どうも、学生エンジニアのirohasです。
本日は、本職であるAiをテーマにしたプログラムを記事にします。
今回やったことは、タイトルの通り「アニメのキャラクターを用いてキャラクターの画像認識をやってみた」です。
今回使用させてもらったアニメはあのアニメオタクなら知らぬ人はいない伝説のスクールアイドルアニメである「ラブライブ!」シリーズ最新作の「虹ヶ咲学園スクールアイドル同好会」になります。
ちなみに余談ですが、僕は虹ヶ咲ではMiaちゃんが最推しです。
それでは早速書いていきます。
目次
1.環境
2.使用ライブラリ
3.データセット作成・修正
4.モデル作成
5.学習結果
6.画像認識
7.おわりに
1. 環境
Anaconda3 (64bit)
Jupyter Notebook
Python 3.9.0
2. 使用ライブラリ
・標準ライブラリ
os : ローカルフォルダ用ライブラリ
time : 処理時間等の可視化用ライブラリ
glob : フォルダ一括取得用ライブラリ
・外部ライブラリ
numpy 1.21.4 : 数値計算ライブラリ
OpenCV 4.5.4.60 : 画像処理ライブラリ
matplotlib 3.5.1 : グラフ描写用ライブラリ
Keras 2.8.0 : ディープラーニング用ライブラリ
3. データセット作成・修正
画像収集
ディープラーニングを行ううえでまずやらなければならないことで一番時間がかかるといっても過言ではないのがこの画像収集です。
今回は虹ヶ咲学園に登場する13人のキャラクターの画像をネットで検索をかけたりして、ひたすら収集します。
例えばこんな感じ↓
次に、集めた画像をディープラーニングしやすいように加工・修正をしていきます。
画像サイズはディープラーニングしやすいように64 × 64にリサイズしていきます。
さらに、検出後に仕分けるのがとてつもなく面倒なので自動で各フォルダに格納されるようにしています。
コードは以下になります。
import cv2
import os
# 各データセットディレクトリパス定義
dataset = "dir_name"
resize = "dir_name"
# OpenCV検出サイズ定義
cv_w, cv_h = 64, 64
# 顔画像サイズ定義
w, h = 64, 64
# 顔検出用カスケードxmlファイルパス定義
cascade = "カスケードファイルの置き場所"
def main():
# キャラ名リスト定義
name_list = os.listdir(dataset)
print(name_list)
# キャラディレクトリ毎に顔検出し、保存先ディレクトリ配下に保存
for name in name_list:
# キャラ画像ディレクトリ定義
print(name)
dataset = dataset + name + "/"
print(dataset)
# 顔画像保存先ディレクトリ定義
resize = resize + name + "/"
print(resize)
# 顔検出実行
detect_face(dataset, resize)
def detect_face(dataset, resize):
# ファイルの取得
img_list = os.listdir(dataset)
print(img_list)
# 画像ファイル毎に顔検出
for file in img_list:
# 画像ファイル読み込み
dataset_img = cv2.imread(dataset + file)
if dataset_img is None:
print("Not open:",dataset_img)
continue
# グレースケール変換
gray = cv2.cvtColor(dataset_img, cv2.COLOR_BGR2GRAY)
# カスケードファイル
cas = cv2.CascadeClassifier(cascade)
for i_mn in range(1, 7, 1):
faces = cas.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=i_mn, minSize=(cv_w, cv_h))
# 顔が1つ以上検出された場合、w x hのサイズで取得
if len(faces) > 0:
for rect in faces:
image = dataset_img[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0] < w or image.shape[1] < h:
continue
face_image = cv2.resize(image,(w, h))
# 顔が検出されなかった場合スキップ
else:
print("no face")
continue
print(face_image.shape)
# ファイルに保存
face_file_name = os.path.join(resize, "face-" + file)
cv2.imwrite(str(face_file_name), face_image)
if __name__ == '__main__':
main()
カスケードファイルに関しては結構種類があるので用途に応じて各自で選ぶといいと思います!
自分は今回キャラクターの検出なので、アニメ顔の検出に優れているlbpcascade_animeface.xmlを使用しました。
リンクはこちら↓
File Here
4. モデル作成
データセットを作成しおわったらいよいよ学習モデルを生成していきます。
import os
import keras
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Activation
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import time
w, h = 64, 64
batch_size = 64
# エポック数(1エポックの画像サンプル数 = ステップ数 * バッチサイズ)
epoch = 100
# 収束判定
convergence = epoch
# 収束判定用差分パラメータ
val_min_delta = 0.001
# 学習用画像ディレクトリ
train_data = 'resize'
def main():
# 環境設定
os.environ['DISPLAY'] = ':0'
# 時間計測
start = time.time()
classes = os.listdir(train_data)
sub_num = len(classes)
# 学習済ファイルの保存先
savefile = 'model/niji_model.h5'
# モデル作成
if os.path.exists(savefile):
print('Model Re-training')
cnn_model = keras.models.load_model(savefile)
else:
print('Model create')
cnn_model = cnn_model_maker(nb_classes)
cnn_model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 画像のジェネレータ生成
train_generator, validation_generator = image_generator(classes)
es_cb = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=val_min_delta, patience=convergence, verbose=1, mode='min')
# CNN
history = cnn_model.fit_generator(
train_generator,
epochs=epoch,
validation_data=validation_generator,
callbacks=[es_cb])
cnn_model.save(savefile)
# 学習所要時間
process_time = (time.time() - start) / 60
print('process_time = ', process_time, '[min]')
# 損失関数の時系列変化をグラフ表示
plot_loss(history)
def cnn_model_maker(sub_num):
input_shape = (w, h, 3)
# ニューラルネットワーク定義
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(sub_num))
model.add(Activation('softmax'))
return model
def image_generator(classes):
# トレーニング画像の生成準備
datagen = ImageDataGenerator(
rescale=1.0 / 255,
zoom_range=0.2,
horizontal_flip=False,
validation_split=0.1)
# データ作成
train_generator = datagen.flow_from_directory(
train_data,
target_size=(w, h),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True,
subset = "training")
# ディレクトリ内の評価用画像を読み込み、データ作成
validation_generator = datagen.flow_from_directory(
train_data,
target_size=(w, h),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True,
subset = "validation")
return (train_generator, validation_generator)
def plot_loss(history):
plt.xlabel('time step')
plt.ylabel('loss')
plt.ylim(0, max(np.r_[history.history['val_loss'], history.history['loss']]))
val_loss, = plt.plot(history.history['val_loss'], c='#56B4E9')
loss, = plt.plot(history.history['loss'], c='#E69F00')
plt.legend([loss, val_loss], ['loss', 'val_loss'])
plt.show()
# グラフを保存
plt.savefig('任意の保存先')
if __name__ == '__main__':
main()
5. 学習結果
学習の経過は以下のようになります。
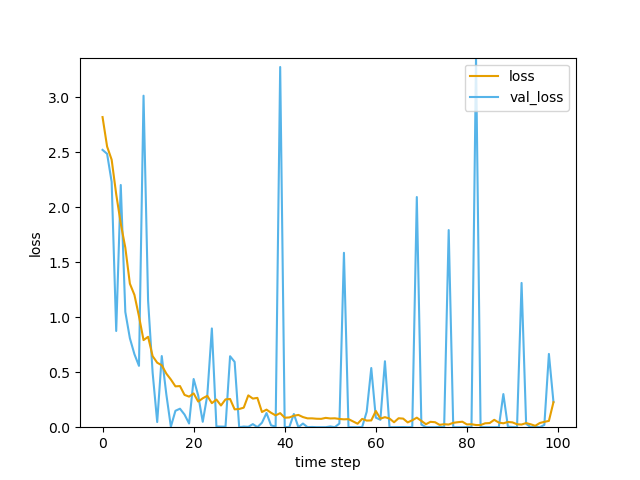
lossは収束していますが、val_lossはかなり不安定になっています。ここから未知のデータに対する精度は不安定なのが読み取れます。今回収集した画像は合計で1000枚に満たないので、汎化性能をあげるには、もっと多くの画像が必要だと思いました。
(現在複数の友人に協力してもらいながらデータ収集を再開しています。)
6. 画像認識
無事モデルの作成も終えたら、いよいよモデルの適用です。
データに使っていない写真に適用させてみます。虹ヶ咲は黒髪系統のキャラクターが多いので少ない枚数でどこまでの精度が出せるのかに注目です。
import os
import keras
import cv2
import matplotlib.pyplot as plt
from keras.models import load_model
import numpy as np
import glob
%matplotlib inline
#ディレクトリを作成
if not os.path.exists("任意の名前"):
os.mkdir("任意の名前")
dir_name = "任意の名前"
#modelの読み込み
model = load_model("モデルのパス")
#テスト用ディレクトリを開く
test_path = glob.glob("任意の名前")
num = 0
for img_path in test_path:
img = cv2.imread(img_path, 1)
name,ext = os.path.splitext(img_path)
num += 1
file_name = dir_name + "test" + str(num) + str(ext)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cas = "cascade/lbpcascade_animeface.xml"
cascade = cv2.CascadeClassifier(cas)
faces=cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=2, minSize=(64,64), maxSize=(512,512))
Labels= ["ai","ayumu","emma","kanata","karin","kasumi","mia",
"ranju","rina","setuna","shioriko","sizuku","yu"]
Threshold = 0.90
#顔が検出されたとき
if len(faces) > 0:
for fp in faces:
#スコアを計算
img_face = img[fp[1]:fp[1]+fp[3], fp[0]:fp[0]+fp[2]]
img_face = cv2.resize(img_face, (64, 64))
score = model.predict(np.expand_dims(img_face, axis=0))
#最も高いスコアを書き込む
score_argmax = np.argmax(np.array(score[0]))
#閾値以下で表示させない
if score[0][score_argmax] < Threshold:
continue
#文字サイズ
fs_rate= 0.007
name = "{0} {1:.1f}% ".format(Labels[score_argmax], score[0][score_argmax]*100)
#座標の調整
text_rate = 0.10
#ラベルを色で分ける
if Labels[score_argmax] == "ai":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0,165,255), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (0,165,255), 2)
if Labels[score_argmax] == "ayumu":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (193,182,255), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (193,182,255), 2)
if Labels[score_argmax] == "emma":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (144,238,144), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (144,238,144), 2)
if Labels[score_argmax] == "kanata":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (204,50,153), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (204,50,153), 2)
if Labels[score_argmax] == "karin":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(225,105,65), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (225,105,65), 2)
if Labels[score_argmax] == "kasumi":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(0,255,255), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (0,255,255), 2)
if Labels[score_argmax] == "mia":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(192,192,192), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (192,192,192), 2)
if Labels[score_argmax] == "ranju":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(32,165,218), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (32,165,218), 2)
if Labels[score_argmax] == "rina":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(255,255,255), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (255,255,255), 2)
if Labels[score_argmax] == "setuna":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(0,0,255), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (0,0,255), 2)
if Labels[score_argmax] == "shioriko":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(87,139,46), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (87,139,46), 2)
if Labels[score_argmax] == "sizuku":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(230,216,173), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (230,216,173), 2)
if Labels[score_argmax] == "yu":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(0,0,0), thickness=3)
cv2.putText(img, name, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (0,0,0), 2)
plt.figure(figsize=(8, 6),dpi=200)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
cv2.imwrite(file_name, img)
#顔が検出されなかったら
else:
print("Read Error:111 No applicable face could be detected.")
実行結果
今回、メンバーの顔を囲うboxの色はメンバーそれぞれのメンバーカラーで設定しました!
・うまく認識したやつ





ただでさえ虹ヶ咲はμ'sやaqoursに比べて画像数が少ないのに、その中でも加入したばっかのMiaちゃんと嵐珠ちゃんがしっかり認識されたのにはびっくりしました!
・誤認識したやつ





まず黒髪系統のキャラの圧倒的なせつな率!!!(笑)
やはりサンプル数が少ないとこうなってしまうんですかね...(笑)
愛ちゃんがなんでMiaだと思われたのか、りなりーがなんで愛ちゃんだと思われたのか不明なので知りたいところではあります(笑)
XAIの一種である、Grad-CamやLIMEを利用して検証しようと思います。
・反省点
10件のテストデータに対し、正解したのは半分の5件と、50%というAIモデルとしては課題が残りまくる結果になってしまいました。
理由としては、ほんとに圧倒的なデータ数不足がまずあげられるので、現在複数の友達に協力してもらいながらデータ数を増やしています。
さらに、誤認識した際のスコアが高いのもデータ数が少ないが故に起こっていることだと考えられるので、まずはデータ数の増加に尽力しようと思います。
誤認識した中でも原因がいまいちわからないものに関しては、先述の通りXAIを利用して検証していこうと思っています。
7. おわりに
学生という身分でありながら、AIを使用した仕事をしているので、苦しむこともなく楽しく制作ができました。
AIに関しては特に試行錯誤が必要になってくる分野なので、そこら辺もAI分野の醍醐味だよなと思います。