なぜ学び直すのかとその目的
学びの参考一覧
https://developer.mozilla.org/ja/docs/Web/API/NodeList
https://ginpen.com/2015/12/22/nodelist-vs-htmlcollection/
・書籍「JavaScript本格入門」p282~p293
getElementByIdとか、querySelectorとかを使う簡単なDOM操作には結構慣れてきました。
でも、複数のDOM操作をする場合にあまり効率よくできてないんじゃないかな?
と思うことがあります。itemやらバブリングやらを使いこなして、スッキリしたコードをかけるようになるべく再入門です。
HTMLコレクション
DOMを取得するにあたって、複数のものを習得した場合の戻り値の1つがHTMLCollectionです。
- getElementsByTagName
- getElementsByClassName
- getElementsByName
この辺の戻り値がHTMLCollectionになっています。
let myCollection = document.getElementsByTagName('meta');
console.log(myCollection);
こちらが結果になります。HTMLCollectionというプロトタイプを継承しています。
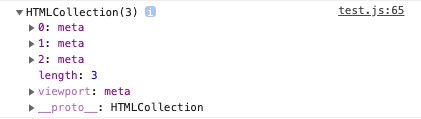
こいつらをうまく扱うためには、まず道具を知るべしです。
以下がHTMLCollecitonオブジェクトのメンバーになります。
| メンバー | 概要 |
|---|---|
| length | 要素数 |
| item(i) | i番目の要素(0 ~ length-1の範囲) |
| namedItem(name) | id,またはname属性が一致する要素の取得 |
let myCollection = document.getElementsByTagName('meta');
console.log(myCollection.item(2).content);
console.log(myCollection[2].content);
コードの2行目と3行目は同じ意味合いで、要はitemはブラケット構文でも記述できる、ということです。
もう1つのノードの集合体,NodeList
- Node.childNodes
- querySelectorAll
この辺の戻り値はNodeListと呼ばれるオブジェクトです。
HTMLCollectionと利用できるメンバーもほぼ同じですが、異なる点もあります。
異なる点としては、
HTMLCollectionは動的
NodeListは静的
ドユコトー?
だと思うので例を見てみましょう。
<div class="one"></div>
<div class="two"></div>
let myNodeList = document.querySelectorAll('div'); //ノードリスト
let myHTMLCollection = document.getElementsByClassName('bom'); //HTMLコレクション
let newNode = document.createElement('div');
newNode.classList.add('bom');
document.body.appendChild(newNode); //新しく<div class="bom"></div>を追加する
console.log(myNodeList.length); //戻り値 2
console.log(myHTMLCollection.length); //戻り値 3
NodeListは静的なので、取得後DOMの操作があってもそれが反映されていません。
対してHTMLCollectionは取得後のDOM操作も感知していて動的です。
ノードウォーキングについて
document.xxxxxっていう要素の取得って...
毎回毎回documentから辿ってってるわけじゃないですか。
例えば3階にある電気屋の炊飯器と冷蔵庫を見にきたのに、
「ここが3階で...あ、炊飯器だ! よし、また一階に戻って冷蔵庫を探そう!」
っていうのと同じでかなり無駄ですね。
そこで特定のノードを基点に相対的な位置関係からノード取得をする方法が役に立ちます。
ノードウォーキングと呼ばれています。
基点のノードをgetXXXX/queryXXXX 系で取得して、そこからノードウォーキングしていけば良さげです。
<body>
<form>
<label for="animal">動物を選んでね</label>
<select id="animal">
<option value="犬">犬</option>
<option value="ネコ">ネコ</option>
<option value="コモドオオトカゲ">コモドオオトカゲ</option>
</select>
</form>
</body>
let basePoint = document.getElementById('animal');
let opts = basePoint.childNodes; //ここに子要素以下が格納される
ただ注意しなければいけないのが、childNodesプロパティが取得するノードはNodeListである点と、ノードが要素ノードだけでない
という点です。空白ノードやテキストノードを含んでしまっています。
詳しくは下記のリンク等を参考にしてください。
https://www.javadrive.jp/javascript/dom/index4.html
以下、console.log(basePoint.childNodes)の結果です。

そこでnodeの種類を判別しなければなりませんね。
nodeTypeプロパティを使用すればそれができます!
nodeTypeで判別できるノードの種類はかなりのものがあるんですが、以下を抑えておけば実務では使えそうです。
| 戻り値 | ノードの種類 |
|---|---|
| 1 | 要素ノード |
| 2 | 属性ノード |
| 3 | テキストノード |
以上を踏まえて、上記のHTMLのoptionを取得してみます。
let basePoint = document.getElementById('animal');
let opts = basePoint.childNodes; //ノードウォーキングの基点
for(let i = 0;i < opts.length; i++){ //取得した全てのノードをチェック
if(opts[i].nodeType === 1){ //要素ノードなら
console.log(opts[i].value); //valueを出力
}
}
子要素リストのその他の取得方法
let child = baseNode.firstElementChild
while(child){
console.log(child.value);
child.nextElementSibling; //兄弟要素取得
}
firstElementChild・・・要素直下の最初の子要素を取得
nextElementSibling・・・要素の次の兄弟要素を取得
どちらも要素エレメントしか取得しないので、nodeType判定が不要な分スッキリしています。
このコードは子要素の兄弟エレメントがなくなるまでループをかけることで、子要素全てを取得していますね。
感想
とりあえず取得できればOK!で今までコーディングしてきたので、
ノードウォーキングはあまり意識していませんでした。今後の役に立ちそうです。
次回はイベント系の処理をしっかり学び直します!