@drillerさんが書いていたQuantopianのチュートリアル記事を参考にしてQuantopianを始めようとしたが、チュートリアル2以降が(多分需要なくて)ないので、自分の見返しようも兼ねて大雑把にまとめて訳してみるとする。
元記事はhttps://www.quantopian.com/tutorials/pipeline
###なぜパイプライン?
アセットアロケーションを効率的に行うためのAPIがパイプライン。研究と構築がIDEと同じ環境で機能する。
###計算
パイプラインで表現できる計算は3タイプある。
Factors:数値による関数。資産に価値を割り当てるために使われる。例えば10日間の平均取引量など。
Filters:ブール値による関数。投資対象をアセットに含めるか外すかを決めるのに使う。
Classifiers:カテゴリのアウトプットで、文字列やintを生成する。Factorsによる結果を受けてアセットをグループ化するのに使う。たとえばどのアセットが取引されているかの分類など。
###Dataset
パイプライン計算は価格、ボリュームデータ、基本データ、パートナーデータを使用して実行する。このチュートリアルでは10日間の平均価格と30日間の平均価格の間に大きな変化がある流動性のある証券を選択するパイプラインを構築する。
###パイプラインの作成
pipelineクラスをインポートし、関数を定義する。今のところは空のパイプラインを返す。make_pipeline()を実行してインスタンス化する。
from quantopian.pipeline import Pipeline
def make_pipeline():
return Pipeline()
my_pipe = make_pipeline()
###パイプラインの実行
my_pipeを実行してみる。その前に特定期間にパイプラインを実行するrun_pipelineをインポートする。
from quantopian.research import run_pipeline
run_pipeline()を実行してみる。第2引数がシミュレーション開始日、第3が終了日。
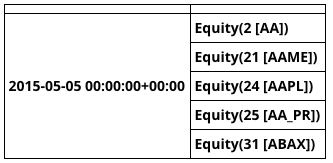
result = run_pipeline(my_pipe, '2015-05-05', '2015-05-05')
run_pipelineを呼び出すとdataと有価証券でインデックスされたpandas Dataframeが返される。空のパイプラインがどのように見えるかは以下の通り。
result.head()
###所感
pipelineの実行はアルゴリズムからではなくNotebookから行う。
ここまで見る限り、pipelineは割と証券のスクリーニングにめちゃめちゃ便利そう。自分の考えたロジックをpipelineを使ってスクリーニングし、アルゴリズムでバックテストするのが容易にできそうなので、エビデンスに基づく投資が実践できそうである。(そうでなくてもテクニカル分析を用いてスクリーニングしてバックテストするのも面白そう)