ようやく使えるようになったので。
導入
以前、WandBを使ったTracingを試してみました。
今回は、LangSmithを使ったトレーシングをDatabricks上で試してみます。
LangSmithとは
公式Docより。
LangSmith は、プロダクショングレードの LLM アプリケーションを構築するためのプラットフォームです。
これにより、任意のLLMフレームワーク上に構築されたチェーンとインテリジェントエージェントをデバッグ、テスト、評価、監視でき、LLMで構築するための頼りになるオープンソースフレームワークであるLangChainとシームレスに統合されます。
LangSmithは、オープンソースのLangChainフレームワークの背後にある会社であるLangChainによって開発されました。
分かりづらいですが、LangChain等のLLM処理の動作を記録し、デバッグやテスト、稼働をモニタする機能を備えたプラットフォームになります。
LangChainの開発元が構築・提供しており、LangChainと高い親和性を持っています。
習うより慣れろ、というわけで実際の挙動を確認してみます。
LLMの処理実行はDatabricks on AWS上で実施しました。
DBRは14.2ML、クラスタタイプはg4dn.xlargeを使用しています。
Step0. LangSmithを利用するための準備
まずは公式サイトからサインアップしてください。
2024/2月現在、LangSmithはまだプライベートベータ中です。
登録後すぐに使えるというわけではない点、ご注意ください。
一旦Waitlistに登録され、利用可能になり次第メールで連絡が来ます。
サービスが利用可能になった後、API Keyを発行します。
コンソール画面左下部のメニューより、メニューからAPI Keysを選び、

Create API Keyボタンを押してキーを発行。
その上で、APIキーをDatabricksのシークレットに登録しておきます。
今回はDatabricks CLIを使い、スコープをlangsmith、キーをapi_keyという名前で登録しました。
CLIを利用する場合、以下のようなコマンドで登録できます。(XXXXXXXXXXXXXXXXXがAPIキー部分)
databricks secrets create-scope wandb
databricks secrets put-secret wandb api_key --string-value XXXXXXXXXXXXXXXXXXXXXXXXXXX
次に、LangSmith上でテスト用のプロジェクトを作成。
名前をtest_projectにしておきます。
以後、LLMの実行結果等をここに保管するようにします。
Step1. パッケージインストール&環境変数設定
Databricks上でノートブックを作成し、必要なパッケージをインストール。
モデルの推論にはExllama V2を利用します。
langsmithパッケージをインストールしているのがいつもとの変化点です。
%pip install -U transformers accelerate "exllamav2==0.0.12" langchain sentencepiece langsmith
dbutils.library.restartPython()
LangSmithを利用するための環境変数を設定します。
API Keyはsecretsに登録したものを取得します。
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = dbutils.secrets.get("langsmith", "api_key")
os.environ["LANGCHAIN_PROJECT"] = "test_project"
Step2. ロギングするためのChainを準備
モデルをロードし、ロギング動作確認用の単純なChainを作成します。
処理自体は前回と同じです。
モデルは事前にダウンロード済みの以下モデルを利用しました。
ChatExllamaV2Modelクラスについては、こちらを参照してください。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.chat import (
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from exllamav2_chat import ChatExllamaV2Model
model_path = "/Volumes/training/llm/model_snapshots/models--TheBloke--openchat-3.5-1210-GPTQ"
chat_model = ChatExllamaV2Model.from_model_dir(
model_path,
system_message_template="{}",
human_message_template="GPT4 User: {}<|end_of_turn|>",
ai_message_template="GPT4 Assistant: {}",
temperature=0.01,
top_p=0.9,
max_new_tokens=512,
cache_8bit=True,
low_mem=True,
cache_max_seq_len=2048,
)
system_template = "You are a helpful AI assistant. Please reply answer in Japanese."
template = """Answer the following question.
Question: {question}
"""
prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template(template),
AIMessagePromptTemplate.from_template(" "),
]
)
chain = ({"question": RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser())
Step3. 推論とトレース実行
では作成したChainを使って推論を実行します。
# 推論実行
async for s in chain.astream("Databricksとは何?"):
print(s, end="", flush=True)
データブリックス(Databricks)は、アメリカのDatabricks, Inc.社が開発したデータ分析プラットフォームです。これにより、大規模なデータセットを効率的に処理し、機械学習モデルを構築し、分析結果を視覚化することが可能です。PythonやScalaなどのプログラミング言語を用いて、データプレインの統合プラットフォーム上で動作します。また、Apache Sparkというオープンソースのエコシステムをベースにしており、高速なデータ処理が可能です。
実行結果だけだとわかりませんが、通常より数秒ほど処理に追加の時間がかかりました。
それでは、LangSmithの画面を見てみましょう。
test_projectのページを見ると、処理がLCELの処理単位で記録されています。
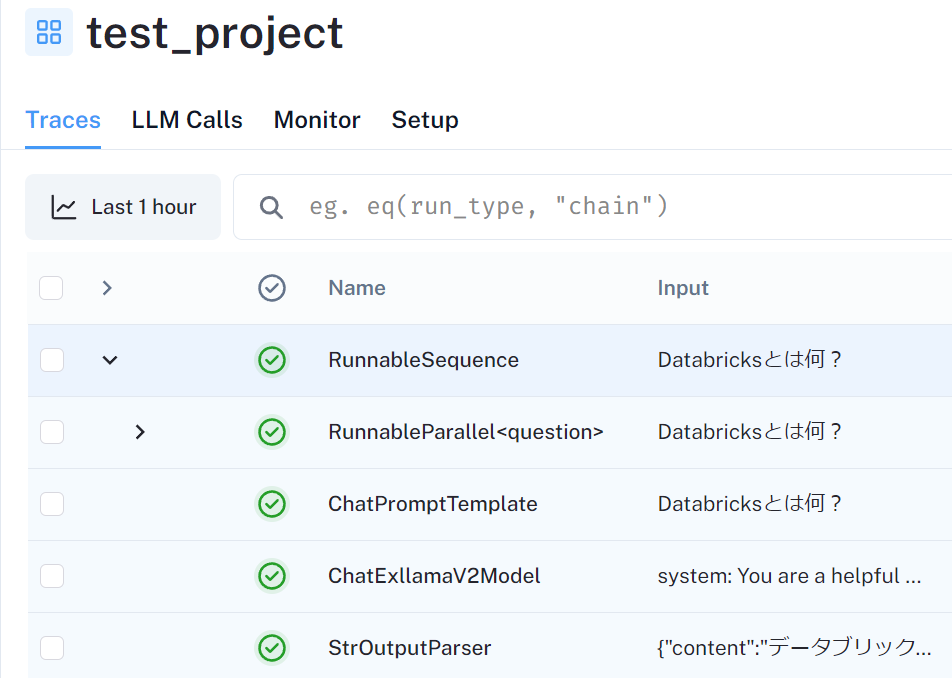
処理を選択すると出力含めて詳細を確認することもできます。
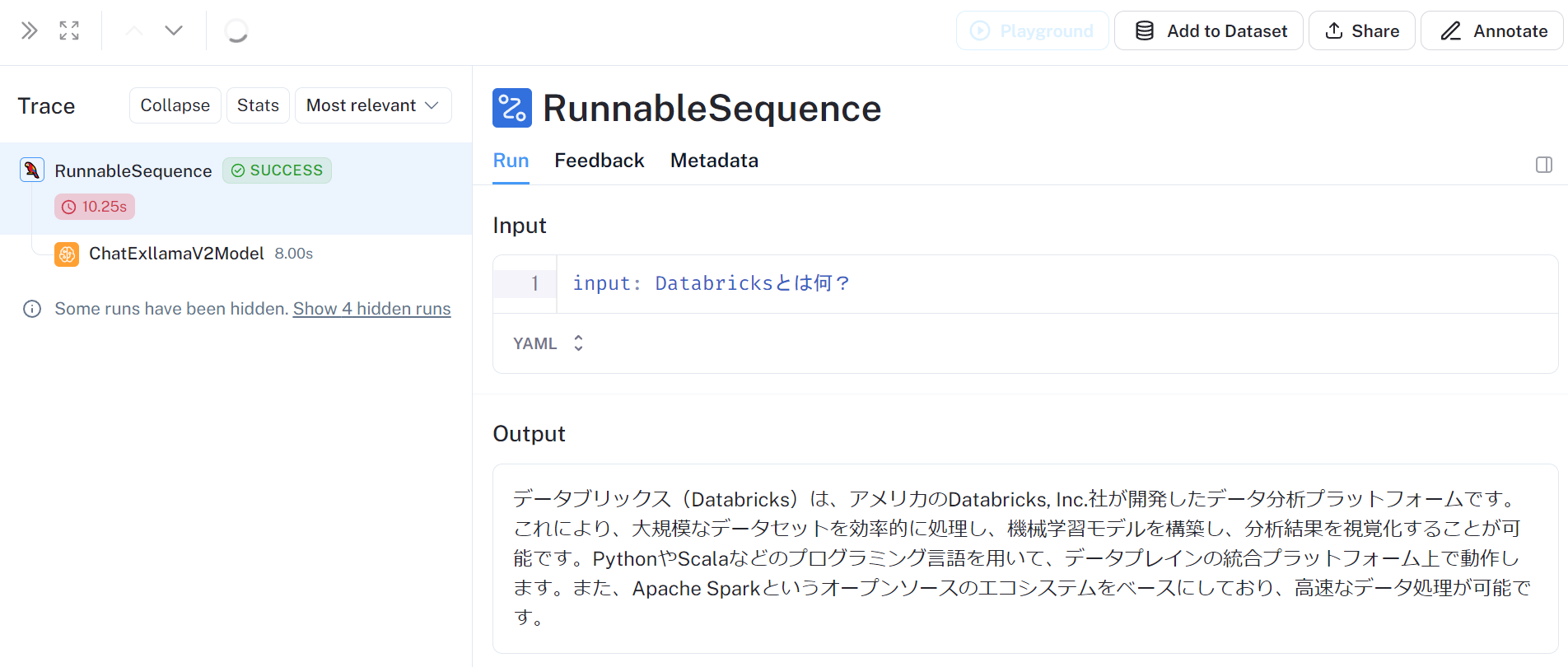
他にMetadataも記録されており、どのような環境下で実行された処理なのか、レイテンシの大きさはどの処理が大きいのか、などを確認することができます。
かなり手軽ですね。
Step4. Context Managerを使ったトレース範囲の限定
こちらにあるように、トレース保管先のプロジェクトや範囲を環境変数を使わずに制御できます。
今回はContext Managerを使ってトレース制御してみます。
まず、通常のトレースを無効化。
# 環境変数でトレースを無効化
os.environ["LANGCHAIN_TRACING_V2"] = "false"
# この処理はロギングされない
async for s in chain.astream("東京の明日の天気は?"):
print(s, end="", flush=True)
Context Managerでロギングを有効化して推論。
from langchain_core.tracers.context import tracing_v2_enabled
# with句の範囲はトレースが有効化される
with tracing_v2_enabled(project_name="test_project"):
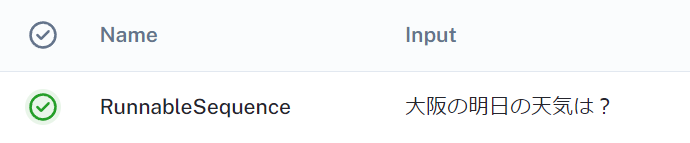
async for s in chain.astream("大阪の明日の天気は?"):
print(s, end="", flush=True)
with句の範囲で実行したChainの内容が記録されました。
まとめ
LangSmithでLLMの処理を記録・確認してみました。
WandBと比べても簡単に記録を実施することができ、またLangChainとの親和性も高いですね。
ただ、記録のためのオーバーヘッドが結構大きい(これはこちらの実装の問題かもしれません)、またプライベートベータであるなど、本格採用を検討する際は注意が必要かと思います。
UIも粗削りな部分がまだ見られるんですが、全体のデザインは割と好みなので、安定化などが進んで正式公開が進んで欲しい。