この記事は
ミクシィグループ Advent Calendar 2020 23日目の記事です.
Adversarial examples の基礎を理解し,最新の動向を知ることを目標としています1.
ざっくりとした内容は以下の通りです.
- Adversarial examples を用いた DNN への攻撃と防御手法についての解説
- 最新動向:NeurIPS 2020 に投稿された論文の紹介
そもそものきっかけ
なんで今さら Adversarial examples なんだと言われそうですが,チームの技術共有会で Image-scaling attacks [QKA+2020] を知ったことがきっかけとなっています2.Adversarial examples による攻撃が現在どれほど行われているか知りませんが,多分今後も増えていくだろうし,一通り知っておいて損はないくらいのノリで調べました.最新手法は NeurIPS の論文眺めればいいでしょという投げやりな感じです(すみません).
ちなみに,Image-scaling attacks とは画像を小さくした時に全く異なる画像が浮かび上がるよう細工を施す手法です.下の図のようにフルサイズでは宮殿(画像左)ですが,リサイズするとハスキー犬(画像右)が出てきます.

(Image source: Machine Learning Attack Series: Image Scaling Attacks)
CNN などの識別器に入力するときはリサイズするのでハスキー犬が入力されていますし,なぜ間違ったのか確認しようとすると(フルサイズで行うため)宮殿の画像が出てきてしまう面白いノイズの加え方だなと思いました.
Adversarial Examples とは
Adversarial examples の代表例としてパンダをテナガザルに誤認識してしまうものがあります.ノイズの加わっていない左側の画像を画像識別モデルに入力すると正しくパンダと認識できるのですが,小さなノイズを加えた右側の画像を入力するとモデルはパンダと認識できなくなってしまいます(しかも99.3%の確信度でテナガザルと予測しています).
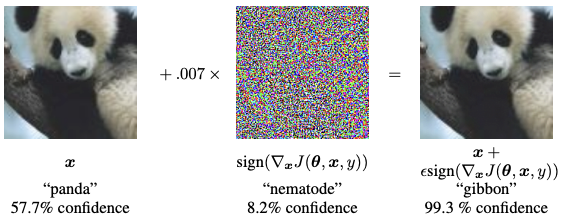
(Image Source: Explaining and Harnessing Adversarial Examples)
2つの例からわかる通り,Adversarial examples とは 機械学習モデルが予測を誤るよう加工されたデータを指します.またモデルの学習時に精度を悪化させるよう故意に混入させたデータも Adversarial examples と呼ばれます.
画像だけではなく,音声,テキスト,グラフなどでも Adversarial examples は作れます.例えば,対話システムで入力するテキストにタイポを混入させ,会話を突然破綻させることも可能です.
入力を調節してモデルに誤認識させるわけですから,もちろん故意に入力を調整する人がいるわけです.この攻撃側が用いる手法を Adversarial Attacks と呼び,その攻撃を防ぐ手法を Adversarial Defenses と呼びます.攻撃と防御の基礎的な内容と代表的手法について触れますが一部しか触れられていないので,一通り知りたい方はレビュー論文 [XMH+20] を読んでください.
1 Adversarial Attacks
ここでは Adversarial examples を生成する方法について見ていきます.
攻撃の対象は画像識別を行う DNN モデルで
- 入力:画像
- 出力:クラスラベル
を想定しています.
1.1 攻撃の分類
Adversarial attacks といっても
- データの入れるタイミング
- ターゲットラベルの有無
- 攻撃側が得られる知識
によって異なる呼ばれ方をするときがあり,論文を読む時に少し混乱するので簡単に説明します.
データの入れるタイミング
データの入れるタイミングによって,学習済みモデルへの攻撃か学習時のモデルへの攻撃か変わってきます.
-
Evasion attack
- 学習済みモデルに対して,入力データを加工して誤った予測をさせる
-
Poisoning attack
- 学習データにフェイクデータを混入させて,モデルそのものの精度を低下させる
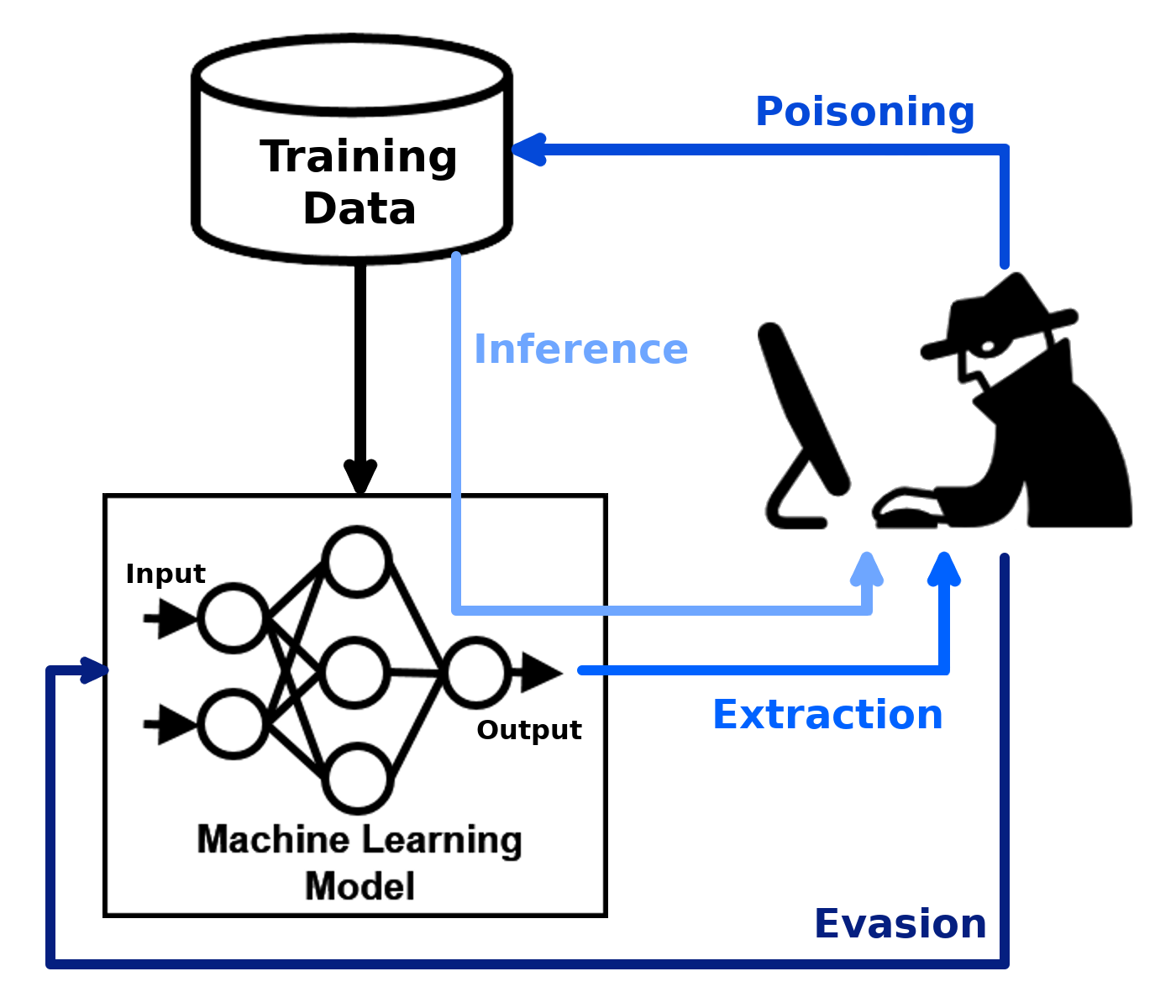 (Image Source: [Adversarial Robustness Toolbox](https://adversarial-robustness-toolbox.readthedocs.io/en/stable/))
(Image Source: [Adversarial Robustness Toolbox](https://adversarial-robustness-toolbox.readthedocs.io/en/stable/))
Poisoning attack は Backdoor attack とも関係し面白い内容なのですが今回は取りあげません.Backdoor attack は事前にモデルを細工しておいて,トリガー付きのデータが入力された時に変な予測をさせてしまう攻撃手法です.そちらに興味ある方は [GDZ+20] やこれの 日本語解説記事 を見てください.
ターゲットラベルの有無
単に正解ラベルを当てられないようにすれば良い場合もあれば,パンダをテナガザルへ誤認識させるみたいに特定のラベル(ターゲットラベル)へと予測させたい場合もあります.
-
Target attack
- モデルの出力をターゲットラベル $t$ へと変更させてしまう
-
Non-target attack
- どのラベルでも良いのでモデルに誤った予測をさせる
ちなみに,ターゲットラベル $t$ をランダムに選ぶ場合もありますし,( $t = \arg\min_yp(y|x)$ のように)最も発生しづらいラベルをターゲットラベルとする場合もあります.
攻撃側が得られる情報
攻撃する側がモデルに関する情報をどれだけ得られるかによって攻撃の仕方は変わり,それぞれ以下の名前で呼びます.
-
White-box attack
- ターゲットとなるモデルの全ての情報(ネットワークの構造や重みの値など)にアクセスできる
- この攻撃に対する防御機能は全てのモデルが持っておくべきとされている
-
Black-box attack
- DNN モデルの構成や重みを知ることはできない
- 入力と出力 ( $+\alpha$ ) の情報のみを使って攻撃を行う
-
Semi-white (grey) box attack
- White-box の設定の下で生成モデルを学習させる
- 生成モデルが一度できたら Black-box の設定で Adversarial examples を作る
White-box attack と Black-box attack の分類に従って具体的な攻撃方法について見ていきます.その後に物理空間上での Adversarial attacks についても解説します.
1.2 White-box attack
White-box attack は攻撃側が対象の全ての情報にアクセス可能な設定での攻撃です.すなわち攻撃側は,識別器 $C$(モデル $F$)と攻撃するサンプル $(x,y)$ の情報を得られる設定の下で,
$$
\|x^\prime - x|| \le \epsilon\hspace{10pt}\mbox{s.t.}\hspace{7pt}C(x^\prime) = t \neq y
$$
を満たす $x^\prime$ を探します.識別器 $C$ は CNN などの画像識別モデルを表していて,この式は識別器 $C$ に画像を入力した時,出力として正解ラベルの $y$ ではなく,ターゲットラベル $t$ が出力されるような小さなノイズを加えた画像 $x^\prime$ を探すことを意味します.$\|x-x^\prime\|$ は元の画像 $x$ とノイズを加えた画像 $x^\prime$ の差を測ることを表していて,大抵は $L_p$ ノルムが使われます3.この問題は損失関数 $\mathcal{L}(x^\prime, t)$ を用いて
$$
x^{\rm adv} = \mathop{\rm arg~min}\limits_{x^\prime}\mathcal{L}(x^\prime, t)\hspace{10pt}\mbox{s.t.}\hspace{7pt}
\|x^\prime - x|| \le \epsilon.
$$
と書くこともできます.$\epsilon$ はノイズの大きさをコントロールするパラメータです.Non-target attack の場合,$x^\prime$ を入力した時に正解ラベル $y$ だけは出力して欲しくないので $(x,y)$ の組み合わせのロスの値が大きくなるようにします.
$$
x^{\rm adv} = \mathop{\rm arg~max}\limits_{x^\prime}\mathcal{L}(x^\prime, y)\hspace{10pt}\mbox{s.t.}\hspace{7pt}
\|x^\prime - x|| \le \epsilon.
$$
ちなみに,現在の多くの Adversarial examples は取り扱いの良さからノイズ $\delta$ を単純に足し合わせて作ります.
$$
x^\prime = x + \delta
$$
したがって,Non-target attack の場合の $x^{\rm adv}$ を $\delta$ を用いて書くと以下のようになります.
\begin{align}
x^{\rm adv} &= x + \delta^{\rm adv}\\
\delta^{\rm adv} &= \mathop{\rm arg~max}\limits_\delta\mathcal{L}(x+\delta, y)\hspace{10pt}\mbox{s.t.}\hspace{7pt}\|\delta\| \le \epsilon.
\end{align}
これから紹介する例はどれもノイズを足し合わせて作られています.
Fast gradient sign method(FGSM)
1つ目はパンダをテナガザルに誤認識させた時に使われた手法です[GSS15].TensorFlow も PyTorch も解説付きの実装があるので見てみてください.
- [Tensorflow] Adversarial example using FGSM
- [PyTorch] ADVERSARIAL EXAMPLE GENERATION
FGSM は次の式にしたがって Adversarial examples を1ステップで生成します.
\begin{align}
x^{\rm adv} &= x + \epsilon\ {\rm sgn}(\nabla_x\mathcal{L}(\theta, x, y)),\hspace{10pt}\mbox{Non-target attack}\\
x^{\rm adv} &= x - \epsilon\ {\rm sgn}(\nabla_x\mathcal{L}(\theta, x, t)),\hspace{11pt}\mbox{Target attack}
\end{align}
$\theta$ はネットワークの重みを表しています.
Non-target attack の場合,$x$ を入力した時にモデルに $y$ と予測してほしくないので $\mathcal{L}(\theta, x, y)$ が大きくなる方向に $\epsilon$ だけ勾配上昇させます.Target attack の場合,入力 $x$ を入れた時に $t$ と予測させたいので $\mathcal{L}(\theta, x, t)$ が小さくなる方向に $\epsilon$ だけ勾配降下させます.これは1ステップの勾配降下法であり,
$$
\min\mathcal{L}(\theta, x^\prime, t)
\hspace{10pt}\mbox{s.t.}\hspace{7pt}\|x^\prime-x\|_\infty\le\epsilon
\hspace{7pt}\mbox{and}\hspace{7pt}x^\prime\in[0,1]^m.
$$
と書けます.$L_\infty$ノルムなので各画素の値を最大 $\epsilon$ だけ変えられることができ,その中でロスの値が最も小さくなる修正画像 $x^\prime$ を探していることになります.
Basic iterative method
Iterative に FGSM を適用して Adversarial examples を生成すること行うこともできます.[KGB17a] [KGB17b] では各ステップで最大 $\alpha$ だけ画素の値を変えて(かつ元の画像から $\epsilon$ 以上変化しないようにして)生成します.
x_0^{\rm adv} = x,\hspace{10pt}x_{n+1}^{\rm adv} =
{\rm Clip}_{x,\epsilon} \{x_n^{\rm adv} + \alpha\ {\rm sgn}
(\nabla_x\mathcal{L}(x_n^{\rm adv}, y))\}
${\rm Clip}_{x,\epsilon}$ は元の画像 $x$ から各画素の値を $\epsilon$ 以上動かさないための処理です.論文では,$\alpha=1$ として毎回画素の値を1ずつ変化させて Adversarial examples を作っています. またイテレーション回数は $\min(\epsilon+4, 1.25\epsilon)$ として決めます.Iterative に生成する方が攻撃性能は高いのですが,Transferabilityは低いとされています.Transferability は,あるモデルに向けて作った Adversarial examples が他のモデルに対しても攻撃として通用する度合いを表していて,Black-box attacks でキーとなる性質です.
Carlini & Wagner's attack
この手法は,FGSM などの攻撃手法を防ぐ Adversarial defenses に対しての反撃として考案されました [CW17a].Carlini & Wagner's attack では以下の最適化問題を解きます.
$$
\min \|x-x^\prime\|_2^2+cf(x^\prime,t)\hspace{10pt}\mbox{s.t.}\hspace{7pt}x^\prime\in[0,1]^m.
$$
$f(x^\prime,t)$ はマージンロスで次の式で定義されます.
f(x^\prime,t)=\max\bigl(0, \max_{i\neq t}Z(x^\prime)_i-Z(x^\prime)_t\bigr)
$Z(x^\prime)_i$ はラベル $i$ のスコアを表しているので,$f(x^\prime,t)$ はターゲットラベル $t$ よりも別のラベルが大きなスコアをとる時にペナルティを課す形となっています.この攻撃は様々な防御手法を掻い潜ってきたため,モデルの安全性を調べる時のベンチマークとなっています.
Universal attack
通常はある1つの入力データ $x$ にノイズを加えてそれを誤認識させますが,[MFF+17] では,テストデータのほとんどで誤認識されるようなノイズがあることを見つけました.具体的には以下を満たすノイズ $\delta$ を探します.
$$
\|\delta\|_p\le\epsilon,\hspace{10pt}\mbox{and}\hspace{7pt}
\underset{x\sim D(x)}{\mathbb{P}}(C(x+\delta)\neq C(x)) \ge 1 - \sigma.
$$
$\epsilon$ はノイズの大きさ,$\sigma$ は求めたい精度のコントロールパラメータとなっています.結果として ILSVRC2012 のテストサンプルのうち 85.4% の誤認識に成功させました.以下の画像は誤認識させた例の一部です.

(Image Source: Universal adversarial perturbations)
1.3 Black-box attack
ネットワークの構造や重みがわからず,攻撃する側は以下の情報しか知り得ないとします.
- 入力 $x$ と出力された識別結果 $y$
- データのドメイン(顔認識なのか,手書き文字認識なのかなど)
- ネットワークの種類(CNN,RNNなど)
このような設定は API で提供されるモデルへの攻撃を想定しているためです.
攻撃概要
[PMG+17] では Transferability に注目して攻撃を行っています.すなわち,あるモデルへの攻撃は似ている別のモデルへの攻撃にもなるという性質を用います4.行うことはシンプルで
- 代替モデル $F^\prime$ を作成
- $F^\prime$ に対して White-box attack の手法を使って Adversarial examples を作る
だけです.そして作られた Adversarial examples は攻撃対象のモデル $F$ に対しても有効(なはず)です.
代替モデルの作り方
少々めんどくさいのは代替モデル $F^\prime$ を作る部分で以下の図の手順で行います.

(Image Source: Practical Black-Box Attacks against Machine Learning)
- データを集める(例えばタスクが顔認識とわかっているなら自分で顔写真を集める)
- 仮のモデル $F^\prime$ のネットワーク構造を決める
- 手順1で集めたデータ $x$ を実際のモデル $F$ に入力して,出力結果を正解ラベル $y$ とする
- 作成したデータセットで仮のモデル $F^\prime$ を学習させる
- Data Augmentation によりデータをかさ増し
- 手順 3-5 を繰り返し行い $F^\prime$ を学習させる
確信度が出力される場合
ここまでの想定では出力は予測ラベルのみでしたが,出力情報として各クラスの確信度が得られる場合はより簡単に攻撃を行うことができます [CZS+17].入力 $x$ を少しずらすとモデル $F$ の勾配情報を得ることができるため,そこから FGSM や Carlini & Wagner's attack などの White-box attack の手法を用いて Adversarial example を作ります.
1.4 Physical world attack
ここまでデジタル画像の Adversarial examples の作り方を見てきましたが,物理空間上での例について見ていきます.[KGB17b] では,デジタル画像の Adversarial examples を一度プリントしてカメラで撮影した画像に対してもモデルが誤認識することが報告されています.下の画像にある通り,ノイズの強さ $\epsilon$ が大きい右側では洗濯機をスピーカーと勘違いしています.

(Image Source: Adversarial examples in the physical world)
Adversarial examples は光の入り方や見る角度にロバストであり,物理空間でも簡単に誤認識を引き起こせてしまうことも報告されています.その後,標識にシールを貼ることで標識と認識させない攻撃手法が提案されました [EEF+18].

(Image Source: Robust Physical-World Attacks on Deep Learning Visual Classification)
このシールは
- シールを貼る位置を $L_1$ノルムベースの(制約条件が $\|x-x^\prime\|_1\le\epsilon$ である)攻撃で判定し
- 貼る位置が決まった後に,そのシールの色を $L_2$ノルムベースの攻撃で生成する
という手順で作られているそうです.さらに 3D プリントでも Adversarial examples を作る例が報告されています [AEI18].

(Image Source: Synthesizing Robust Adversarial Examples)
画像から分かる通り,亀の 3D プリントをライフル銃と誤認識してしまっています.
ここまで複数の例から Adversarial examples は外的要因に対してかなりロバストであることがわかったと思います.では次にモデル自体がどの程度 Adversarial examples に対してロバストであるかを測る指標について見ていきましょう.
2 評価基準
モデルがどの程度 Adversarial examples に耐性があるか,ノイズの大きさの観点から見ていきます.これは
-
Global robustness
- どの程度のノイズを加えると誤った予測をするか
-
Adversarial risk(Global adversarial loss)
- ある大きさのノイズを加えた時,どの程度誤認識するか
の2点で測ることができます.以下でそれぞれの定義について述べます.
2.1 Global robustness
Global robustness は,モデルがどの程度のノイズで誤認識を起こすかを測る指標です.ノイズへの強度を測るため,初めに Minimal perturbation という指標を導入します.これは次の式で定義されます.
$$
\delta_\min:=\mathop{\rm arg~min}\limits_\delta\|\delta\|_p
\hspace{10pt}\mbox{s.t.}\hspace{5pt}C(x+\delta) \neq y.
$$
そして,Minimal perturbation のノルムを取ったものを Robustness と呼びます.
$$
r(x,F) := \|\delta_\min\|_p
$$
Robustness は入力データ $x$ に依存します.これをデータに関して期待値をとったものが Global Robustness です.
$$
\rho(F) := \mathop{\mathbb{E}}\limits_{x\sim\mathcal{D}}r(x,F)
$$
この値が小さければ小さいほど,微小な変更で誤った予測をしてしまうことになります.
2.2 Adversarial risk
Adversarial risk は大きさ $\epsilon$ までのノイズを加えた時に,データ全体としてどの程度誤った予測を行うかを表す指標です.元のデータ点 $x$ と近いところで最もロスの値が高くなってしまう点を Most-adversarial example と呼び,以下のように定義します.
$$
x^{\rm adv}:=\mathop{\rm arg~max}\limits_{x^\prime}\mathcal{L}(\theta, x^\prime, y)
\hspace{10pt}\mbox{s.t.}\hspace{5pt}\|x^\prime - x \|\le\epsilon.
$$
$\theta$ は識別器 $F$ のネットワークの重みです.そして,$x^{\rm adv}$ でのロスの値を Adversarial loss $\mathcal{L_{\rm adv}}$ と呼びます.
$$
\mathcal{L_{\rm adv}}:=\mathcal{L}(x^{\rm adv})=\mathop{\max}\limits_{\|x^\prime -x\|\le\epsilon}\mathcal{L}(\theta, x^\prime, y)
$$
Adversarial loss をデータに関して期待値をとったものが Adversarial risk です.
$$
\mathcal{R_{\rm adv}}(F) := \mathop{\mathbb{E}}\limits_{x\sim\mathcal{D}}\mathcal{L_{\rm adv}}
$$
この値が大きければ大きいほど,データセットの中の多くで誤認識を起こせることになります.
3 Adversarial Defenses
ここでは Adversarial examples を防御する方法について見ていきます.
3.1 防御方法の種類
防御方法には大きく分けて次の3つがあります.
-
Gradient masking/obfuscation
- ネットワークの勾配情報をマスクしてしまう
-
Robust optimization
- モデル自体をロバストにしてしまう
-
Adversary detection
- モデルに入力する前に Adversarial Examples かどうかチェックする
3.2 Gradient masking/obfuscation
多くの攻撃は識別器の勾配情報を用いるため,その情報を隠すことで防御を行います.
微分不可能にする方法
入力に non-smooth な関数 $g(x)$ を挟むことで,識別器 $C(g(x))$ 全体を $x$ について微分不可能にさせます.例えば Thermometer encoding [BRR+18] では,画像のピクセル値 $x_i$ を $l$ 次元のベクトルへと離散化します(例えば,$l=10$ の時 $\tau(0.66) = 0000001111$ といった感じです).
蒸留を用いた方法
蒸留を用いて勾配情報を隠してしまう方法もあります [PMW+16].蒸留では温度パラメータ $T$ を含んだ温度付きソフトマックス
$$
{\rm softmax}(x_i, T) = \frac{\exp(x_i/T)}{\sum_j\exp(x_j/T)}
$$
を用いて以下の図の手順で学習を行います.左側が教師モデルの学習,右側が生徒モデルの学習手順となっています.
 (Image Source: [Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks](https://ieeexplore.ieee.org/document/7546524))
(Image Source: [Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks](https://ieeexplore.ieee.org/document/7546524))
生徒モデルの学習までずっと温度パラメータを $T$ を1より大きな値としておきますが,予測時には $T=1$ まで温度を下げて,あるラベルがほぼ1で他はほぼ0という出力にさせます.結果として,この生徒モデルは勾配情報をうまく隠して Adversarial attacks を防ぎます.
複数のモデルを使う
複数のモデルを作って,評価時にランダムにモデルを選択し予測を行うことで防ぐ方法もあります.複数のモデルの作り方の例として,ニューロンをランダムに除く方法があります [DAL+18].
注意点
Gradient masking/obfuscation は攻撃する人を惑わすだけで,Adversarial examples の攻撃を無効にはできていない点に注意すべきです.[CW17a] では脆弱性が指摘されていて,[ACW18] ではこのタイプの防御をすり抜ける攻撃手法が提案されています.
3.3 Robust optimization
Robust optimization は学習方法を修正して Adversarial examples に対してモデル自体をロバストにする手法です.具体的にやることは以下の2つのどちらかです.
- Adversarial risk を最小化するよう学習させる
\begin{align}
\theta^*
&=\mathop{\rm arg~min}\limits_{\theta\in\Theta}\mathcal{R_{\rm adv}}(\theta)\\
&=\mathop{\rm arg~min}\limits_{\theta\in\Theta}\underset{x\sim D(x)}{\mathbb{E}}\underset{\|x^\prime - x\|\le \epsilon}{\max}\mathcal{L}(\theta, x^\prime, y)
\end{align}
- Global robustness を最大化するよう学習させる
\begin{align}
\theta^*
&=\mathop{\rm arg~max}\limits_{\theta\in\Theta}\rho(\theta)\\
&=\mathop{\rm arg~max}\limits_{\theta\in\Theta}\underset{x\sim D(x)}{\mathbb{E}}\underset{C(x^\prime)\neq y}{\min}\|x^\prime - x\|_p
\end{align}
評価基準の項目で見た通り,Adversarial risk が小さければ誤認識するデータは減り,Global robustness が大きければ誤認識させるために大きめの修正が必要となります.そこで,これらを強めるようネットワークの重みを調整します.
ノイズに対して強くする
ノイズを少し付加しただけで識別結果が大きく異なってしまうモデルは良くないので,[BSS+14] では各層にリプシッツ定数による制約を課してノイズに強くさせます.
$$
\forall x,\ r,\hspace{10pt}\|\phi_k(x;W_k)-\phi_k(x+r;W_k)\|\le L_k\|\delta\|
$$
この制約により Adversarial risk は次の値で抑えられます.
\begin{align}
\mathcal{R}_{\rm adv}&=\underset{x\sim D(x)}{\mathbb{E}}\left(\mathop{\max}\limits_{\|x^\prime -x\|<\epsilon}\mathcal{L}(F(x^\prime), y)\right)\\
&\le \underset{x\sim D(x)}{\mathbb{E}}\mathcal{L}(x) + \underset{x\sim D(x)}{\mathbb{E}}\left(\underset{\|x^\prime - x\|< \epsilon}{\max}|\mathcal{L}(F(x^\prime),y)-\mathcal{L}(F(x),y)|\right)\\
&\le \underset{x\sim D(x)}{\mathbb{E}}\mathcal{L}(x) + \lambda_p\prod_{k=1}^K L_k
\end{align}
ここで $\lambda_p$ は損失関数のリプシッツ定数です.3行目を見ると,Adversarial examples の効果はリプシッツ定数の積 $\lambda_p\prod_{k=1}^K L_k$ で抑えられていることがわかります.結果として Adversarial examples に対してもロバストになります.
Adversarial training
Adversarial attacks では,Adversarial example $x^\prime$ をモデルに入力した時に正解ラベル $y$ を予測しないよう損失関数 $\mathcal{L}(x^\prime, y)$ を大きくするよう学習を行いました.Adversarial training では,$x^\prime$ が $y$ と対応づけられるように学習を行います.
FGSM を用いた Adversarial training は,次の手順で収束するまで行います [KGB17a].
- ミニバッチ $B=\{x_1,x_2,...,x_m\}$ を読み込む
- $\{x_1,x_2,...,x_m\}$ から $k$ 個の Adversarial examples $\{x_1^{\rm adv},x_2^{\rm adv},...,x_k^{\rm adv}\}$ を生成する
- $k$ 個を生成したものと置き換える $B^\prime=\{x_1^{\rm adv},x_2^{\rm adv},...,x_k^{\rm adv},x_{k+1},...,x_m\}$
- $B^\prime$ を使って学習を行う.
ちなみに,ここでの損失関数 $\mathcal{L}_{\rm AT}$ は以下のものを使います.
\mathcal{L}_{\rm AT}=\frac{1}{(m-k)+\lambda k}\left(\sum_{i=k+1}^m\mathcal{L}(x^i,y^i)+\sum_{j=1}^k\lambda\mathcal{L}(x_j^{\rm adv},y^j)\right)
$\lambda$ はどの程度 Adversarial example を重視するかのパラメータで,論文では $\lambda = 0.3$ としています.
この手法は FGSM attack に対してロバストであることが確認されていますが,他の攻撃手法への脆弱性が指摘されています.そのため,複数のモデルから Adversarial examples を作りロバストにする方法が提案されました [TKP+18].その提案手法では,ロバストにしたいモデル $F$ のハイパーパラメータを少し変えた複数のモデルを作り,それら複数のモデルから Adversarial examples を生成して,生成したものを用いて Adversarial risk を小さくするようモデル $F$ の学習を行います.
3.4 Adversarial examples の検出
モデルへの入力を直に予測するのではなく,データが Adversarial かどうかを判定し,Adversarial な場合は予測を行わないようにします.
判別モデルの追加
Adversarial examples かどうかを判別できたら良いので,
[MGF+17] では下の図にある通り,学習された識別モデルのある隠れ層の情報を用いて補助ネットワークで判別を行わせていました.論文による AD(2)が最も精度高く検出できてたそうです.
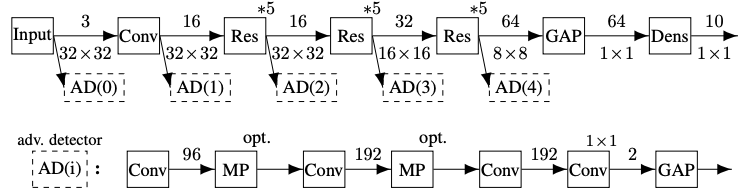
(Image Source: On Detecting Adversarial Perturbations)
他にも主成分分析 [HG17] や Maximum Mean Discrepancy [GMP+17] を使って判別する方法も提案されています.
予測結果の変化による判定
自然な画像の場合,モデルのパラメータや入力データを少し変更しても安定的に予測するだろうという期待から,それらの操作を行った時に識別結果が変わるかどうかから判定します.[FCS+17] では,ドロップアウトを使ってモデルを修正した時に識別結果が変わるかを見ます.[XEQ18] では,画像の色深度(表現可能な色の多さ)を減らしていった時に識別結果が変わるかを見ます.
ここまで検出手法を見てきましたが,[CW17b] では,この当時の Adversarial examples を検出する手法全てに対して検出を逃れることが可能であることが指摘されています.
4 NeurIPS2020 から見る Adversarial examples 最新動向
何個か論文をピックアップしてそれの簡単な解説を行います.少ない情報で攻撃をする手法やより巧妙な攻撃手法やが出てきている一方,Adversarial examples に対して人間がロバストであるという事実に光が当たってきていて,より良いモデルがここから提案されて欲しいなと思いました(アホっぽい感想).
画像のブレによる攻撃
| Title | Watch out! Motion is Blurring the Vision of Your Deep Neural Networks |
|---|---|
| Authors | Qing Guo, Felix Juefei-Xu, Xiaofei Xie, Lei Ma, Jian Wang, Bing Yu, Wei Feng, Yang Liu |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/0a73de68f10e15626eb98701ecf03adb-Abstract.html |
| Code | https://github.com/tsingqguo/ABBA |
視覚的に自然でもっともらしい(動きによる)ブレを用いた Adversarial examples を生成できる新たな手法を提案しています.著者たちはノイズを単純に足すのではなく,より複雑な操作ができるようカーネルで重み付けします.
$$
x_p^{\rm adv} = \sum_{q\in\mathcal{N}(p)}x_q k_{qp}
\hspace{10pt}\left(\sum_{q\in\mathcal{N}(p)}k_{qp}=1\right)
$$
ここで $x_p$ は画像 $x$ の $p$ 番目のピクセルを,$\mathcal{N}(p)$ は画像のピクセルの集合を表しています.例えば,$\mathcal{N}(p)$ として $p$ の周囲をとり,カーネル $k_{qp}$ としてガウスカーネルを取れば,$x^{\rm adv}$ はガウシアンぼかしのある画像となります.
この論文では,以下の最適化問題を解くことでブレの Adversarial examples を生成します.
\begin{align}
\mathop{\rm arg~max}\limits_\mathcal{K}\mathcal{L}((\sum_{q\in\mathcal{N}(p)}x_q k_{qp}),y)
\hspace{10pt}\mbox{s.t.}\hspace{5pt}\forall p,\hspace{3pt}\|k_p\|_0\le\epsilon,
\hspace{5pt}\max(k_p)=k_{pp},\hspace{3pt}
\sum_{q\in\mathcal{N}(p)}k_{qp}=1
\end{align}
ただし,これだけでは自然なブレ画像とならないため,「どの部分がどう動くのが自然か」を saliency map を利用して考慮します(図のダチョウの部分を PoolNet を使って検出している).
 (Image source: [Watch out! Motion is Blurring the Vision of Your Deep Neural Networks](https://proceedings.neurips.cc/paper/2020/hash/0a73de68f10e15626eb98701ecf03adb-Abstract.html))
(Image source: [Watch out! Motion is Blurring the Vision of Your Deep Neural Networks](https://proceedings.neurips.cc/paper/2020/hash/0a73de68f10e15626eb98701ecf03adb-Abstract.html))
またこの手法の移動情報を用いて,実際に携帯のカメラを動かしてブレのある画像を撮影した結果,(Transferability は高くないものの)85.3%の確率で誤認識させることに成功しています.
少数の変更による攻撃
| Title | GreedyFool: Distortion-Aware Sparse Adversarial Attack |
|---|---|
| Authors | Xiaoyi Dong, Dongdong Chen, Jianmin Bao, Chuan Qin, Lu Yuan, Weiming Zhang, Nenghai Yu, Dong Chen |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/8169e05e2a0debcb15458f2cc1eff0ea-Abstract.html |
| Code | https://github.com/LightDXY/GreedyFool |
| $L_2$ または $L_\infty$ ベースの攻撃では画像の全ピクセルを変化させて Adversarial examples を作りますが,$L_0$ ベースの攻撃では一部のピクセルのみを変化させます(この $L_0$ ベースの攻撃を疎な攻撃と呼びます).この論文ではより少ないピクセルの変化のみで攻撃できるようにするため |
- 勾配情報から $k$ 個のピクセルを選択
- Greedy search で不必要な点を探索・削除
という2段階の手順で Adversarial examples を作ることを提案しています.さらに,疎な攻撃では変化させた場所がはっきり見えてしまいがちですが,それを隠すために画像のどの点を修正すべきかガイドする画像の歪み情報を GAN に基づいて学習させています.結果としてより少数のピクセルの変更かつ,その変更がわかりづらい Adversarial examples の生成に成功しています(下の図参照).
 (Image source: [GreedyFool: Distortion-Aware Sparse Adversarial Attack](https://proceedings.neurips.cc/paper/2020/hash/8169e05e2a0debcb15458f2cc1eff0ea-Abstract.html))
(Image source: [GreedyFool: Distortion-Aware Sparse Adversarial Attack](https://proceedings.neurips.cc/paper/2020/hash/8169e05e2a0debcb15458f2cc1eff0ea-Abstract.html))
この画像から少ないピクセルの点の自然な変更で Adversarial examples を作れていることがわかります.その結果,攻撃の成功率も向上しています.
新たな状況設定での攻撃
| Title | Practical No-box Adversarial Attacks against DNNs |
|---|---|
| Authors | Qizhang Li, Yiwen Guo, Hao Chen |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/96e07156db854ca7b00b5df21716b0c6-Abstract.html |
| Code | https://github.com/qizhangli/nobox-attacks |
| No-box と言われる攻撃側がモデル情報や学習データセットにアクセスすることもモデルへクエリを投げることもできない設定での Adversarial examples について実用的な手法を提案しています.学習データへのアクセスもモデルにたくさんクエリを投げることもできませんが,数十件程度の少数の例のみ収集できるとしています.このような場合は Black-box attack で解説した代替モデル $F^\prime$ を作ることができないため,著者らは Auto encoder を用いて画像の特徴を抽出するとともに,少数のデータを使って教師あり学習を行い攻撃手法を開発しました. |
 (Image source: [Practical No-box Adversarial Attacks against DNNs](https://proceedings.neurips.cc/paper/2020/hash/96e07156db854ca7b00b5df21716b0c6-Abstract.html))
(Image source: [Practical No-box Adversarial Attacks against DNNs](https://proceedings.neurips.cc/paper/2020/hash/96e07156db854ca7b00b5df21716b0c6-Abstract.html))
この画像の上部は予測モデルの学習に用いるテクニックを,下はネットワーク構造を表しています.予測モデルの学習には,2つの教師なし学習(回転とパズルのような変形を元に戻す学習)と1つの教師あり学習(プロトタイプのデータでラベルと対応づける学習)を用います.モデルができたらあとは既存の White-box attacks のアプローチで Adversarial examples を作ります.clarifai.com のセレブの顔認識システムで,10枚の顔画像のみを使用して予測精度を100.00%からわずか15.40%にまで低下できたそうです.
防御手法のロバストな評価に向けて
| Title | On Adaptive Attacks to Adversarial Example Defenses |
|---|---|
| Authors | Florian Tramer, Nicholas Carlini, Wieland Brendel, Aleksander Madry |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/11f38f8ecd71867b42433548d1078e38-Abstract.html |
| Code | https://github.com/wielandbrendel/adaptive_attacks_paper |
| 2018年以降の ICLR, ICML, NeurIPS で発表された 13 の Adversarial defenses 手法に対しての評価方法には欠点があることを指摘し,別の攻撃を行うことで元の評価で報告されていた値よりも精度が低下することを示しています. |
著者らは防御手法の重要な部分を特定し極力シンプルな攻撃によって,それら手法の報告された値よりも防御の精度が下がることを示しました(13 本中 12 本の論文の著者には連絡が取れ,実際に攻撃が有効であること認めてもらった).この論文の目的は,研究者がより綿密な評価を行えるよう支援することだそうで,実際のシステムやユーザを攻撃することには焦点を当てていないそうです.
視覚的機構からロバストなモデルを作る
| Title | Biologically Inspired Mechanisms for Adversarial Robustness |
|---|---|
| Authors | Manish Vuyyuru Reddy, Andrzej Banburski, Nishka Pant, Tomaso Poggio |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/17256f049f1e3fede17c7a313f7657f4-Abstract.html |
| Code | https://github.com/WildTangles/adversary |
| 人間の視覚は視覚刺激の小さな摂動に対してロバストであり,人工ニューラルネットワークが霊長類の脳の腹側視覚の流れのモデルとして適していることが計算と実験の研究から明らかになってきているそうです.このことから著者たちは,まだ現在の画像認識モデルには組み込まれていない生物学的視覚の側面が Adversarial examples に対するロバスト性を向上させるかどうかを調べました. |
生物学的に示唆された2つのメカニズム
- 視細胞による視覚刺激の不均一な空間的サンプリング
- V1ニューロンが様々なスケールのレンジを持つ
を取り入れた下の図のような ResNet ベースのモデルを提案し,ロバスト性が向上することを確認しました.
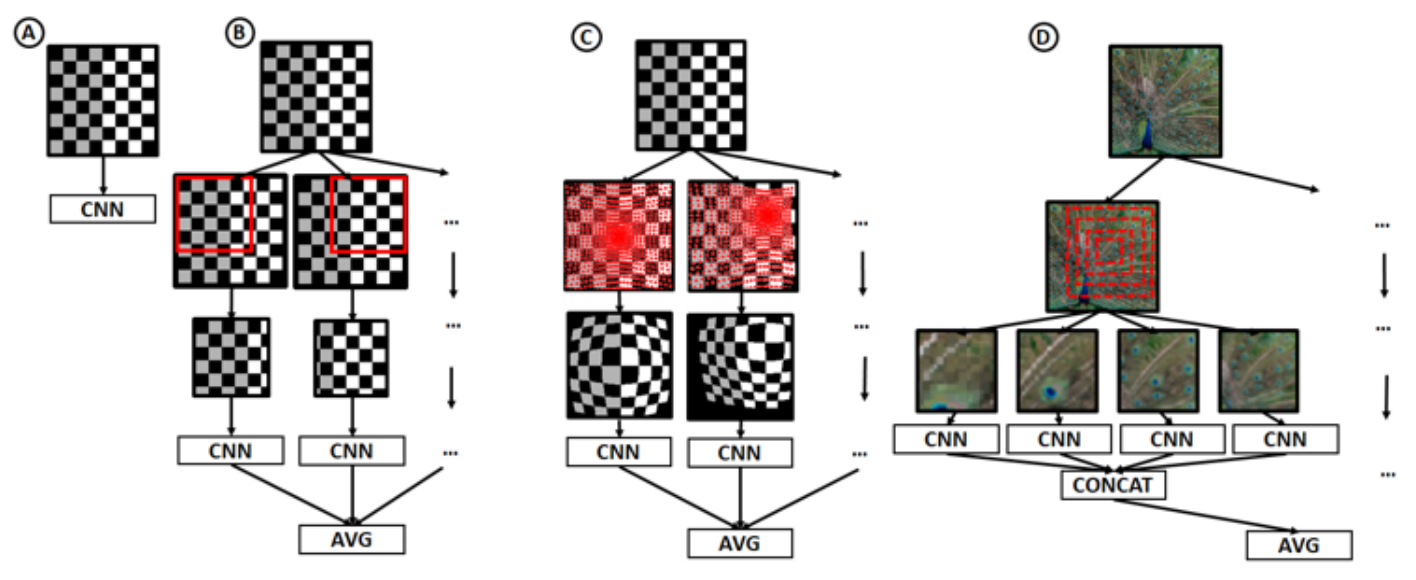 (Image source: [Biologically Inspired Mechanisms for Adversarial Robustness](https://proceedings.neurips.cc/paper/2020/hash/17256f049f1e3fede17c7a313f7657f4-Abstract.html))
B, C, D が提案手法で,B と C のロバスト性が向上しました.
(Image source: [Biologically Inspired Mechanisms for Adversarial Robustness](https://proceedings.neurips.cc/paper/2020/hash/17256f049f1e3fede17c7a313f7657f4-Abstract.html))
B, C, D が提案手法で,B と C のロバスト性が向上しました.
ロバストネスは転移学習にも有効
| Title | Do Adversarially Robust ImageNet Models Transfer Better? |
|---|---|
| Authors | Hadi Salman, Andrew Ilyas, Logan Engstrom, Ashish Kapoor, Aleksander Madry |
| Paper | https://proceedings.neurips.cc/paper/2020/hash/24357dd085d2c4b1a88a7e0692e60294-Abstract.html |
| Code | https://github.com/Microsoft/robust-models-transfer |
| Adversarial robustness とは小さな摂動に対してもモデルが不変であるよう,ノイズを加えたものを最小化する学習方法です. |
\underset{\theta}{\min}\mathbb{E}_{(x,y)\sim D}[\mathcal{L}(x,y;\theta)] \rightarrow
\underset{\theta}{\min}\mathbb{E}_{(x,y)\sim D}\left[\underset{\|\delta\|_2\le\epsilon}{\max}\mathcal{L}(x+\delta,y;\theta)\right]
すなわち,モデルが学習データ点のリスクを最小化しながら,これらの各点の周囲で局所的に安定であることも求めつつ学習を行います.しかし,この学習は普通のモデルに比べて精度が低いことが知られています.一方,ロバストモデルの特徴表現は通常のモデルよりも良い点もあることがわかってきているそうです.良い点の例としては以下のものが挙げられます.
- より良い勾配をもち,人間がわかりやすい特徴を持つ(下図左)
- ロバストな特徴表現から入力データを近似的に再構成できる(下図右)
 (Image source: [Do Adversarially Robust ImageNet Models Transfer Better?](https://proceedings.neurips.cc/paper/2020/hash/24357dd085d2c4b1a88a7e0692e60294-Abstract.html))
(Image source: [Do Adversarially Robust ImageNet Models Transfer Better?](https://proceedings.neurips.cc/paper/2020/hash/24357dd085d2c4b1a88a7e0692e60294-Abstract.html))
著者たちは Adversarial robustness が人間の特徴表現と類似した特徴表現の獲得につながっていて,学習にはロバスト性も必要であると予測しました.それを検証するため 12 個の転移学習データセットに対して精度評価を行った結果が以下の図です.
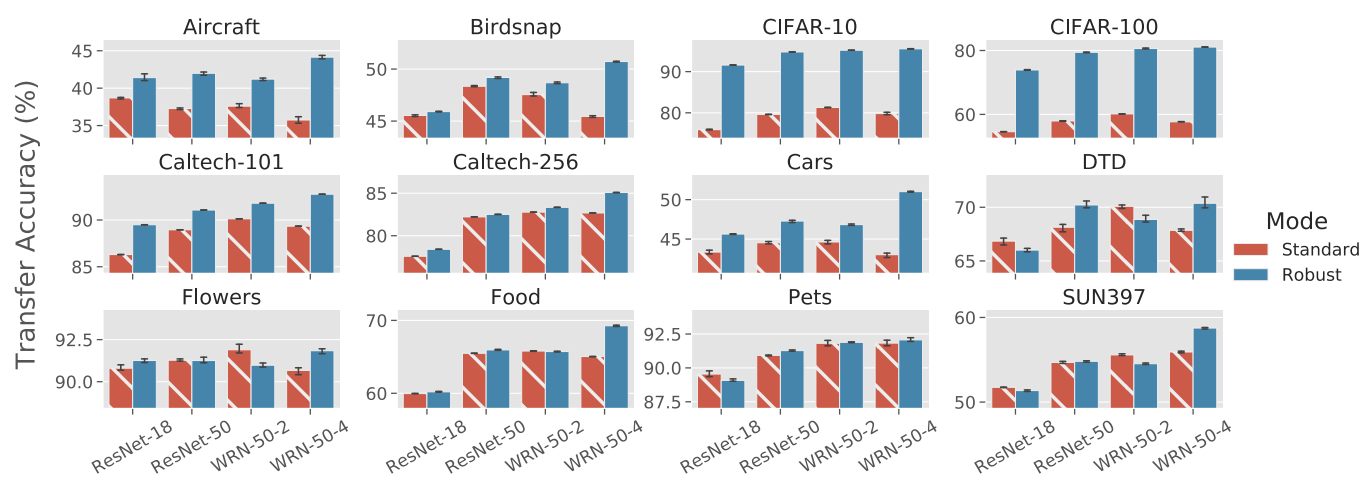 (Image source: [Do Adversarially Robust ImageNet Models Transfer Better?](https://proceedings.neurips.cc/paper/2020/hash/24357dd085d2c4b1a88a7e0692e60294-Abstract.html))
(Image source: [Do Adversarially Robust ImageNet Models Transfer Better?](https://proceedings.neurips.cc/paper/2020/hash/24357dd085d2c4b1a88a7e0692e60294-Abstract.html))
この結果から通常の画像認識タスクでは,精度は低いものの転移学習ではロバスト性が重要であることが示されました.
おわりに
長い文章を読んでいただきありがとうございました.最初に述べたとおり,Adversarial examples の素人が調べただけの記事なので間違っている箇所もあると思いますが,何かしらの参考になれば嬉しいです(+ 間違っている点のご指摘もいただけたら助かります).
参考文献
Image-scaling attack
- [QKA+2020] ↩︎
- Adversarial Preprocessing: Understanding and Preventing Image-Scaling Attacks in Machine Learning.
- Erwin Quiring, David Klein, Daniel Arp, Martin Johns and Konrad Rieck.
- In Proceeding of USENIX Security Symposium, 2020.
レビュー論文
- [XMH+20] ↩︎
- Adversarial Attacks and Defenses in Images, Graphs and Text: A Review.
- Han Xu, Yao Ma, Hao-Chen Liu, Debayan Deb, Hui Liu, Ji-Liang Tang, Anil K. Jain.
- International Journal of Automation and Computing, 17(2):151–178, 2020.
Backdoor attack
- [GDZ+20] ↩︎
- Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review.
- Yansong Gao, Bao Gia Doan, Zhi Zhang, Siqi Ma, Jiliang Zhang, Anmin Fu, Surya Nepal, Hyoungshick Kim.
- arXiv preprint arXiv:2007.10760, 2020.
White-box attack
- [CW17a] ↩︎
- Towards Evaluating the Robustness of Neural Networks.
- Nicholas Carlini, David Wagner.
- IEEE Symposium on Security and Privacy, 2017.
- [GSS15] ↩︎
- Explaining and Harnessing Adversarial Examples.
- Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy.
- In International Conference on Learning Representations, 2015.
- [KGB17a] ↩︎
- Adversarial Machine Learning at Scale.
- Alexey Kurakin, Ian J. Goodfellow, Samy Bengio.
- In International Conference on Learning Representations, 2017.
- [MFF+17] ↩︎
- Universal adversarial perturbations.
- Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, Pascal Frossard.
- In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017.
Black-box attack
- [CZS+17] ↩︎
- ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models.
- Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, Cho-Jui Hsieh.
- In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 2017.
- [PMG+17] ↩︎
- Practical Black-Box Attacks against Machine Learning.
- Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik, Ananthram Swami.
- In Proceedings of ACM on Asia Conference on Computer and Communications Security, 2017.
Physical world attack
- [AEI18] ↩︎
- Synthesizing Robust Adversarial Examples.
- Anish Athalye, Logan Engstrom, Andrew Ilyas, Kevin Kwok.
- In International Conference on Machine Learning, 2018.
- [EEF+18] ↩︎
- Robust Physical-World Attacks on Deep Learning Visual Classification.
- Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, Dawn Song.
- In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- [KGB17b] ↩︎
- Adversarial examples in the physical world.
- Alexey Kurakin, Ian Goodfellow, Samy Bengio.
- In International Conference on Learning Representations Workshop, 2017.
Gradient masking
- [ACW18] ↩︎
- Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.
- Anish Athalye, Nicholas Carlini, David Wagner.
- In International Conference on Machine Learning, 2018.
- [BRR+18] ↩︎
- Thermometer Encoding: One Hot Way To Resist Adversarial Examples.
- Jacob Buckman, Aurko Roy, Colin Raffel, Ian Goodfellow.
- In International Conference on Learning Representations, 2018.
- [DAL+18] ↩︎
- Stochastic Activation Pruning for Robust Adversarial Defense.
- Guneet S. Dhillon, Kamyar Azizzadenesheli, Zachary C. Lipton, Jeremy D. Bernstein, Jean Kossaifi, Aran Khanna, Animashree Anandkumar.
- In International Conference on Learning Representations, 2018.
- [PMW+16] ↩︎
- Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks.
- Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, Ananthram Swami.
- In Proceedings of IEEE Symposium on Security and Privacy, 2016.
Robust optimization
- [BSS+14] ↩︎
- Intriguing properties of neural networks.
- Joan Bruna, Christian Szegedy, Ilya Sutskever, Ian Goodfellow, Wojciech Zaremba, Rob Fergus, Dumitru Erhan.
- In International Conference on Learning Representations, 2014.
- [TKP+18] ↩︎
- Ensemble Adversarial Training: Attacks and Defenses.
- Florian Tramèr, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, Patrick McDaniel.
- In International Conference on Learning Representations, 2018.
Adversarial example detection
- [CW17b] ↩︎
- Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods.
- Nicholas Carlini, David Wagner.
- In Workshop on Artificial Intelligence and Security, 2017.
- [FCS+17] ↩︎
- Detecting Adversarial Samples from Artifacts.
- Reuben Feinman, Ryan R. Curtin, Saurabh Shintre, Andrew B. Gardner.
- arXiv preprint arXiv:1703.00410, 2017.
- [GMP+17] ↩︎
- On the (Statistical) Detection of Adversarial Examples.
- Kathrin Grosse, Praveen Manoharan, Nicolas Papernot, Michael Backes, Patrick McDaniel.
- arXiv preprint arXiv:1702.06280, 2017.
- [GWK17] ↩︎
- Adversarial and Clean Data Are Not Twins.
- Zhitao Gong, Wenlu Wang, Wei-Shinn Ku.
- arXiv preprint arXiv:1704.04960, 2017.
- [HG17] ↩︎
- Early Methods for Detecting Adversarial Images.
- Dan Hendrycks, Kevin Gimpel.
- In International Conference on Learning Representations Workshop, 2017.
- [MGF+17] ↩︎
- On Detecting Adversarial Perturbations.
- Jan Hendrik Metzen, Tim Genewein, Volker Fischer, Bastian Bischoff.
- In International Conference on Learning Representations, 2017.
- [XEQ18] ↩︎
- Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks.
- Weilin Xu, David Evans, Yanjun Qi.
- In Network and Distributed Systems Security Symposium, 2018.
その他参考となるリンク
- Adversarial Robustness - Theory and Practice
- Robustness in Machine Learning (CSE 599-M)
- CVPR 2020 Workshop on Adversarial Machine Learning in Computer Vision
- A Complete List of All (arXiv) Adversarial Example Papers
- Adversarial Attack | Papers With Code
-
グラフやテキストに対する Adversarial examples にも触れた記事を書こうとしていたのですが,書いてて全然ゴールが見えなくなり辛い気持ちになったためその部分は端折ってしまいました(端折った上に予定よりめちゃくちゃ遅れて年内ギリギリの投稿となってしまいました...) ↩
-
自律型会話ロボットを作るチームに所属してます.是非チェックしてみてください https://romi.ai/ ↩
-
Lpノルムに馴染みのない方はコンパクトにまとまっているこの記事を参考にしてください https://mathtrain.jp/lpnorm ↩
-
Transferability を利用するので,FGSM など Transferability の高い攻撃アルゴリズムを使うべきだそうです ↩