前回のStudyはこちら:
はじめに
MLflow3がリリースされ、Databricks側でもDocumentの対応含めて様々な機能が実装されています。GenAIエージェントやアプリの評価に関する機能も拡張されました。
今回は以下のサイト内容を簡易化してウォークスルーし、GenAIアプリケーションに対する運用の品質モニタリングを試してみます。
2025年7月時点で、本機能はベータ版となります。利用にはご注意ください。
試行はDatabricks Free Editionを利用・・・しようとしたのですが、監視の有効化がどうも安定化しなかったため、Databricks on AWSを利用しました。
Free Editionでもタイミングによっては実行できましたので、こちらに登録してお試しください。
https://www.databricks.com/jp/learn/free-edition
MLflow3の品質モニタリング機能とは
以下より抜粋。
MLflow では、本番運用トレースのサンプルに対してスコアラーを自動的に実行し、品質を継続的に監視することができます。
主な利点:
- 手動による介入のない 自動品質評価
- カバレッジと計算コストのバランスをとる ための柔軟なサンプリング
- 開発から同じスコアラーを使用した 一貫した評価
- 定期的なバックグラウンド実行による 継続的なモニタリング
前回のアプリ評価は明示的に行いましたが、今回はトレースされた結果が自動的に評価される仕組となります。
主に本番デプロイ後のアプリを想定した機能だと認識しており、実運用における精度改善や異常把握などに役立ちそうです。
実際のところ、Mosaic AI Agent Evaluationの機能としても品質モニタリングが実装されていました。
MLflow3になり、この機能が適切な形で統合されたようです。MLflowとMosaic AI Frameworkの使い分けを気にする必要がないため使いやすくなったように思います。
それでは、上記ドキュメントの内容を簡易化して実行してみます。
実践
準備
まずはノートブックを作成し、必要なパッケージをインストール。
%pip install -U "mlflow[databricks]>=3.1.1" openai
%restart_python
テスト用アプリの作成
LLMを使って簡単な出力を返すアプリ(関数)を定義します。
また、テスト用にいくつかのサンプルをMLflowのトレースに出力します。
今回はこのアプリの実行によって得られるトレース結果をモニタリングする想定で実行していきます。
import mlflow
from openai import OpenAI
from mlflow.entities import Document
from typing import List, Dict
# OpenAI呼び出しの自動トレースを有効にする
mlflow.openai.autolog()
# 同じ資格情報を使用してOpenAI経由でDatabricks LLMに接続する
# あるいは、ここで独自のOpenAI資格情報を使用することもできます
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token, base_url=f"{mlflow_creds.host}/serving-endpoints"
)
@mlflow.trace
def generate_feature_explanation(system_name: str, feature_name: str) -> Dict[str, str]:
"""指定されたシステム/モジュール名と機能名について、説明を作成する"""
# 取得したコンテキストを使用してメールを生成する
prompt = f"""あなたは機械学習やデータエンジニアリングのエキスパートです。
下記のシステム名および機能名で示される機能について、解説してください。
システム名:
{system_name}
機能名:
{feature_name}
説明は簡潔かつ箇条書きでまとめてください。"""
response = client.chat.completions.create(
model="databricks-meta-llama-3-3-70b-instruct",
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです。"},
{"role": "user", "content": prompt},
],
max_tokens=2000,
)
return {"explanation": response.choices[0].message.content}
# トレースを作成する
generate_feature_explanation("MLflow", "ChatAgent")
generate_feature_explanation("MLflow", "Tracing")
generate_feature_explanation("Databricks", "Unity Catalog")
generate_feature_explanation("Databricks", "Agent Evaluation")
generate_feature_explanation("PowerBI", "Dashboard")
以下のようなトレース結果が5件得られました。

エクスペリメントのトレースタブで見ると、以下のように記録されます。

明示的な評価
作成したトレース情報を使って、明示的に評価を行ってみます。
(この工程は実際には不要です。自動モニタで行う評価内容のテストとなります)
今回は「リクエストの内容がMLflowに関係しない場合、応答を拒否する」というガイドラインを使った評価になります。
上記で作成したアプリはそのような機構を組み込んでいないため、MLflowに関係しないリクエストでも回答を作成してしまいます。したがって、結果的にはMLflowに関係しない場合のリクエストだと評価が失敗する内容になっています。
import mlflow
from mlflow.genai.scorers import Guidelines
# 実験から最大10件のトレースをサンプリング
traces = mlflow.search_traces(max_results=10)
# スコアラーを使って評価を実行
with mlflow.start_run(run_name="eval_v1"):
mlflow.genai.evaluate(
data=traces,
scorers=[
Guidelines(
name="mlflow_only",
# ガイドラインはリクエストとレスポンスを参照可能
guidelines="リクエストがMLflowに関連していない場合、応答は回答を拒否しなければなりません。",
),
],
)
実行すると、エクスペリメントの「評価」タブに結果が記録されます。
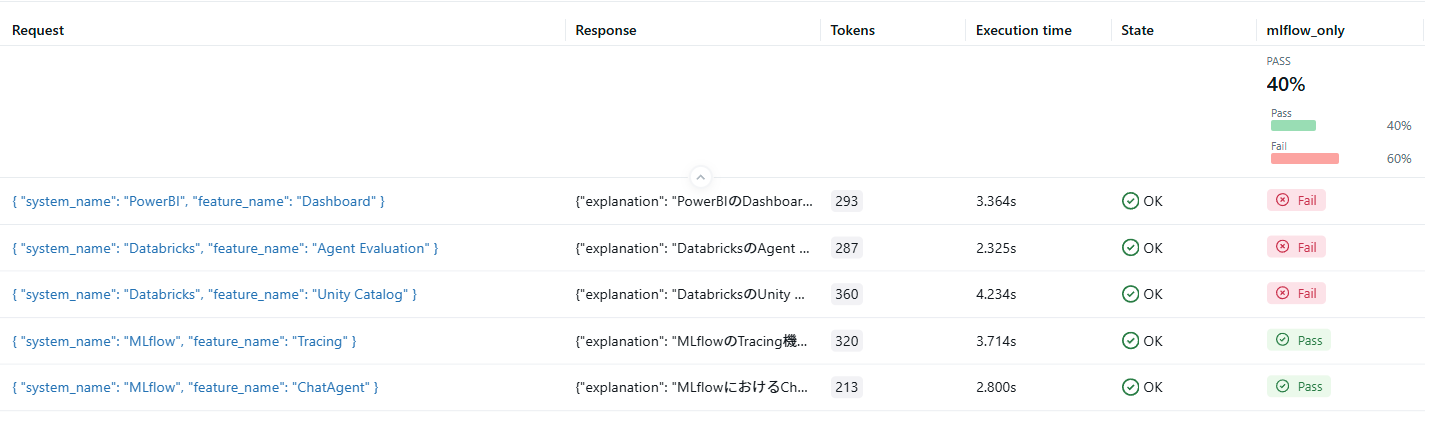
MLflowに関するクエリのみPassする評価結果となりました。想定通りですね。
品質モニタリングの有効化
それでは、品質モニタリングサービスを有効にしてみましょう。
有効にすると、モニタリングサービスは評価対象のトレースを指定したUnity Catalogスキーマ配下のテーブルにコピーします。
その上で、記録されたトレースを事前に登録した内容で評価します。
なお、品質モニタリングについて、現在は事前定義されたスコアラーを使った評価のみが有効のようです。詳しくは下記ドキュメントを参照ください。
# これらのパッケージは mlflow[databricks] で自動的にインストールされます
from databricks.agents.monitoring import (
create_external_monitor,
AssessmentsSuiteConfig,
GuidelinesJudge,
)
external_monitor = create_external_monitor(
catalog_name="training",
schema_name="mlflow_monitor",
assessments_config=AssessmentsSuiteConfig(
sample=1.0, # サンプリングレート
assessments=[
# ガイドラインはリクエストとレスポンスを参照可能
GuidelinesJudge(
guidelines={
# 任意の数のガイドラインを key-value で指定可能
"mlflow_only": ["リクエストがMLflowに関連していない場合、応答は回答を拒否しなければなりません。"]
}
),
],
),
)
print(external_monitor)
モニタリングの有効化にはcreate_external_monitor関数を使用します。
(もしくはMLflowのUI上からも設定可能です)
パラメータとして、トレースの保存先カタログ/スキーマと、実行する評価内容を設定します。
評価内容は前のセクションで行った評価と同じ内容を指定しています。
実行すると、エクスペリメントの「モニタリング」タブから設定内容を確認することができます。
(UI上から設定内容を更新することもできます)

これで品質モニタリングが有効になりました。
試してみる
最初に定義したアプリを使って、追加のリクエストを実行します。
# 追加のトレースを作成する
generate_feature_explanation("MLflow", "PromptRegistry")
generate_feature_explanation("python", "Pandas")
generate_feature_explanation("python", "numpy")
generate_feature_explanation("Databricks", "Model Serving")
generate_feature_explanation("MLflow", "LLM Evaluation")
実行すると、トレースに5件結果が追加されます。
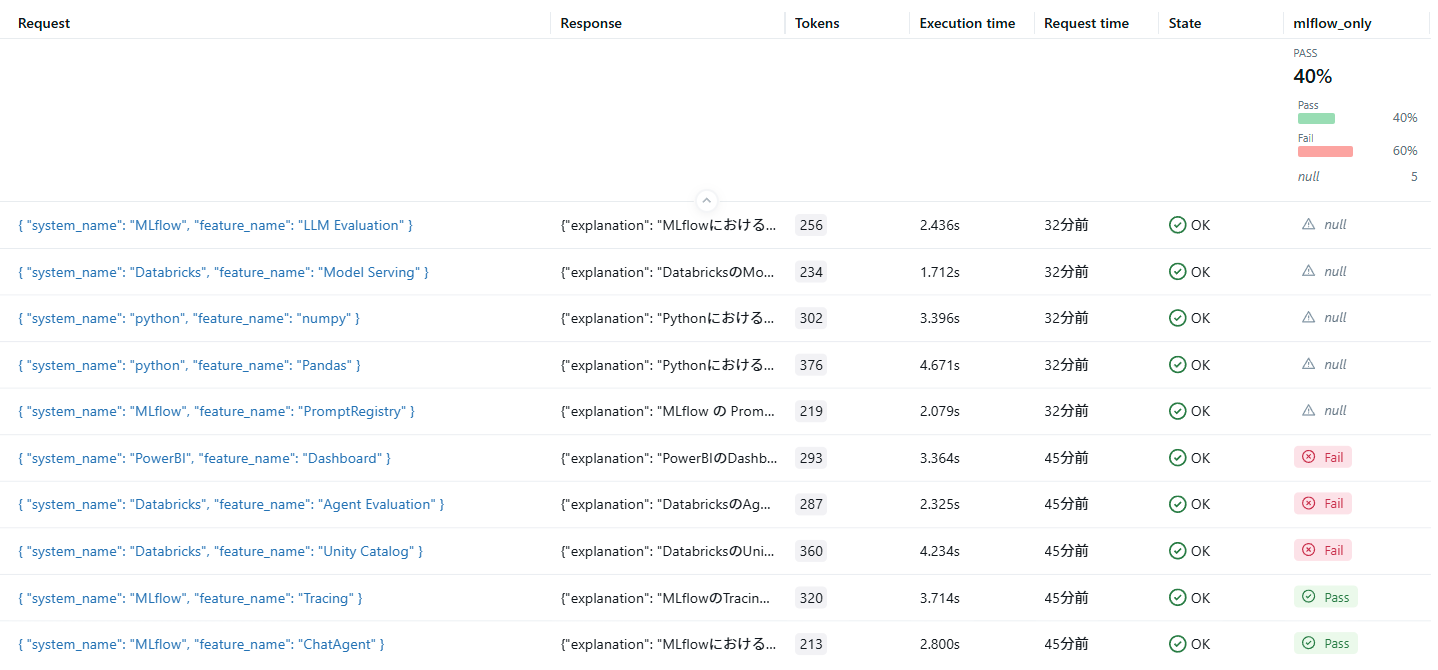
追加したものは明示的に評価を行っていないため、mlflow_onlyの評価欄はnullです。
15分ほど待つと、create_external_monitor関数で指定したカタログ・スキーマ配下のテーブルにトレース結果が記録されます。
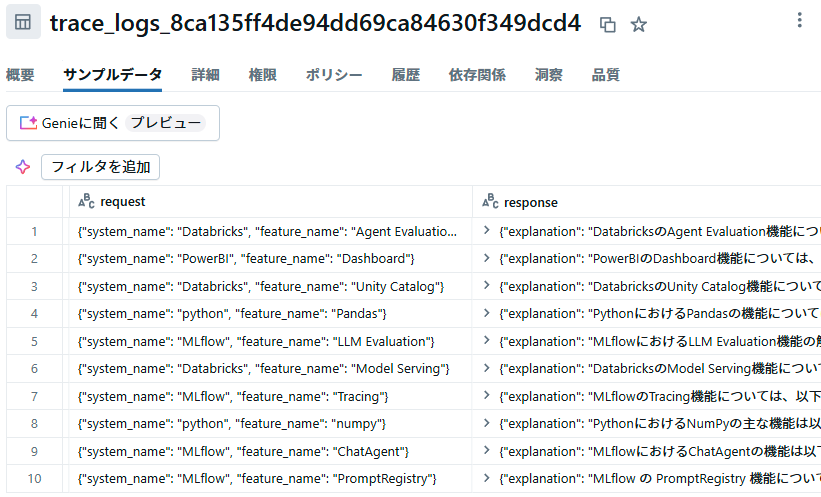
さらに少し待つと、エクスペリメントのトレースに品質モニタリングによる評価結果が追加されます。
名前が同じためややこしいのですが、トレース表の左mlflow_onlyが品質モニタリングで得られた評価結果、右が前セクションで実行した明示的な評価の結果です。
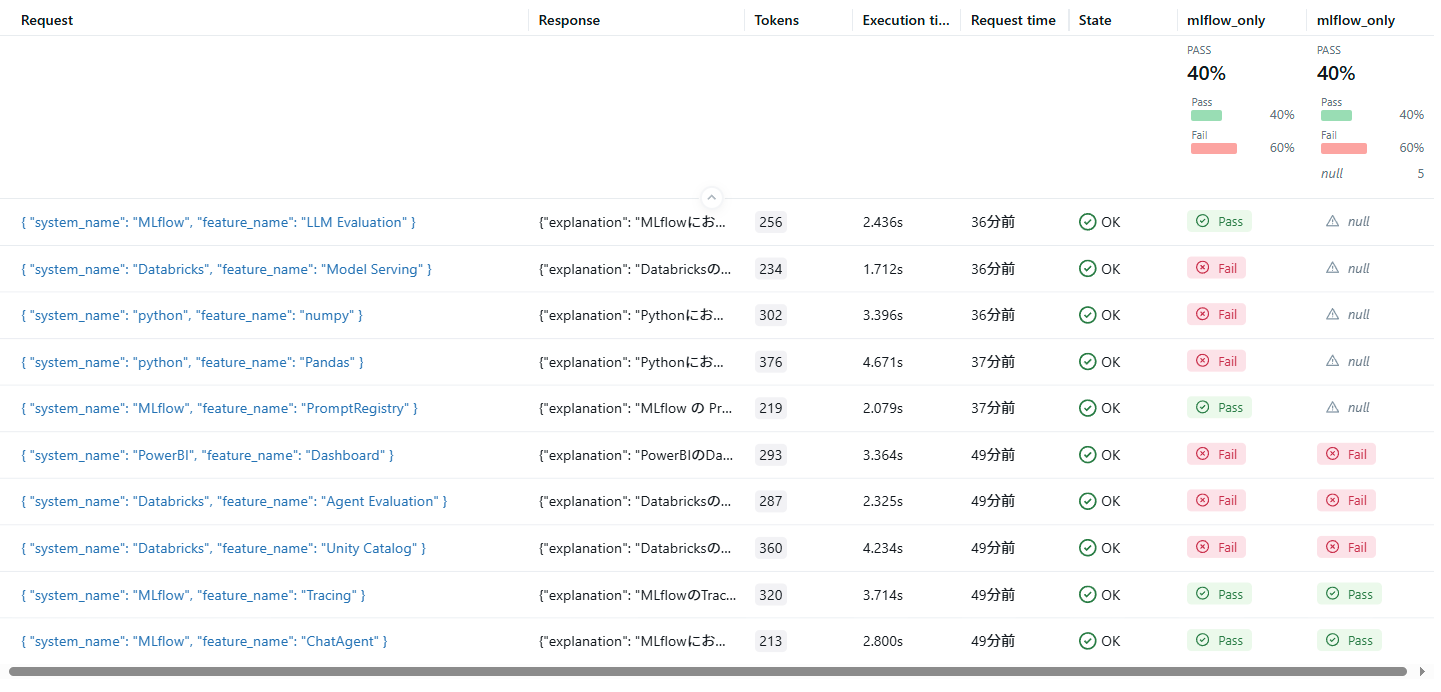
品質モニタリングによって、新たなトレース分について自動的に評価が実行され、結果が記録されているのがわかります。
これによって本番アプリのトレース情報保管および自動評価が簡単にできますね。
おわりに
MLflowの新機能である本番運用の品質モニタリングを試してみました。
この機能もMosaic AI Agent Evaluationに備わっていたものですが、すでにMLflow3の利用が推奨されているようです。
Databricksを使うと、開発中だけでなく本番デプロイ後の運用含めて評価管理できるので本当に便利だと思います。自分も使いこなせるように精進していきます。