導入
私が学ぶRAGの実質1回目です。
まずはベーシックなRAGを実践します。
主に以下の内容をベースにしています。
LangChainのDocでは、RAGを以下のような流れで説明しています。
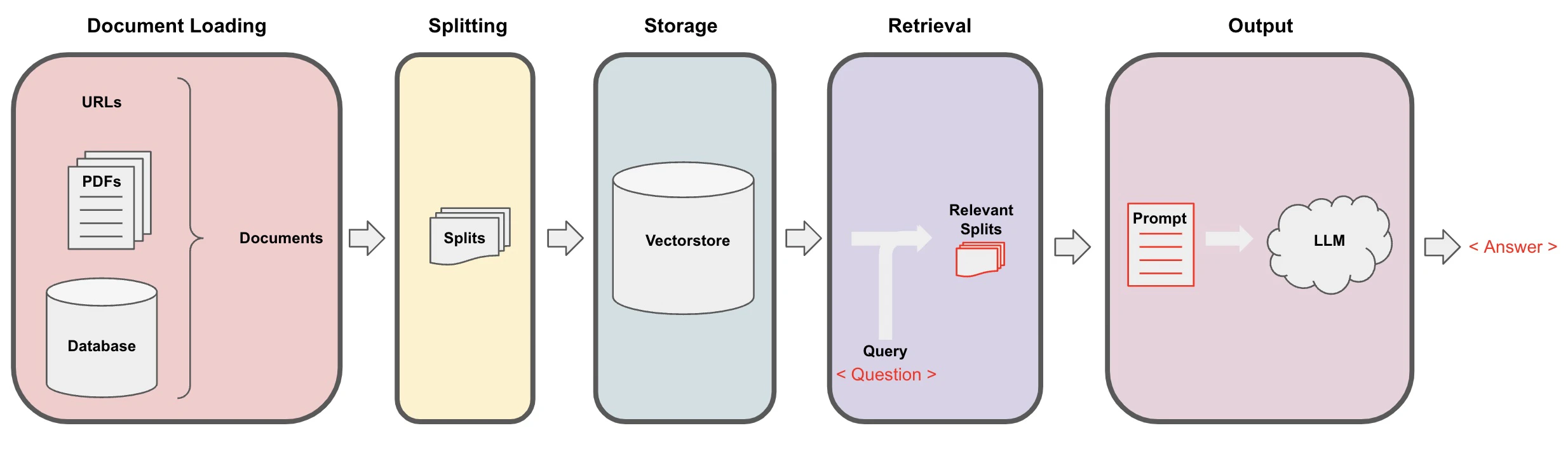
この流れに沿って実践していきます。
Step0. モジュールインストール
今後、使うモジュールをインストールします。
%pip install -U -qq transformers accelerate autoawq=="0.1.5" langchain faiss-cpu
%pip install databricks-feature-engineering
dbutils.library.restartPython()
Step1. Document Loading
準備編で保管した特徴量を取得します。
読み込んだデータは、docsという名前のビューから参照できるようにします。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
feature_name = "training.llm.sample_doc_features"
df = fe.read_table(name=feature_name)
df.createOrReplaceTempView("docs")
Step2. Splitting
ごくごく単純なText Splitterを使って長文データをチャンキングします。
今回は40文字をオーバーラップし、200文字のチャンクを作ることにしました。
langchain標準のRecursiveCharacterTextSplitterだと日本語的な文字で分割してくれないため、
句読点を区切り文字に追加したTextSplitterを作って対応しています。
チャンキング処理はSparkのUDFを使って実行しました。
(1行しかデータが無いので、今回はあまり有用ではありませんが。。。)
from typing import Any
import pandas as pd
from pyspark.sql.functions import pandas_udf
from langchain.text_splitter import RecursiveCharacterTextSplitter
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""句読点も句切り文字に含めるようにするためのスプリッタ"""
def __init__(self, **kwargs: Any):
separators = ["\n\n", "\n", "。", "、", " ", ""]
super().__init__(separators=separators, **kwargs)
@pandas_udf("array<string>")
def split_text(texts: pd.Series) -> pd.Series:
# 適当なサイズとオーバーラップでチャンク分割する
text_splitter = JapaneseCharacterTextSplitter(chunk_size=200, chunk_overlap=40)
return texts.map(lambda x: text_splitter.split_text(x))
# チャンキング
df = spark.table("docs")
df = df.withColumn("chunk", split_text("page_content"))
# Pandas Dataframeに変換し、チャンクのリストデータを取得
pdf = df.select("chunk").toPandas()
texts = list(pdf["chunk"][0])
Step3. Storage
チャンクデータに埋め込み(Embedding)を行い、ベクトルストアへデータを保管します。
まずはEmbedding用のモデルをロード。
以下のモデルをダウンロードしたものを利用します。
import torch
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
device = "cuda" if torch.cuda.is_available() else "cpu"
# ダウンロード済みモデルのパス
embedding_path = "/Volumes/training/llm/model_snapshots/models--intfloat--multilingual-e5-large"
embedding = HuggingFaceEmbeddings(
model_name=embedding_path,
model_kwargs={"device": device},
)
FAISSでベクトルストアを作成し、Retriverを取得します。
今回は3件の類似データを取得するようにしました。
vectorstore = FAISS.from_texts(texts, embedding)
retriever = vectorstore.as_retriever(search_kwargs={"k":3})
テストしてみます。
# サンプル
retriever.get_relevant_documents("この契約において知的財産権はどのような扱いなのか?")
[Document(page_content='納入物の改良・改変をはじめとして、あらゆる使用(利用)態様を含む 。また、本契約\nにおいて「知的財産権」とは、知的財産基本法第2条第2項所定の知的財産権をいい、\n知的財産権を受ける権利及びノウハウその他の秘密情報を含む。 \n2 乙は、 納入物に第三者の知的財産権を利用する場合には、 第1条第2項 の規定に従い、\n乙の費用及び責任において当該第三者から本契約の履行及び本契約終了後の甲による'),
Document(page_content='(契約保証金) \n第3条 甲は、本契約に係る乙が納付すべき契約保証金の納付を全額免除する。 \n \n (知的財産 権の帰属及び 使用) \n第4条 本契約の締結時に乙が既に所有又は管理していた 知的財産権(以下「 乙知的財産\n権」という。)を 乙が納入物に使用した場合には、甲は、当該乙知的財産権を、仕様書\n記載の「目的」のため、仕様書の「納入物」の項 に記載した利用方法に従い、本契約終'),
Document(page_content='が所有し、又は管理する知的財産権の実施許諾や動産・不動産の使用許可の取得等を含\nむ。)が必要な場合には乙の費用及び責任で行うものとする。 甲の指示により、委託者\n名を明示して業務を行う場合も同様とする。 \n3 甲は、委託業務及び納入物に関して、約定の委託金額以外の支払義務を負わない。 本\n契約終了後の納入物の利用についても同様とする。 委託金額には委託業務の遂行に必要')]
Step4. Chain creation
RAGを実行するChainを作成します。
まずは構成要素を準備していきます。
Prompt Template
簡単なチャットテンプレートを準備。
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import (
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
template = """次のcontextの内容のみを使い、なるべく平易な文章を使って日本語で質問に回答してください。
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template(template),
AIMessagePromptTemplate.from_template(""),
]
)
LLM
こちらの記事で作成したCyberAgent社のCALM2 Chatを使います。
が、HuggingFace Transformersで読めるモデルであれば同様に利用できると思います。
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers_chat import ChatHuggingFaceModel
model_path = "/Volumes/training/llm/model_snapshots/models--local--cyberagent-calm2-7b-chat-AWQ-calib-ja-1k"
generator = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
chat_model = ChatHuggingFaceModel(
generator=generator,
tokenizer=tokenizer,
human_message_template="USER: {}\n",
ai_message_template="ASSISTANT: {}",
temperature=0.1,
max_new_tokens=1024,
)
Chain
これまで作成した構成要素を組み合わせてChainを作成します。
最近のlangchainはLangChain Expression Language (LCEL)の利用が推奨されており、こちらで記載します。
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser()
)
Step5. Run
準備は整いましたので、実行してみます。
chain.invokeでも実行できますが、ストリーミング出力させてみます。
for s in chain.stream("この契約において知的財産権はどのような扱いなのか?"):
print(s, end="", flush=True)
この契約において、知的財産権は以下のように扱われます。
まず、納入物の改良・改変を含むあらゆる使用態様を含むと規定されています。また、本契約において「知的財産権」とは、知的財産基本法第2条第2項に規定する知的財産権を指し、知的財産権を受ける権利及びノウハウその他の秘密情報を含むとされています。
次に、乙が納入物に第三者の知的財産権を利用する場合には、第1条第2項の規定に従い、乙の費用及び責任において当該第三者から本契約の履行及び本契約終了後の甲による使用権の取得等が必要であるとされています。
また、甲は、乙が既に所有又は管理していた知的財産権(以下「乙知的財産権」という。)を納入物に使用した場合には、当該乙知的財産権を、仕様書記載の「目的」のため、仕様書の「納入物」の項に規定した利用方法に従い、本契約終了後も所有し、又は管理する知的財産権の実施許諾や動産・不動産の使用許可の取得等を含むと規定されています。
したがって、この契約においては、納入物の改良・改変や第三者の知的財産権の利用について、知的財産権に関する規定が設けられています。
内容の確からしさは確認していませんが、それなりに妥当な感じで回答してくれています。
まとめ
まずは基本、ということでベーシックなRAGの実装でした。
よりシンプルなサンプルがLangchain Templateの中にも公開されています。
次はParent Document Retrieverを使ったRAGを実践予定。