最近、Embedding周りの進歩が著しい。
導入
※ 本シリーズの一覧はこちら。
BAAI(Beijing Academy of Artificial Intelligence)から、BGE-M3というEmbedding用のモデルが公開されました。
上記サイトの一部を邦訳すると、
本プロジェクトでは、多機能・多言語・多粒性において汎用性に優れたBGE-M3について紹介します。
- 多機能性:埋め込みモデルの3つの一般的な検索機能(密検索、マルチベクトル検索、疎検索)を同時に実行できます。
- 多言語対応:100以上の作業言語をサポートできます。
- 多粒性: 短い文から最大 8192 トークンの長いドキュメントまで、さまざまな粒度の入力を処理できます。
という特性を持ったモデルとなります。
単一の埋め込み手段(Dense Vector)だけでなく、Sparse VectorやColBERTのようなMulti-Vectorもこのモデル単体で得られるという、もはやどういう仕組なのかよくわからない。(論文読めばわかるのでしょうが、まだ未読)
日本語含めた多言語に対応しており、一部のベンチマークでは界隈でよく使われるmultilingual-e5-largeを越える性能を発揮しています。
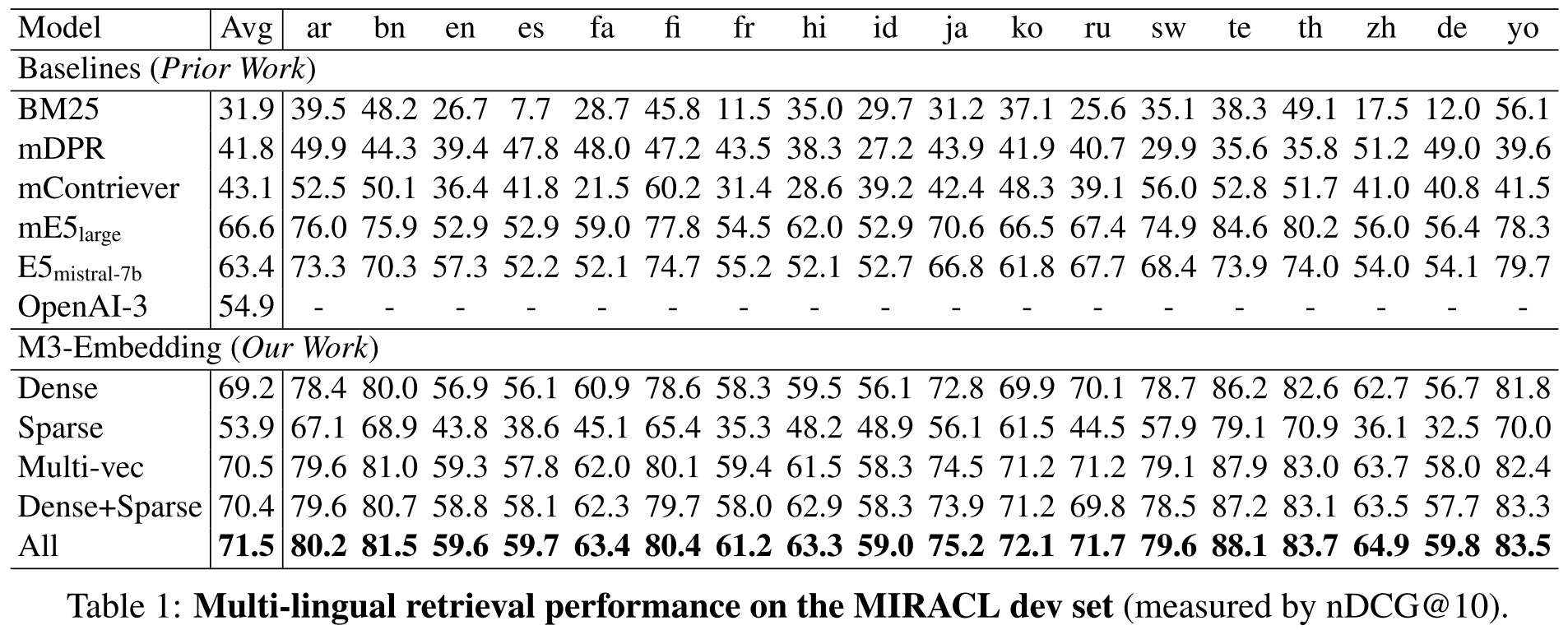
また、oshizo氏のJapaneseEmbeddingEvalでも非常に高い性能を示しています。
もしかしたら、日本語RAGにおける新たな埋め込みのスタンダードモデルになるかもしれないなと思い、このモデルを使った検索を試してみました。
検証はDatabricks on AWS、DBRは14.2ML、g4dn.xlargeクラスタで行っています。
LangChainのRetrieverの中で使ってみる
まずは、LangChain上でのベクトルストア埋め込みモデルとして使ってみます。
Step0. パッケージインストール
必要なパッケージをインストール。ベクトルストアにはFAISSを利用します。
%pip install -U -qq transformers accelerate langchain faiss-gpu sentence_transformers tqdm
dbutils.library.restartPython()
Step1. テキストデータの準備
検索対象のテキストデータを準備します。
こちらのWikipediaからデータをお借りします。
(この記事の流用なので、コード内のUser-AgentがRAGatouilleになっていますが、無視してください)
import requests
def get_wikipedia_page(title: str):
"""
Retrieve the full text content of a Wikipedia page.
:param title: str - Title of the Wikipedia page.
:return: str - Full text content of the page as raw string.
"""
# Wikipedia API endpoint
URL = "https://ja.wikipedia.org/w/api.php"
# Parameters for the API request
params = {
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
}
# Custom User-Agent header to comply with Wikipedia's best practices
headers = {"User-Agent": "RAGatouille_tutorial/0.0.1"}
response = requests.get(URL, params=params, headers=headers)
data = response.json()
# Extracting page content
page = next(iter(data["query"]["pages"].values()))
return page["extract"] if "extract" in page else None
# 葬送のフリーレンの内容を取得
full_document = get_wikipedia_page("葬送のフリーレン")
Step2. チャンクデータの作成
単純なテキストスプリッタを作成して、チャンクに分割します。
from typing import Any
from langchain.text_splitter import RecursiveCharacterTextSplitter
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""句読点も句切り文字に含めるようにするためのスプリッタ"""
def __init__(self, **kwargs: Any):
separators = ["\n\n", "\n", "。", "、", " ", ""]
super().__init__(separators=separators, **kwargs)
text_splitter = JapaneseCharacterTextSplitter(chunk_size=512, chunk_overlap=128)
texts = text_splitter.split_text(full_document)
Step3. 埋め込みモデルのロードとベクトルストア作成
BGE-M3をロードします。
LangChainにはHuggingFaceBgeEmbeddingsというBAAIのBGE系埋め込みモデルを利用するための専用クラスた用意されており、そちらを利用します。
import torch
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import FAISS
device = "cuda" if torch.cuda.is_available() else "cpu"
# model_path = "BAAI/bge-m3" # Huggingfaceから取得する場合
model_path = "/Volumes/training/llm/model_snapshots/models--BAAI--bge-m3" # 今回は事前ダウンロードしたものを利用
model_kwargs = {"device": device}
encode_kwargs = {"normalize_embeddings": True} # Cosine Similarity
embedding = HuggingFaceBgeEmbeddings(
model_name=model_path,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
ロードした埋め込みモデルを利用し、FAISSでベクトルストアを作成。
そこから、1件のみ検索結果を取得するRetrieverを取得します。
vectorstore = FAISS.from_texts(texts, embedding)
retriever = vectorstore.as_retriever(search_kwargs={"k":1})
Step4. 検索
作成したRetrieverを使って、クエリに対する関連文書を取得してみます。
retriever.get_relevant_documents("アニメでフリーレンの声優を務めているのは誰?")
[Document(page_content='=== フリーレン一行(主要人物) ===\nフリーレン (Frieren)\n声 - 種﨑敦美\n本作の主人公。魔王を討伐した勇者パーティーの魔法使い。長命なエルフ族の出身で、少女のような外見に反して1000年以上の歳月を生き続けている。人間とは時間の感覚が大きく異なるため、数か月から数年単位の作業をまったく苦にせず、ヒンメルらかつての仲間たちとの再会も50年の月日が経ってからのことだった。ヒンメルが天寿を全うして他界したのを機に、自身にとってはわずか10年足らずの旅の中でヒンメルの人となりを詳しく知ろうともしなかったことを深く後悔し、趣味の魔法収集を兼ねて人間を知るための旅を始める。生前時のヒンメルに対する意識は希薄であったが、幻影鬼(アインザーム)との遭遇時や、奇跡のグラオザーム に「楽園へと導く魔法(アンシレーシエラ)」を使われた際などは幻想の中でヒンメルを思い描くなど、無自覚に意識しているような描写が散見されている。')]
声優名を含む文書が取得できていますね。
もうひとつぐらい聞いてみます。
retriever = vectorstore.as_retriever(search_kwargs={"k":3})
retriever.get_relevant_documents("自分と相手の魂を「服従の天秤」に乗せ、魔力が少ない方を服従させる魔法の名前は何?")
[Document(page_content='魔族の中でも500年以上を生きる長命であり、おのれの魔力に絶対的な自信をもつ。「服従の天秤」という天秤に自身と相手の魔力を乗せて魔力が少ないほうを「服従させる魔法」を扱い、首がない不死の軍勢を手駒としていた。\n不死の軍勢を率いて、自身を倒しに来たフリーレンと対峙。フリーレンの魔力制御による隠蔽を見抜けず侮って天秤を使用するが、偽装を解いたフリーレンと自身との歴然たる魔力差に驚愕し、逆に自身が操られる。最後は自害しろという命令をフリーレンから受け、泣きながらみずから首を斬って死亡する。\nリュグナー\n声 - 諏訪部順一'),
Document(page_content='=== 魔族の魔法 ===\n血を操る魔法(バルテーリエ)\nリュグナーが使用。血に魔力を込めて操っているとみられる。\n血を複数の触腕のように形成して切断や刺突攻撃をする。\n模倣する魔法(エアフアーゼン)\nリーニエが使用。人が動いている時の体内の魔力の流れを記憶し、動きを模倣する。\nシュタルクとの戦闘の際、以前に記憶したアイゼンの動きを模倣して戦った。\n服従させる魔法(アゼリューゼ)\n断頭台のアウラが使用。自分と相手の魂を「服従の天秤」に乗せ、より大きな魔力を持つ者がその相手を永遠に服従させる。\n自分のほうが魔力が少なければ自分が相手に服従することになる諸刃の剣と言える魔法。\n霧を操る魔法(ネベラドーラ)\n神技のレヴォルテの部下の魔族が使用。魔力を込めた霧はわずかな魔力にも反応する性質を持つ。\n攻撃を旋風に変える魔法(メドロジュバルト)\n神技のレヴォルテの部下の魔族が使用。剣撃の射程を拡大するのに使用している。\n万物を黄金に変える魔法(ディーアゴルゼ)\n黄金郷のマハトが使用。北部平原の城壁都市ヴァイゼを住民もろとも一瞬のもとに黄金に変え、術者が封印された現在もその範囲を拡大している。'),
Document(page_content='=== その他の用語 ===\n呪い\n魔物や魔族が使い、人類が未だに解明できていない魔法のこと。人を眠らせたり石にしてしまう。人類の魔法技術では原理も解除方法も不明であるが、唯一僧侶が使う女神様の魔法だけは別で、呪いに対処できる(僧侶自身は女神の加護があるために呪いが効きにくい)。\n女神様の魔法\n聖典に記された魔法。聖典所持者かつ資質がないとうまく扱えず、その原理も呪いと同様分かっていない。\n封魔鉱\n魔法を無効化する力を持った鉱石。その純度により無効化できる範囲が変わる。また、魔力を込めると光る性質があり、込めた魔力が強いほど強く光る。とても希少で小石ほどの大きさでも金貨数枚はくだらない程の価値があるが、最大級の硬度を持つ為に採掘や加工は極めて困難。\n聖雪結晶\n北部高原のシュマール雪原で採掘される鉱物。魔法薬の原料になるが、めったに見つからず、凶暴な魔物がうろつく危険地帯に鉱脈があるため、貴重品として高値で取引されている。フリーレン一行が冒険者の野営地を訪れた際は、鉱脈保護のための魔物退治と対人結界の設置を引き受けた。')]
2件目の文書に、正解を含むものが取得できています。
このRetrieverをRAGのパイプラインに組み込むことで、BGE-M3の埋め込みを使ったRAGを構築することができます。
FlagEmbeddingを使ったハイブリッド検索で使う
LangChainのHuggingFaceBgeEmbeddingsは内部的にsentence_transformersを利用しています。
これはmultilingual-e5といったモデルと同様にテキストからDense Vector(Dense Embedding)を生成していました。
BGE-M3は前述のように、Sparse VectorやMulti Vectorを生成することができ、それぞれの結果を使った類似度計算をハイブリッドに行うこともできます。
(ベンチマークでは、これらのハイブリッド検索を行う方が性能が高い)
そのための計算・検索機能を提供するFlagEmbeddingというパッケージがあるので、こちらを使って検索を行ってみます。
Step0. パッケージインストール&設定
必要なパッケージをインストール。ベクトルストアにはFAISSを利用します。
%pip install -U transformers accelerate FlagEmbedding tqdm
dbutils.library.restartPython()
また、一部の警告メッセージの表示を抑制するために、環境変数を設定しておきます。
import os
# 警告メッセージやtqdmのプログレスバー表示の抑制
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["TQDM_DISABLE"] = "true"
Step1. モデルのロード
FlagEmbeddingを使ってBGE-M3モデルをロードします。
use_fp16パラメータをTrueにすることで、FP16で読み込まれます。
ロード時間が長くなり、精度が若干低下しますが、VRAMの使用量は減少します。
from FlagEmbedding import BGEM3FlagModel
# model_path = "BAAI/bge-m3" # Huggingfaceから取得する場合
model_path = "/Volumes/training/llm/model_snapshots/models--BAAI--bge-m3"
model = BGEM3FlagModel(
model_path,
use_fp16=True,
)
Step2. 検索対象データの準備
前の例と同様に、Wikipediaから取得したデータを検索対象にします。
各種関数・クラスの定義は省略。
texts = text_splitter.split_text(get_wikipedia_page("葬送のフリーレン"))
これで準備が終わりました。実際に埋め込み計算や検索を行ってみましょう。
Step3. 埋め込み計算
FlagEmbeddingのBGEM3FlagModelを使って埋め込み計算をするにはencodeメソッドを呼び出します。
encodeメソッドに渡すパラメータとして、return_XXXというのがありますが、これのON/OFFで計算対象と出力結果が変わります。
今回は全て(Dense/Sparse/Multi-Vecotr)を計算させて結果を取得します。
questions = ["アニメでフリーレンの声優を務めているのは誰?"]
embedding_results = model.encode(
questions,
return_dense=True,
return_sparse=True,
return_colbert_vecs=True,
)
embedding_results
{'dense_vecs': array([[-0.0213 , -0.03345, -0.02501, ..., -0.0413 , -0.04416, -0.00185]],
dtype=float16),
'lexical_weights': [defaultdict(int,
{'82535': 0.1736,
'119415': 0.2023,
'55658': 0.2646,
'164711': 0.1731,
'22880': 0.1149,
'20119': 0.055,
'7826': 0.01072,
'6814': 0.00537,
'24737': 0.05008,
'32': 0.01288})],
'colbert_vecs': [array([[-0.00621396, -0.02997278, -0.03361665, ..., 0.00607441,
0.00466726, -0.01904117],
[ 0.03132125, -0.0207976 , 0.00202447, ..., -0.03096452,
-0.01657922, -0.00983694],
[ 0.00263906, -0.01390883, -0.03344551, ..., 0.00955931,
0.00943067, -0.02744783],
...,
[-0.00762547, -0.0211793 , -0.03424935, ..., -0.00916132,
0.01407602, -0.02154791],
[-0.01637382, -0.02296405, -0.0329668 , ..., 0.0059993 ,
0.02380935, -0.02031857],
[ 0.02402889, 0.01261898, -0.03680696, ..., 0.00374815,
0.02906884, 0.00310384]], dtype=float32)]}
これらの結果を使って、類似度計算するメソッドも公開されています。
以下は、Dense Embeddingの結果を使って類似度計算するサンプルです。
sentence_1 = ["Databricksとはなんですか?"]
sentence_2 = [
"データブリックス(Databricks)は、アメリカのDatabricks, Inc.社が開発したデータ分析プラットフォームです。これにより、大規模なデータセットを効率的に処理し、機械学習モデルを構築し、分析結果を視覚化することが可能です。PythonやScalaなどのプログラミング言語を用いて、データプレインの統合プラットフォーム上で動作します。また、Apache Sparkというオープンソースのエコシステムをベースにしており、高速なデータ処理が可能です。",
"東京の明日の天気は、現在の天気予報情報によって判断されます。それを確認するために、ウェブ上で天気サイトやテレビ番組、新聞記事などから最新の天気予報をチェックしてください。",
]
embeddings_1 = model.encode(sentence_1)
embeddings_2 = model.encode(sentence_2)
similarity = embeddings_1["dense_vecs"] @ embeddings_2["dense_vecs"].T
print(similarity)
[[0.7505 0.2408]]
sentence_1とsentence2の類似度計算した結果が出力されています。
sentence_2は二つの文章が入っており、1点目の類似度が高い(0.75)という計算結果になりました。
Step4. ハイブリッド検索
では、Dense/Sparse/Multi-Vectorの埋め込み計算結果全てを使ってハイブリッド検索を行ってみます。
検索対象はStep2.で読み込んだWikipediaデータです。
questions = ["自分と相手の魂を「服従の天秤」に乗せ、魔力が少ない方を服従させる魔法の名前は何?"]
sentence_pairs = [[i, j] for i in questions for j in texts]
result = model.compute_score(
sentence_pairs,
max_passage_length=128, # a smaller max length leads to a lower latency
weights_for_different_modes=[
0.4,
0.2,
0.4,
], # weights_for_different_modes(w) is used to do weighted sum: w[0]*dense_score + w[1]*sparse_score + w[2]*colbert_score
)
結果をPandas DataFrameにして確認。
import pandas as pd
pd.DataFrame(result)
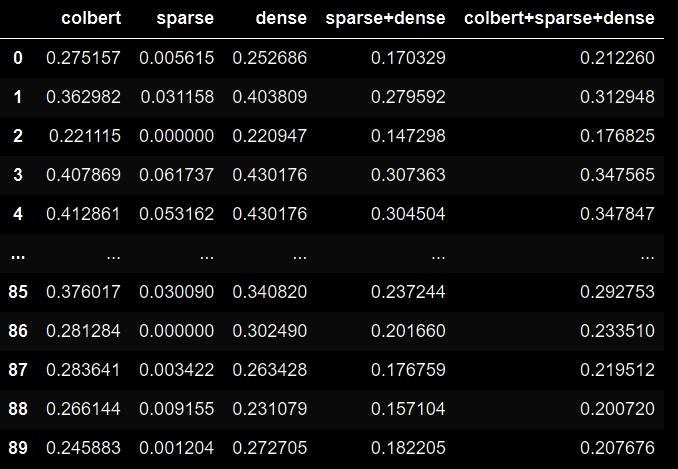
このように、Dense/Sparse/Multi-Vector(ColBERT)ごとの類似度計算、および組み合わせでの類似度計算結果を取得することができます。
組み合わせでの類似度計算はcompute_socreメソッドのweights_for_different_modesパラメータで重みを設定できます。
では、colbert+sparse+denseの全組み合わせを使って最も類似度が大きかったチャンクを表示してみます。
pdf = pd.DataFrame(sentence_pairs, columns=["question", "similar_doc"])
pdf["score"] = result["colbert+sparse+dense"]
display(pdf.sort_values(by="score", ascending=False).head(2))
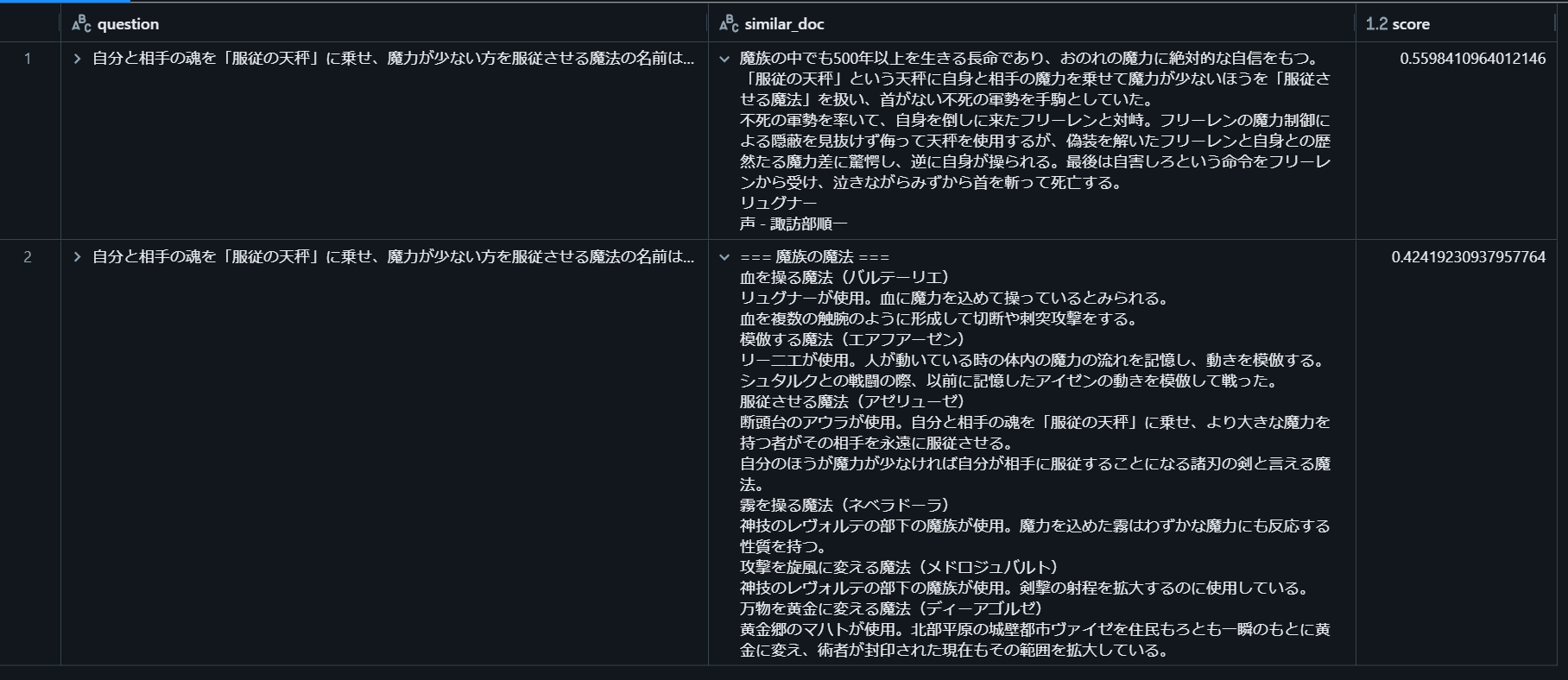
2件目に正解が含まれていました。
まとめ
BGE-M3を使った埋め込み・検索を試してみました。
OpenAI社も最近新たな埋め込みモデルAPIを公開しましたが、ローカル(オープン)LLMの世界でも優秀なモデルが公開されており、非常に面白いです。
RAGの性能を高める上で埋め込みに関する工夫は重要であり、今後もこういった高性能なモデルが公開されていくと(素人的に使う側にとっては)ありがたいですね。