久しぶりに音声認識。
導入
Reazon Human Interaction LaboratoryがReazonSpeech v2.0を公開しました。
ReazonSpeech v2.0では、従来のESPnetに加え、NVIDIA NeMoベースのモデルの提供をしており、
新しく提供されたモデルは、高速かつ高精度に日本語を認識できる点が特徴のようです。
以下の図ではWhisper Large-v2と同程度の精度かつWhisper Tinyよりも高速に認識していることが示されています。
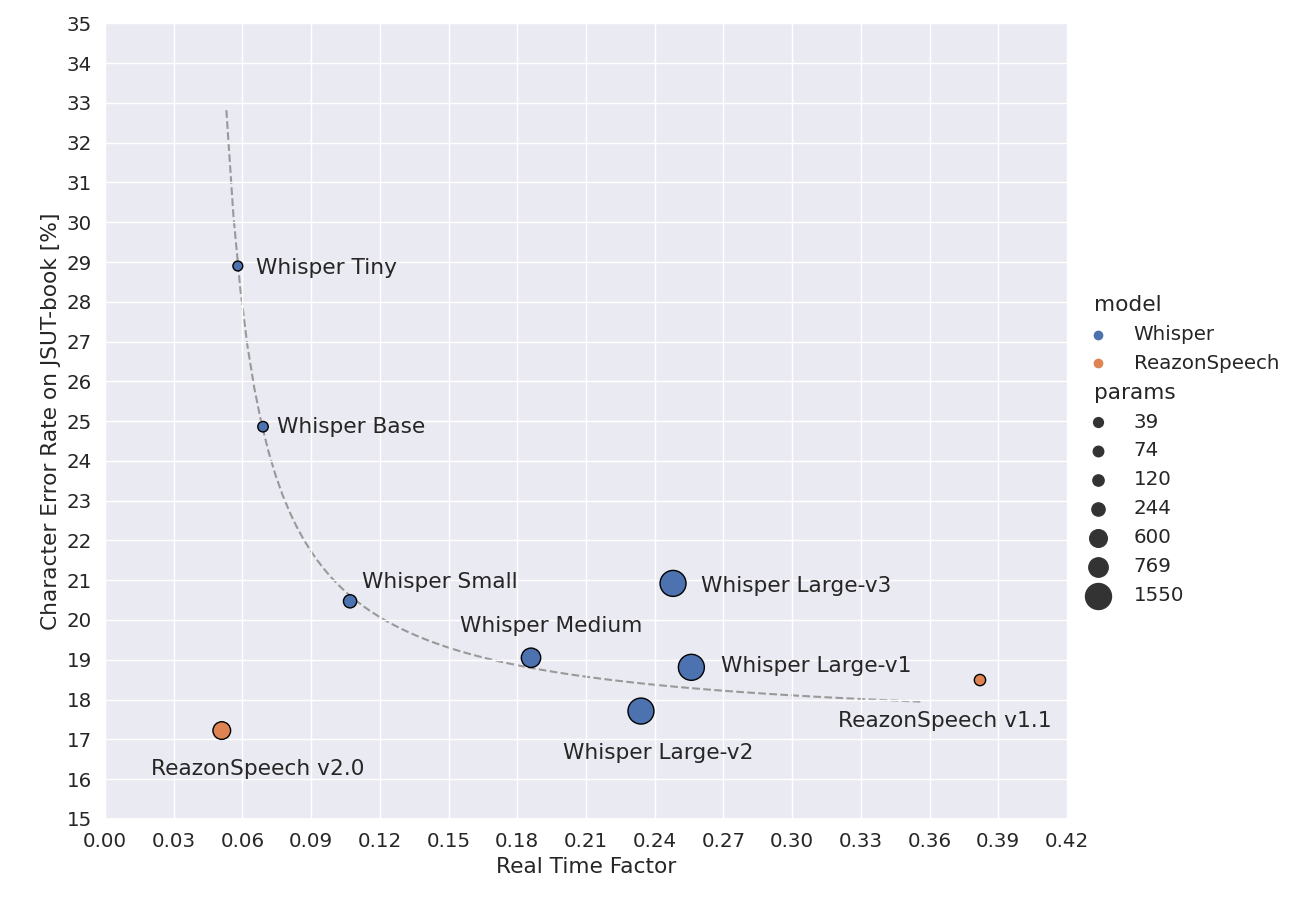
以下の比較記事を見て面白そうに思いましたので、Databricks上で試してみました。
検証環境はDatabricks on AWSでDBRは14.3ML、CPUクラスタを利用しています。
Step1. パッケージのインストール
githubからパッケージをインストールする必要があるため、こちらのリポジトリをReposを使ってクローンします。

ノートブックを作成し、Reposでクローンしたパスを利用してnemo.asrパッケージをインストールします。
# gitコマンドを使って直接クローンする場合:
# $ git clone https://github.com/reazon-research/ReazonSpeech
# $ pip install ReazonSpeech/pkg/nemo-asr # or espnet-oneseg, espnet-asr
%pip install /Workspace/Repos/ReazonSpeech/pkg/nemo-asr
Step2. テスト用の音声ファイルを準備
今回は音声さんを利用して音声ファイルを作成しました。

作成したファイルを、Unity Catalog Volumes上にカタログエクスプローラ経由でアップロードしておきます。

Step3. 音声認識
モデルと音声ファイルをロードし、認識処理を実行します。
load_modelの初回実行時はhuggingfaceからモデルファイルをダウンロードするため、少し時間がかかります。
from reazonspeech.nemo.asr import load_model, transcribe, audio_from_path
# Load ReazonSpeech model from Hugging Face
model = load_model()
# Read a local audio file
audio = audio_from_path("/Volumes/training/default/sample_data/wav/139816755543920.mp3")
# Recognize speech
ret = transcribe(model, audio)
transcribeの処理自体は、CPUクラスタでも数秒程度で完了しました。
では、認識結果を確認してみます。
from pprint import pprint
pprint(ret)
TranscribeResult(text='データブリックスはアパッチスパークをもとにしたクラウドネイティブのデータエンジニアリングプラットフォームです。データブリックスはスパークの柔軟性と強力さを生かしながらデータ科学者やデータエンジニアが協力してデータを扱うことを目的としています。',
subwords=[Subword(seconds=0, token_id=2, token=''),
Subword(seconds=0.14, token_id=291, token='デ'),
Subword(seconds=0.30000000000000004,
token_id=19,
token='ー'),
Subword(seconds=0.38, token_id=123, token='タ'),
Subword(seconds=0.6200000000000001,
token_id=189,
token='ブ'),
Subword(seconds=0.7, token_id=65, token='リ'),
Subword(seconds=0.78, token_id=249, token='ック'),
Subword(seconds=1.02, token_id=29, token='ス'),
Subword(seconds=1.18, token_id=7, token='は'),
--- 中略 ---
Subword(seconds=16.7, token_id=11, token='と'),
Subword(seconds=16.86, token_id=283, token='しています'),
Subword(seconds=17.18, token_id=1, token='。')],
segments=[Segment(start_seconds=0,
end_seconds=6.54,
text='データブリックスはアパッチスパークをもとにしたクラウドネイティブのデータエンジニアリングプラットフォームです。'),
Segment(start_seconds=7.5,
end_seconds=11.58,
text='データブリックスはスパークの柔軟性と強力さを生かしながら'),
Segment(start_seconds=12.14,
end_seconds=17.18,
text='データ科学者やデータエンジニアが協力してデータを扱うことを目的としています。')])
出力結果のように、認識した全文、サブワード、セグメントをそれぞれ取得することができます。
サブワードとセグメントは開始・完了秒数が取得できるため、利便性も高い結果を得られます。
認識結果もかなり精度良いですね。
句読点の出力は無いと思っていたのですが、今回試した例では句読点も出力されました。
まとめ
ReazonSpeech v2を試してみました。軽く試した程度なので長文認識での精度評価等はわからないのですが、確かに高速かつ高精度で認識されているように感じました。
また、Databricksだと追加のライブラリインストールも不要で、簡単に動作させることができて良いですね。
音声認識系はビジネス活用の幅も広いと思っているので、いろんなユースケースが発掘できるといいなあ。