多くの企業ユースケースにおいて求められるRAGってこれなんじゃないでしょうか。
導入
LangChain Blogの以下記事でSelf-Reflective RAGが紹介されていました。
かなり実用的な内容だと思いましたので、今回はCRAGのCookbookの内容を一部改変してウォークスルーしたいと思います。
全体的に長くなりそうなので、今回は解説&準備編です。
なお、検証はDatabricks on AWSで行いました。
DBRは14.3ML LTS、g4dn.xlargeのクラスタを利用しています。
Self-Reflective RAGとは?
上記Blog記事よりざっくり邦訳・抜粋。
RAGを実装するには、RAGのステップに関する論理的な推論が必要であることに多くの人が気づいています。たとえば、(質問とインデックスの構成に基づいて)いつ検索するのか、いつより良い推論のために質問を書き換えるのか、もしくはいつ関連しない検索済み文書を破棄して再検索するのか、などです。
LLMを使って自己修正的に低品質の検索結果や生成を補足するために、Self-Reflective RAGという用語が論文では紹介されています。基本的なRAGフローは、単にチェーンを使用するだけで、LLMは取得したドキュメントに基づいて何を生成するかを決定します。
一部のRAGフローでは、LLMが質問に基づいて異なるレトリーバーなどを決定するルーティングを使用します。
しかし、Self-Reflective RAGは通常、質問を再生成したり、ドキュメントを再取得したりして、何らかのフィードバックを必要とします。ステートマシンは、ループをサポートする第3のタイプのコグニティブアーキテクチャであり、これに適しています。ステートマシンは、一連のステップ(例えば、検索、ドキュメントの採点、クエリの書き直し)を定義し、それらの間の遷移オプションを設定するだけです。たとえば、取得したドキュメントが関連しない場合は、クエリを書き直して新しいドキュメントを再取得します。
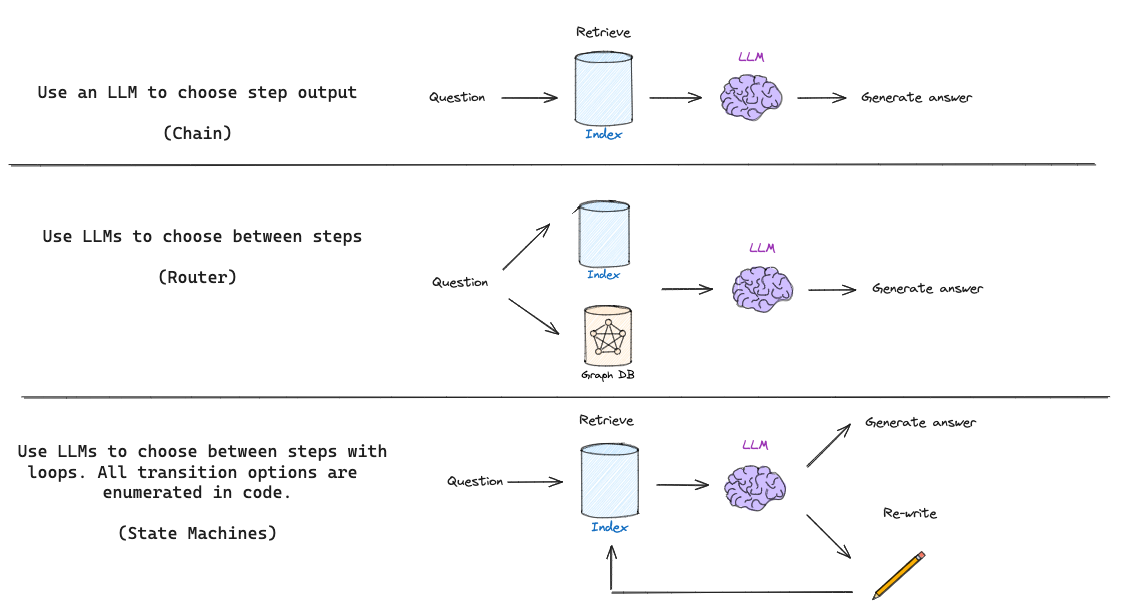
なかなか難解な表現ですね。。。
私の理解としては、Self-Reflective RAGは内部状態を持つ有限状態機械(FSM)として構築され、状態によって処理を変化・遷移先を決定する仕組だと認識しました。つまり、現在のノード位置と内部状態で遷移先をコントロールできるため、「文書検索した結果が0だったら、条件を変えて再検索する」「もしくは別のDBで再検索する」「生成するLLMを状態によって切り替える」というようなことが柔軟に制御できます。
LangChain(LCEL)でRAGを組む上で、条件分岐(Routing)の最善実装とかどうするのがいいかなーと思っていましたが状態機械で遷移先を決定する仕組なら(複雑度は上がりますが)柔軟に拡張もできそうです。
元BlogではSelf-Reflective RAGとしてCorrective RAG(CRAG)とSelf-RAGの2種をLangGraphを使って構築する例が記載されています。今回は、CRAGを中心に実践してみます。
Corrective RAG(CRAG)とは
CRAGは、端的に言うとRetrieveした文章の確からしさを検証し、不適当な内容があった場合Web検索などを用いて修正するフェーズを組み込んだSelf-Reflective RAGの一種です。
これによって、「質問に対してあまり正しくない検索文書しか取得できなかった場合、Web検索に切り替えて情報を取り直す」というようなことに対応したRAGが実現できます。
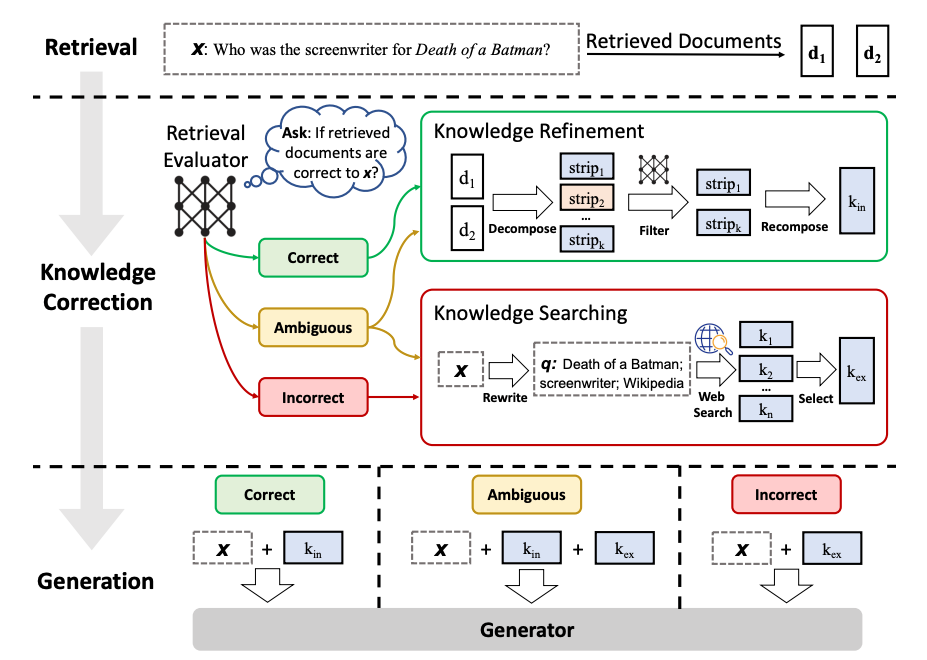
今回はLangChainのCookbookを参考に、CRAGの簡易実装を試します。
実装はLangGraphを利用して行われており、大まかに以下のようなグラフを構成します。
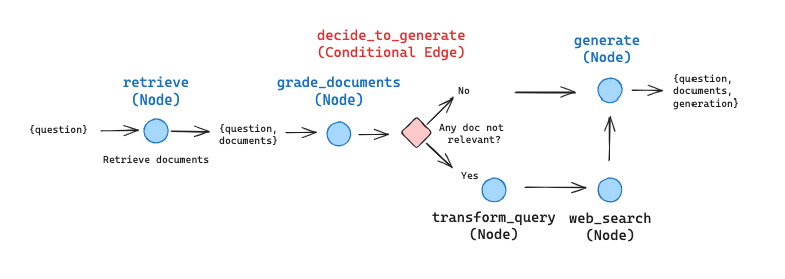
それでは、実装を行っていきましょう。
Step1. パッケージインストール
必要なパッケージをインストールします。
今回は一部LLMの推論エンジンとしてSGLangを利用します。
加えて、LangChainやLangGraph等を利用します。
# torch, xformers
# pytorchのリポジトリから直接インストールする場合
# %pip install -U https://download.pytorch.org/whl/cu118/torch-2.1.2%2Bcu118-cp310-cp310-linux_x86_64.whl
# %pip install -U https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl
%pip install -U /Volumes/training/llm/tmp/torch-2.1.2+cu118-cp310-cp310-linux_x86_64.whl
%pip install -U /Volumes/training/llm/tmp/xformers-0.0.23.post1+cu118-cp310-cp310-manylinux2014_x86_64.whl
# vLLM
# GithubからvLLMを直接インストールする場合
# %pip install https://github.com/vllm-project/vllm/releases/download/v0.3.0/vllm-0.2.7+cu118-cp310-cp310-manylinux1_x86_64.whl
%pip install /Volumes/training/llm/tmp/vllm-0.3.0+cu118-cp310-cp310-manylinux1_x86_64.whl
# !git clone https://github.com/flashinfer-ai/flashinfer.git
!cd /Workspace/Repos/SGLangリポジトリの場所/sglang && pip install -U -e "python[srt]"
%pip install -U "triton>=2.2.0"
%pip install -U langchain langchain-openai langgraph langchainhub chromadb tavily-python
dbutils.library.restartPython()
Step2. 外部サービスの利用準備
今回は、処理の一部にWeb検索を組み込みますが、DuckDuckGoではなくてTavilyを利用します。
APIを呼び出すためのキーを公式から取得してください。
詳細な手順はnpaka大先生の以下blogを参照ください。(いつも参考にさせてもらっています)
発行したAPIキーは、Databricksのシークレットに保管しておきます。
今回もDatabricks CLIを利用し、スコープをtavily、キーをapi_keyとして保管します。
databricks secrets create-scope tavily
databricks secrets put-secret tavily api_key --string-value xxxxxxxxxxxxxxxxxxx
Step3. 環境設定・必要なモデルの読み込み
モデルの読み込みや必要な環境設定を実行します。
まず、SGLangをGPUクラスタで動作させるためにtorchのstart_methodを変更。
import torch
torch.multiprocessing.set_start_method('spawn', force=True)
次に、埋め込み用のモデルをLangChainのHuggingFaceBgeEmbeddingsクラスを使って読み込んでおきます。
このモデルは、ベクトルストアの作成や検索において利用します。
埋め込み用のモデルは、事前にダウンロードしておいたBGE-M3を利用しました。
import torch
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "/Volumes/training/llm/model_snapshots/models--BAAI--bge-m3"
model_kwargs = {"device": device}
encode_kwargs = {"normalize_embeddings": True} # Cosine Similarity
embedding = HuggingFaceBgeEmbeddings(
model_name=model_path,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
※ 手前みそですが、BGE-M3については以前記事を書いています。
次にSGLangを使って、LLMをロードします。
モデルは事前にダウンロードしておいたOpenChat v1.5 016のGPTQ量子化済みモデルを利用します。
なお、SGLang何それって方は、以下の記事を参考にしてください。
from sglang import function, system, user, assistant, gen, set_default_backend, Runtime
from sglang.lang.chat_template import (
get_chat_template,
register_chat_template,
ChatTemplate,
)
# チャット用のプロンプトテンプレート
register_chat_template(
ChatTemplate(
name="openchat",
default_system_prompt=None,
role_prefix_and_suffix={
"system": ("", "\n"),
"user": ("GPT4 Correct User: ", "<|end_of_turn|>"),
"assistant": ("GPT4 Correct Assistant: ", "<|end_of_turn|>"),
},
)
)
model_path = (
"/Volumes/training/llm/model_snapshots/models--TheBloke--openchat-3.5-0106-GPTQ"
)
# Embedding用モデルでVRAMを消費しているため、mem_fraction_staticを小さめに設定
runtime = Runtime(model_path, mem_fraction_static=0.5)
runtime.endpoint.chat_template = get_chat_template("openchat")
# OpenChat-3.5-0106のtokenizerファイルのバグ対応
runtime.get_tokenizer().eos_token_id = 32000
set_default_backend(runtime)
最後に、SGLangで読み込んだモデルをOpenAIのAPIとして利用するための環境変数を設定します。
SGLangは上記のコードを実行すると、別プロセスとしてモデルを利用するためのAPIサーバを立ち上げます。このサーバはOpenAIのAPIと互換があるように設計されているため、URLを適切に設定すればOpenAIのAPIクライアントからアクセスすることができます。
また、Tavilyを利用できるように、ここで環境変数にAPIキー情報を設定しておきます。
import os
# SGLang SRTへ接続させるための設定
os.environ["OPENAI_BASE_URL"] = runtime.url + "/v1"
os.environ["OPENAI_API_KEY"] = "EMPTY"
# Tavily APIを実行するためのAPIキーを設定
os.environ["TAVILY_API_KEY"] = dbutils.secrets.get("tavily", "api_key")
Step4. ベクトルストア/Retriverの準備
RAGで利用するRetriverを準備します。
今回も以下のWikipediaから情報を取得し、ChromaDBにチャンキングしたデータを保管して利用することにします。
最後にベクトルストアからLangChainのRetrieverを作成しています。
今回はクエリに対して3件の文書を取得する設定にしています。
from typing import Any
import requests
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""句読点も句切り文字に含めるようにするためのシンプルなスプリッタ"""
def __init__(self, **kwargs: Any):
separators = ["\n\n", "\n", "。", "、", " ", ""]
super().__init__(separators=separators, **kwargs)
def get_wikipedia_page(title: str):
"""
日本語Wikipediaから情報を取得
"""
URL = "https://ja.wikipedia.org/w/api.php"
params = {
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
}
# Wikipediaのベストプラクティスに則って、カスタムユーザエージェントをヘッダに設定
headers = {"User-Agent": "Langchain+Databricks+RAG/0.0.1"}
response = requests.get(URL, params=params, headers=headers)
data = response.json()
# コンテンツを取得
page = next(iter(data["query"]["pages"].values()))
return page["extract"] if "extract" in page else None
# Wikipediaの情報を1件取得し、適当にチャンク分け
docs = [get_wikipedia_page("葬送のフリーレン")]
docs_list = [Document(page_content=d) for d in docs]
text_splitter = JapaneseCharacterTextSplitter(chunk_size=512, chunk_overlap=40)
doc_splits = text_splitter.split_documents(docs_list)
# VectorDBであるChromaに保管
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embedding,
)
# Retriever取得。検索件数は3件固定
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
ここまでで準備はほぼほぼ終わりです。
暫定まとめ
Corrective RAG(CRAG)の準備編でした。
次回は、今回準備した内容とLangGraphを使い、CRAGの処理や遷移を構築します。
続きはこちら: