導入
RAG(Retrieval Augmented Generation)はLLM活用において重要なテクニックであり、一般的には非構造化ファイルを読み込んでテキスト化、チャンク処理等を行って埋め込みモデルを使ってベクトル化という流れがよく使われます。
(最近はマルチモーダル用に画像としての取込もよく実施されていますが)
この一連の流れ、Databricksを使ったら効率的かつ楽に増分処理のパイプライン構築ができるんじゃないかと思い、実際にやってみました。
今回はPDFファイル、Word(docx)、PowerPoint(pptx)の3種のファイルに対応した処理を組みます。
流れとしては以下のようになります。
構築環境はDatabricks on AWS、クラスタはサーバレスです。
Step1. データ準備
サンプルとして取り込むデータを用意します。
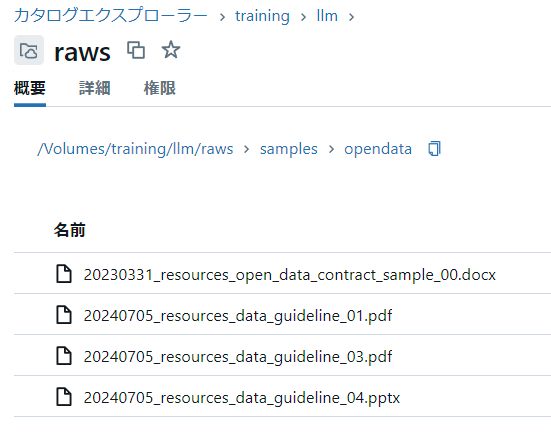
今回はデジタル庁のオープンデータサイトから、オープンデータ基本指針などのPDF、PowerPoint、Wordファイルをいくつか取得し、Databricks Unity Catalog Volumesに保管します。
今回は/Volumes/training/llm/raws/samplesという場所にボリューム作成およびファイルを保管しました。
Step2. 環境セットアップ
ノートブックを作成し必要なパッケージをインストールします。
本当はunstructuredを使おうとしたのですが、SparkのStreaming処理が完了しないなどうまくいかなかったので、ファイル種別ごとに異なるパッケージを利用します。パッケージの詳細は処理部分で補足します。
%pip install -q magika pymupdf4llm docx2txt python-pptx pptx2txt2
%pip install -q -U langchain_core langchain_text_splitters
dbutils.library.restartPython()
各種パラメータをウィジットを使って定義します。
主にファイルの保管場所パスや、テキスト化したデータの保管先テーブル名などを変数として格納しています。
import os.path
dbutils.widgets.text("catalog", "training")
catalog = dbutils.widgets.get("catalog")
dbutils.widgets.text("schema", "llm")
schema = dbutils.widgets.get("schema")
dbutils.widgets.text("raw_table", "sample_documents_raw")
raw_table = dbutils.widgets.get("raw_table")
dbutils.widgets.text("text_table", "sample_documents_text")
text_table = dbutils.widgets.get("text_table")
dbutils.widgets.text("chunked_table", "sample_documents_chunked")
chunked_table = dbutils.widgets.get("chunked_table")
dbutils.widgets.text("raw_data_path", "/Volumes/training/llm/raws/samples")
raw_data_path = dbutils.widgets.get("raw_data_path")
dbutils.widgets.text(
"checkpoint_path", "/Volumes/training/llm/delta/samples/checkpoint"
)
checkpoint_path = dbutils.widgets.get("checkpoint_path")
print("Raw Table:", catalog, schema, raw_table)
print("Text Table:", catalog, schema, text_table)
print("Chunk Table:", catalog, schema, chunked_table)
print("-" * 50)
print("Raw Data Path:", raw_data_path)
print("Checkpoint Path:", checkpoint_path)
Step3. 処理①:ドキュメントファイルの取込
Databricks Auto Loaderを使って各文書ファイルをバイナリデータとして取り込みテーブルに保管します。
Auto Loaderを使うことで、ボリュームにファイルが追加で置かれた際に新規ファイルだけ増分取り込みができます。また、テーブルとしてデータを取り込むことで、今後Spark上でこれらのデータを容易に扱うことができるようになります。
(
# Databricks Autoloaderを使って増分ファイル取込
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "binaryFile")
.option("pathGlobFilter", "{*.pdf,*.docx,*.pptx}")
.option("recursiveFileLookup", "true")
.load(raw_data_path)
.writeStream.option("checkpointLocation", os.path.join(checkpoint_path, raw_table))
.trigger(availableNow=True)
.toTable(f"{catalog}.{schema}.{raw_table}")
.awaitTermination()
)
以下のような形で保管されます。

Step4. 処理②:ドキュメントファイルの取込
処理①で取り込んだバイナリ形式の文書データからテキストデータを抽出します。
そのためのUDFをまずは定義。
処理としては最初にファイル種別判定を行い、ファイル種別ごとにテキスト化処理を使い分けています。
ファイル種別判定にはGoogleが公開しているmagikaを使用。
各文書のパースでは、以下のパッケージを利用しました。
- PDF:PyMuPDF4LLM
- Word(docx):doc2txt
- PowerPoint(pptx):pptx2txt2
Unstructuredが使えるともっと多様なファイルへの対応がより容易にできるかと思います。
from pyspark.sql.functions import udf
import pyspark.sql.functions as F
import io
@udf("string")
def identify_file_type(content):
""" ファイル種別の判別 """
from magika import Magika
m = Magika()
res = m.identify_bytes(content)
return str(res.output.ct_label)
@udf("string")
def parse_pdf_to_txt(content):
""" PDFファイルをテキストに変換 """
import pymupdf4llm
import pymupdf
import io
try:
doc = pymupdf.open(stream=io.BytesIO(content), filetype="pdf")
md_text = pymupdf4llm.to_markdown(doc)
return md_text
except:
# 例外時はひとまずNoneを返す。ちゃんと実装することをお薦め。
return None
@udf("string")
def parse_docx_to_txt(content):
""" DOCXファイルをテキストに変換 """
import docx2txt
try:
return docx2txt.process(io.BytesIO(content))
except:
# 例外時はひとまずNoneを返す。ちゃんと実装することをお薦め。
return None
@udf("string")
def parse_pptx_to_txt(content):
""" PPTXファイルをテキストに変換 """
import pptx2txt2
import io
try:
# text = pptx2txt2.extract_text(io.BytesIO(content))
texts = pptx2txt2.extract_text_per_slide(io.BytesIO(content))
return "\n\n".join(texts.values())
except:
# ひとまずNoneを返す
return None
定義したUDFを使って文書データからテキストを抽出し、テーブルへ保管します。
(
spark.readStream.table(f"{catalog}.{schema}.{raw_table}")
# ファイル種別の判別
.withColumn("file_type", identify_file_type("content"))
# 種別に則ったテキストデータのパース
.withColumn(
"text",
F.when(F.col("file_type") == "pdf", parse_pdf_to_txt("content"))
.when(F.col("file_type") == "docx", parse_docx_to_txt("content"))
.when(F.col("file_type") == "pptx", parse_pptx_to_txt("content"))
.otherwise(None),
)
.writeStream.option("checkpointLocation", os.path.join(checkpoint_path, text_table))
.trigger(availableNow=True)
.toTable(f"{catalog}.{schema}.{text_table}")
.awaitTermination()
)
以下のような形で保管されます。

Step5. 処理③:チャンキング
このままでは大きなテキストデータの塊で保管されているため、適切なサイズでチャンキングします。
今回はLangChainのText Splitterを使って単純なチャンキングを行いました。
まずはチャンク分割用のUDFを作成。
from pyspark.sql.functions import pandas_udf
import pandas as pd
@udf("array<string>")
def split_to_chunks(text):
"""テキストをチャンキング"""
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing import Any
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""日本語用のTextSplitter。句読点も句切り文字に含める
参考:https://www.sato-susumu.com/entry/2023/04/30/131338
"""
def __init__(self, **kwargs: Any):
separators = [
"\n\n",
"\n",
"。",
"、",
" ",
"",
"#",
"##",
"###",
"```\n\n-----\n\n```",
]
super().__init__(separators=separators, **kwargs)
text_splitter = JapaneseCharacterTextSplitter(chunk_size=400, chunk_overlap=100)
return text_splitter.split_text(text)
@pandas_udf("string")
def extract_dirname(paths: pd.Series) -> pd.Series:
"""パスからディレクトリ名を抽出"""
return paths.apply(lambda x: os.path.basename(os.path.dirname(x)))
UDFを使ってテキストをチャンクに分割・保管します。
今後のベクトル化に向けてユニークなIDを自動生成したかったため、IDを自動採番するテーブルを事前に作成し、そこにデータを書き込むようにしています。
import pyspark.sql.functions as F
## 先にテーブルを作成。IDを自動生成し、CDCが有効になるように作成
create_tbl_sql = f"""
CREATE TABLE IF NOT EXISTS {f"{catalog}.{schema}.{chunked_table}"} (
path string,
dir string,
modificationTime timestamp,
length bigint,
file_type string,
chunk string,
id bigint GENERATED BY DEFAULT AS IDENTITY NOT NULL,
CONSTRAINT t_pk PRIMARY KEY(id)
) TBLPROPERTIES ('delta.enableChangeDataFeed' = 'true')
"""
spark.sql(create_tbl_sql)
## ストリームで書き込み
(
spark.readStream.table(f"{catalog}.{schema}.{text_table}")
# チャンキング
.withColumn("dir", extract_dirname("path"))
.withColumn("chunk", split_to_chunks("text"))
.withColumn("chunk", F.explode("chunk"))
# 不要列の除去
.drop("content", "text")
.writeStream.option(
"checkpointLocation", os.path.join(checkpoint_path, chunked_table)
)
.trigger(availableNow=True)
.toTable(f"{catalog}.{schema}.{chunked_table}")
.awaitTermination()
)
以下のように、チャンク単位のレコードを保持しユニークなIDを持つテーブルができました。

Step6. インデックス作成
チャンクデータを使って、ベクトル検索用のインデックスを作成します。
Mosaic AI Vector Searchを使って実現します。
基本的には以前記事で書いたこちらの内容と同様です。
利便性のために別のノートブックを作成し、databricks-vectorsearchパッケージを最新化。
また、インデックスの保管先やVector Search用エンドポイント名などのパラメータをウィジットから取得します。
%pip install -U -q databricks-vectorsearch
dbutils.library.restartPython()
dbutils.widgets.text("catalog", "training")
catalog = dbutils.widgets.get("catalog")
dbutils.widgets.text("schema", "llm")
schema = dbutils.widgets.get("schema")
dbutils.widgets.text("src_chunk_table", "sample_documents_chunked")
src_chunk_table = dbutils.widgets.get("src_chunk_table")
dbutils.widgets.text("id_column", "id")
id_column = dbutils.widgets.get("id_column")
dbutils.widgets.text("chunk_column", "chunk")
chunk_column = dbutils.widgets.get("chunk_column")
dbutils.widgets.text("vector_search_endpoint", "default_vector_search_endpoint")
vector_search_endpoint = dbutils.widgets.get("vector_search_endpoint")
dbutils.widgets.text("vector_search_index", "sample_documents_index")
vector_search_index = dbutils.widgets.get("vector_search_index")
dbutils.widgets.text("embedding_endpoint", "embedding_bge_m3_endpoint")
embedding_endpoint = dbutils.widgets.get("embedding_endpoint")
dbutils.widgets.text("embedding_dimensions", "1024")
embedding_dimensions = int(dbutils.widgets.get("embedding_dimensions"))
print("Source Chunked Table:", catalog, schema, src_chunk_table)
print("ID Column:", id_column)
print("Chunk Column:", chunk_column)
print("Vector Search Index:", catalog, schema, vector_search_index)
print("Vector Search Endpoint:", vector_search_endpoint)
print("Embedding Endpoint:", embedding_endpoint)
print("Embedding Dimensions:", embedding_dimensions)
Mosaic AI Vector Searchを使ってインデックスを作成。
import time
from databricks.vector_search.client import VectorSearchClient
def index_exists(vsc, endpoint_name, index_full_name):
try:
vsc.get_index(endpoint_name, index_full_name).describe()
return True
except Exception as e:
if "RESOURCE_DOES_NOT_EXIST" not in str(e):
print(
f"Unexpected error describing the index. This could be a permission issue."
)
raise e
return False
def wait_for_index_to_be_ready(vsc, vs_endpoint_name, index_name):
for i in range(180):
idx = vsc.get_index(vs_endpoint_name, index_name).describe()
index_status = idx.get("status", idx.get("index_status", {}))
status = index_status.get(
"detailed_state", index_status.get("status", "UNKNOWN")
).upper()
url = index_status.get("index_url", index_status.get("url", "UNKNOWN"))
if "ONLINE" in status:
return
if "UNKNOWN" in status:
print(
f"Can't get the status - will assume index is ready {idx} - url: {url}"
)
return
elif "PROVISIONING" in status:
if i % 40 == 0:
print(
f"Waiting for index to be ready, this can take a few min... {index_status} - pipeline url:{url}"
)
time.sleep(10)
else:
raise Exception(
f"""Error with the index - this shouldn't happen. DLT pipeline might have been killed.\n Please delete it and re-run the previous cell: vsc.delete_index("{index_name}, {vs_endpoint_name}") \nIndex details: {idx}"""
)
raise Exception(
f"Timeout, your index isn't ready yet: {vsc.get_index(index_name, vs_endpoint_name)}"
)
# インデックス作成
vsc = VectorSearchClient()
full_source_table_name = f"{catalog}.{schema}.{src_chunk_table}"
full_index_name = f"{catalog}.{schema}.{vector_search_index}"
if not index_exists(vsc, vector_search_endpoint, full_index_name):
print(f"Creating index {full_index_name} on endpoint {vector_search_endpoint}...")
index = vsc.create_delta_sync_index(
endpoint_name=vector_search_endpoint,
source_table_name=full_source_table_name,
index_name=full_index_name,
pipeline_type="TRIGGERED",
primary_key=id_column,
embedding_dimension=embedding_dimensions,
embedding_source_column=chunk_column,
embedding_model_endpoint_name=embedding_endpoint,
)
wait_for_index_to_be_ready(vsc, vector_search_endpoint, full_index_name)
else:
# Vector Searchのコンテンツを更新し、新規データを保存するように同期処理を起動
wait_for_index_to_be_ready(vsc, vector_search_endpoint, full_index_name)
vsc.get_index(vector_search_endpoint, full_index_name).sync()
print(f"index {full_index_name} on table {full_source_table_name} is ready")
これでチャンクデータテーブルと同期するインデックステーブルが作られます。
実際に検索できるか試してみます。
import pandas as pd
from databricks.vector_search.client import VectorSearchClient
def conv_related_docs_to_pdf(result):
cols = [c["name"] for c in result["manifest"]["columns"]]
return pd.DataFrame(result["result"]["data_array"], columns=cols)
vsc = VectorSearchClient()
full_index_name = f"{catalog}.{schema}.{vector_search_index}"
index = vsc.get_index(endpoint_name=vector_search_endpoint, index_name=full_index_name)
result = index.similarity_search(
query_text="オープンデータの意義を教えて",
columns=[id_column, chunk_column, "path", "dir", "file_type"],
num_results=5,
)
display(conv_related_docs_to_pdf(result))

検索自体は出来ています。
せっかくなので、ファイル種別やフォルダ名などでフィルタをしてみましょう。
result = index.similarity_search(
query_text="オープンデータの意義を教えて",
columns=[id_column, chunk_column, "path", "dir", "file_type"],
num_results=5,
filters={"dir": "opendata", "file_type": "pptx"},
query_type="HYBRID",
)
display(conv_related_docs_to_pdf(result))

ファイル種別がpptxのみから検索が実行されました。いろいろコントロールできそうですね。
Step7. ワークフロー化する
実運用を想定する場合、ファイルが新規にアップされたらその分だけ自動的にインデックス作成まで実行されると便利です。
Databricksのワークフロー機能を使うとこのあたり簡単に実装できます。
(各種パラメータをウィジットから取得するようにしていたのはワークフロー活用を想定していたため)
まず、ワークフローからジョブを作成し、上記二つのノートブックを実行するジョブを作成します。
※ クラスタはサーバレスでOK。便利になりました。

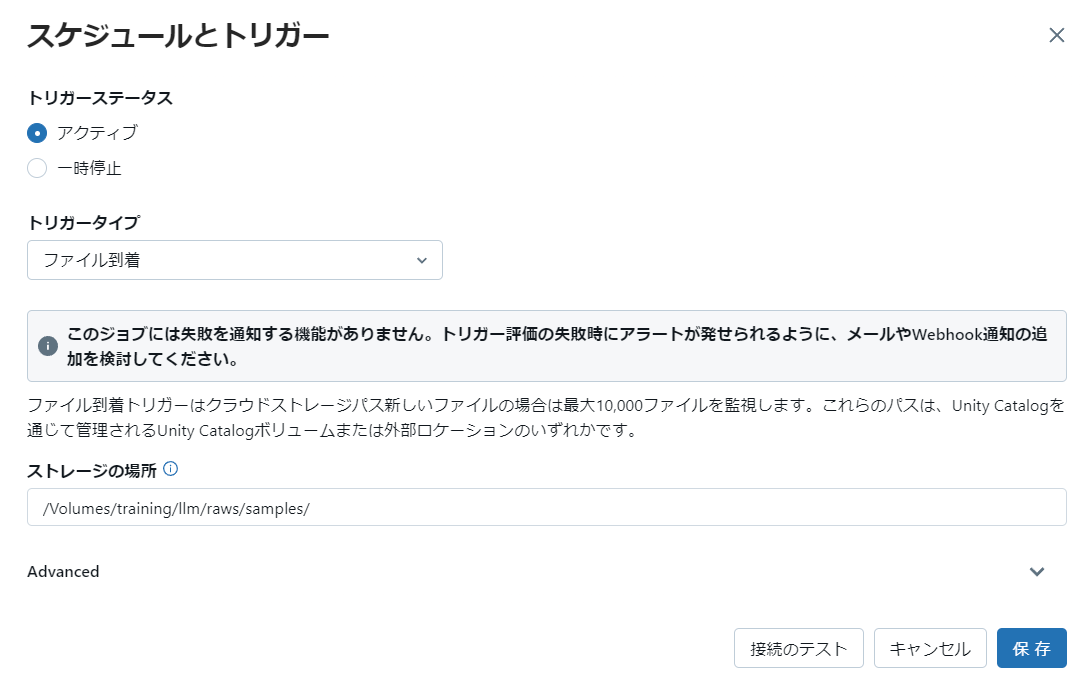
その上でジョブのトリガーとして「ファイル到着」を設定。
ファイルの置き場所にしているUnity Catalog Volumesの場所を指定します。
これで、該当の場所に新たな文書ファイルを置くと自動的にファイルを取り込んでインデックス作成まで実行されるようになります。
高いリアルタイム性が求められる場合は別の工夫が必要ですが、そこまで必要ではない場合はこれで十分なケースも多いのではないかと思います。
まとめ
Databricksを使ったRAG用ドキュメントロードパイプラインを簡易実装してみました。
比較的少ない記述量で最低限のパイプライン実装ができたのではないかと思います。
その他Delta Live Tablesを使うなど、改善の余地は多量にあるので時間あればもう少しちゃんと作って見たいと思います。
しかしDatabricksやSpark使うと本当にデータパイプラインは効率的かつ堅牢に作れますね。
サーバレス機能も拡充されてより時間効率向上やコスト最適が進みありがたい限りです。
参考記事