導入
私が学ぶRAGの実質7回目です。シリーズ一覧はこちら。
今回は半構造化データに対するRAGの実践です。
これは何?
Langchainの下記Blog内 Semi-Structured Data のセクションで解説されています。
ざっくり邦訳+図を掲載。
非構造化ファイルの構文解析とマルチベクトル検索を組み合わせることで、半構造化データのRAGをサポートすることができます。テーブル要素の要約を生成し、自然言語検索により適しています。
もしテーブルの要約がユーザーの質問に対して意味的類似性によって検索された場合、生のテーブルは上記のように回答合成のためにLLMに渡されます。
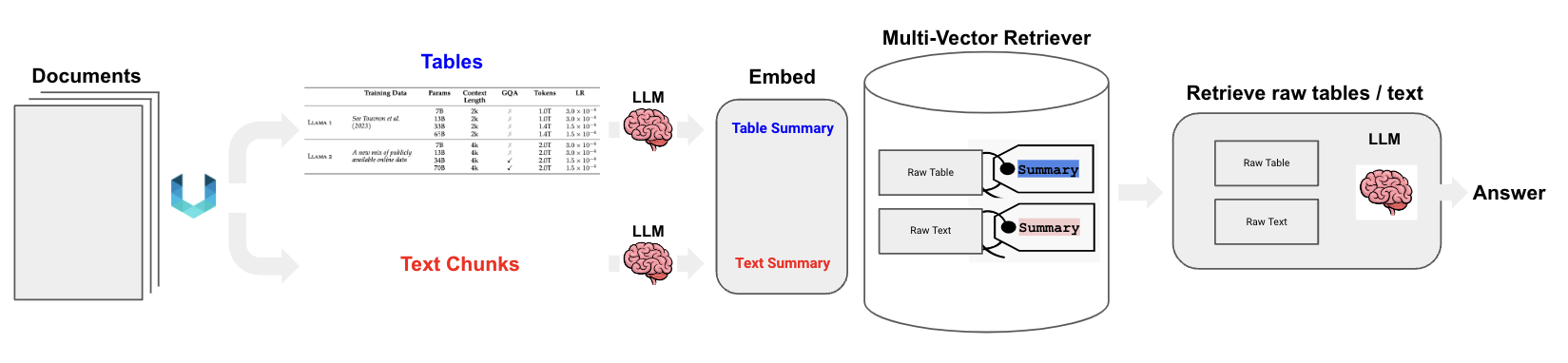
図中にあるように、例えばPDFデータを対象にRAGを実現しようとする場合、表なども含まれています。
表はそのままに扱わなければ十分意味をもった情報となりませんが、単純にテキスト化してチャンクにすると意味を失ってしまいます。
このようなケースにおいて、表は表のままに検索できるように、LLMに渡す必要があります。
LangchainのMulti-Vector Retrieverは、これを実現するために、「表に対しては、サマリした検索用の情報を生成し、それに対してベクトル検索させる。LLMに与える情報はサマリ元である表情報を渡す」ということを実現しています。
というわけで実践してみましょう。
今回は非常に長くなってしまったので2回に分割します。
この記事では要約含めた特徴量データを保管するところまで実施します。
なお、今回の内容は、以下のLangchain Templatesの内容を参考に実践します。
https://python.langchain.com/docs/templates/rag-semi-structured
DatabricksのDBRは14.1 ML、GPUクラスタで動作を確認しています。
Step0. Package Install
今回はUnstructuredというpythonパッケージを使用します。
このパッケージを使うために必要な外部ライブラリを最初にインストールします。
tesseractを使えるようにするために、aptのリポジトリに追加。
%sh add-apt-repository ppa:alex-p/tesseract-ocr5 && apt update
tesseract等必要なライブラリをaptからインストール。
%sh apt install -y libmagic-dev tesseract-ocr libtesseract-dev tesseract-ocr-jpn tesseract-ocr-jpn-vert tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert poppler-data
popplerがうまくubuntuのapt上でインストールできなかったので、Debianのパッケージファイルをダウンロードして直接インストール。
%sh wget http://security.ubuntu.com/ubuntu/pool/main/p/poppler/libpoppler118_22.02.0-2ubuntu0.3_amd64.deb -P /tmp/pkg/ && \
wget http://security.ubuntu.com/ubuntu/pool/main/p/poppler/poppler-utils_22.02.0-2ubuntu0.3_amd64.deb -P /tmp/pkg/ && \
wget http://security.ubuntu.com/ubuntu/pool/main/p/poppler/libpoppler-dev_22.02.0-2ubuntu0.3_amd64.deb -P /tmp/pkg/ && \
dpkg -i /tmp/pkg/libpoppler118_22.02.0-2ubuntu0.3_amd64.deb /tmp/pkg/poppler-utils_22.02.0-2ubuntu0.3_amd64.deb /tmp/pkg/libpoppler-dev_22.02.0-2ubuntu0.3_amd64.deb
tesseractで日本語データを扱えるようにするためのファイルをダウンロード。
%sh wget -P /usr/share/tesseract-ocr/4.00/tessdata https://github.com/tesseract-ocr/tessdata/raw/4.00/jpn.traineddata
最後に、pipから必要なパッケージをインストール。
%pip install -U -qq transformers accelerate langchain langchainhub faiss-cpu unstructured[all-docs]
# CUDA 11.8用
%pip install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.7/autoawq-0.1.7+cu118-cp310-cp310-linux_x86_64.whl
%pip install "databricks-feature-engineering"
dbutils.library.restartPython()
LLMはこのシリーズで共通のAWQ量子化フォーマットのファイルをTransformersで読み込みます。
そのためにAutoAWQをインストールしていますが、AutoAWQはCUDA 11.8版をWheelを指定してインストールしています。
(DatabricksのDBR ML 14台はCUDAのバージョンが11.8のため)
Step1. Document Loading
今回は準備編で保管したデータは使わず、PDFファイルを最初から取り込みなおします。
まず、以下のサイトに掲載されている「①令和5年度概算契約書」のPDFファイルをダウンロード。
# PDFファイルをローカルにダウンロード
import os
import requests
pdf_url = "https://www.meti.go.jp/information_2/downloadfiles/r5gaisan-2_format.pdf"
local_dir = "/tmp/unstructured/pdf/"
local_path = local_dir + "r5gaisan-2_format.pdf"
resp = requests.get(pdf_url)
if not os.path.exists(local_dir):
os.makedirs(local_dir)
with open(local_path, "wb") as f:
f.write(resp.content)
Unstructuredを使ってPDFファイルを取り込みます。
import os
from unstructured.partition.pdf import partition_pdf
# tesseractの設定
os.environ["TESSDATA_PREFIX"] = "/usr/share/tesseract-ocr/4.00/tessdata"
raw_pdf_elements = partition_pdf(
filename=local_path,
extract_images_in_pdf=False,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path="/tmp/unstructured/images/",
languages=["jpn"],
)
これで、PDFファイルが読み込まれました。
取り込まれたデータはElementというチャンク化したデータの情報を含んだリストになります。
Step2. Conver to DataFrame
このままでは取り扱いづらいので、DataFrame形式に変換します。
import pyspark.sql.functions as F
from unstructured.documents.elements import Title, NarrativeText
from unstructured.staging.base import convert_to_dataframe
# idをUUID化
for r in raw_pdf_elements:
r.id_to_uuid()
# Pandasデータフレームへ変換
pdf = convert_to_dataframe(raw_pdf_elements)
# 対象を最低限に絞る
pdf = pdf[["element_id", "type", "text", "page_number", "filename"]]
# Spark DataFrameへ変換
df = spark.createDataFrame(pdf)
# ノイズ文字を簡易除去
df = df.withColumn("text", F.regexp_replace(F.col("text"), "R5-G-2\n", ""))
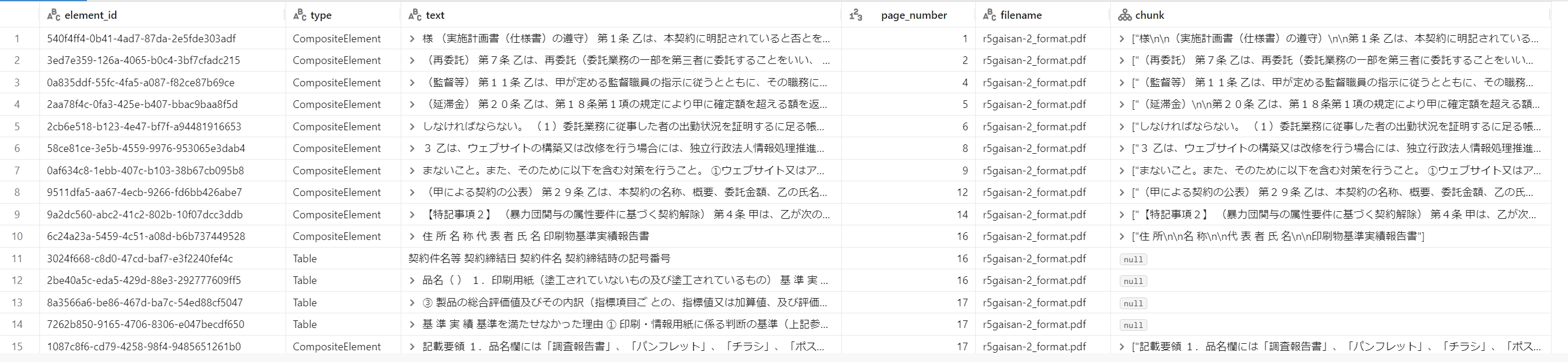
display(df)
df.createOrReplaceTempView("doc")
出力結果は次のようになります。

typeがTableのデータが、PDFに含まれる表データを取り込んだデータです。
取込処理自体が結構時間がかかるため、一旦特徴量テーブルに保管しておきます。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
feature_name = "training.llm.sample_doc_features2"
df = spark.table("doc")
doc_table = fe.create_table(
name=feature_name,
primary_keys="element_id",
schema=df.schema,
description="Unstructured PDF Data",
)
fe.write_table(name=feature_name, df=df, mode="merge")
Step3. Chunking
保管したデータを読み直し、まずは通常のテキストデータをチャンキングします。
Unstructuredで読み込んだ時点でチャンキングはしているのですが、検索性能が上がるかなと思い、もう少し割ってみました。
チャンキング自体はこれまでと同様、シンプルなやり方で分割しています。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
feature_name = "training.llm.sample_doc_features2"
df = fe.read_table(name=feature_name)
df.createOrReplaceTempView("feature_doc")
from typing import Any
import pandas as pd
import pyspark.sql.functions as F
from pyspark.sql.functions import pandas_udf
from langchain.text_splitter import RecursiveCharacterTextSplitter
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""句読点も句切り文字に含めるようにするためのスプリッタ"""
def __init__(self, **kwargs: Any):
separators = ["\n\n", "\n", "。", "、", " ", ""]
super().__init__(separators=separators, **kwargs)
@pandas_udf("array<string>")
def split_text(texts: pd.Series) -> pd.Series:
# 適当なサイズとオーバーラップでチャンク分割する
text_splitter = JapaneseCharacterTextSplitter(chunk_size=200, chunk_overlap=40)
return texts.map(lambda x: text_splitter.split_text(x))
# type=CompositeElementのみチャンキング
df = spark.table("feature_doc")
df = df.withColumn("chunk", F.when(F.col("type") == F.lit('CompositeElement'), split_text("text")))
display(df)
df = df.cache()
df.createOrReplaceTempView("chunked_doc")
Step4. Summarize Table Data
type=="Table"の表データからサマリテキストを生成します。
サマリの生成はLLMに実施させます。モデルは前回同様OpenChat 3.5を利用しました。
また、今回はSpark上で処理させるためにpandas_udfで実装しましたが、今回のボリュームでは一度Pandas Dataframe化して処理する方が速いと思います。
import pyspark.sql.functions as F
import pandas as pd
@pandas_udf("string")
def summarize_texts(texts: pd.Series) -> pd.Series:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers_chat import ChatHuggingFaceModel
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import (
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
model_path = "/Volumes/training/llm/model_snapshots/models--TheBloke--openchat_3.5-AWQ"
generator = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. Table or text chunk: {element} """
summarize_prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template(prompt_text),
AIMessagePromptTemplate.from_template(""),
]
)
summarize_model = ChatHuggingFaceModel(
generator=generator,
tokenizer=tokenizer,
human_message_template="GPT4 Correct User: {}<|end_of_turn|>",
ai_message_template="GPT4 Correct Assistant: {}",
repetition_penalty=1.2,
temperature=0.1,
max_new_tokens=2048,
)
summarize_chain = {"element": lambda x: x} | summarize_prompt | summarize_model | StrOutputParser()
texts = list(texts)
results = summarize_chain.batch(texts, {"max_concurrency": 2})
return pd.Series(results)
df = spark.table("chunked_doc")
df = df.repartition(1)
df = df.withColumn("table_summary", F.when(F.col("type") == "Table", summarize_texts("text")))
df = df.cache()
display(df)
df.createOrReplaceTempView("summarized_doc")
以下のように、table_summaryという表データのサマリデータ列を追加しました。

Step5. Save as Features
加工データをDatabricksの特徴量テーブルとして保管。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
feature_name = "training.llm.sample_doc_features3"
df = spark.table("summarized_doc")
doc_table = fe.create_table(
name=feature_name,
primary_keys="element_id",
schema=df.schema,
description="Unstructured PDF Data2",
)
fe.write_table(name=feature_name, df=df, mode="merge")
これでRAGに使えるデータ生成が完了しました。
まとめ
次回に続きます。