LLMのAIを使う際、課金方法は基本的にトークン量で課金される。
(参考:ChatGPTやAzure OpenAI Serviceの課金単位「トークン」とは? 計算してみよう)
従来のAPIは流量で課金されることがほとんであるため、流量制御のプラグインで課金額を調整できたが、AIの場合は使いすぎ防止などの観点からトークン量でリクエストを制限したくなる。
Kong GatewayのAI Rate Limiting Advanced Pluginを使うと、LLMプロバイダーから返ってきたトークンデータを使用してリクエスト数を制限することが出来る。
通常の流量制御のプラグインと大きく違う点は、流量ではなくトークン数をベースに制限出来る点であり、AIの使いすぎによる課金などを防ぐことが出来そうだ。
今回はこの動作を確認してみる。
なお、通常の流量制御を行うRate Limiting Pluginについては「KongのRate Limiting Advanced PluginとRedis Sentinelを組み合わせて使う」という記事で紹介しているので、興味がある人は参照して欲しい。
AI Rate Limiting Advanced Pluginとは
AI Rate Limiting Advanced PluginとはKong Gatewayのプラグインで前述の通りLLMプロバイダーのトークン利用量によってリクエストを制御を行う事が出来る。
導入前後のイメージはざっくり以下のような感じとなる。

利用者はKong Gateway経由でLLMプロバイダーにアクセスし、Kong Gatewayはレスポンス取得時にトークン利用量を記録する。
トークンの記録方法としては、Rate Limiting Advanced Pluginと同じでlocal、cluster、redisの3つから選べる(これらの説明に関しては旧記事参照)。
またトークンの計算方法として3つの方法が用意されている。
| 方法 | 意味 |
|---|---|
prompt_tokens |
Prompt(入力)のトークン数 |
completion_tokens |
Completion(出力)のトークン数 |
total_tokens |
prompt_tokensとcompletion_tokensの合計、デフォルトで使用 |
トークン数についてはAIにAPIでリクエストを発行した際、レスポンスの中から以下のような出力が確認でき、これを利用しているものと思われる。
"usage": {
"prompt_tokens": 22,
"completion_tokens": 10,
"total_tokens": 32
},
またトークンの上限(Limit)と現在の残量(Remaining)については以下のようにLLMプロバイダごとの情報がレスポンスヘッダから確認できる(設定で隠すことも可能)
X-AI-RateLimit-Remaining-100-cohere: 100
X-AI-RateLimit-Limit-1000-openai: 3600
X-AI-RateLimit-Remaining-1000-openai: 3577
X-AI-RateLimit-Limit-100-cohere: 100
なお、AIがついていない以下のようなヘッダについてはLLMプロバイダが付与するヘッダであり、Kong Gatewayは関与していないので注意。(参考:Rate limits in headers)
x-ratelimit-limit-requests: 500
x-ratelimit-limit-tokens: 30000
x-ratelimit-remaining-requests: 499
x-ratelimit-remaining-tokens: 29475
x-ratelimit-reset-requests: 120ms
x-ratelimit-reset-tokens: 1.05s
'24/7時点で対応しているLLMプロバイダは
openai, azure, anthropic, cohere, mistral, llama2, requestPrompt
となっている。
その他の設定項目については多くがRate Limiting Advanced Pluginのものを引き継いでいるのでそちらも併せて参考にするとよい。
検証環境
検証を行うにあたり、ここでは既に以下があるものとして進める。
- Kong Gateway Enterprise v3.7
- LLMサービスのAPIトークン
- deckコマンド
Kong GatewayのAdmin APIは公開されており、deckコマンドで利用可能になっているものとする。
LLMサービスのAPIトークンはここではOpenAIのものを利用する。
お金をかけずに試したい人はCohereかローカルにLLMサービスを立てて使うとよい。
Pluginの導入
以下のような感じでKong Gatewayが提供するProxyの/ai-ratelimitにアクセスすると、Service側のAI Rate Limit Pluginでトークン量を制限するように構築する。
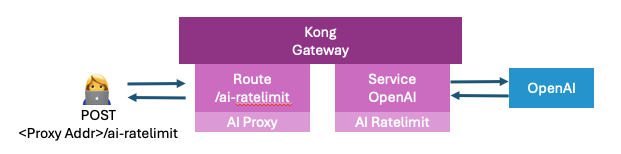
なお、AI Proxy PluginをRouteで設定しているが、AI Rate Limit Pluginのの利用が前提となっているので、併せて設定している。
Kong Gatewayに各種プラグインの設定をするために、以下のdeck用YAMLを作成する。
services:
- name: common-ai-for-ratelimit
host: localhost
port: 8000
plugins:
- name: ai-rate-limiting-advanced
config:
tokens_count_strategy: total_tokens
llm_providers:
- limit: 100
name: openai
window_size: 100
routes:
- name: openai-for-ratelimit
headers:
llm:
- openai
paths:
- "~/ai-ratelimit$"
methods:
- POST
plugins:
- name: ai-proxy
config:
route_type: "llm/v1/chat"
auth:
header_name: "Authorization"
header_value: "Bearer sk-svcacct-xxxx"
model:
provider: "openai"
name: "gpt-4-turbo"
options:
max_tokens: 512
temperature: 1.0
model.providerに設定した値はこちらから適当に選んだ。
auth.header_valueのsk-svcacct-xxxxに関しては自身のOpenAIのAPIキーを設定する。
(分かりやすさの観点でベタ書きしているが、実際はSecret Managementを使って隠蔽することを推奨)
AI Rate Limiting Advanced Pluginの設定箇所は以下の部分になる。
plugins:
- name: ai-rate-limiting-advanced
config:
tokens_count_strategy: total_tokens
llm_providers:
- limit: 100
name: openai
window_size: 100
tokens_count_strategyは指定しなくてもデフォルトでtotal_tokensだが、分かりやすくするためにあえて設定している。
なお、OpenAIだと出力の方が高くなるため、出力トークンの制御に該当するcompletion_tokensを設定して使うと良さそうだが、'24/7/19時点でcompletion_tokens指定時に正常に動作していないように見えるのでここでは選んでいない。
作成したdeck用YAMLを適用する。
deck gateway dump -o /tmp/dump.yaml
deck gateway sync /tmp/dump.yaml ./ai-ratelimit.yaml
検証
Kong Gateway経由でOpenAIにプロンプトを数回投げて、トークン量ベースの流量制御が効くかを確認する。
まず最初にアクセス先とプロンプトを環境変数に設定する。
PROXY=https://192.168.64.202
ROUTE_PATH=ai-ratelimit
PROMPT="1+1は?"
以下のcurlコマンドを2回実行する。
curl -k -i --compressed --http1.1 -X POST ${PROXY}/${ROUTE_PATH} \
-H "llm: openai" \
-H "Content-Type: application/json" -d "{
\"messages\": [{
\"role\": \"user\",
\"content\": \"$PROMPT\"
}] }"
1回目の出力はおおよそ以下のような感じになっていると思う。
:(省略)
X-AI-RateLimit-Limit-100-openai: 100
X-AI-RateLimit-Remaining-100-openai: 100
;(省略)
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "1+1は2です。"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 12,
"completion_tokens": 7,
"total_tokens": 19
},
X-AI-RateLimit-Remainingに関してはまだ利用トークン数がカウントされていないので100のままとなる。
利用したトークン数の合計は19なので、次回実行時の残トークン数は100-19=81となるはずだ。
2回目の出力は以下のような感じとなる。
:(省略)
X-AI-RateLimit-Limit-100-openai: 100
X-AI-RateLimit-Remaining-100-openai: 81
:(省略)
期待した通り、前回のトークンの総数を引いた数が残数となっている。
ここで利用トークンが多そうな内容に変えてリクエストを送ってみる。
PROMPT="日本の観光地の人気トップ3と特長を教えて"
curl -k -i --compressed --http1.1 -X POST ${PROXY}/${ROUTE_PATH} \
-H "llm: openai" \
-H "Content-Type: application/json" -d "{
\"messages\": [{
\"role\": \"user\",
\"content\": \"$PROMPT\"
}] }"
実行結果は以下となった。
"usage": {
"prompt_tokens": 31,
"completion_tokens": 512,
"total_tokens": 543
},
利用トークン数(543)が制限(100)を上回った。
この状態でリクエストを発行しても失敗するはずだ。
実施に実行した結果が以下となる。
HTTP/1.1 429 Too Many Requests
Date: Fri, 19 Jul 2024 01:53:59 GMT
Content-Type: application/json; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
X-AI-RateLimit-Reset-100-openai: 130
X-AI-RateLimit-Retry-After-100-openai: 130
X-AI-RateLimit-Limit-100-openai: 100
X-AI-RateLimit-Remaining-100-openai: 0
X-AI-RateLimit-Retry-After: 130
X-AI-RateLimit-Reset: 130
X-Kong-Response-Latency: 1
Server: kong/3.7.1.2-enterprise-edition
X-Kong-Request-Id: 54e199023349775c0c3ca81979db6a25
{"message":"API rate limit exceeded for provider(s): openai"}
残数(X-AI-RateLimit-Remaining-100-openai)が0となり、429が返ってきた。
これにより、リクエストの制限をトークン量で制限出来ることが確認できた。
所感
組織でAIを活用する上で、使いすぎをどう抑止するかは課題になると思われる。
アカウントごとに設定するのであれば容易だが、同一アカウントを利用用途などで更に細かく設定したい場合などユースケースによってはLLMプロバイダが提供している手段だけだと使いすぎを防ぐのが難しくなってくる。
利用規模が大きくなった時など、複雑かつガバナンスをしっかり効かせるようなケースが出てきた場合はこのプラグインを大いに活用できそうだ。