初学者がやるコンペ記録の第2回です。参加しているコンペはこちら。
前回の内容はこちら。
今の状況&所感
- 暫定評価0.97以上。前回からスコアは上がっているが、まだまだ試行錯誤中。
- 終盤に入ってきていますが、やり切れてないことも多く、どこまでやるか迷ってます。
- 慣れてくると、だいたいやること定まって迷いとか減るんだろうなあ。
一日の投稿が50回ぐらいできればいいのに
前回から追加で行っていること
縛りも含めて、基本的なやり方はあまり変わっていませんので、個人的にインパクトがあった点だけつらつらと書きます。
続・特徴量エンジニアリング
ずっとやってますが、2/10に開催された中間イベントの資料は参考になりました。
私は都合が合わなくて参加できなかったのですが、Slack見ていると盛り上がっていたみたいですね。参加したかった。。。
特に、金融ドメイン知識が皆無だったので、ドメインから考えるモデル精度向上Tipsの資料は非常にありがたかったです。
まだ見られてない方はSlackに掲載されている資料のチェックをお勧めします。
データバランスの調整
不均衡データの調整の仕方や、トレーニングデータの総量を調整しています。
今のところスコアが著しく変わるわけではないのですが、ちまちま試行錯誤しています。
アンサンブル工程の追加
書籍「Kaggleで勝つデータ分析の技術」の第7章にもあるアンサンブルも実施しています。
もともとコンペ後半にやろうとは考えていましたが、思ったよりスコアに大きく影響を与えたので、ちょっと掘り下げて書いてみます。
ただ、私自身アンサンブルをこのような形でやるのは初めてなので、間違ったことを書いてるかもしれません。注意。
アンサンブルとは?
複数のモデルを組み合わせてモデルを作ること、もしくは予測を行うことをアンサンブルといいます。
Kaggleで勝つデータ分析の技術より
複数モデルの予測結果に対して平均をとるようなシンプルなアンサンブルから、スタッキングと呼ばれるモデルの予測値からさらにモデルを作る方法などがあります。
Qiitaの中でも「アンサンブル」で検索すると大量にお役立ち記事がでてくるので、取り入れてみたい方はそちらを確認されるのがよいかと思います。
今回のコンペで、(加重)平均を取るのがよいのか、スタッキングまで踏み込む方がいいのかは各自の状態によって異なる気はします。
また、評価スコアがROC AUCという特性上、予測値(確率)の平均値ではなく、確率を順位に変換して平均を取る方法も有効かと思います。
MLflowにおけるアンサンブルのためのモデル管理
今回の私のやり方だと、AutoMLで大量にモデルを作ってくれるので、アンサンブルを行うためのモデルには事欠きません。
また、MLflow上にモデルはすべて記録されているので、過去に作った高スコアモデルの活用も簡単に行えました。
簡単にMLflowでどうやってアンサンブル対象のモデルを管理しているか私がやっている内容を紹介したいと思います。
私の自己流なので、これがベストなやり方かどうかはわかりません。
参考程度に認識ください。
1. 作ったモデルをモデルレジストリに登録する
スコアがいいなど、アンサンブル対象にしたいモデルをエクスペリメント等から確認し、画面右下のペインから、Register Modelボタンを押すと、モデルレジストリにモデルを登録することができます。
アンサンブル対象候補のモデルをこの操作でどんどんモデルレジストリに登録してください。
このとき、同一モデル名の別バージョンとして登録します。
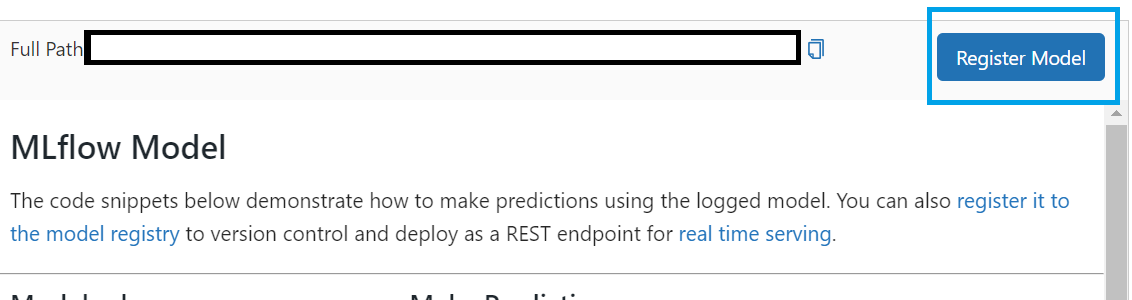
モデルレジストリって何?っていう方は以下参照ください。
2. モデルレジストリ内のモデルにタグを付ける
「モデル」メニューからモデルレジストリのUIを開き、自分が作成したモデルの画面を開きます。
各バージョンごとにモデルがリストアップされているのを確認できると思います。
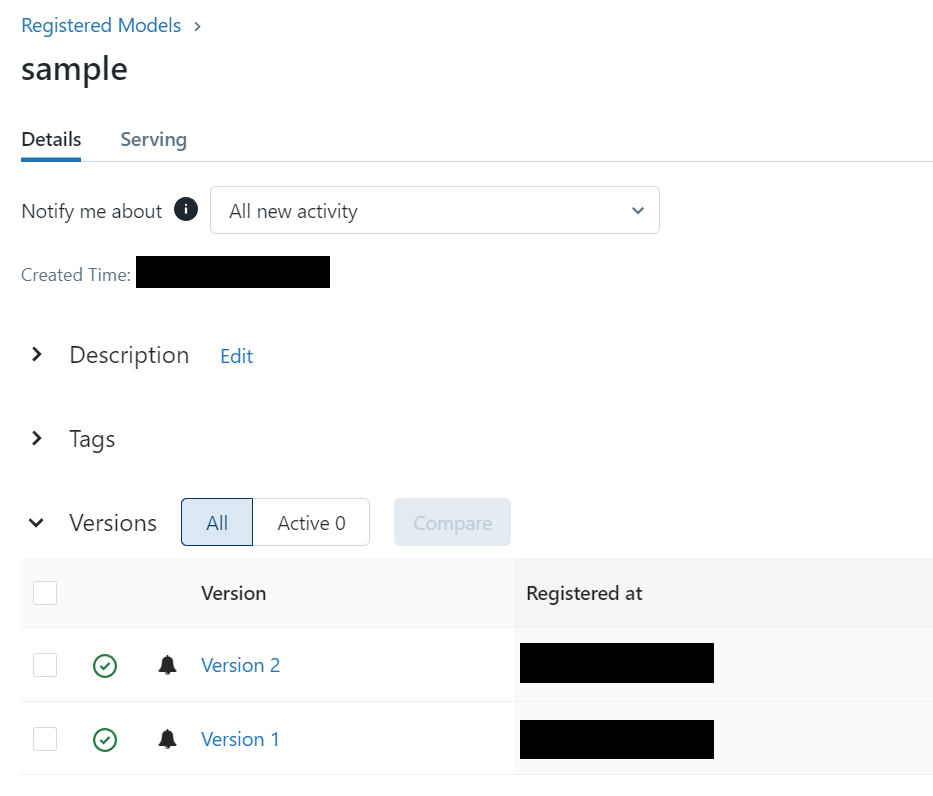
ここに登録している全てのバージョンのモデルをアンサンブル対象にする場合はこの工程を飛ばしてもいいのですが、実際にはこの中でもアンサンブル対象にする・しないを切り替えたりすると思いますので、アンサンブル対象バージョンのモデルにタグ付けをします。
例えば、Version 1のモデルをアンサンブル対象にしたい場合、Version 1のリンクをクリックし、詳細の画面を開いてください。
このUI上から、タグを設定することができます。
以下の画面では、key:emsemble、value:trueでタグを設定しています。(正確には、Addボタンを押すと登録される)
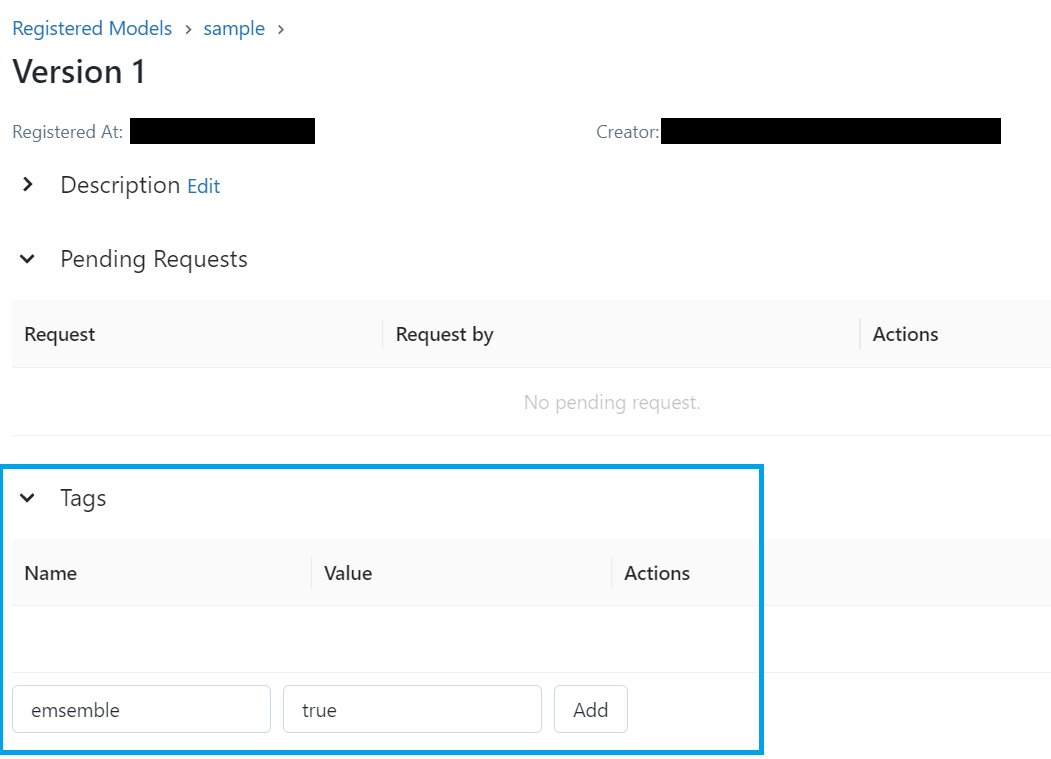
これをアンサンブル対象のバージョン分だけ繰り返します。
※ コード実行で登録することもできます。UI操作が面倒な方は是非調べてみてください!
3. Notebook内でモデルをロードする
モデルレジストリでタグ付けしたモデルは、mlflowの機能を使うことでロードできます。
以下、ロード処理の例です。
(こちらのコードを利用する場合、model_nameの中身はモデルレジストリに登録しているモデル名に変更してください)
# 例:モデルレジストリから特定のタグ付けをしたモデルを全てロードする
import mlflow
from mlflow import MlflowClient
model_name = "モデルの名前"
# emsemble=trueでタグ付けしたモデルのバージョンを取得
client = MlflowClient()
model_versions = [v.version for v in client.search_model_versions(f"name='{model_name}' and tags.emsemble='true'")]
# アンサンブル用モデルのロード
# 今回はdictionary型のmodels変数にロードしたモデルを格納する
models = {}
for v in model_versions:
model_version_uri = f"models:/{model_name}/{v}"
print(f"Loading registered model version from URI: {model_version_uri}")
model = mlflow.sklearn.load_model(model_version_uri)
models[v] = model
4. モデルを使って予測する
その後、ロードしたモデルを使って、予測のprobabilityを取得します。
# 例:modelsに格納されたモデルを使って予測値の確率を得る
# 下記処理だと、gid, prediction, (モデルの)versionの3列を持ったpandas dataframeが得られる
# forループで予測を実行しているが、sparkのudfを活用するなど並行処理で回した方が効率はよくなる
# テストデータの読み込み
test_pdf = spark.table("テストデータのテーブル名").toPandas()
# 予測結果取得
predictions = []
for k, v in models.items():
ret = v.predict_proba(test_pdf)
ret = pd.DataFrame(ret, columns=["proba_0", "proba_1"])
ret = pd.concat([test_pdf["gid"], ret["proba_1"]], axis=1)
ret['version'] = k
predictions.append(ret)
pred_pdf = pd.concat(predictions, axis=0)
5. アンサンブルを行う
この後pivotを使って縦長データを横長データに変換し、アンサンブル処理を行う流れになります。
スタッキングする場合は、ここでもAutoMLが使えたりします。
以上、MLflowでアンサンブルを回す際のモデル管理例でした。
まとめ
- アンサンブルに採用するモデルの選択とか、正直悩んでます。もっと勉強が必要。
- 最後まで粘っていきたいと思います!
- コンペ終わったら、苦労した点とかも書き出したい。