はじめに
この記事は、統計検定2級に合格するためにあと少しの方や、二度目の受験をする方に向けて書いたものとなっています。
統計検定2級を受けようと思っている方などは、先に以下のサイトから勉強することをおすすめします。
また、以下の記事をもとにプラスで必要だと感じたところを筆者なりに書いています。
ちなみに、筆者は2020年6月に統計検定2級CBT方式で合格したので、記事として公開しました。
移動平均
株価や気温など時間で細かく変化するデータを眺めるときに、変動が細かすぎて全体をつかみにくい場合に使われる手法。
5項の移動平均(奇数)
ma_i = \frac{x_{i-2}+x_{i_1}+x_i+x_{i+1}+x_{i+2}}{2ab}
6項の移動平均(偶数)→両端を0.5倍する必要あり
ma_i = \frac{0.5 \times x_{i-2}+x_{i_1}+x_i+x_{i+1}+0.5\times x_{i+2}}{2ab}
偏差値
標準化したデータ(期待値=0,標準偏差=1)をわかりやすくするために、期待値=50,標準偏差=10となるように変換したもの。
偏差値= \frac{x- \bar{x}}{s} \times{10} + 50\\
(sは標準偏差を表す)
コレログラム
元データと時間をずらしたデータとの相関のこと自己相関という。
コレログラムとは、時間のラグと自己相関を表したグラフのことを指す。
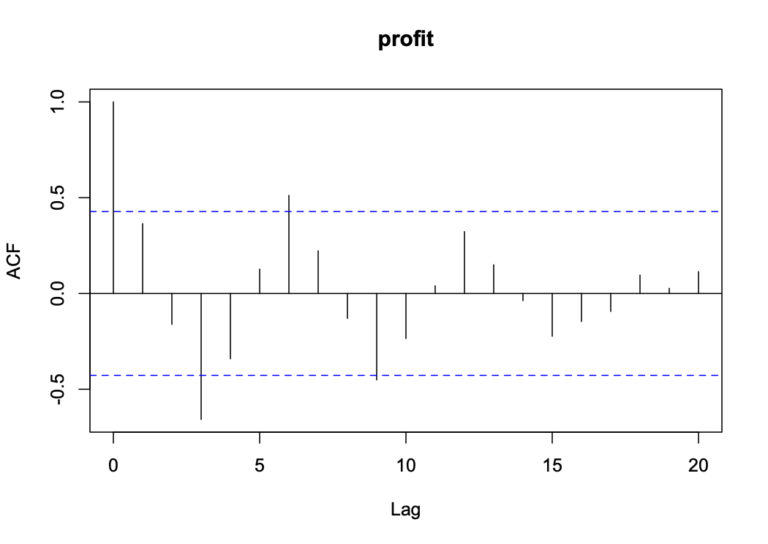
縦軸が自己相関で横軸がラグ数となる。
また、青い点線の範囲に含まれる値はすべて、無相関とみなす。(棄却限界値)
誤差
誤差は大きく分けて、2つに分けられる。
- 統計誤差→
測定の仕方、対象の選び方で生じる誤差である。 - 確率誤差→統計誤差を覗いた後に残っている誤差である。偶然誤差とも言われる。
変化率
変化率=\frac{変化後データ - 変化前データ}{変化前データ} \times 100
抽出方法
| 抽出法法 | 説明 | メリット | デメリット |
|---|---|---|---|
| 層化抽出法 | 各層から必要な数の調査対象を無作為に抽出する | 制度◯ | 構成情報を知る必要あり |
| クラスター抽出法 | クラスターに分けてからクラスターを無作為抽出し、選んだクラスターを全数調査 | 時間や手間を節約 | 標本に偏り |
| 多段抽出法 | グループに分け、無作為抽出 | コスト低、効率良い | 標本に偏り |
| 系統抽出法 | 通し番号ごと抽出、1番目をランダムに決める必要あり | 時間、手間、コスト節約 | 標本に偏り |
独立
独立の場合なのかを区別する必要あり
区間推定でも独立であるかないかは重要になってくる
\begin{align}
共分散(cov)& = 0 \\
V(X+Y) &= V(X) + V(Y) + 2cov(X,Y) \\
→V(X+Y) &= V(X) + V(Y)
\end{align}
ポアソン分布と指数分布
ポアソン分布
nが非常に大きく、確率が小さくなったとき、「np=一定」とするときに使われる。
ある期間までの回数を求めるときに使われる。
np = λ\\
P(X=k) = \frac{e^{-λ}λ^k}{k!} (k = 0,1,\cdots,n)
期待値と分散
E(X) = λ\\
V(X) = λ
λが大きくなるに連れて、正規分布に従う
指数分布
次に起こるまでの期間を求めるときに使われる。
確率密度関数
f(x) = \left\{
\begin{array}{1}
λe^{-λx} & (x \geq 0) \\
0 & (x \lt 0)
\end{array}
\right.
xまでの累積分布関数
\begin{array}
F(x) &= \int_{0}^{x}(λe^{-λx})dx\\
&= 1 - e^{-λx}
\end{array}
期待値と分散
E(x) = \frac{1}{λ}\\
V(x) = \frac{1}{λ^2}
t分布
母分散がわからず、母平均の区間推定を行うときに使われる。
統計量t
t = \frac{\bar{x}-μ}{se}
t分布の信頼区間の求め方
-t_{a/2}(n-1) \hspace{0.5cm} \leqq \hspace{0.5cm} \frac{\bar{x}-μ}{se}
\hspace{0.5cm} \leqq \hspace{0.5cm} t_{a/2}(n-1)
しかし、nが非常に大きくなったとき(n>120)は、中心極限定理より、標準正規分布として、扱って良い
t分布の条件
1. 標本は、母集団から選ばれる
2. 母集団の分布は、正規分布に従う
3. 2標本t分布の際は、2つの母集団の母分散は、等しい
→当てはまらなければ、F分布を使う
母平均の差の検定(2標本t検定)
前提として、2標本t検定を行う際は2つの母分散は等しいとする。
-
対応しているデータがある場合(独立✕)
→差の平均と不偏分散を出す→t分布 -
母分散は等しく、対応していないデータが場合(独立◯)
→プールした分散→t分布 -
母分散は等しくない、対応していないデータがある場合(独立◯)
→統計量tは1.と同じように求める→自由度は、welchの検定を参照
カイ二乗分布
Z1,Z2,Z3..Zkがお互いにそれぞれ独立で、標準正規分布に従っている確率変数であるときに、算出される自由度kのχ2が従う確率分布
\begin{array}\
X^2 &= Z_1^2 + Z_2^2 + \cdots + Z_k^2\\
&= \sum_{k=1}^{n} k = \frac{X_i - μ}{σ} \hspace{0.5cm} \cdots X^2(k) \\
&= \frac{(k-1)S^2}{σ^2} \hspace{0.5cm} \cdots X^2(k-1)
\end{array}
有意水準
- 帰無仮説が正しいのに、帰無仮説を棄却してしまう確率のことを指す。第一種の過誤とも言われる。
- 帰無仮説が正しくないときに、正しく棄却する確率を検出力と言われる。
- 対立仮説が正しいのに、帰無仮説を採用してしまう確率を第二種の過誤と言われる。
p値
帰無仮説が正しいとしたときに、事象よりも極端なことが起きる確率のことを指す。
p値 < 有意水準 → 帰無仮説を棄却する
p値 > 有意水準 → 対立仮説を棄却する
仮説検定のとき
帰無仮説のもとで検定統計量がそのままp値となる。よって、帰無仮説が正しいとする確率となる。
回帰分析のとき
p値「パラメーターは0である」という帰無仮説に沿っている。
p>αのとき
→帰無仮説を正しいとするため、そのパラメーターはほぼ0となる。
→そのパラメーターはそのモデルに必要ない
***p<αのとき***
→帰無仮説を棄却する
→パラメーター必要
F分布
2つのカイ二乗検定がお互いに独立である場合に従う確率分布
\begin{array}\
F &= \frac{X_1^2 / k_1}{X_2^2 / k_2}\\
&= \frac{S_1^2 / σ_1^2}{S_2^2 / σ_2^2}
\end{array}
上側確率→下側確率に変換
F_a(m_1,m_2) = \frac{1}{F_{1-a}(m_2,m_1)}