こちらの続き?です。
導入
今回も「プロビジョニングされたスループットの基盤モデルAPIs」を使わないモデルサービングのユースケースをやってみます。
「プロビジョニングされたスループットの基盤モデルAPIs」は現状OpenAI等のAPIが提供しているJSONモードに代表される構造化出力をサポートしていません。(たぶん。勉強不足だったらごめんなさい)
そのため、結果をJSONで取得したり、特定の内容を選択出力するような場合、プロンプトのチューニングやエラー時の再実行処理の実装などを結構頑張る必要があります。
このような場合、現状はそれをサポートするモデル/APIエンドポイントを用意する方が便利だと思います。
というわけで、今回はvLLMとLM Format Enforcerを使って高速に構造化出力をバッチ処理できるAPIエンドポイントをDatabricks Model Serving上で実装してみます。
DatabricksのDBRは15.1ML、インスタンスタイプはg5.xlarge(AWS)です。
Step1. パッケージインストール
vllmを利用するためのパッケージをインストールします。
また、合わせて最新のmlflowをインストールします。
%pip install torch==2.3.0 --index-url https://download.pytorch.org/whl/cu121
%pip install flash-attn==2.5.8 --no-build-isolation
%pip install vllm==0.4.2
%pip install lm-format-enforcer==0.9.8
%pip install "mlflow-skinny[databricks]>=2.12.2"
dbutils.library.restartPython()
Step2. MLflow カスタムモデルの作成
MLflowに登録する構造化出力用のLLMバッチ推論カスタムモデルを定義します。
※ 長いので折りたたんでいます。
処理としては、mlflow.pyfunc.PythonModelを継承したカスタムクラスを作成し、推論処理でvLLMのgenerateを実行しています。
小さな工夫ですが、いろんなモデルを利用できるように、プロンプトのテンプレートは入れ替えられるようにしています。
エラーハンドリングなどかなり割愛しているので、参考にされる場合は注意ください。
VllmOfflineInferenceModel
from typing import List
import uuid
import mlflow
from mlflow.types.llm import ChatResponse, ChatMessage
import json
# Define a custom PythonModel
class VllmOfflineInferenceModel(mlflow.pyfunc.PythonModel):
def __init__(
self,
prompt_map,
pre_prompt="",
post_prompt="",
):
self.prompt_map = prompt_map
self.pre_prompt = pre_prompt
self.post_prompt = post_prompt
def format_messages(self, messages):
"""ChatMessageのリストからプロンプト文字列を作成"""
prompt = self.pre_prompt
for mes in messages:
template = self.prompt_map.get(mes.role)
if template:
prompt += template.format(mes.content)
prompt += self.post_prompt
return prompt
def load_context(self, context):
from vllm import LLM, SamplingParams
from lmformatenforcer.integrations.vllm import (
build_vllm_token_enforcer_tokenizer_data,
)
model_directory = context.artifacts["llm-model"]
print("Loading model: " + model_directory)
llm = LLM(model=model_directory)
self._llm = llm
self._tokenizer_data = build_vllm_token_enforcer_tokenizer_data(llm)
def predict(self, context, model_input, params=None):
from vllm import SamplingParams
# プロンプトの作成
prompts = self._build_prompt_from_model_input(model_input, params)
# サンプリングパラメータの作成
sampling_params = self._build_sampling_params(params)
# バッチ推論
results = self._llm.generate(
prompts, sampling_params=sampling_params, use_tqdm=False
)
collected_outputs = [{"output": result.outputs[0].text} for result in results]
return collected_outputs
def _build_prompt_from_model_input(self, model_input, params):
"""プロンプトを構築する"""
DEFAULT_SYSTEM_PROMPT = "You are a helpful assistant."
system_prompt = (
params.get("system_prompt", DEFAULT_SYSTEM_PROMPT)
if params
else DEFAULT_SYSTEM_PROMPT
)
prompts = [
self.format_messages(
[
ChatMessage(role="system", content=system_prompt),
ChatMessage(role="user", content=p),
]
)
for p in model_input["prompt"]
]
return prompts
def _build_sampling_params(self, params):
"""サンプリングパラメータを構築する"""
from vllm import SamplingParams
from lmformatenforcer import CharacterLevelParser, JsonSchemaParser
from lmformatenforcer.integrations.vllm import build_vllm_logits_processor
_params = params.copy() if params else {}
json_schema = _params.pop("json_schema", None)
selected_param_keys = [
"presence_penalty",
"frequency_penalty",
"repetition_penalty",
"temperature",
"top_p",
"top_k",
"stop",
"max_tokens",
"min_tokens",
]
_params = {key: _params[key] for key in selected_param_keys if key in _params}
# stopは文字列で入ってくることがあるため、その場合リストに変更
if isinstance(_params.get("stop"), str):
_params["stop"] = [_params["stop"]]
elif _params.get("stop", "") is None:
_params["stop"] = []
sampling_params = SamplingParams(**_params)
# json_schemaの指定がある場合、LM Format EnforcerによるJSON形式強制する
if json_schema:
parser = JsonSchemaParser(json_schema=json.loads(json_schema))
logits_processor = build_vllm_logits_processor(self._tokenizer_data, parser)
sampling_params.logits_processors = [logits_processor]
return sampling_params
def __getstate__(self):
# vLLMモデルはPickle化から除外
state = self.__dict__.copy()
state.pop("_llm", None)
state.pop("_tokenizer_data", None)
return state
Step3. モデルのスキーマ定義
MLFlowへ登録するにあたって、入力/パラメータのスキーマをシグネチャとして定義します。
入力はシンプルにプロンプトのリストを渡すだけです。
パラメータ側にシステムプロンプトの設定や、構造化出力のスキーマ(今回はJSON形式のみ)を設定できるようにしています。
import numpy as np
import pandas as pd
import mlflow
from mlflow.models.signature import ModelSignature
from mlflow.types import ColSpec, DataType, ParamSchema, ParamSpec, Schema
# Define input and output schema
input_schema = Schema(
[
ColSpec(DataType.string, "prompt"),
]
)
output_schema = Schema([ColSpec(DataType.string, "output")])
parameters = ParamSchema(
[
ParamSpec("temperature", DataType.float, np.float32(0.1), None),
ParamSpec("max_tokens", DataType.integer, np.int32(512), None),
ParamSpec("top_k", DataType.integer, np.int32(50), None),
ParamSpec("top_p", DataType.float, np.float32(0.8), None),
ParamSpec("repetition_penalty", DataType.float, np.float32(1.0), None),
ParamSpec("stop", DataType.string, None, None),
ParamSpec(
"system_prompt", DataType.string, "You are a helpful assistant.", None
),
ParamSpec("json_schema", DataType.string, None, None),
]
)
signature = ModelSignature(
inputs=input_schema, outputs=output_schema, params=parameters
)
# Define input example
input_example = [
{"prompt": "What is Databricks?"},
{"prompt": "What is AI?"},
{"prompt": "What is Data warehouse?"},
]
Step4. MLFlowへのモデル登録
先ほど作成したカスタムクラスやシグネチャを使ってMLFlowにモデル登録します。
実際のLLMとしては、以下のモデルを事前ダウンロードしておいて設定しました。
Llama3-8BをGPTQ/Marlin形式で量子化したモデルです。
(Marlinというものがあることを今回初めて知りました)
import mlflow
import os
mlflow.set_registry_uri("databricks-uc")
registered_model_name = "training.llm.batch_inference_model"
extra_pip_requirements = [
"ninja==1.11.1.1",
"torch==2.3.0 --index-url https://download.pytorch.org/whl/cu121",
"https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu122torch2.3cxx11abiFALSE-cp311-cp311-linux_x86_64.whl", # flash-attnは直接whl指定
"vllm==0.4.2",
"lm-format-enforcer==0.9.8",
]
# conda_env
conda_env = mlflow.pyfunc.get_default_conda_env()
conda_env["dependencies"][-1] = {
"pip": ["mlflow==2.12.2"]
+ mlflow.pyfunc.get_default_pip_requirements()
+ extra_pip_requirements
}
model_path = "/Volumes/training/llm/model_snapshots/models--qeternity--Meta-Llama-3-8B-Instruct-Marlin/"
prompt_map = {
"system": "<|start_header_id|>system<|end_header_id|>\n\n{}<|eot_id|>",
"user": "<|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|>",
"assistant": "<|start_header_id|>assistant<|end_header_id|>\n\n{}<|eot_id|>",
}
post_prompt = "<|start_header_id|>assistant<|end_header_id|>\n\n"
model = VllmOfflineInferenceModel(prompt_map=prompt_map, post_prompt=post_prompt)
with mlflow.start_run() as run:
_ = mlflow.pyfunc.log_model(
artifact_path="model",
python_model=model,
artifacts={
"llm-model": model_path,
},
signature=signature,
input_example=input_example,
conda_env=conda_env,
example_no_conversion=True,
await_registration_for=1200, # モデルサイズが大きいので長めの待ち時間にします
registered_model_name=registered_model_name, # 登録モデル名 in Unity Catalog
)
Step5. エンドポイント登録
MLFlowに登録したモデルを、DatabricksモデルサービングにAPI経由で登録します。
from mlflow import MlflowClient
import mlflow
import os
import requests
import json
mlflow.set_registry_uri("databricks-uc")
registered_model_name = "training.llm.batch_inference_model"
client=MlflowClient()
model_name = registered_model_name
versions = [mv.version for mv in client.search_model_versions(f"name='{model_name}'")]
# 現ノートブックからAPIのURLとトークンを取得
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
data = {
"name": "batch-inference2-endpoint",
"config":{
"served_entities": [
{
"entity_name": registered_model_name,
"entity_version": versions[0],
"workload_type": "GPU_MEDIUM",
"workload_size": "Small",
"scale_to_zero_enabled": True
}]
},
}
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers)
print(json.dumps(response.json(), indent=4))
ここまででエラーが出なければ準備終了です。
モデルサービスが準備可能になるまでは30分以上かかるのでお茶でも飲んで待ちましょう。
Step6. バッチ処理を試す
では、実際に試してみます。
まずはREST API経由で簡単に実行。
二つの問い合わせを同時に渡します。
import requests
import json
from pprint import pprint
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
data = {
"inputs": [
{"prompt": "Databricksの特長を箇条書きで述べてください。"},
{"prompt": "東京の環境名所を3カ所教えてください。"},
],
"params": {
"temperature": 1.0,
"max_tokens": 100,
},
}
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(
url=f"{API_ROOT}/serving-endpoints/batch-inference2-endpoint/invocations",
json=data,
headers=headers,
)
ret = response.json()["predictions"]
pprint(ret)
[{'output': 'Here are the notable features of Databricks:\n'
'\n'
'**Unified Analytics**:\n'
'\n'
'* Supports multiple data sources (e.g., CSV, JSON, Avro, Parquet, '
'ORC) and formats (e.g., Apache Parquet, ORC, CSV)\n'
'* Allows for data sharing and collaboration between teams and '
'organizations\n'
'\n'
'**Apache Spark-based**:\n'
'\n'
'* Built on top of Apache Spark, providing high-performance and '
'scalability\n'
'* Supports Spark 2.x and 3.x versions\n'
'* Provides seamless integration'},
{'output': 'Here are three major environmental organizations in Tokyo:\n'
'\n'
'1. **The Nature Conservancy Japan** (): This international '
'organization has a chapter in Tokyo that focuses on protecting '
"Japan's natural environment and promoting sustainable "
'development. They have several projects in Tokyo, including urban '
'forestry and wetland conservation efforts.\n'
"2. **The Tokyo Metropolitan Government's Bureau of Environment** "
'(): This is a government agency responsible for implementing '
'environmental policies and initiatives in the Tokyo metropolitan '
'area. They oversee issues such as air and water pollution, waste '
'management,'}]
英語ではありますが、ちゃんとまとめて結果が返ってきていますね。
次に、MLFlow Deployments SDKを使って同じクエリを実行してみます。
また、システムプロンプトの指定など、パラメータを変えてみます。
import mlflow.deployments
import os
import pandas as pd
from pydantic import BaseModel, conlist
from typing import Literal
os.environ["DATABRICKS_HOST"] = API_ROOT
os.environ["DATABRICKS_TOKEN"] = API_TOKEN
client = mlflow.deployments.get_deploy_client("databricks")
system_prompt = (
"You are a helpful assistant.You MUST reply in Japanese."
)
inputs = pd.DataFrame(
[
{"prompt": "Databricksの特長を箇条書きで述べてください。"},
{"prompt": "東京の環境名所を3カ所教えてください。"},
]
)
response = client.predict(
endpoint="batch-inference2-endpoint ",
inputs={
"inputs": inputs.to_dict(orient="records"),
"params": {
"temperature": 0.1,
"max_tokens": 512,
"system_prompt": system_prompt,
"stop": "<|eot_id|>",
},
},
)
display(pd.DataFrame(response.get("predictions")))

同様に結果が返ってきました。
MLFlow Deployments SDKの方が、若干親切なインターフェースだと思います。
では、構造化出力を実行してみます。
今回は、事前設定した質問Databricksにはどのような機能がありますか?に対して、(Retrieverで検索されたと想定する)文書が関連するものかどうかを判定し、その結果をJSON形式で出力しています。
今回のカスタムクラスはパラメータとしてJSON形式のスキーマを与えることで構造化出力するようにしました。
import mlflow.deployments
import os
import pandas as pd
from pydantic import BaseModel, conlist
from typing import Literal
os.environ["DATABRICKS_HOST"] = API_ROOT
os.environ["DATABRICKS_TOKEN"] = API_TOKEN
client = mlflow.deployments.get_deploy_client("databricks")
class Grade(BaseModel):
grade: Literal["yes", "no"]
question = "Databricksにはどのような機能がありますか?"
system_prompt = (
"You are a grader assessing relevance of a retrieved document to a user question. \n"
f"Here is the user question: {question} \n"
"Documents are provided as user prompt.\n"
"If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n"
"Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.\n"
"Please return 'no' even if the document is an unintelligible sentence.\n\n"
f"You MUST reply using the following schema:{Grade.schema_json()}"
)
# 邦訳:
# あなたは、検索された文書とユーザーの質問との関連性を評価する採点者です。
# 次がユーザーからの質問です: {question}
# 文書はユーザプロンプトとして提供されます。
# 検索された文書がユーザーの質問に関連するキーワードや意味を含んでいる場合、関連性があると評価します。
# その文書が質問に関連しているかどうかを、「yes」か 「no」の2値で判定してください。
inputs = pd.DataFrame(
[
{
"prompt": (
"Databricksは、Apache Sparkを基盤としており、"
"Sparkのパフォーマンスを改善するために、独自の技術を開発しています。"
),
},
{
"prompt": "Snowflakeには、厳重なセキュリティ機能があります。これにより、ユーザーのデータを保護することができます。",
},
{
"prompt": (
"CloudFormationは、インフラストラクチャーのデプロイメントサービスを提供します。"
"これにより、インフラストラクチャーを自動的にデプロイメントすることができます"
),
},
{
"prompt": "監視サービスを提供します。これにより、インフラストラクチャーのパフォーマンスを監視し、問題を早期に発見することができます。",
},
{
"prompt": "Mlflowによる機械学習モデルの管理機能を備えます。",
},
]
)
response = client.predict(
endpoint="batch-inference2-endpoint ",
inputs={
"inputs": inputs.to_dict(orient="records"),
"params": {
"temperature": 0.1,
"max_tokens": 512,
"system_prompt": system_prompt,
"stop": "<|eot_id|>",
"json_schema": Grade.schema_json(),
},
},
)
display(pd.DataFrame(response.get("predictions")))
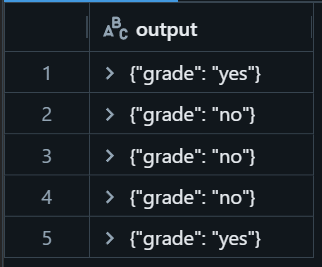
最初と最後のみ、関連しているという判定でした。
出力トークン数が小さいのもあり、1秒程度でこの5件の判定は実行できています。
まとめ
実際のところ、大量データのバッチ処理はJob等で回す方がよいとは思いますが、オンラインバッチ的に使う分にはモデルサービングのエンドポイントとして用意しておくと利便性や処理効率性が高いと思います。
(どれくらいのスループットが出るのかはまだ計ってないのですが。。。)
バッチ処理で頭を悩ませるのは、プロプライエタリなサービスを使うと入力トークン量が増えてコスト面で大変なのですが、モデルサービングとして利用する場合はそこを気にしなくていいところがポイントかと。
(とはいえ、実際にコストメリットがあるかどうかはユースケースによって変わってくるとは思いますが)
また、LLMを使うと非常に汎用性が高いAPIサーバとなるのがいいですね。
性能面・速度面など気を付けないところも多いですが、こういうエンドポイントがひとつあると、様々なユースケースに応用できると考えています。