はじめに
前回コンパラマップの基本的なプログラムを作りました。
今回は実際の特許データを使用してコンパラマップを作成したいと思います。
プログラム
データフレーム作成
データフレームの作成部分は、以下の記事で作成したコードを流用します。
今回は「課題」と「出願人」を2社しか使用しませんので、予め、課題と出願人の限定処理を行っています。
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
# googleドライブの利用
from google.colab import drive
drive.mount('/content/drive')
# データの前処理
# データの読み込み(google ドライブから)
df_fterm = pd.read_csv("/content/drive/MyDrive/吸収性物品3_2553.csv")
#必要な列のみ抽出
df_fterm = df_fterm[['Fターム(最新)','出願人・権利者(最新)']]
# 欠落データを削除
df_fterm = df_fterm.dropna()
# Fターム列をコピーして追加
df_fterm['課題'] = df_fterm['Fターム(最新)']
# ;で課題を分割
df_fterm['課題'] = df_fterm['課題'].str.split(';')
# ;で出願人・権利者(最新)を分割
df_fterm['出願人・権利者(最新)'] = df_fterm['出願人・権利者(最新)'].str.split(';')
# 課題と解決手段と出願人をエクスプロード
df_fterm = df_fterm.explode('課題').explode('出願人・権利者(最新)')
# 課題の限定処理
task_list = ["3B200 BA01", "3B200 BA02", "3B200 BA03", "3B200 BA04", "3B200 BA05", "3B200 BA06", "3B200 BA07", "3B200 BA08", "3B200 BA09", "3B200 BA10", "3B200 BA11", "3B200 BA12", "3B200 BA13", "3B200 BA14", "3B200 BA15", "3B200 BA16", "3B200 BA17", "3B200 BA18", "3B200 BA19"]
df_fterm = df_fterm[df_fterm['課題'].isin(task_list)]
# 出願人の限定処理
applicant_list = ["花王株式会社", "日本製紙クレシア株式会社"]
df_fterm = df_fterm[df_fterm['出願人・権利者(最新)'].isin(applicant_list)]
# map置き換え用の辞書作成
replace_dict_1 = {
'3B200 BA01': '吸水性',
'3B200 BA02': '親水性',
'3B200 BA03': '透水性',
'3B200 BA04': '拡散性',
'3B200 BA05': '撥水性',
'3B200 BA06': '逆流防止',
'3B200 BA07': '通気性',
'3B200 BA08': '風合',
'3B200 BA09': '嵩高',
'3B200 BA10': '膨張性',
'3B200 BA11': '伸張性',
'3B200 BA12': '伸縮性',
'3B200 BA13': '剛性',
'3B200 BA14': '密度',
'3B200 BA15': '光透過性',
'3B200 BA16': '接着性',
'3B200 BA17': '分解性',
'3B200 BA18': '水分解性',
'3B200 BA19': '保温性',
}
# mapメソッドを使用して分類を日本語に置き換える
df_fterm.loc[:, '課題'] = df_fterm['課題'].map(replace_dict_1)
# データフレーム確認
print(df_fterm)
出力されたデータフレームは以下となります。うまく、出願人・権利者(最新):2社と課題のデータフレームが作成されております。
Fターム(最新) 出願人・権利者(最新) 課題
0 3B200 AA03;3B200 BA01;3B200 BA03;3B200 BA16;3B... 日本製紙クレシア株式会社 吸水性
0 3B200 AA03;3B200 BA01;3B200 BA03;3B200 BA16;3B... 日本製紙クレシア株式会社 透水性
0 3B200 AA03;3B200 BA01;3B200 BA03;3B200 BA16;3B... 日本製紙クレシア株式会社 接着性
1 3B200 AA03;3B200 BA04;3B200 BA16;3B200 BB03;3B... 花王株式会社 拡散性
1 3B200 AA03;3B200 BA04;3B200 BA16;3B200 BB03;3B... 花王株式会社 接着性
... ... ... ...
2163 3B200 AA01;3B200 AA03;3B200 EA24;3B200 EA07;3B... 花王株式会社 分解性
2163 3B200 AA01;3B200 AA03;3B200 EA24;3B200 EA07;3B... 花王株式会社 接着性
2163 3B200 AA01;3B200 AA03;3B200 EA24;3B200 EA07;3B... 花王株式会社 嵩高
2163 3B200 AA01;3B200 AA03;3B200 EA24;3B200 EA07;3B... 花王株式会社 親水性
2163 3B200 AA01;3B200 AA03;3B200 EA24;3B200 EA07;3B... 花王株式会社 吸水性
ピボットテーブル
ここでなぜピボットテーブルを作成するかというと、棒グラフの大小により色を変えようとしたからです。ChatGPTが提案してきたのは、このピボットテーブル化でした。
しかし、この部分はなぜかエラーが多発しましたので、特に色の濃淡をつける必要がない場合には、前回のコードの方を参考にしてください。
# 出願人の一覧を取得
unique_applicants = df_fterm['出願人・権利者(最新)'].unique()
# 出願人が2社でない場合、エラーを表示
if len(unique_applicants) != 2:
raise ValueError("データには2つの異なる出願人が含まれている必要があります。")
# 2つの出願人を変数に格納
company1, company2 = unique_applicants
# データフレームを再構成し、同じ課題を同じ行に配置
df_pivot = df_fterm.pivot_table(index='課題', columns='出願人・権利者(最新)', aggfunc=len, fill_value=0)
# マルチインデックスを単一インデックスに変換
df_pivot.columns = df_pivot.columns.get_level_values(1)
# データフレーム確認
print(df_pivot)
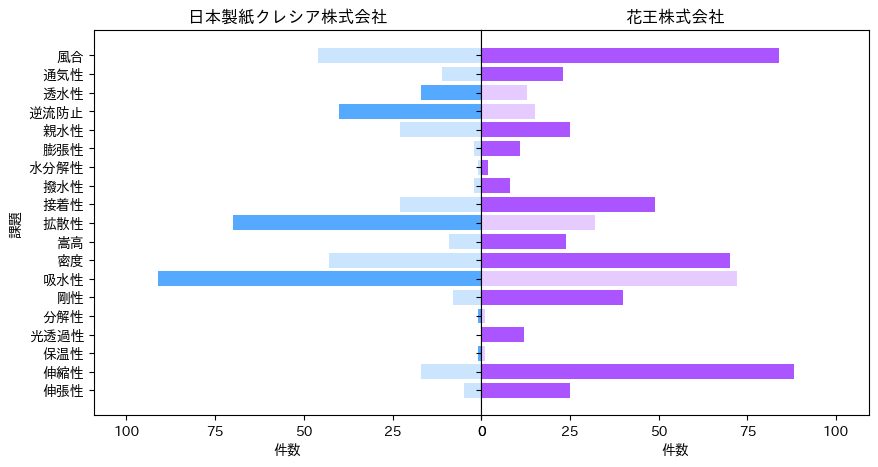
生成されたデータフレームは以下となります。コンパラマップなど書かずとも、このデータフレームを出力としてもよいかもしれません。
出願人・権利者(最新) 日本製紙クレシア株式会社 花王株式会社
課題
伸張性 5 25
伸縮性 17 88
保温性 1 1
光透過性 0 12
分解性 1 1
剛性 8 40
吸水性 91 72
密度 43 70
嵩高 9 24
拡散性 70 32
接着性 23 49
撥水性 2 8
水分解性 1 2
膨張性 2 11
親水性 23 25
逆流防止 40 15
透水性 17 13
通気性 11 23
風合 46 84
グラフ化
グラフを描画します。
# 各課題について、より大きな値を持つ出願人を特定
df_pivot['強調'] = df_pivot.idxmax(axis=1)
# 強調色と非強調色を定義
emphasize_color = sns.color_palette("cool", 2)
non_emphasize_color = [(r, g, b, 0.3) for r, g, b in emphasize_color]
# グラフの最大値を計算
max_count = max(df_pivot[company1].max(), df_pivot[company2].max())
x_limit = max_count * 1.2 # 余裕のある値
# グラフを描画
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5), sharey=True, gridspec_kw={'wspace': 0})
ax1.invert_xaxis() # 左のグラフのx軸を反転
ax1.barh(df_pivot.index, df_pivot[company1], color=[emphasize_color[0] if winner == company1 else non_emphasize_color[0] for winner in df_pivot['強調']])
ax2.barh(df_pivot.index, df_pivot[company2], color=[emphasize_color[1] if winner == company2 else non_emphasize_color[1] for winner in df_pivot['強調']])
ax1.set_xlim(x_limit, 0) # 左のグラフのx軸の範囲を指定
ax2.set_xlim(0, x_limit) # 右のグラフのx軸の範囲を指定
ax1.set_title(f'{company1}')
ax1.set_xlabel('件数')
ax1.set_ylabel('課題')
ax2.set_title(f'{company2}')
ax2.set_xlabel('件数')
ax1.locator_params(axis="x", nbins=5)
ax2.locator_params(axis="x", nbins=5)
plt.show()
コンパラマップ
完成したコンパラマップは以下となります。件数で優っている横棒を濃くし、劣っている横棒を薄くしてみました。これにより、強弱がなんとなくわかるかと思います。
しかし、横棒の長さで大小はわかりますので、このような処理は無駄というか、遊びみたいなものです。
感想
横棒を普通に並べるのが良いのか、コンパラ風に並べるのが良いのかはよくわかりませんが、こういうグラフも書けることを覚えておけば、何かの役に立つかもしれません。
今までは、バブルチャートを主に作っておりましたが、棒グラフもなかなかよいと感じました。次は折れ線グラフで何か作ってみたいと思います。