以下の続きです。
導入
引き続き、CRAGのCookbookの一部改変ウォークスルーの続きをしていきます。
前回はモデルの読み込みやベクトルストアの作成などまで実施しました。
今回はLangGraphを使ってCRAGのノードやエッジを設定、そして実行までしていきます。
LangGraphについては、手前みそですが以前以下のような記事を書いたので参考まで。
Step5. 状態クラスの定義
グラフ内の状態を保管・管理するためのクラスを定義します。
全ての状態をDict型で保管する構成となります。
from typing import Dict, TypedDict
class GraphState(TypedDict):
"""
グラフの状態を表します。
Attributes:
keys: 各キーが文字列である辞書
"""
keys: Dict[str, any]
Step6. ノードとエッジの定義
LangGraphのグラフノードとなる処理(関数)と、グラフの分岐条件を制御する関数を定義します。
今回構成するグラフは以下のような画像のフローとなります。(Cookbookより引用)
画像の青丸がノード、ひし形部分が分岐条件を設定するエッジとなります。
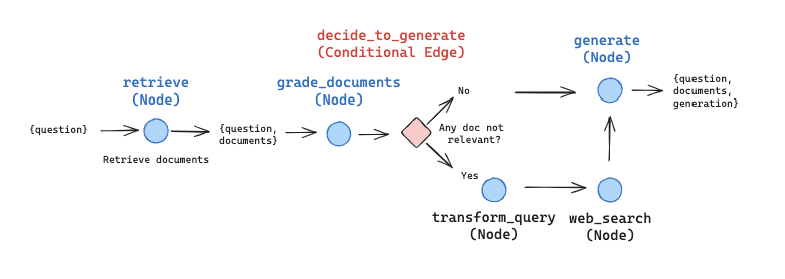
各ノードは、何らかの処理を実行した上で(Step5で定義した)状態を変化させます。
なお、このCookbookでは実論文に対して以下の変更が加えられているとのこと。
- knowledge refinementフェーズは省略。
- 関連のない文書が取得された場合、Web検索結果を取得・利用。この場合、Tavilyを使って検索。
- Web検索を行う際はオリジナルのクエリをWeb検索に適した形に変換。
では、各ノードの定義をしていきます。
retrieve
関連文書を検索するノード処理の定義です。
Step4で作成したRetrieverを使って文書を取得し、グラフの状態オブジェクトに格納して返すだけのシンプルな内容です。
import json
import operator
from typing import Annotated, Sequence, TypedDict
from langchain import hub
from langchain.output_parsers.openai_tools import PydanticToolsParser
from langchain.prompts import PromptTemplate
from langchain.schema import Document
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.tools.ddg_search.tool import (
DuckDuckGoSearchResults,
DuckDuckGoSearchRun,
)
from langchain_community.vectorstores import Chroma
from langchain_core.messages import BaseMessage, FunctionMessage
from langchain_core.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
AIMessagePromptTemplate,
)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
import sglang as sgl
def retrieve(state):
"""
文書を検索する
Args:
state (dict): 現在のグラフ状態
Returns:
state (dict): 検索された文書を含んだグラフ状態
"""
print("---RETRIEVE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.get_relevant_documents(question)
return {"keys": {"documents": documents, "question": question}}
grade_documents
retrieveで取得した文書が質問と関連するかどうかをLLMに判定させ、関連する文書だけにフィルタするノード処理の定義です。
また、関連しない文書が1件でも含まれていた場合、Web検索を利用するフラグをONにします。
オリジナルのCookbookではOpenAI GPT-4を利用して関連を判定する処理となっていましたが、今回はロード済みのローカルLLM(OpenChat v1.5 7B)を利用するように改変しています。
Yes/Noの判定をなるべく高い確立で出力できるようにするため、SGLangのJSONデコード機能を利用しています。
def grade_documents(state):
"""
文書が質問と関連するかどうかを判定する
Args:
state (dict): 現在のグラフ状態
Returns:
state (dict): 関連文書のみを残したグラフ状態
"""
print("---CHECK RELEVANCE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# JSONテンプレート
grade_regex = r"""\{\n""" + r""" "score": "(yes|no)"\n""" + r"""\}"""
# SGLangで判定処理
@sgl.function
def grade_gen(s, context, question):
template = (
"You are a grader assessing relevance of a retrieved document to a user question. \n"
f"Here is the retrieved document: \n\n{context} \n\n"
f"Here is the user question: {question} \n"
"If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n"
"Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.\n"
"Please return 'no' even if the document is an unintelligible sentence.\n\n"
)
s += sgl.user(template)
s += sgl.assistant(sgl.gen("json_output", max_tokens=128, regex=grade_regex))
# 各文書に対してスコア(yes/no)判定
filtered_docs = []
search = "No" # デフォルトはWeb検索を利用しない
for d in documents:
# SGLangで推論実施。結果はJSON形式の文字列で取得
s = grade_gen.run(
question=question,
context=d.page_content,
temperature=0,
)
grade = json.loads(s.get_var("json_output"))["score"]
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
search = "Yes" # Perform web search
continue
return {
"keys": {
"documents": filtered_docs,
"question": question,
"run_web_search": search,
}
}
transform_query
LLMを使って質問クエリをWeb検索に適したクエリに変換するノード処理の定義です。
こちらもオリジナルのCookbookではOpenAI GPT-4を利用していましたが、SGLang+ローカルLLMでJSON形式の結果を出力するように変更しています。(そのため、変換性能はイマイチです)
def transform_query(state):
"""
クエリをWeb検索に適した形に変換する
Args:
state (dict): 現在のグラフ状態
Returns:
state (dict): クエリを適し形に置き換えたグラフ状態
"""
print("---TRANSFORM QUERY---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# JSONテンプレート
query_regex = (
r"""\{\n"""
+ r""" "improved_query": ".{1,25}"\n"""
+ r"""\}"""
)
@sgl.function
def query_gen(s, question):
template = (
"Provide a better search query for web search engine.\n"
f"Original Query: \n{question}\n\n"
)
s += sgl.user(template)
s += sgl.assistant("Improved Search Query:\n\n" +
sgl.gen(
"json_output", max_tokens=128, frequency_penalty=1.1, regex=query_regex
)
)
s = query_gen.run(
question=question,
temperature=0,
)
better_question = json.loads(s.get_var("json_output"))["improved_query"]
return {"keys": {"documents": documents, "question": better_question}}
web_search
Tavily APIを使って質問クエリからWeb検索結果を取得するノード処理の定義です。
関連文書に加えて、検索結果を状態に追加して返します。
def web_search(state):
"""
Tavily APIを使ったWeb検索の結果を返す
Args:
state (dict): 現在のグラフ状態
Returns:
state (dict): 検索文書にWeb検索結果を追加したグラフ状態
"""
print("---WEB SEARCH---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
tool = TavilySearchResults()
docs = tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"keys": {"documents": documents, "question": question}}
generate
RAGのGであるLLMを使った回答を生成するノード処理の定義です。
オリジナルのCookbookではOpenAI GPT-3.5 turboを利用してものを、ローカルLLMを利用するように変更しています。
ただし、SGLangのOpenAI API互換サーバを利用するため、LangChainのChatOpenAIをそのまま利用しています。
また、プロンプトテンプレートもローカルLLMで正しい回答を得られやすくするために一部オリジナルと比べて変更しています。
def generate(state):
"""
回答を生成する
Args:
state (dict): 現在のグラフ状態
Returns:
state (dict): LLMの回答を追加したグラフ状態
"""
print("---GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# Prompt
prompt = ChatPromptTemplate(
input_variables=["context", "question"],
messages=[
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=["context", "question"],
template=(
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer the question. "
"If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\n"
"Question:\n{question} \n\n"
"Context:\n{context} \n"
),
)
),
AIMessagePromptTemplate.from_template(""),
],
)
# SGLangのOpenAI互換サーバへ接続
llm = ChatOpenAI(
temperature=0,
max_tokens=256,
streaming=False,
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": documents, "question": question})
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}
decide_to_generate
現状のグラフ状態からWeb検索をするかしないかを判定する分岐制御の処理です。
Conditional Edgeとして利用します。
def decide_to_generate(state):
"""
Web検索を実施するかどうかを判定
Args:
state (dict): 現状のグラフ状態
Returns:
str: 決定した次のノード名
"""
print("---DECIDE TO GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
filtered_documents = state_dict["documents"]
search = state_dict["run_web_search"]
if search == "Yes":
# 関連しない文章があったらtransform_queryに遷移
print("---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---")
return "transform_query"
else:
# 関連する文書しかない場合、generateに遷移
print("---DECISION: GENERATE---")
return "generate"
これでノードやエッジ類の定義が完了です。
Step7. グラフの構築
定義したノード用の関数やエッジ用の関数を利用して、LangGraphのグラフを構築します。
グラフのノード/エッジの構成はStep6で示した画像の通りです。
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("transform_query", transform_query)
workflow.add_node("web_search", web_search)
# Build graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search")
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
長かった準備とグラフ構築はこれで完了です。
それでは実行してみましょう!
Step8. CRAGによる推論を実行する
では、推論してみましょう。
準備文書だけで答えれる場合
今回、ベクトルストアに格納した文書に回答が含まれる質問をしてみます。
inputs = {"keys": {"question": "フェルンの師匠は誰?"}}
output = app.invoke(inputs)
print(output["keys"]["generation"])
---RETRIEVE---
---CHECK RELEVANCE---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---DECIDE TO GENERATE---
---DECISION: GENERATE---
---GENERATE---
フェルンの師匠はフリーレンです。
---RETRIEVE---などの出力は各ノード内で出力したテキストです。
今回のクエリで辿った道筋は、
retrieve -> grade_documents -> (decide_to_generate) -> generate
という流れであったことが分かります。
grade_documentsでは3つの文書の判定を行いましたが、全て関連文書として判定されました。
結果としてWeb検索の併用を行う判断にならず、retrieveで取得した文書のみを使って回答生成した、ということになります。
準備文書だけでは答えれない場合
では、ベクトルストアの文書とまったく関係ない内容を質問してみます。
inputs = {"keys": {"question": "Databricksとは何?"}}
output = app.invoke(inputs)
print(output["keys"]["generation"])
---RETRIEVE---
---CHECK RELEVANCE---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---DECIDE TO GENERATE---
---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---
---TRANSFORM QUERY---
---WEB SEARCH---
---GENERATE---
Databricks is a unified, open analytics platform for building, deploying, sharing,
and maintaining enterprise-grade data, analytics, and AI solutions at scale.
It integrates with cloud storage and security in your cloud account and manages
and deploys cloud infrastructure on your behalf.
Databricks is designed to simplify the process of building big data and artificial
intelligence (AI) solutions and is used for deriving valuable insights from
data to make informed business decisions.
今回のクエリで辿った道筋は、
retrieve -> grade_documents -> (decide_to_generate) -> transform_query -> web_search -> generate
という流れでした。
retrieveで取得した文書はどれも「関連なし」と判断され、その結果としてWeb検索のルートになるように分岐判定されています。結果として、今回の回答はWeb検索の結果のみを使って回答されました。
このように、CRAGではベクトルストアに格納したドメイン知識だけで答えれない状況かどうかを自己判定し、ナレッジの品質をあげるアクションを取るということができます。
拡張を考えると、これでも十分な関連文書を取得できない場合の処理や、モデレーション・エラーハンドリングなどもノードとして組み込めば、さらに実用的なフローが組めると思います。
まとめ
Slef-Reflective RAGのうち、CRAGを実践してみました。
基本的にはCRAGのCookbookのウォークスルーではありますが、無駄にローカルLLMを使う方向でこだわってみました。
個人的に今回のようなRAG処理はかなり実用的な気がしています。
「まずは業務文書から検索して、その中に無かったらWeb検索したものから回答して」というニーズが結構多いと思うためです。
LangChainのLCELだけだと、ここまでの制御を柔軟にやるのは結構面倒という認識なのですが、LangGraphとの組み合わせで拡張性を保ったまま処理を構築できたのはとても興味深かったです。
継続的に試したり、これを活かしたアプリ構築などしてみたいと思います。