背景
プログラミングの初心者が最初に作るプログラムはだいたいジャンケンゲームかクイズゲームですね。
選択肢を選ぶだけなので難しいテクニックは何も必要ありません。
初心者ならずとも新しい言語やフレームワークを学ぶにあたり、実際何かを作ってみるのが一番効率的だと思います。
その場合も簡単なものから始めるのが挫折しないコツでしょう。
今回の成果物
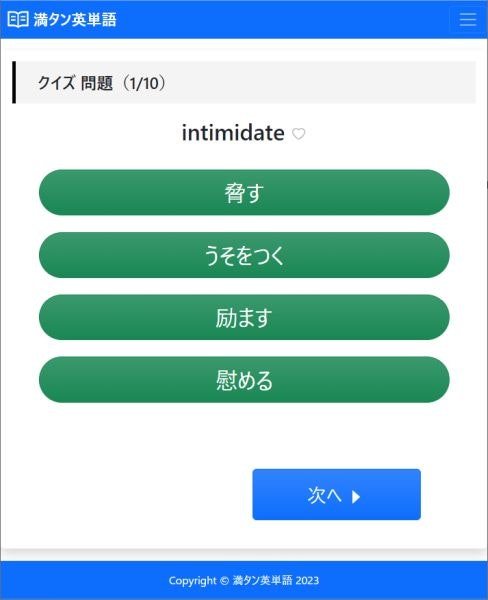
私の場合はフロントエンド開発は初心者なので、勉強としてクイズアプリを作ることにしました。
せっかくなら多少は実用的なアプリということで英単語アプリにしました。成果物は下記になります。
実装はReact x TypeScript x Firebaseになります。
ReactもFirebaseも今回始めて使ったので大変勉強になりましたがテーマとずれるため割愛します。
英単語について
英単語アプリを作るにあたって、まずは単語をそろえる必要があります。
幸い世の中には頻度や難易度別にたくさんの英単語リストが公開されています。
- 「English Word List」
- 「Vocabulary List」
等のキーワードで検索すると国内外でたくさんヒットします。
私の場合は勉強用として以前作成した自作の単語リスト(※)を活用することにしました。
※かつて公開されていたアルクさんのSVL12000のリストをベースに上記サイトの単語等も取り入れたもの
問題はChatGPTに作ってもらう
さて、クイズアプリなのでクイズがないと始まらないのですが、さすがに15000語ぶんのクイズを作るのは手間がかかりすぎです。完全に趣味の勉強の範囲を逸脱します。
そもそも英単語のクイズ問題自体を作りたいわけじゃないし。
そこでChatGPTです。AIにクイズを自動生成してもらいます。
AIなら頭を一切使うことなくクイズ問題が手に入るというわけです。
ChatGPTをAPI呼び出しで使う
ChatGPT には Web画面で使う対話型とAPIを呼び出して使う方法の2種類があります。
ChatGPTのチャットは文字数に制限があり一度に大量の単語のクイズを作ってもらうことはできません。
何度も質問を投げないといけなくなるため、今回はAPI呼び出しで使うことにしました。
ちなみに「CSV形式で返してください」とお願いすればCSV形式で返してくれます。CSVなら加工も容易そうです。
ChatGPTのAPIを使うには事前登録が必要になります。
無料利用枠もありますので、お試しも可能です。
データベースにデータを保存する
ChatGPTから返ってきたデータをそのままテキストファイルなどに保存しても良いのですが、テキストファイルだと何かと扱いが面倒です。いちいちファイルを開いてデータを読み出すのも大変そうです。
なので今回はデータベースを利用することにしました。
データベースは何でも良いと思いますが、私は慣れているのでMySQLを使いました。
SQLiteとかでもいいと思います。
データベースの前準備
ローカルでMySQLを立ち上げて、下記のテーブルを作成します。
テーブル名「words」
カラム名 「id」「name」「correct」「incorrect1」「incorrect2」「incorrect3」「incorrect4」
※ それぞれ単語、正答、不正解1~4となります。
「name」欄に、CSVとしてインポートするなど集めておいた単語を流し込んでセットしておきます。
ここで正答と不正解の欄は空です。
PythonでChatGPTのAPIを呼び出す
準備ができたらChatGPT のAPIを呼び出すPythonプログラムを走らせます。
APIおよびデータベースの接続情報は適宜変更が必要です。
import pymysql
import os
from datetime import datetime
import openai
import time
openai.api_key = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
mysql_kwargs = {
"host": "localhost",
"port": 3306,
"user": "hogeuser",
"password": "xxxx",
"database": "somedb",
}
def callchatgpt(words):
question = "次の英単語リストの選択問題クイズを作りCSVデータを出力してください。"
question += "単語、正解の和訳、不正解の和訳1、不正解の和訳2、不正解の和訳3、不正解の和訳4。"
question += "CSVデータ以外は出力しないでください。\n----\n"
for word in words:
question += word + "\n"
response = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
messages = [
{"role": "user", "content": question},
],
)
retvals = []
answer = response.choices[0]["message"]["content"].strip()
answer_lines = answer.split("\n")
for answer_line in answer_lines:
if answer_line == "":
continue
answer_vals = answer_line.split(",")
#ヘッダ行は無視します
if answer_vals[0] == "単語":
continue
retvals.append(answer_vals)
return retvals
def main(connection):
cursor = connection.cursor(pymysql.cursors.DictCursor)
cursor.execute("SELECT * FROM words WHERE correct IS NULL ORDER BY id LIMIT 10")
rows = cursor.fetchall()
words = []
for row in rows:
words.append(row['name'])
if len(words) > 0:
retvals = callchatgpt(words)
if retvals is not None and len(retvals) > 0:
for retval in retvals:
if len(retval) == 6:
cursor.execute("UPDATE words SET correct = %s, incorrect1 = %s, incorrect2 = %s, incorrect3 = %s, incorrect4 = %s WHERE name = %s", (retval[1], retval[2], retval[3], retval[4], retval[5], retval[0]))
# 保存を実行
connection.commit()
cursor.close()
if __name__ == "__main__":
connection = pymysql.connect(**mysql_kwargs)
# 繰り返し数
repeat = 5
for i in range(repeat):
main(connection)
# 接続を閉じる
connection.close()
完了すれば、データベースの「correct」「incorrect1」「incorrect2」「incorrect3」「incorrect4」にChatGPTが返してくれた正解と不正解の値が入っています。
これでクイズの問題を作ることができました。
所感
- 実際はそんなにスムーズに行かなかった。
- まとめて大量のリクエストを投げるとChatGPTがビジー状態になって取得が失敗することがしばしば発生した。
- 何度もリクエストすると、1分あたり3回までとか言うレスポンスとともにリジェクトされるようになった。
- その場合はmainの後でsleepを入れるなど、適宜工夫が必要だった。
- また返してくるCSVデータもかなり怪しいデータも多い。
- 選択肢も英語だったり、空欄で返してきたり、クイズとして成立してないものも結構あった。
- 使えなそうなデータは目視により人力でのチェックによる修正が必要だった。
- データの品質についてはプロンプトを改善することでもうちょっとマシになるのかもしれない。
- モデルは「gpt-3.5-turbo」を利用した。
- 精度はGPT-4モデルの方が良いが値段と処理時間がぐんと上がるため断念。
- 1リクエストで10単語処理するようにしたので、総リクエスト数は1500。実際は試行錯誤含めてもう少しぐらい。
- それぐらいのリクエスト数でも無料課金枠に収まった。安い。