⭑ りんご%
⭑ みかん%
⭑ バナナ%
\end{itemize}
\begin{}~\end{}はどうでしょう。
よく使う環境名=リストタイプも、列挙することで無理矢理短縮しました。それからLatin-1 Supplementにある«ギュメ»はもともとフランス語の引用符なので、これにquote環境を振ってみています。
\cjkcategory{latn1,latnA,sym26,sym15}{noncjk} %Enclosed Alphanumericsを追加
\newunicodechar{⬎}{\begin}
\newunicodechar{⬏}{\end}
\newunicodechar{⭑}{\item}
\newunicodechar{⒤}{itemize}
\newunicodechar{⑴}{enumerate}
\newunicodechar{⒟}{description}
\newunicodechar{Ⓠ}{quotation}
\newunicodechar{«}{\begin{quote}}
\newunicodechar{»}{\end{quote}}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
⬎{document}
ここは字下げしています
⬎{⒟}%
⭑[主食] バナナ%
⭑[おやつ] バナナ%
⭑[デザート] バナナ%
⬏{⒟}%
«マレー語において“pspang zapra”とは、「バナナ一本を食べる所要時間」を表す語です。»
ここは字下げしていません
⬏{document}

ここまで来るといたずらにややこしくしているだけのような気がしてきました。ほどほどにしておいた方がよさそうです。
いっそ日本語で
そもそもnewunicodecharで定義する字は、当然ながら普通の文中には出てこない文字である必要があります。つまり書きにくいということで、使っている辞書で最初から変換できればラッキーですがそうでなければ辞書登録しなければなりません。筆者もここまでに相当なコピペと辞書登録を繰り返しています。
これまでの前提を覆すようですが、分かりやすいマークアップということなら、\newcommandで普通にバックスラッシュつきの日本語のマクロを定義するのもいいんじゃないかと思います。
日本語マクロには字数制限はありません。青空文庫記法のように、日本語や全角文字を用いるシンタックスに慣れている方は、こちらのほうが直感的にWYSIWYGっぽく感じられるかもしれません。
\newcommand{\表題}{\title}
\newcommand{\大見出し}{\section}
\newcommand{\中見出し}{\subsection}
\newcommand{\小見出し}{\subsubsection}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\表題{江戸川乱歩短編集}
\大見出し{二銭銅貨}
\中見出し{上}
「あの泥坊が羨しい」二人の間にこんな言葉が交される程、其頃は窮迫していた。
おわりに
いかがでしたでしょうか?後半は筆者の力不足故にWYSIWYGというよりただのオレオレ記法みたいになりましたが、newunicodecharはもっと素晴らしいパッケージです(参考リンク中の一番最後の、ZRさんのgistなんか凄いぞ)。
ここからもっと自然で妥当なLaTeXプリプロセッサなんかが出てきたりしたらいいなあと夢見ています。
Pandoc使えや
主要参考文献
- [改訂第6版]LaTeX2ε美文書作成入門
- TEX in Practice: Volume III: Tokens, Macros
- pTeXで縦書きモード時にハイパーリンクを埋め込む方法のメモ - 方向
- 2.11.1 obeylines
- upLaTeX でアクセント付きのラテン文字などがうまく出力されないときの対処法|Colorless Green Ideas
- TeX/upTeX/Manual - 松浦高志のWikiページ
- 単独の Unicode 文字を命令として扱う(newunicodechar パッケージ) - マクロツイーター
- LaTeX: 和文を欧文扱いして和文扱いする件
-
CR+LFであるWindowsでは改行コードを変更しなくても動きましたが、CRしかないMacではどうなるか未検証です。 ↩