どうもエンジニアのirohasです。
日々AI開発エンジニアとして鍛錬を続けていますが、今回はKaggleの「digit-recognizerコンペ」にシンプルなNN(ニューラルネットワーク)モデルで挑み、98%越える高精度を叩き出したのでそれについての記事を書いていきます。
目次
1.はじめに
2.環境
3.ニューラルネットワークって何?
4.事前準備
5.実装
6.モデルの説明
7.精度
8.まとめ
1. はじめに
みなさんはKaggleというものをご存じでしょうか?
Kaggleは、データサイエンスと機械学習のコミュニティプラットフォームで、世界中の現役のAI開発エンジニアやデータサイエンティストはもちろんのこと、学生や、そこら辺の職種を志望している方などが日々研鑽を積んでいます。
主にKaggleでは以下のような多くの機能を提供しています:
コンペティション(Competition): 企業や研究機関が提供する実際の問題に対して、データサイエンティストが最良のモデルやソリューションを開発するための競技会。優勝者や上位の参加者は賞金や賞品を受け取ることができます。
データセット(Dataset): ユーザーが公開したり、共有したりする様々なデータセットにアクセスすることができます。これは研究や学習、プロジェクトのための素材として非常に役立ちます。
ノートブック(Notebook): ユーザーはKaggle上でJupyterノートブックを作成、実行、共有することができます。これはデータ解析やモデルの構築、学習の過程を他のユーザーと共有するためのものです。
ディスカッション(Disccusion): ユーザーはディスカッションフォーラムで質問をしたり、知識を共有したり、フィードバックを受け取ったりすることができます。
学習: Kaggleは「Kaggle Learn」というプラットフォームも提供しており、これはデータサイエンスの基礎から応用までの短いチュートリアルやコースが含まれています。
さらにKaggleにはそこでの成果に応じて、金・銀・銅の3種類のメダルが付与され、その数に応じてユーザーのランクも設定されます。
■Kaggleのランク
・Grand Master
・Master
・Expert
・Contributer
・Novice
Kaggleのランクは上記のように5つの段階があり、全員Noviceから始まり、Grand Masterが頂点に君臨しています。
KaggleのMasterランクですら、日本では200人程度しかいないとされており、上位ランクへの昇格のしにくさが見て取れます。
さらにこのランクは、上記4つの機能に個別で設定されており、それぞれでランク昇格の条件も異なります。
詳しくはこちら↓
https://www.kaggle.com/progression
2. 環境
PC: MacOS
言語: Python v3.10
GPU: T4 GPU
ライブラリ:
[標準ライブラリ]
なし
[外部ライブラリ]
Matplotlib
Numpy
Sklearn
Pandas
Torch
3. ニューラルネットワークって何?
Neural Network(ニューラルネットワーク)とは、人間の脳の神経細胞の接続に触発されて作られたAIモデルのことで、画像認識から自然言語処理、音声認識まで、様々な分野での応用が広がっています。
ニューラルネットワークの基本知識として、
ニューラルネットワークは、以下の要素から成り立っています。
ニューロン:情報を処理する基本的な単位。
各ニューロンは、複数の入力を受け取り、加重平均を計算した後、活性化関数を適用して出力を生成します。
重みとバイアス:これらは学習の際に調整されるパラメータで、ニューロンの入力とどのように関連するかを決定します。
活性化関数:ニューロンの出力値を制限または変換する非線形関数。例としては、シグモイド関数やTanh関数(ハイパボリックタンジェント関数)などがあります。
ニューラルネットワークの構造:
一般的なニューラルネットワークは、入力層、一つ以上の隠れ層、そして出力層から成り立っています。入力層はデータを受け取り、出力層は最終的な予測や分類の結果を返します。
隠れ層は、複雑なデータの特徴やパターンを捉える役割を果たしています。
ディープラーニング:
多数の隠れ層を持つニューラルネットワークを「ディープニューラルネットワーク」と呼びます。このような深いネットワークは、ディープラーニングとして知られる分野で主に使用されています。
4. 事前準備
kaggle以外で大会用のtrain、testデータを使用する場合はkaggleからローカルにデータを落とさなければならないので、まずはそれを行います。
kaggleで実装する場合は、直接データを使用できるので、特に準備は不要です。
5. 実装
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# データの読み込み
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
labels = train_data['label'].values
train_images = train_data.drop('label', axis=1).values.reshape(-1, 1, 28, 28).astype(np.float32) / 255.0
test_images = test_data.values.reshape(-1, 1, 28, 28).astype(np.float32) / 255.0
print(train_images.shape)
print(test_images.shape)
# データを学習用と評価用に分割
train_images, val_images, train_labels, val_labels = train_test_split(train_images, labels, test_size=0.2, random_state=42)
# DataLoaders
train_tensor = torch.utils.data.TensorDataset(torch.tensor(train_images), torch.tensor(train_labels))
val_tensor = torch.utils.data.TensorDataset(torch.tensor(val_images), torch.tensor(val_labels))
test_tensor = torch.utils.data.TensorDataset(torch.tensor(test_images))
train_loader = DataLoader(train_tensor, batch_size=32, shuffle=True)
val_loader = DataLoader(val_tensor, batch_size=32, shuffle=False)
test_loader = DataLoader(test_tensor, batch_size=32, shuffle=False)
# オリジナルニューラルネットワークを構築
class DigitCNN(nn.Module):
def __init__(self):
super(DigitCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.fc1 = nn.Linear(2304, 128)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(2)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.maxpool(x)
x = self.relu(self.conv2(x))
x = self.maxpool(x)
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
model = DigitCNN()
# GPU使用チェック
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
# optimizerなどの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習と検証のロスと精度を記録するリスト
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
# Training
num_epochs = 20
best_accuracy = 0.0 # 追加:最高の精度を記録するための変数
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, targets) in enumerate(train_loader):
data, targets = data.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
# Validation
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, targets in val_loader:
data, targets = data.to(device), targets.to(device)
outputs = model(data)
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
accuracy = 100. * correct / total
train_losses.append(loss.item()) # 学習ロスを追加
val_losses.append(criterion(outputs, targets).item()) # 検証ロスを追加
train_accuracies.append(100. * correct / (batch_idx * train_loader.batch_size)) # 学習精度を追加
val_accuracies.append(accuracy) # 検証精度を追加
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Accuracy: {accuracy:.2f}%")
# モデルの保存
if accuracy > best_accuracy:
best_accuracy = accuracy
torch.save(model.state_dict(), 'model/best_model.pth')
# ロスのグラフ
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Training Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 精度のグラフ
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Training Accuracy')
plt.plot(val_accuracies, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()
# 最高の精度を持つモデルをロード
model.load_state_dict(torch.load('model/best_model.pth'))
# テストデータでの予測
model.eval()
predictions_list = []
with torch.no_grad():
for (data,) in test_loader:
data = data.to(device)
outputs = model(data)
_, predicted = outputs.max(1)
predictions_list.extend(predicted.cpu().numpy())
predictions = np.array(predictions_list)
# 結果を保存するcsvの作成
submission = pd.DataFrame({'ImageId': range(1, len(predictions) + 1), 'Label': predictions})
submission.to_csv('result.csv', index=False)
6. モデルの説明
軽く今回作成したモデルの説明をしていきます。
class DigitCNN(nn.Module):
def __init__(self):
super(DigitCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.fc1 = nn.Linear(2304, 128)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(2)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.maxpool(x)
x = self.relu(self.conv2(x))
x = self.maxpool(x)
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
今回のモデルは、2つの畳み込み層と2つの全結合層を組み合わせたシンプルな構造で作成しました。
理由としては、手書き数字の識別には、複雑なネットワーク構造は必要としないからです。
他の理由としては、個人的には、「MNISTのような手書き数字データは、28x28ピクセルのグレースケール画像として提供されており、解像度は低いため、情報の量も限られているから学習しやすい」のと、「分類タスク自体が0~9の数字の10クラスのみであり、多クラスの問題ではないため、出力の複雑性が低いので、小さいモデルでも十分に精度が出せて、逆に複雑なモデルを使用すると過学習に陥ってしまう危険性がある」と考えています。
なので今回は、上記のような簡単なモデルで高い精度が見込めるのではないかと考えました。
今回のモデルを可視化したものが以下の画像になります。
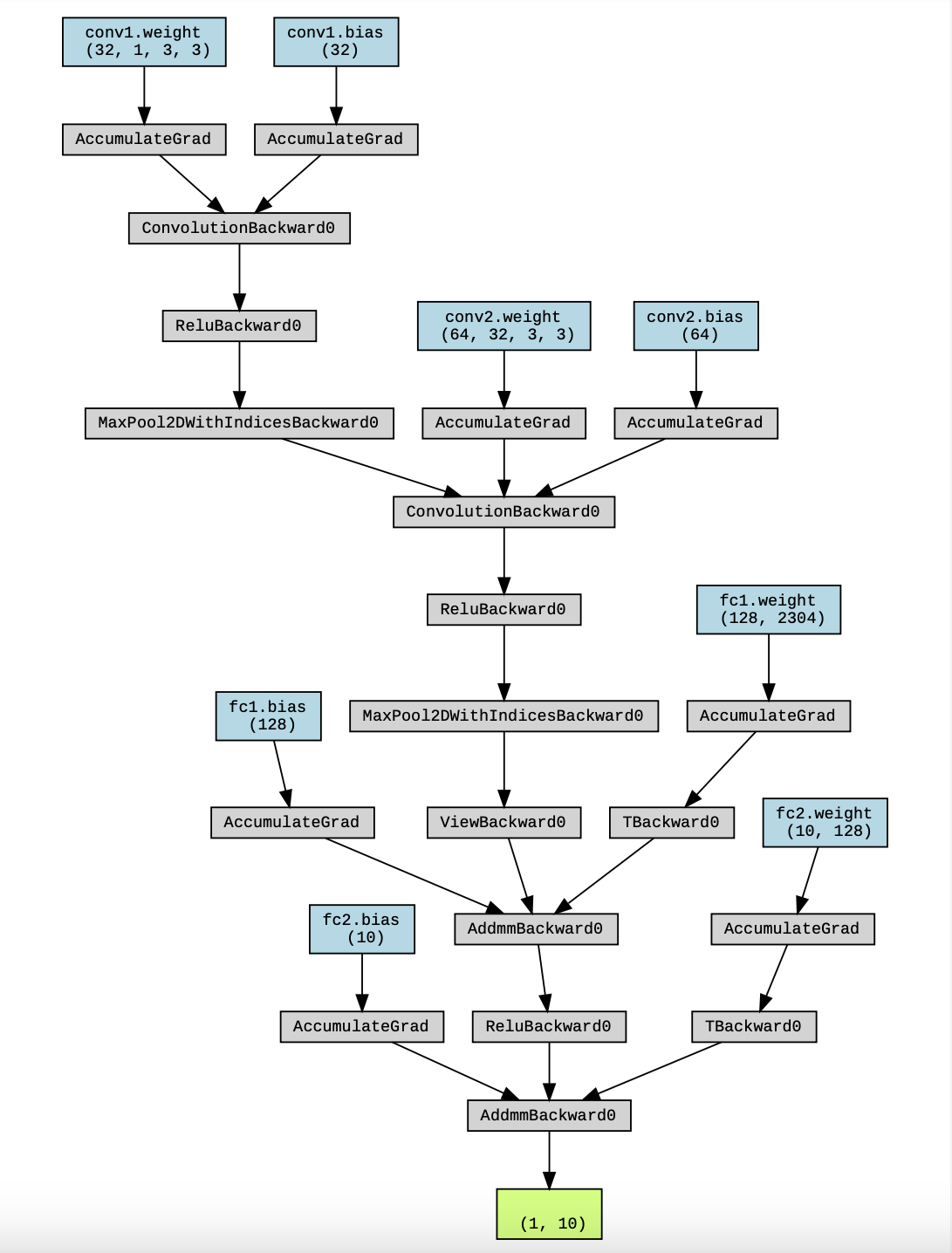
7. 精度
学習してみた結果が以下になります。
精度:
Epoch [1/20], Loss: 0.0458, Accuracy: 97.86%
Epoch [2/20], Loss: 0.1140, Accuracy: 98.29%
Epoch [3/20], Loss: 0.0026, Accuracy: 98.61%
Epoch [4/20], Loss: 0.0042, Accuracy: 98.52%
Epoch [5/20], Loss: 0.0058, Accuracy: 98.61%
Epoch [6/20], Loss: 0.0003, Accuracy: 98.77%
Epoch [7/20], Loss: 0.0019, Accuracy: 98.44%
Epoch [8/20], Loss: 0.0296, Accuracy: 98.94%
Epoch [9/20], Loss: 0.0000, Accuracy: 98.92%
Epoch [10/20], Loss: 0.0033, Accuracy: 98.92%
Epoch [11/20], Loss: 0.0023, Accuracy: 98.62%
Epoch [12/20], Loss: 0.0000, Accuracy: 98.56%
Epoch [13/20], Loss: 0.0236, Accuracy: 98.90%
Epoch [14/20], Loss: 0.0018, Accuracy: 98.90%
Epoch [15/20], Loss: 0.0003, Accuracy: 98.67%
Epoch [16/20], Loss: 0.0107, Accuracy: 99.07%
Epoch [17/20], Loss: 0.0062, Accuracy: 98.69%
Epoch [18/20], Loss: 0.0006, Accuracy: 98.61%
Epoch [19/20], Loss: 0.0922, Accuracy: 98.87%
Epoch [20/20], Loss: 0.0000, Accuracy: 99.10%
かなり高精度で学習できているのがわかりますね!
最終的には99.10%とほぼ文句なしの精度になっているので、モデルの作成において間違ってはいなかったことがわかります。
8. まとめ
このようにAI開発といっても、そのタスクやデータの大きさなどさまざまな要素に応じて使用するニューラルネットワークの中身は変えないといけないですし、当然ですが、同じモデルを使いませることの方がすくないため、自分でその時に応じて組み替えていかなければなりません。
最近AIブームがきているめ、これから機械学習やディープラーニングを学んで、AI開発エンジニアになろうと考えている方もうらっしゃると思いますが、一つだけ注意点を共有しておきたいと思います。
それは、AI開発のプログラムを覚えるだけじゃだめということです。
AI開発をする上で一番必要になってくるのは、行列や線形代数、微積などの数学的能力であると考えるからです。
結局、ニューラルネットワークにしても何にしてもやってることは"計算"なので、まずは以下に定式化できるか、それを使用して自由自在にモデルが組めるかが大事になってくると思います。
ですので、未経験からAI開発エンジニアになろうと考えている方はぜひ高校数学レベルからでいいので数学を学ぶことをおすすめします!