Databricks/MLflow共にAgentを定義・普及させる方向に進化してきてる感。
導入
MLflowのバージョン2.17.0(Release Candidate)が公開されました。
LLMをChatカスタムモデルとして構築するためのChatModelに関する拡張が(個人的にも)今回の主要アップデートのようです。
これらアップデートに関してもいろいろ試したいと思っているのですが、2.17に合わせてドキュメントもいろいろ更新されているようで、LLMのセクションで以下のチュートリアルが追加されていました。
普段からmlflow.pyfunc.ChatModelをよく使っていたのですがかなり勉強になる内容だったため、ここで紹介されている内容の一部紹介とサンプルコードのウォークスルーをDatabricks上で行います。
2024/9/29時点のドキュメント内容を基にしています。
ウォークスルー環境はDatabricks on AWS、DatabricksのDBRは15.4ML、クラスタはサーバレスを用いました。
MLflow ChatModelとは?
以下の内容を邦訳しつつ一部抜粋。
急速に進化する生成型人工知能(GenAI)の分野は、エキサイティングな機会と統合の課題を提供します。最新のGenAIの進展を効果的に活用するためには、柔軟性と標準化のバランスを取るフレームワークが必要です。
MLflowは、バージョン2.11.0で導入されたmlflow.pyfunc.ChatModelクラスを使用して、このニーズに対応し、GenAIアプリケーションの一貫したインターフェースを提供しながら、デプロイメントとテストを簡素化します。
詳細は上記ドキュメントを確認することをお薦めしますが、生成AI(LLMなど)の利用においてMLflowはChatModelというクラスを提供しており、これを継承したクラスを実装することでOpenAI APIと類似したインターフェースを持つカスタムモデルを作ることができます。
例えば、ローカルLLMをMLflowでロギングする際に、Chatメッセージを入力として受け取って推論結果を返すクラスを容易に作ることができます。(通常MLflowでカスタムクラスを作成する際に利用するPythonModelは、Chatメッセージ形式の入力をそのまま受け取る定義を作ることが煩雑)
MLflowでGenAIアプリケーションを構築する際には、使いやすさとカスタマイズのレベルのバランスを取るために適切なモデル抽象化を選択することが重要です。この目的のために、MLflowは主に2つのクラスを提供しています: mlflow.pyfunc.ChatModelとmlflow.pyfunc.PythonModel。
それぞれに強みとトレードオフがあり、どちらがあなたのユースケースに最適かを理解することが重要です。
ChatModelの利点: シンプルさ、標準化、迅速なデプロイメント、管理するコードが少ない。
ChatModelの欠点: 柔軟性の制限、標準化された入力がすべてのカスタムニーズに適合しない可能性。
PythonModelの利点: 高度にカスタマイズ可能、任意の入出力フォーマットを処理可能、複雑な要件に適応可能。
PythonModelの欠点: より多くのセットアップが必要、カスタム署名の定義においてエラーが発生しやすい、入力変換の慎重な管理が必要。
推奨事項: 会話型エージェントに迅速で標準化された信頼性の高いソリューションが必要な場合は、mlflow.pyfunc.ChatModelを使用してください。プロジェクトが柔軟性を要求し、モデルの動作のあらゆる側面をカスタマイズする必要がある場合は、mlflow.pyfunc.PythonModelを選択してください。
加えて、ドキュメントではカスタムクラスの実装方法(ChatModelと従来のPythonModel)どちらを使うべきか、というPros/Consも記載されています。
記載されているように、ChatModelでは入力できるパラメータ定義などに制約ができるため独自パラメータの追加には不向きです。
例えば(私の記事でたまにやる)構造化出力用のスキーマ情報を独立したパラメータとして指定するカスタムは現状のChatModelではできません。(Chat用メッセージに埋め込むなどは可能)
とはいえ、個人的には生成AI(LLM)のカスタムクラスをDatabricks上で利用する場合、基本的にはChatModelを使う方がよいと思います。これはDatabricks Mosaic AI Model Servingを使ってAPIエンドポイントを公開する場合、LangChainやOpenAIクライアントのようなライブラリから標準的に利用可能なインターフェースを提供できるためです。
このチュートリアルは何をしているの?
ChatModelをカスタムして以下のことを行っています。
邦訳して抜粋。
- カスタムmlflow.pyfunc.ChatModelインスタンスにMLflowトレーシングを統合する。
- mlflow.pyfunc.log_model()内のmodel_configパラメータを使用してモデルをカスタマイズする。
- 標準化された署名インターフェースを活用してデプロイメントを簡素化する。
- mlflow.pyfunc.ChatModelクラスを拡張する際の一般的な落とし穴を認識し、回避する。
個人的な学びとしては、model_config関連を知らなかったので勉強になりました。いつのバージョンで出来てたんだろ。
また、拡張時の落とし穴はかなり大事なポイントですね。
Core Conceptのチャプターが(英語ですが)かなり丁寧に解説されているのでここをしっかり理解することが大事だと思います。
実際にチュートリアルのコードを動かしてみる
では、Example of custom ChatModel以下に記載されているコードを実行しながら見ていきます。
ノートブック作成&パッケージインストール
ウォークスルーにあたってDatabricks上でノートブックを作成し、まずは関連パッケージをインストール。
mlflowは念のためバージョン2.17(のリリース候補版)である2.17.0rc0を指定しました。
flaskはMLflowがdeploy検証に利用するようなのでインストールしています。
%pip install flask
%pip install -U "mlflow-skinny[databricks]==2.17.0rc0"
dbutils.library.restartPython()
カスタムChatモデルクラスの作成
次に、本題であるChatModelをカスタムしたBasicAgentクラスを定義します。
オリジナルに対してコメントを日本語化&%%writefileとmlflow.models.set_modelを使ったModels From Code対応のみ手を加えています。
%%writefile "./basic_agent.py"
import mlflow
from mlflow.types.llm import ChatResponse, ChatMessage, ChatParams, ChatChoice
from mlflow.pyfunc import ChatModel
from mlflow import deployments
from typing import List, Optional, Dict
from mlflow.models import set_model
class BasicAgent(ChatModel):
def __init__(self):
"""プレースホルダー値でBasicAgentを初期化します。"""
self.deploy_client = None
self.models = {}
self.models_config = {}
self.conversation_history = []
def load_context(self, context):
"""コネクタとモデル設定を初期化します。"""
self.deploy_client = deployments.get_deploy_client("databricks")
self.models = context.model_config.get("models", {})
self.models_config = context.model_config.get("configuration", {})
def _get_system_message(self, role: str) -> Dict:
"""
指定された役割のシステムメッセージ設定を取得します。
Args:
role (str): エージェントの役割(例:"oracle" または "judge")。
Returns:
dict: 指定された役割のシステムメッセージ。
"""
if role not in self.models:
raise ValueError(f"Unknown role: {role}")
instruction = self.models[role]["instruction"]
return ChatMessage(role="system", content=instruction).to_dict()
@mlflow.trace(name="Raw Agent Response")
def _get_agent_response(
self, message_list: List[Dict], endpoint: str, params: Optional[dict] = None
) -> Dict:
"""
エージェントのエンドポイントを呼び出して応答を取得します。
Args:
message_list (List[Dict]): エージェントへのメッセージのリスト。
endpoint (str): エージェントのエンドポイント。
params (Optional[dict]): 呼び出しの追加パラメータ。
Returns:
dict: エージェントからの応答。
"""
response = self.deploy_client.predict(
endpoint=endpoint, inputs={"messages": message_list, **(params or {})}
)
return response["choices"][0]["message"]
@mlflow.trace(name="Agent Call")
def _call_agent(
self, message: ChatMessage, role: str, params: Optional[dict] = None
) -> Dict:
"""
役割に基づいて特定のエージェントにリクエストを準備して送信します。
Args:
message (ChatMessage): 処理するメッセージ。
role (str): エージェントの役割(例:"oracle" または "judge")。
params (Optional[dict]): 呼び出しの追加パラメータ。
Returns:
dict: エージェントからの応答。
"""
system_message = self._get_system_message(role)
message_list = self._prepare_message_list(system_message, message)
# エージェントの応答を取得
agent_config = self.models[role]
response = self._get_agent_response(
message_list, agent_config["endpoint"], params
)
# 会話履歴を更新
self.conversation_history.extend([message.to_dict(), response])
return response
@mlflow.trace(name="Assemble Conversation")
def _prepare_message_list(
self, system_message: Dict, user_message: ChatMessage
) -> List[Dict]:
"""
エージェントに送信するメッセージのリストを準備します。
Args:
system_message (dict): システムメッセージの辞書。
user_message (ChatMessage): ユーザーメッセージ。
Returns:
List[dict]: 送信するメッセージの完全なリスト。
"""
user_prompt = {
"role": "user",
"content": self.models_config.get(
"user_response_instruction", "Can you make the answer better?"
),
}
if self.conversation_history:
return [system_message, *self.conversation_history, user_prompt]
else:
return [system_message, user_message.to_dict()]
def predict(
self, context, messages: List[ChatMessage], params: Optional[ChatParams] = None
) -> ChatResponse:
"""
エージェントの会話を処理するための予測メソッド。
Args:
context: MLflowのコンテキスト。
messages (List[ChatMessage]): 処理するメッセージのリスト。
params (Optional[ChatParams]): 会話の追加パラメータ。
Returns:
ChatResponse: 構造化された応答オブジェクト。
"""
# Fluent APIコンテキストハンドラを使用して、スパンに含まれる内容を制御
with mlflow.start_span(name="Audit Agent") as root_span:
# ユーザー入力をルートスパンに追加
root_span.set_inputs(messages)
# ルートスパンに属性を追加
attributes = {**params.to_dict(), **self.models_config, **self.models}
root_span.set_attributes(attributes)
# オラクルとの会話を開始
oracle_params = self._get_model_params("oracle")
oracle_response = self._call_agent(messages[0], "oracle", oracle_params)
# ジャッジで応答を処理
judge_params = self._get_model_params("judge")
judge_response = self._call_agent(
ChatMessage(**oracle_response), "judge", judge_params
)
# 会話履歴をリセットし、最終応答を返す
self.conversation_history = []
output = ChatResponse(
choices=[ChatChoice(index=0, message=ChatMessage(**judge_response))],
usage={},
model=judge_params.get("endpoint", "unknown"),
)
root_span.set_outputs(output)
return output
def _get_model_params(self, role: str) -> dict:
"""
指定された役割のモデルパラメータを取得します。
Args:
role (str): エージェントの役割(例:"oracle" または "judge")。
Returns:
dict: エージェントのパラメータの辞書。
"""
role_config = self.models.get(role, {})
return {
"temperature": role_config.get("temperature", 0.5),
"max_tokens": role_config.get("max_tokens", 500),
}
set_model(BasicAgent())
コード量がまあまあ多いのですが、主に行っているのはチャットメッセージ形式の入力を受け取り、
- 問い合わせに対する回答をLLMで生成
- その回答内容が正しいかをさらに別のLLMで判定し、回答内容を強化する
という2段階のステップで回答を生成するものとなっています。
つまりは既存のLLMにおける回答機能を拡張するエージェントと呼べるかな、と。
個人的なポイントは、
- Tracing機能の拡充
- Model Configからのモデル設定情報取得
です。どちらも一通り実行した上で振り返ってみます。
モデル用設定を作成
モデルの設定情報を作成します。
この辞書型の変数をロギング時に渡すことで、Chatカスタムモデルのload_context内で利用することができるようになります。(yaml形式の設定ファイルからも渡すこともできるようです)
設定内容は、回答を生成するoracleモデルと生成結果の判定・回答強化を担うjudgeモデルの設定などを含んでいます。
LLMのエンドポイント設定も含まれており、今回は以下の記事で作成したエンドポイントをoracle/judge両方に指定しました。(本来は別のLLMエンドポイントを指定するべきですが、チュートリアルなので簡易化)
model_config = {
"models": {
"judge": {
"endpoint": "lm-jp-3-13b-instruct-endpoint",
"instruction": (
"あなたは他の人が提供した回答を評価する役割です。質問と回答の両方の文脈に基づいて、"
"回答が間違っている場合は修正された回答を提供し、正しい場合は追加の文脈と説明で回答を強化してください。"
),
"temperature": 0.5,
"max_tokens": 2000,
},
"oracle": {
"endpoint": "lm-jp-3-13b-instruct-endpoint",
"instruction": (
"あなたは詳細だが簡潔な回答を提供することに優れた知識源です。"
"提供された情報に基づいて質問に回答してください。"
),
"temperature": 0.9,
"max_tokens": 4000,
},
},
"configuration": {
"user_response_instruction": "提供された文脈の履歴を用いて、この回答を評価し強化できますか?"
},
}
私、この機能をちゃんと知らなかったので今までartifactsとして設定ファイルを埋め込み、コンテキストとして読み込んでました。
標準の設定機能があるの、便利だなあ。。。
入力サンプルを作成
モデルの入力例を定義します。
この入力例はロギング時の検証やUI上での表示など、地味に重要な役割を果たします。
カスタムChatモデルの場合、指定を省略することもできるのですがここを見るにちゃんと登録することがおススメされています。
input_example = {
"messages": [
{
"role": "user",
"content": "あまりスキルを必要としないスコーンを焼くための良いレシピは何ですか?",
}
]
}
ロギングと推論
これまでのChatカスタムクラスやモデル設定、入力例を基にMLflowへロギングします。
また、Databricks Unity Catalogにモデルを登録しておきます。
import mlflow
# Databricks Unity Catalogを利用してモデル管理
mlflow.set_registry_uri("databricks-uc")
# Unity Catalogへの登録名。任意の場所を指定してください。
registered_model_name = "training.llm.basic_agent"
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
"model",
python_model="basic_agent.py",
model_config=model_config,
input_example=input_example,
registered_model_name=registered_model_name,
)
ロギングしたモデルをロードして、推論実行。
loaded = mlflow.pyfunc.load_model(model_info.model_uri)
response = loaded.predict(
{
"messages": [
{
"role": "user",
"content": "野球のバットの材質は何?",
}
]
}
)
print(response["choices"][0]["message"]["content"])
もちろん、提供された文脈を基にして回答を評価し、強化することができます。以下にそのプロセスを示します。
### 1. 提供された文脈の確認
まず、提供された文脈を確認します。例えば、以下のような文脈が考えられます:
```plaintext
野球のバットの材質について教えてください。
```
### 2. 回答の評価
次に、提供された文脈に対してどのように回答が提供されているかを評価します。
#### 評価ポイント
- 具体性: バットの材質について具体的な情報を提供しているか。
- 明確さ: 情報が明確で理解しやすいか。
- 関連性: 質問に対して適切な情報を提供しているか。
- 完全性: 必要な情報が全て含まれているか。
### 3. 回答の強化
評価結果を基に回答を強化します。
#### 強化された回答
```plaintext
野球のバットの材質には、主に以下の3つがあります。それぞれの材質には特有の特性と利点がありますので、用途や好みに応じて選ばれることが多いです。
1. 木製バット:
- カシ(オーク)、メープル(カエデ)、アオダモ(トネリコ)などの木材が使われることが一般的です。
- 特徴: 適度な重さとバランスがあり、打撃時のコントロールがしやすいです。また、木材の柔軟性が打球感を向上させる一方で、耐久性に欠けるため、頻繁に交換が必要です。
- 利点: 環境に優しく、比較的安価です。
2. 金属バット:
- アルミニウム、ジュラルミン、マグネシウムなどの金属が使用されます。
- 特徴: 軽い重量でスイングが速くなり、飛距離が出やすいです。また、耐久性にも優れています。
- 利点: 重量が軽いため、パワーヒッター向け。また、メンテナンスがほとんど不要です。
3. カーボンバット:
- カーボンファイバー(炭素繊維)やグラスファイバー(ガラス繊維)などの複合材料が使用されます。
- 特徴: 軽量で強度が高く、反発力も優れています。
- 利点: 軽量で扱いやすく、高反発のため飛距離が出やすいです。
これらの材質を組み合わせたハイブリッドバットも登場しており、用途や選手の特性に応じて最適なバットを選ぶことができます。例えば、木製バットの打感を楽しみたい選手や、金属バットの飛距離を必要とする選手など、それぞれのニーズに合わせたバットが提供されています。
```
### 4. 追加情報の提供
さらに、追加の情報を提供して回答を強化します。
#### 追加情報
- 用途の具体例:
- ピッチャーが使用するバットは、通常木製で、コントロールを重視した設計が多いです。
- バッターが使用するバットは、飛距離を重視して金属バットやカーボンバットを選ぶことが多いです。
- 専門家の意見:
- プロ野球選手やコーチの間では、木製バットの打感が好きだという意見が多いです。一方で、金属バットは飛距離が出やすいため、特に若手選手やパワーヒッターに好まれます。
- 最新のトレンド:
- 近年では、ハイブリッドバットの需要が増加しており、木製バットの打感と金属バットの飛距離を兼ね備えたバットが開発されています。
このように、提供された文脈を基に回答を強化することで、より具体的で明確な情報を提供することができます。
【Tracing情報】
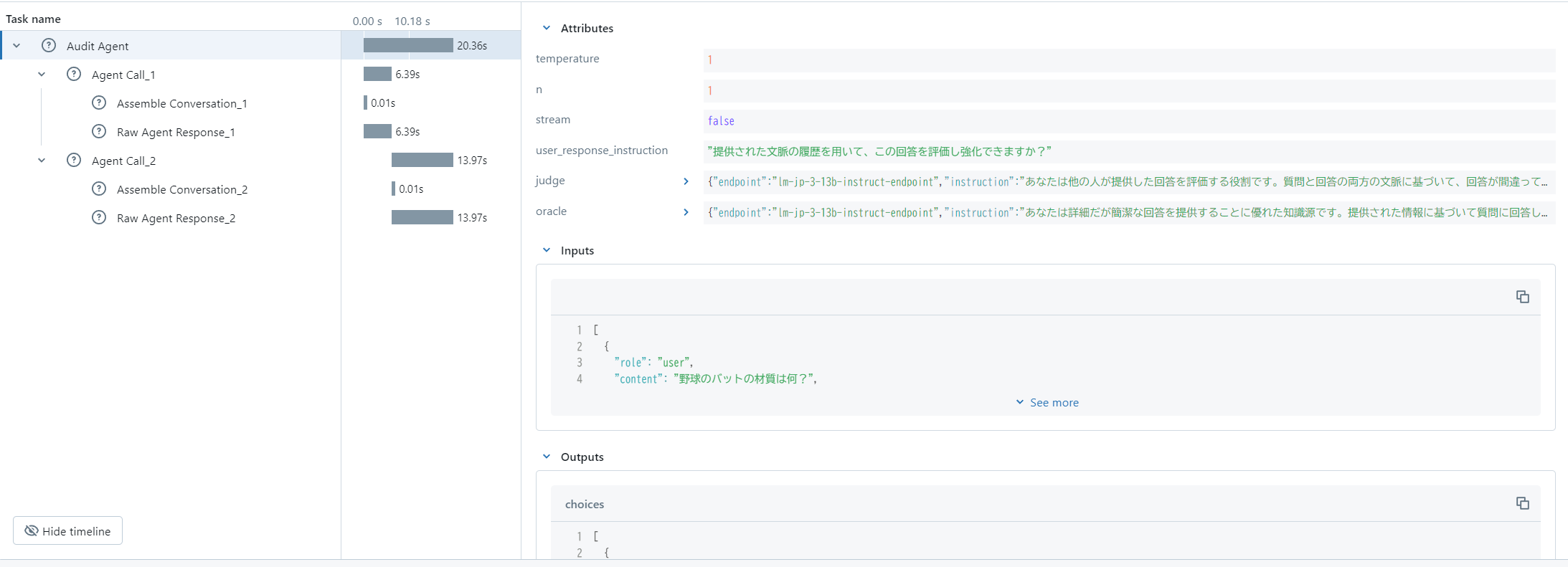
もともとのLLMの性能やプロンプトもあり若干イケてないところがありますが、問い合わせ回答を強化するエージェントによる推論が出来ました!
また、MLflow Tracingの対応も行っていることにより、エージェントの処理結果を容易に確認することもできます。
では、保存したモデルの中身についてもう少し見てみます。(ここからオリジナル)
Databricksのエクスペリメント画面から保管したモデルを見ると、まず「概要」タブの下部にあるパラメータ情報にmodel_configで指定した内容が表示されます。これは便利。

次に「アーティファクト」の中身を見てみます。
MLmodelの中を見ると、こちらにmodel_configの内容が保管されています。(日本語は文字化けしてますが。。。)

basic_agent.pyにはChatカスタムモデルのコードが含まれています。
これはMLflowのModels from Code機能でモデルをロギングしたためです。

input_example.jsonには作成した入力例が入っていますね。
temperatureなどのパラメータを指定しなかった場合、デフォルトの内容が入る模様。

これらはChatModelを使うためというわけではないのですが、ロギング時に指定することで後から確認しやすくなっています。モデル運用のためには重要な機能ですね。
モデルをデプロイする
Unity Catalogにモデルを登録したので、このままDatabricks Mosaic AI Model Serving機能を使ってエージェントをデプロイしてみます。
「サービング」メニューを開き「サービングエンドポイントを作成する」ボタンをクリックして作成画面に行き、先ほど登録したモデルをエンティティに指定してください。
外部のLLM APIを利用するため、このエンドポイントにおけるクラスタータイプはCPUで大丈夫です。
ここでのポイントは環境変数として「DATABRICKS_HOST」「DATABRICKS_TOKEN」などを指定すること。
エージェントの中で他のモデルのエンドポイントにアクセスしているため、ここが設定されていないと認証等で失敗します。(認証の仕方によっては別の環境変数指定が必要です。詳細はこちら)
下記画像は設定の一例で、環境変数として「DATABRICKS_HOST」「DATABRICKS_TOKEN」を設定しています。
また、環境変数の中身はシークレットから参照するようにしています。

無事作成が終わったら、動かしてみましょう。
UI上からクエリを投げてみます。

問題なく動作しました。
また、このエンドポイントはOpenAI APIと類似のインターフェースを提供しています。
そのため外部からは通常のChat Completion APIとしての利用が可能です。
まとめ
MLflowのチュートリアルをウォークスルー+αしてみました。
モデルの設定など改めて理解できて個人的にとても勉強になりました。
MLflowはボリュームがどんどん増えてきて複雑性も増してきています。一方、ドキュメントのクリーンアップも進んで来ていてこれから始める人にとってもやさしい作りになってきているように思いました。
カスタム用のChatModelは以前から使っていて非常に便利な機構だと思っていましたが、このあたりに関連する機能もどんどん進化していってますね。特にエージェント構築方向をかなり強化してきているように思います。
Databricks Mosaic AI Model Servingもこのあたりに易しい形で機能拡張して欲しいなあ・・・(プロビ(略) 基盤モデルAPI側が優先でしょうけども)。
その他、LangChainやLangGraph、LlamaIndexとの連携もするとより複雑なエージェントの構築もできそうで、そのあたりの組み合わせをいろいろ試したいと思います。
MLflowの拡張と合わせて、GenAIやエージェントがもっともっと発展してくことを期待してます!