はじめに
こんにちは。株式会社ジールの@is_zealです。
前回の投稿で、Amazon Kendraを使用してS3に保存したテキストファイルをデータソースとして検索しましたが、その中でさらに気になったことがあったので、追加で検証をしてみました。
【前回投稿した記事】
https://qiita.com/is_zeal/items/fdc976de108c369f7f56
今回検証する内容
① DB(RDS)をデータソースとして検索した場合、作成したテーブルの値を読み取って結果を返してくれるのか?
② 複数のデータソースを選択して検索した場合、1つのデータソースにしか存在しないデータでも結果を返してくれるのか?
検証準備
今回の検証では、RDSとS3をデータソースとして使用します。
〈環境構成図〉

〈検証準備〉
a. RDSに検証用のテーブルを作成する。
b. S3にバケットを作成し、そのバケットに検証用テキストファイルを格納する。
c. Amazon Kendraで検証用のインデックスを作成する。
d. 作成した検証用インデックスに、RDSコネクタを使用して、検証用のテーブルをデータソースとして追加する
e. 作成した検証用インデックスに、S3コネクタを使用して、S3バケットをデータソースとして追加する
f. 追加したデータソースを同期させる
検証準備 b、c、e、f については、前回投稿した記事と同じように実施します。
検証準備 a については、以下の記事を参考に検証用のテーブルを作成しました。
〈参考記事〉
https://qiita.com/saki-engineering/items/b4a5f61d5632c952a6cb
〈作成した検証用のテーブル:Sales〉
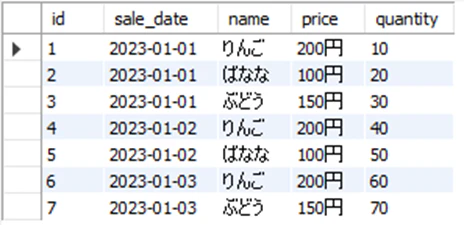
今回は検証準備 d の手順を記載します。
※画面は日本語に翻訳して表示しています。
検証準備 d.
作成した検証用インデックスに、RDSコネクタを使用して、検証用のテーブルをデータソースとして追加する
①データソースの追加画面から、Amazon RDSコネクタの「コネクタの追加」をクリックします。

②任意のデータソース名を入力し、言語を選択して「次に」をクリックします。

③データソースとして追加したいRDSの情報、AWS Secrets Managerの選択、VPCとセキュリティグループ、IAMロールを入力して、「次に」をクリックします。
④使用するデータベースエンジンを選択して、ACL列と検出列(データソースとして追加するテーブルの項目名)を追加し、同期実行スケジュールを選択して「次に」をクリックします。
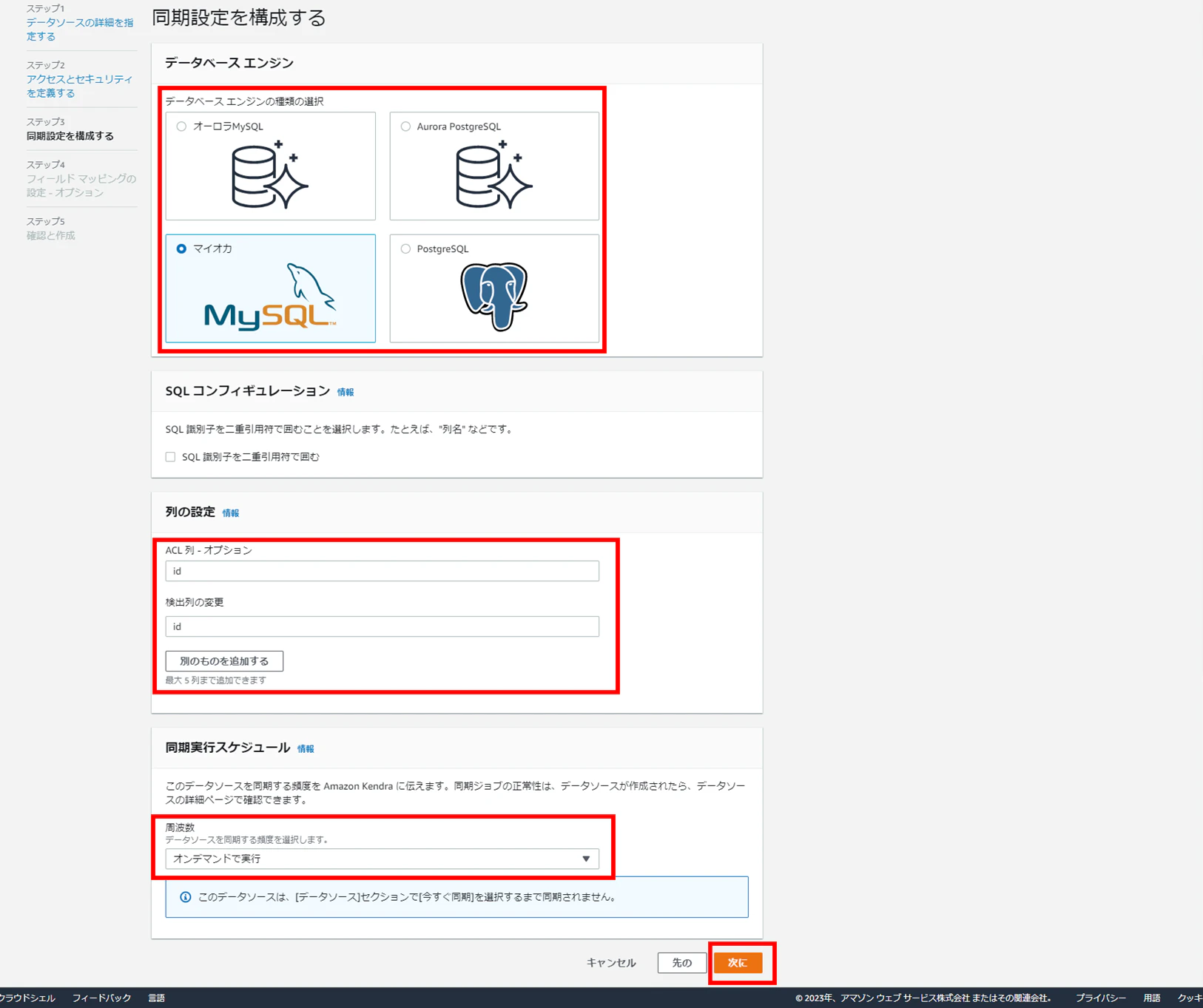
※全角文字を入力すると、以下のようなエラー表示が出ます。

※テーブルの項目名が間違っていると、同期時にエラーが発生し同期が失敗します。

⑤Amazon Kendraのフィールドマッピング設定を行います。
追加するテーブルの列名とデータ型を選択し、Amazon Kendraがデータをマッピングして読み取れるように設定を行います。今回はデータソースとして追加する全ての列をマッピングします。
マッピングの設定後、「次に」をクリックします。

フィールドのマッピング設定にミスがあると、データソースの追加やデータの同期を行う際にエラーとなります。
[失敗例]
・データベース列名がテーブルの項目名と異なっている
・データ型が間違っている
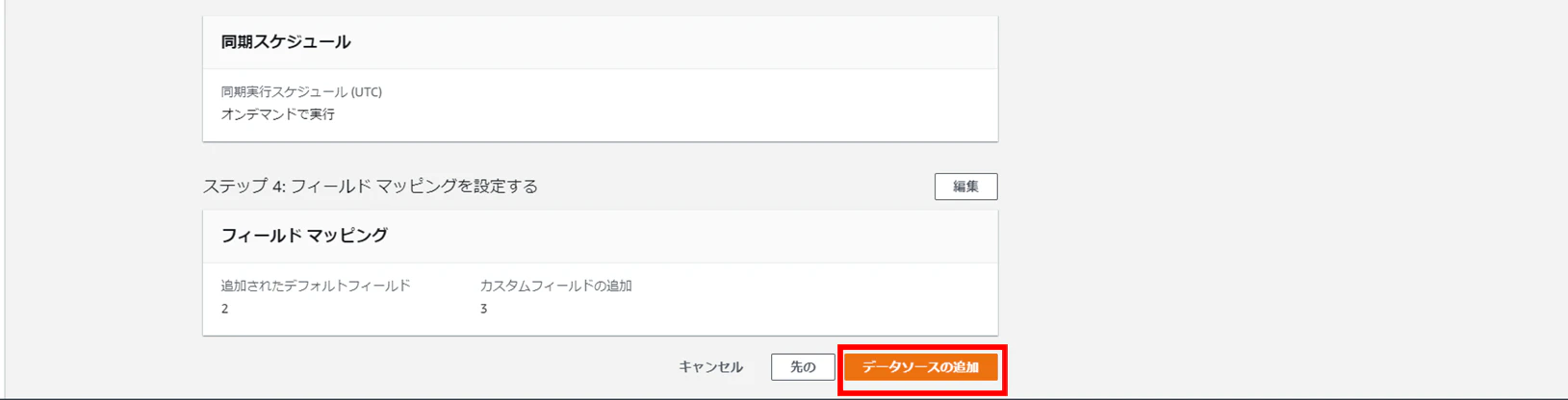
⑥「データソースの追加」をクリックします。
検証①
DB(RDS)をデータソースとして検索した場合、作成したテーブルの値を読み取って結果を返してくれるのか?
今回、検証で使用するテーブルは以下の「Sales」テーブルです。
〈Sales〉

まずは自然言語で「りんごの値段は?」と検索してみると、以下のように結果が返ってきました。

Amazon Kendraから答えを提案はしてくれず、「文書フィールド」で検索ワードに当てはまるデータを表示しています。
また、name列が「ばなな」のデータも表示されています。
(関連性のあるものでソートしましたが、なぜか「ばなな」のデータも関連性があると判断されています...)
自然言語ではなく、「りんご」という単語だけを入力して検索してみると、以下のように結果が返ってきました。
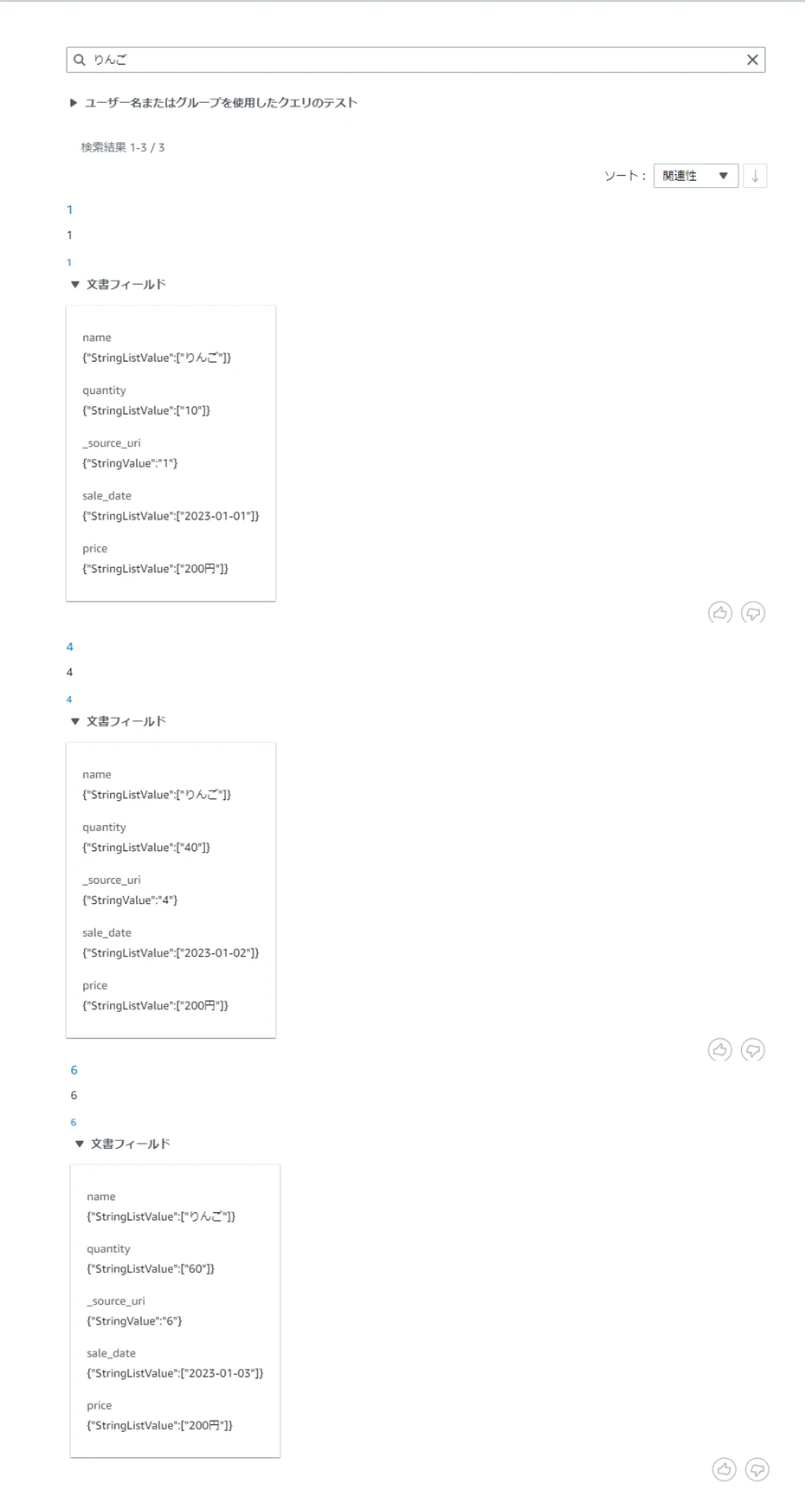
自然言語で検索した時と同じように、Amazon Kendraが答えを提案することはありませんでしたが、大きく異なるのはname列が「りんご」のデータのみが表示されました。(「値段」という言葉が検索結果に影響してしまったのかもしれません...)
テーブルにあるデータを読み取ってくれているようですが、自然言語での検索だと情報の絞り込みが難しいようです。
「1月のりんごの売上額は?」といったような、集計が必要となる検索についても試してみましたが、Amazon Kendraは答えを提案してくれず、「りんごの値段は?」と検索した時と同じように文書フィールドのみを結果として表示しました。
検証②
複数のデータソースを選択して検索した場合、1つのデータソースにしか存在しないデータでも結果を返してくれるのか?
Amazon Kendraではデータソースを1つだけでなく、複数追加することができます。
実際に、データソースとして検証①で使用したRDSのテーブルと、S3バケットに格納したxlsxファイルを追加して検索してみました。
〈データソース①:Salesテーブル(RDS)〉

〈データソース②:test.xlsx(S3)〉

データソース②:test.xlsxには、RDS側も持っているりんごの価格と、RDS側が持っていないみかんの価格を記載しています。
2つのデータソースを追加して、「みかんの値段は?」と検索したところ、以下のような結果が返ってきました。

S3のファイルからみかんの値段を検索し、答えを提案してくれました。
また、RDSとS3のどちらもデータを保持している「りんご」について、「りんごの値段は?」と検索してみると、結果は「S3の検索結果」+「RDSの検索結果」という結果になりました。
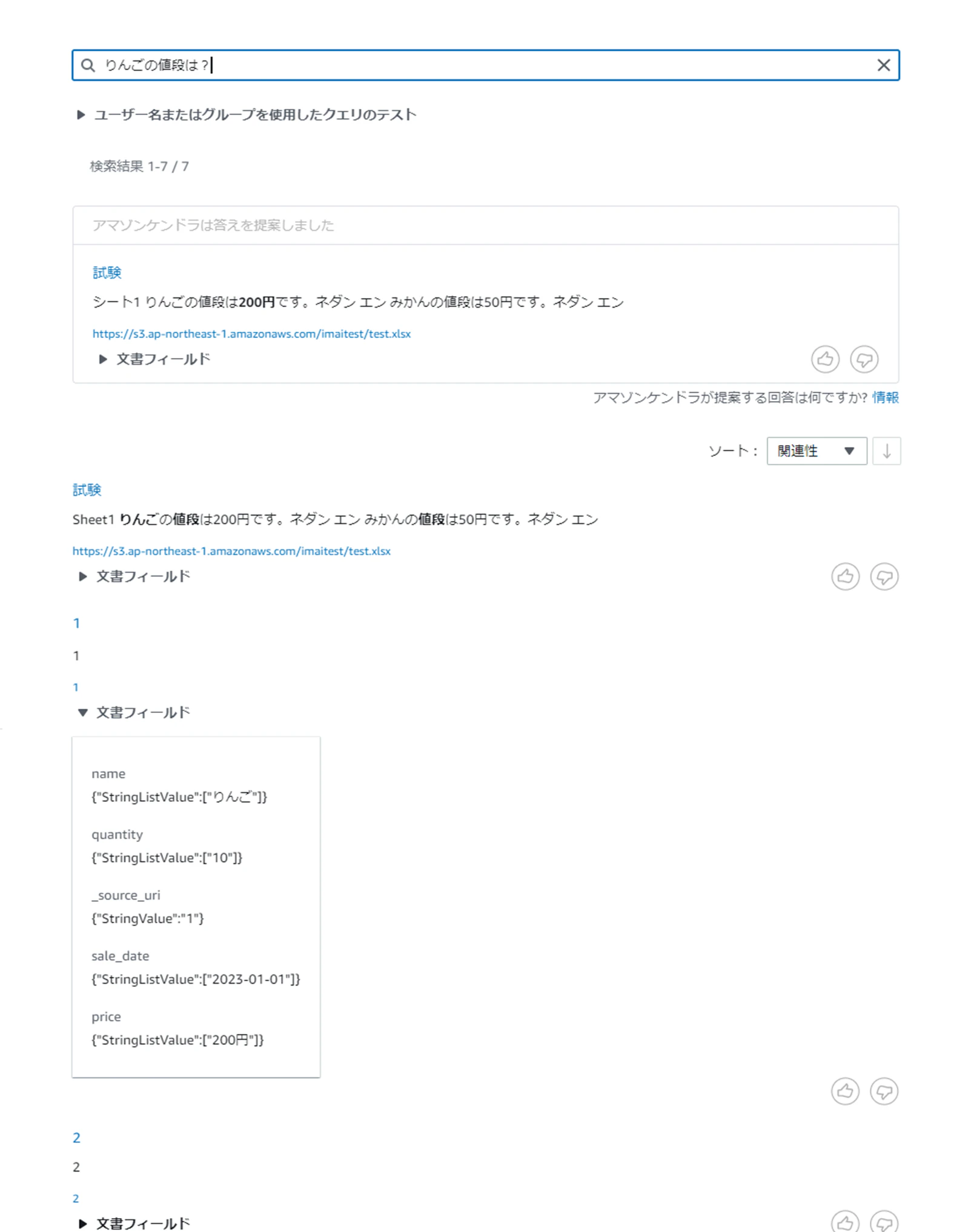
複数のデータソースを追加した際の結果は、データソースのどれか1つでも検索に引っかかるデータを持っていれば、検索結果として表示してくれることが分かります。
まとめ
今回はRDSに作成したテーブルへの検索と、複数のデータソースに対しての検索を試してみました。RDSのテーブルについての検索は単語のみの検索の場合はデータを絞って検索してくれるものの、回答の提案や集計が必要な回答は得られませんでした。
また、複数のデータソースを追加しての検索はテキスト形式のデータソースであれば問題なく検索できました。
テーブルに登録したデータを読み取って答えを提案してくれたり、表やテーブルを読み取って集計して答えを提案してくれるようになると、さらに便利になると感じました。
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/?utm_source=qiita&utm_medium=referral&utm_campaign=qiita_zeuscloud_content-area